

机器学习||李宏毅课程笔记13终身学习(Life Long Learning)
这是李宏毅老师机器学习【第十三节课程】的笔记(仅用于个人学习记录),本节课程简单对终身学习(Life Long Learning)进行了介绍。
Basic
终身学习(Life Long Learning,LLL),又称Continuous Learning、Never Ending Learning、 Incremental Learning
- 我們先教機器做某一件事情,比如說學會做語音辨識,那它就會做語音辨識了;
- 接下來你再教它第二個任務,教它做影像辨識,它就會做影像辨識;
- 接下來你再教它做第三個任務,也許是翻譯,它就會做影像辨識加語音辨識加翻譯了。
难点——灾难性遗忘
那你讓機器依序學的時候,它就是學了新的東西就忘了舊的東西。
它就好像是一個腦袋有洞的人,新的任務進來,舊的東西就掉出去了,它永遠學不會多個技能。
Multi-Task Training ⇒ upper bound of LLL
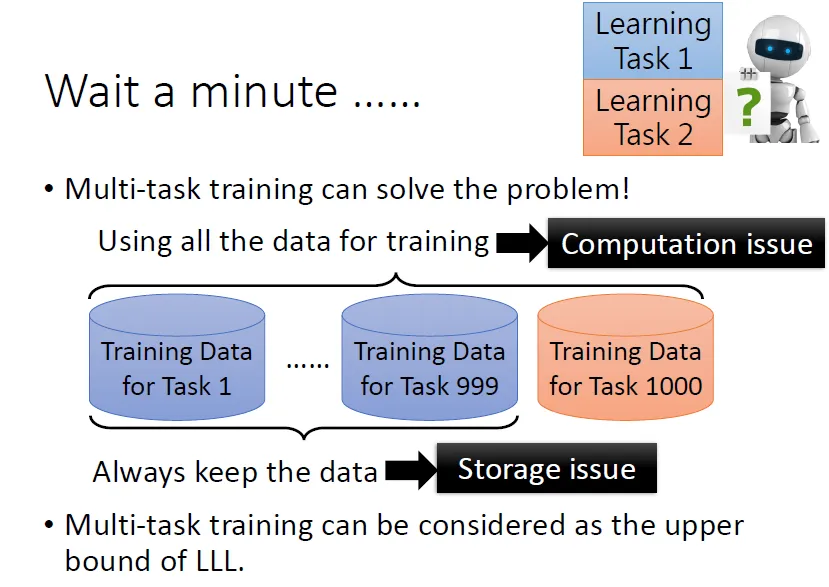
让机器同时利用多个任务的数据进行学习的训练方法成为Multi-task training,这种训练方法看似可行,但是需要机器把之前所学任务的所有训练数据再学习新任务时一起从头学一遍,会带来很大的时间代价和空间代价,这个代价是难以负担的。
雖然當任務多的時候,multi-task training這是一個不切實際的做法,但是它确实可以讓機器學會多個任務,因而被视为Life Long Learning 的 Upper Bound,是 Life Long Learning 沒有辦法超越的結果。
Train a model for each task(一个任务一个模型)的问题
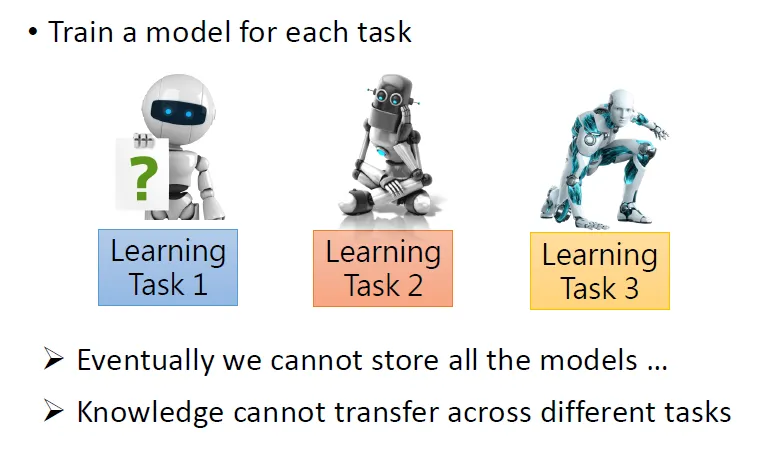
问题:
- 模型过多无法存储
- 信息、数据不能在不同的任务间迁移
