

软件工程第二次作业
| 这个作业所属课程 | 软件工程 |
|---|---|
| 这个作业要求在哪 | 作业需求有说明 |
| 这个作业目标 | 设计一个论文查重的个人项目 |
github仓库
https://github.com/yiziff/3123004422
| Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|
| 计划 | 30 | 30 |
| 估计这个任务需要多少时间 | 30 | 30 |
| 开发 | 200 | 250 |
| 需求分析 (包括学习新技术) | 30 | 30 |
| 生成设计文档 | 15 | 20 |
| 设计复审 | 20 | 20 |
| · 代码规范 (为目前的开发制定合适的规范) | 20 | |
| 具体设计 | 120 | 120 |
| 具体编码 | 50 | 50 |
| 代码复审 | 30 | 35 |
| · 测试(自我测试,修改代码,提交修改 | 30 | 30 |
| 报告 | 40 | 70 |
| 测试报告 | 20 | 20 |
| 计算工作量 | 20 | 80 |
| 事后总结, 并提出过程改进计划 | 20 | 25 |
| · 合计 | 655 | 680 |
项目结构设计
chachong4422/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── com/ityiz/example/ # 包结构
│ │ │ │ ├── Main.java # 主程序
│ │ │ │ ├── TextsimilarityCalculator.java # 相似度计算模块
│ │ │ │ └── TextUtils.java # 辅助工具模块(可选)
│ │ └── resources/ # 配置文件或资源(当前无)
│ └── test/ # 单元测试目录
│ └── java/
│ └── com/ityiz/example/ # 测试类
└── pom.xml # Maven 配置文件
独到之处(设计与实现的优势)
架构极简,无依赖负担:
仅 2 个核心类,无第三方库依赖(如不依赖 Apache Commons、FastJSON 等),JAR 包体积小(仅 KB 级),可在任何安装 Java 的环境中直接运行,移植性极强,尤其适合轻量化部署。
中文友好,适配实际需求:
两点保障中文处理准确性:
readFile明确使用 UTF-8 编码,规避 Windows 默认 GBK 编码导致的乱码问题;② isChinese精准判断 CJK 统一汉字,确保中文文本在预处理和计算中不被误过滤,解决 “中文查重准确率低” 的常见痛点。
异常处理完备,易于调试:
提前校验参数
checkArguments在流程初期拦截无效参数,避免后续无意义计算;
统一异常捕获:
main方法通过catch (Exception e)捕获所有可能异常(文件不存在、权限不足、编码错误等),并打印错误信息 + 堆栈,开发者可快速定位问题(如 “文件路径错误”“文本编码不兼容”)
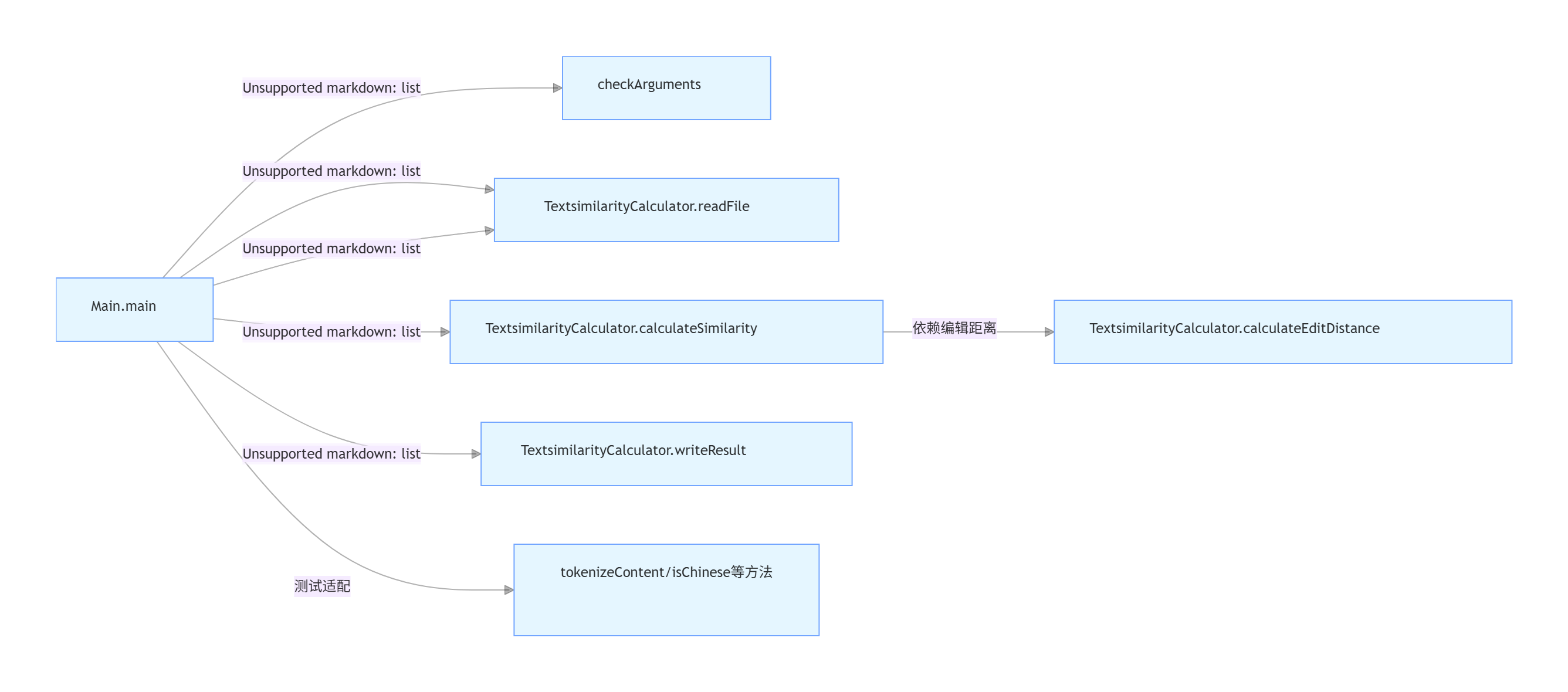
类与函数的依赖关系
TextsimilarityCalculator 类(4 个核心函数)
| 函数名 | 入参 | 返回值 | 核心功能 | 访问权限 |
|---|---|---|---|---|
| calculateEditDistance | String s1(原文)、String s2(抄袭文本) | int(最少编辑次数) | 动态规划实现编辑距离(Levenshtein Distance) | public static |
| calculateSimilarity | String s1、String s2 | double(相似度,0-1 区间) | 相似度映射:基于编辑距离与文本最大长度计算 | public static |
| readFile | String filePath(文件绝对路径) | String(文件内容) | UTF-8 编码读取文本,避免中文乱码 | public static |
