

面向对象之继承
动静态方法
类中定义的函数有多种特性
class Student:
school_name = '羊村'
# 类中直接定义的函数默认绑定给对象,类调用时需要几个参数就传几个参数,对象调用时会将自己当做第一个参数传进去
def func1(self):
print('喜羊羊牛掰噶拉斯')
# 被@classmethod修饰的函数,默认绑定给类,类调用时第一个参数就是类本身,对象调用时会将产生该对象的类当做第一个参数传进去
@classmethod
def func2(cls):
print('舔狗沸羊羊')
# 普通的函数,无论是类还是对象调用都需要手动传参
@staticmethod
def func3(a):
print('羡慕懒洋洋')
obj = Student()
obj.func1() # 喜羊羊牛掰噶拉斯
Student.func1(1) # 喜羊羊牛掰噶拉斯
Student.func2() # 舔狗沸羊羊
obj.func2() # 舔狗沸羊羊
Student.func3(1) # 羡慕懒洋洋
obj.func3(2) # 羡慕懒洋洋
面向对象中继承的概念
面向对象三大特性:封装、继承、多态
1.继承的含义
表示资源的从属关系
eg:爸爸有一个亿,儿子啥都没有,但是儿子继承了爸爸后就可以使用这一个亿
编程中也一样,A类有数据和功能,B类没有,那么B类继承了A类后就拥有了A类的数据和功能
2.继承实操
class Father:
money = '我有一个亿'
class son(Father):
pass
1.继承类(son)我们称之为子类、派生类
2.被继承类(Father)我们称之为父类
3.子类定义时要继承谁就在括号内填写谁的名字, 继承多个时括号内直接填写多个类名用逗号隔开即可
3.继承的本质
继承的本质可以参考类和对象
对象是数据与功能的结合体
类是多个对象的相同数据和功能的结合体
父类是多个子类的相同数据和功能的结合体
# 都是为了节省代码!!!
继承本质可以分为两部分
抽象:把多个类相同的东西抽出去组成一个新的类
继承:多个类继承刚刚抽取出的新类
名字的查找顺序
1.不继承情况下名字的查找顺序
class A:
a = 1
obj = A()
obj.a = 2
print(obj.a) # 2
不继承情况下名字的查找顺序
1.先从自己的名称空间查找
2.找不到再去产生该对象的类中查找
3.如果类里面也没有,报错
2.单继承情况下名字的查找顺序
class A:
a = 1
class B(A):
obj = B()
print(obj.a) # 1
单继承情况下名字的查找顺序可以参考不继承情况下名字的查找顺序
先找对象自己,再找产生对象的类,最后找父类,都没有就报错
3.多继承情况下名字的查找顺序
class F1:
a = 1
class F2:
a = 2
class F3:
a= 3
class A(F1, F2, F3):
pass
obj = A()
print(obj.a) # 1
正常情况下是按照括号内类名的填写顺序从左往右查找
情况一:
class S1(F1):
a = 4
class S2(F2):
a = 5
class S3(F3):
a= 6
class B(S1, S2, S3):
pass
obj1 = B()
print(obj1.a)
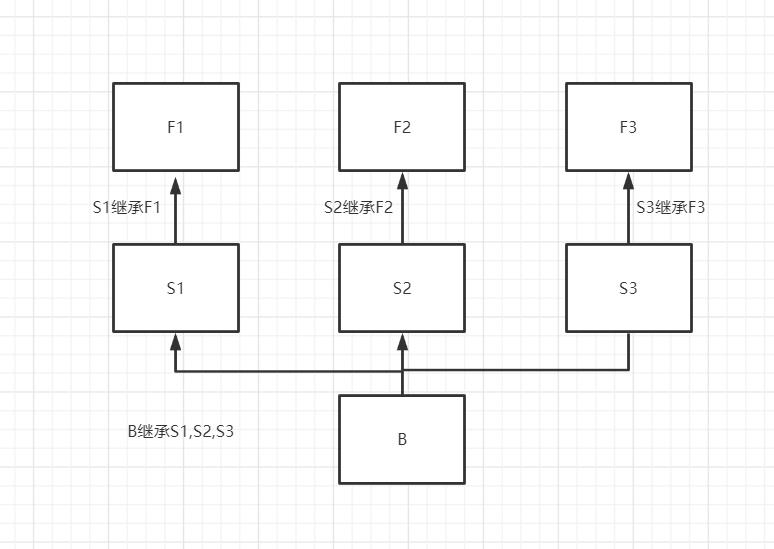
此种情况称之为非菱形继承,它的查找顺序是(关系图见图一)
obj1 > B > S1 > F1 > S2 > F2 > S3 > F3
非菱形继承的特点是深度优先(从左往右每条分支都走完再去下一条分支)
情况二:菱形继承
class G:
a = 7
class F1(G):
a = 1
class F2(G):
a = 2
class F3(G):