Selective Synaptic Plasticity(突触的可塑性)/Regularization based Approach
只有部分的連結是有可塑性的,有一些連結必須被固化。
每一個參數,對我們過去學過的任務的重要性是不一樣的有一些參數。在學新的參數的時候,那些舊的、重要的參數,值盡量不要變;新的任務只去改那些對過去的任務不重要的參數就好。
改写Loss
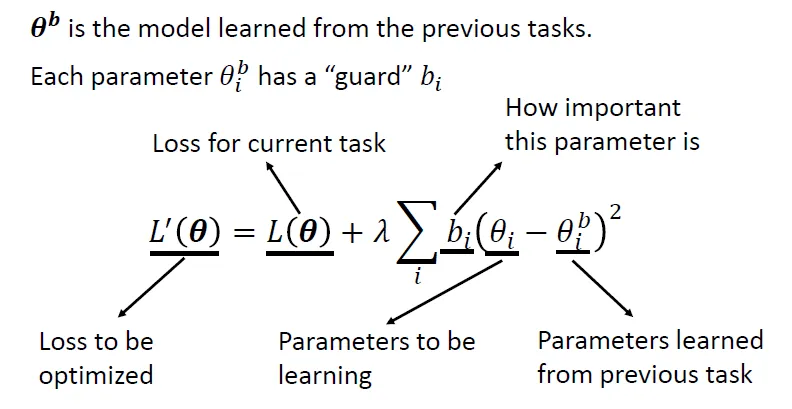
\(\theta^b\)表示从之前任务中学到的参数。
对于Loss,在原来的Loss后再增加一项,希望新学到的 \(\theta_i\) 与 \(\theta^b_i\) 尽量靠近,并为每一个参数设置一个“守卫”\(b_i\)来说明“多强烈地”希望二者能够靠近,也就是原来的参数有多么重要。
- \(b_i\)=0, 对 \(\theta_i\) 没有限制⇒会发生灾难性遗忘
- \(b_i=\infin\),\(\theta_i\)与之前任务的参数\(\theta_i^b\)严格相等⇒顽固,旧的任务不遗忘、但新的任务学不好
如何设定“守卫”\(b_i\)?⇒人为设定,根据参数的“重要性”
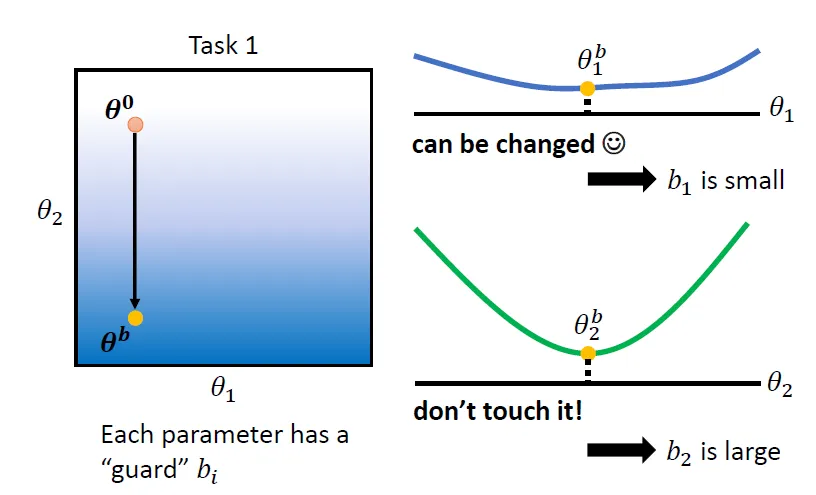
在訓練完一個模型,得到 θb 之後,看看 θb 裡面每一個參數對這個任務的影響。
舉例來說,
- θb 在 θ1 這個方向做一下移動,好像對 Loss 沒有什麼影響,就知道說θ1 沒有很重要,所以我們就可以給 θ1 比較小的 b 的值,也就是 \(b_1\) 设的小一点;
- 當我們改變 θ2 的值的時候,對 Loss 的影響是大的,代表說 θ2 对 Task 1 是重要的參數,所以你要把 θ2 的 b 設得大一點,也就是 \(b_2\) 设的大一点,尽量让这个参数不要发生大的变化。
Gradient Episodic Memory (GEM)