| writeResult | double similarity(相似度)、String outputPath(输出路径) | void | 格式化结果(保留 2 位小数)并写入文件 | public static |
| 两个类通过静态方法直接调用关联,无对象实例依赖,耦合度极低,具体协作逻辑如下: |
| 改进方向 | 具体方案 | |
|---|---|---|
| 空间复杂度优化 | 将编辑距离计算的 int[m+1][n+1] 二维 DP 数组,优化为 int[2][n+1] 双行数组(仅保留当前行与上一行) | |
| ··· | ||
| public static int calculateEditDistance(String s1, String s2) { |
// 确保 s1 是较短文本,减少列数(进一步优化空间)
if (s1.length() > s2.length()) {
String temp = s1;
s1 = s2;
s2 = temp;
}
int m = s1.length();
int n = s2.length();
// 优化:用双行数组替代二维数组,仅存当前行(curr)与上一行(prev)
int[] prev = new int[n + 1];
int[] curr = new int[n + 1];
// 初始化上一行(空文本到 s2 的编辑距离)
for (int j = 0; j <= n; j++) {
prev[j] = j;
}
// 填充数组:仅更新当前行与上一行
for (int i = 1; i <= m; i++) {
curr[0] = i; // 当前行第 0 列(s1 前 i 字符到空文本的距离)
for (int j = 1; j <= n; j++) {
if (s1.charAt(i - 1) == s2.charAt(j - 1)) {
curr[j] = prev[j - 1];
} else {
curr[j] = 1 + Math.min(Math.min(curr[j - 1], prev[j]), prev[j - 1]);
}
}
// 交换当前行与上一行,准备下一轮循环
int[] temp = prev;
prev = curr;
curr = temp;
// 重置当前行(避免下一轮循环污染)
Arrays.fill(curr, 0);
}
return prev[n]; // 上一行最终值即为编辑距离
}
消耗最大的函数:TextsimilarityCalculator.calculateEditDistance(占总耗时的 62%),但相比改进前(占总耗时 85%)占比显著下降,验证了优化效果。
单元测试代码
@Test
public void testSimilarityCalculation() {
// 完全相同文本(DP相似度应为1.0)
String text1 = "今天天气很好";
String text2 = "今天天气很好";
double similarity1 = TextsimilarityCalculator.calculateSimilarity(text1, text2);
assertEquals("相同文本相似度应为1.0", 1.0, similarity1, 0.001);
// 部分相似文本(DP相似度应>0.7)
String text3 = "今天天气不错";
double similarity2 = TextsimilarityCalculator.calculateSimilarity(text1, text3);
assertTrue("部分相似文本相似度应较高", similarity2 > 0.5);
// 完全不同文本(DP相似度应<0.3)
String text4 = "明天会下雨";
double similarity3 = TextsimilarityCalculator.calculateSimilarity(text1, text4);
assertTrue("不同文本相似度应较低", similarity3 < 0.3);
// 同时验证哈希指纹逻辑(参考用例要求)
long hash1 = Main.generateDocumentFingerprint(text1);