a= 3
class S1(F1):
a = 4
class S2(F2):
a = 5
class S3(F3):
a= 6
class A(S1, S2, S3):
pass
obj = A()
print(obj.a)
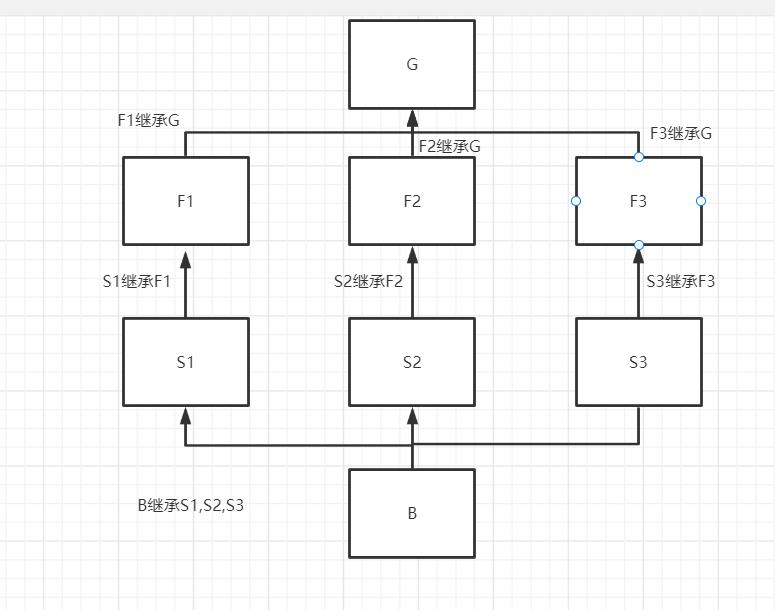
此种情况称之为菱形继承,它的查找顺序是(关系图见图二)
obj1 > B > S1 > F1 > S2 > F2 > S3 > F3 > G
菱形继承的特点是广度优先,闭环的点G最后才会去找
图一
图二
经典类与新式类
经典类:不继承object或者其子类的类
新式类:继承object或者其子类的类
在python2中有经典类和新式类
在python3中只有新式类(所有类默认都继承object)
派生方法
子类基于父类的某个方法做了扩展
class A:
def __init__(self, a, b, c)
self.a = a
self.b = b
self.c = c
class B(A):
def __init__(self, a, b, c, d)
super().__init__(a, b, c)
self.d = d
A类中定义了一个方法,但是这个方法只能添加a,b,c三个数据,现在需要多添加一个数据d,原本A类中的方法不能改
所以就用到了派生方法
在不改变原方法的基础上做扩展
派生方法实战
我们之前说过派生方法就是对继承类里面方法的衍生,但是具体如何使用不知道,那么我们可以通过下面的例子来具体了解一下
import json
import datetime
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'json'
}
res = json.dumps(d)
print(res)
# 报错 raise TypeError(f'Object of type {o.__class__.__name__} '
# TypeError: Object of type date is not JSON serializable
不是所有的数据类型都可以被序列化,能够被序列化的只有下面的列表左边的数据类型
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
那么上面的代码如果想执行可以自己手动转
d = {
't1': str(datetime.date.today()),
't2': str(datetime.datetime.today())
}
还有一种方法就是派生方法
根据错误提示我们可以查看dumps源码,发现cls参数默认传的是JsonEncoder,查看该类源码发现default方法是报错的发起者,那么我们就可以继承并重写default方法
class MyJsonEncoder(json.JSONEncoder):
def default(self, o):
"""
:param o: 接收无法被序列化的数据
:return: 返回可以被序列化的数据
"""
if isinstance(o, datetime.datetime): # 判断是否是datetime类型 如果是则处理成可以被序列化的类型
return o.strftime('%Y-%m-%d %X')
elif isinstance(o, datetime.date):
return o.strftime('%Y-%m-%d')
return super().default(o) # 最后还是调用原来的方法 防止有一些额外操作没有做
res = json.dumps(d, cls=MyJsonEncoder)
print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号