爬取百度页面代码写入到文件+web请求过程解析
一、爬取百度页面代码写入到文件
代码示例:
from urllib.request import urlopen #导入urlopen包
url="http://www.baidu.com" #需要爬取网页的网址
resp=urlopen(url)
with open("mybaidu.html",mode="w",encoding="utf-8") as f: #encoding="utf-8"防乱码
f.write(resp.read().decode())#将爬取到的代码写入到文件中,decode()用于解码,防止中文乱码
print("爬取完成!")
二、 web请求过程解析
1.服务器渲染:在服务器直接将数据和html整合在一起,特点为在html源代码中可以看到数据。
例:在百度中搜索“李白”,得到的页面及解析如下:
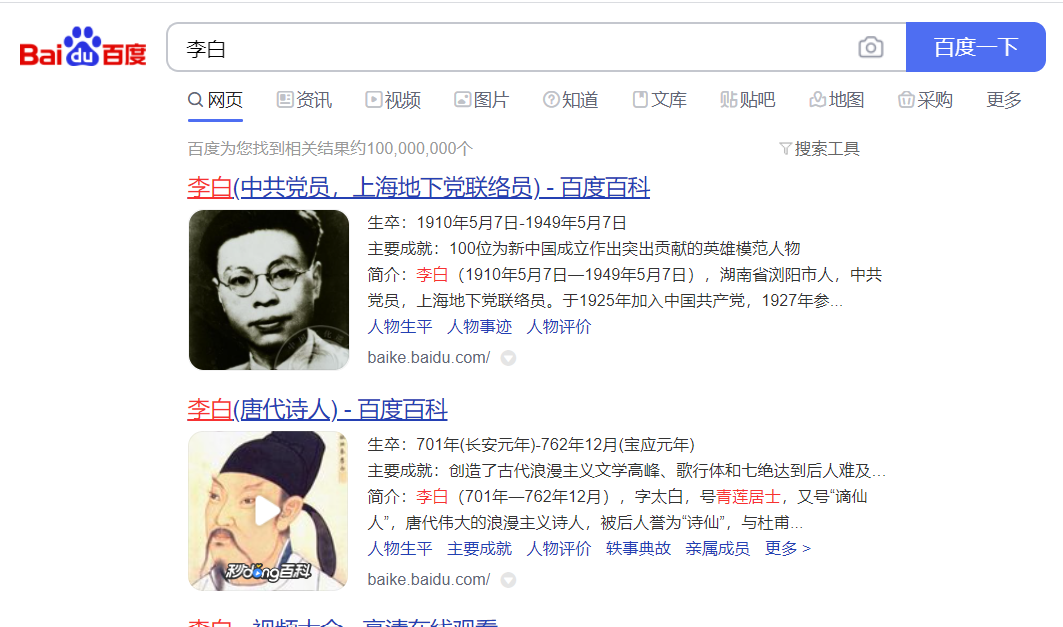

很明显在html源代码中可以看到数据。
2.客户端渲染:客户端发送两次请求,第一次请求得到html代码,第二次得到数据,在客户端中将二者整合呈现给用户。
特点:在html源代码中无法看到数据
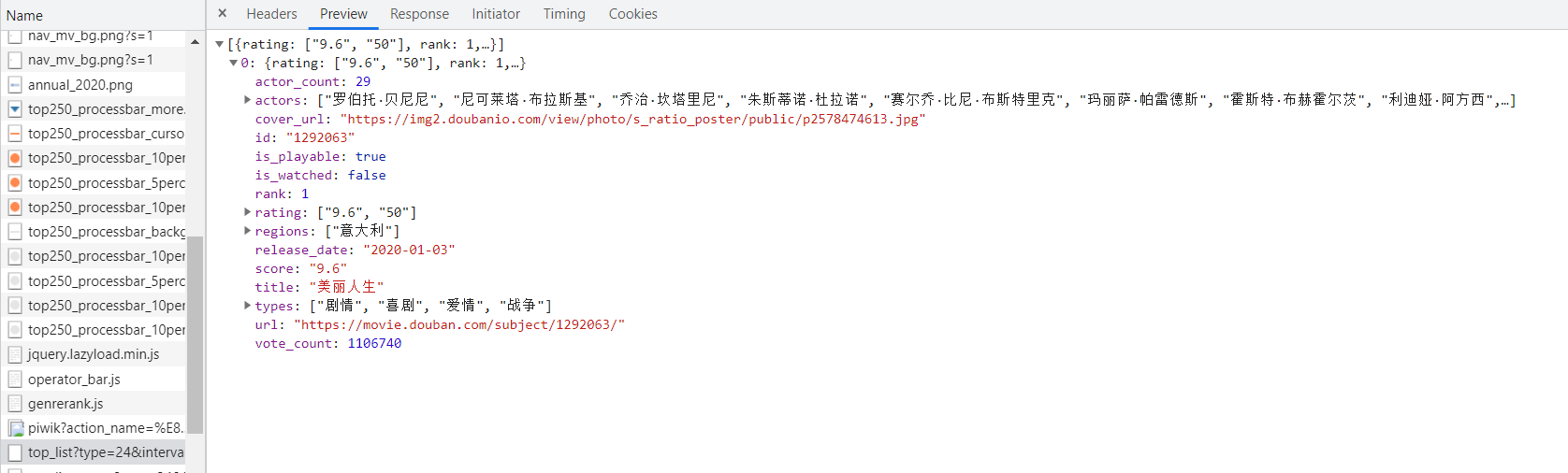
例:查看豆瓣分类排行榜页面,其预览中并没有展示数据,由此可见其源代码中没有数据。

在下面的请求中可以看到数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号