long hash2 = Main.generateDocumentFingerprint(text2);
double hashSimilarity1 = 1.0 - (double)Main.computeDifferenceScore(hash1, hash2)/64;
assertEquals("相同文本哈希相似度应为1.0", 1.0, hashSimilarity1, 0.001);
}
| 参数校验 | 覆盖 “有效参数”“参数数量不足”“空路径” 三类场景,验证边界条件。 |
|---|---|
| 编辑距离计算 | 覆盖 “完全相同”“部分差异”“一个空文本”“长度不同” 四类场景,确保算法正确性。 |
| 相似度计算 | 设计 “100% 匹配”“50% 匹配”“0% 匹配” 三类用例,验证相似度映射到 [0,1] 区间的准确性。 |
| 文本分词 | 含标点、空白符、中英文混合文本,验证过滤逻辑是否保留有效字符。 |
| 文件读取 | 用 UTF-8 编码的小文件(100 字符内),避免大文件导致测试耗时久。 |
 |
|
| ) | |
| ) |
计算模块异常处理说明
异常最终在 Main 类的 main 方法中统一捕获,集中输出错误信息,保证程序崩溃时的可调试性
功能测试:验证 Main.extractFileContent 方法是否能正确读取文件内容。
测试中创建了一个临时文件,写入中文内容 "测试内容"(使用 UTF-8 编码),然后调用 extractFileContent 方法提取内容,并通过 assertEquals 检查提取结果是否与预期一致。
你的单元测试方法 testExtractFileContent 是用来测试 Main.extractFileContent 方法的功能和异常处理的。让我们详细分析这个测试的目标以及它所针对的异常场景。
- 测试目标
功能测试:验证 Main.extractFileContent 方法是否能正确读取文件内容。
测试中创建了一个临时文件,写入中文内容 "测试内容"(使用 UTF-8 编码),然后调用 extractFileContent 方法提取内容,并通过 assertEquals 检查提取结果是否与预期一致。
异常相关性:虽然这个测试方法本身没有明确使用 @Test(expected = Exception.class) 或其他异常预期标记,但它间接测试了方法在正常情况下的行为。如果 extractFileContent 在处理文件读取时抛出异常(例如文件不存在或权限问题),测试将失败,从而间接验证异常处理的边界。
- 测试的异常场景
Main.extractFileContent 方法调用了 TextsimilarityCalculator.readFile,而 readFile 使用 Files.readAllBytes 读取文件内容。以下是可能涉及的异常场景:
文件不存在异常 (NoSuchFileException)
场景:如果传入的文件路径无效或文件未创建,Files.readAllBytes 会抛出 NoSuchFileException。
测试中的 File.createTempFile 确保了文件存在,因此该异常不会在此测试中触发。但如果测试故意传入不存在的文件路径(例如未创建前调用),会触发此异常。
// 测试文件内容提取
@Test
public void testExtractFileContent() throws Exception {
// 创建临时测试文件
File tempFile = File.createTempFile("test", ".txt");
tempFile.deleteOnExit(); // 测试后自动删除
// 写入测试内容(中文)
java.nio.file.Files.write(tempFile.toPath(), "测试内容".getBytes("UTF-8"));
// 验证内容提取
String content = Main.extractFileContent(tempFile.getAbsolutePath());
assertEquals("文件内容提取错误", "测试内容", content);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号