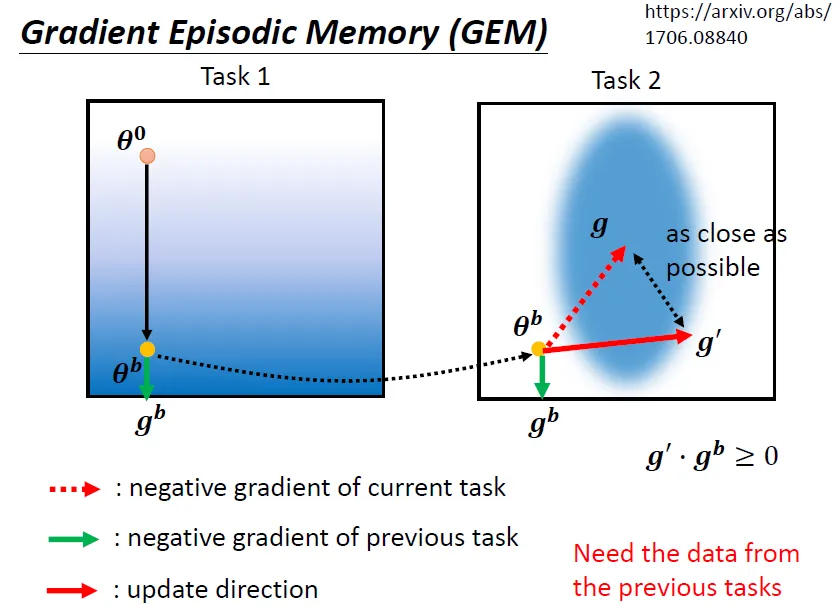
方法:不是在參數上做限制,而是在 Gradient Update 的方向上做限制
- 計算任務二的 Gradient需要判断要不要按照任務二算出來的 Gradient 的方向 Update 參數。
- 在 Update 參數之前,先算一下這一個參數在任務一上做 Update 的方向\(g^b\)
- 如果两个任务上的方向“不一致”(Inner Product <0),就要修改此时要更新的\(g\),得到\(g'\)满足:
- \(g\)与\(g'\)尽可能靠近
- \(g'\)与\(g^b\)夹角是锐角(Inner Product >0)
- 利用\(g'\)更新参数,可以减轻灾难性遗忘的问题
Additional Neural Resource Allocation Memory
改变使用在每一个任务里面的Neural 的 Resource
Progressive Neural Network
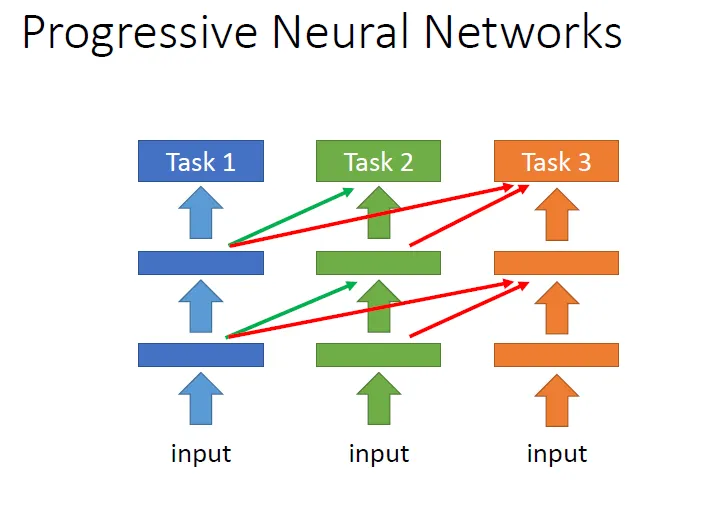
每一个任务都重新训练一些额外的neural,从而保证之前的任务的模型参数完全不会被改变。
问题:
当模型大小的增长过快时,仍然难以存储。
PackNet
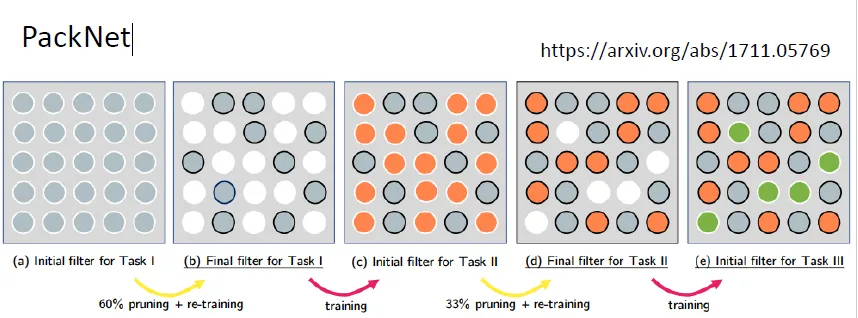
一开始就分配一个较大的模型,每个任务只允许使用某一些参数;要求在先期的任务中,模型里的参数不要里面被全部用完,方便后续任务继续使用。
Progressive Neural Network+ PackNet ⇒CPG
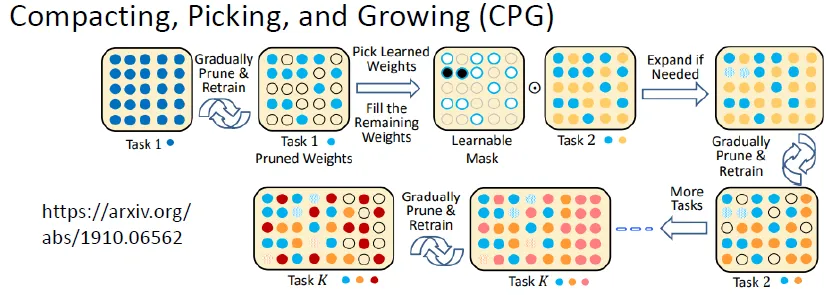
Model既可以增加新的參數,每训练一个新的任务时,又都只保留部分的參數可以拿來做訓練。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号