淘宝登陆对selenium爬虫的封杀和反爬
众所周知目前使用selenium打开浏览器访问淘宝,会弹出登录页面,不管你是手动还是自动登录一律都是在滑块验证码时不通过,今天花了几个小时分析了一下,也只是对其整体有了个认识
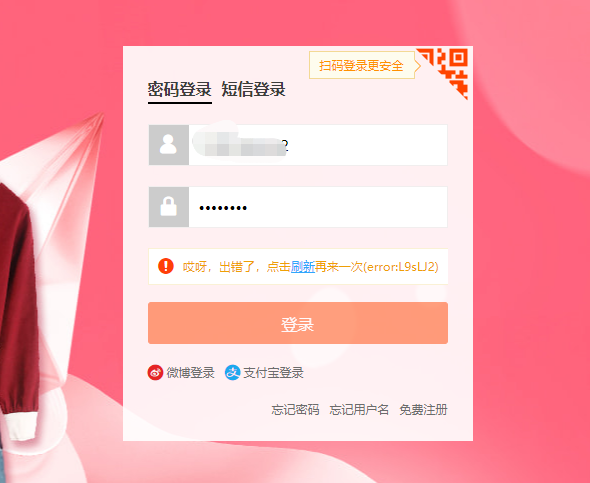
总体上淘宝的反爬虫思路是:基于用户身份的ua算法,来识别浏览器是正常状态还是非正常状态。
ua:UA的中文翻译是用户代理,全称是User Agent,简单来说是终端的环境信息如:Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1
它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
但是这只是一般意义上的ua参数,实际使用中ua代表了一个终端的标识,ID代表了一个用户的标识,随着网络安全的深入,ua已经不再是一串环境的信息字符串,而是开发者单独发开出来的一套甄别终端的算法,成为了单独执行的js文件
当访问淘宝登录界面会发送一个POST请求,这个post请求中有一个关键信息ua

ua参数很长一串,看似像RSA加密过的,并且这个参数时刻变化着,两次生成的ua都不相同:
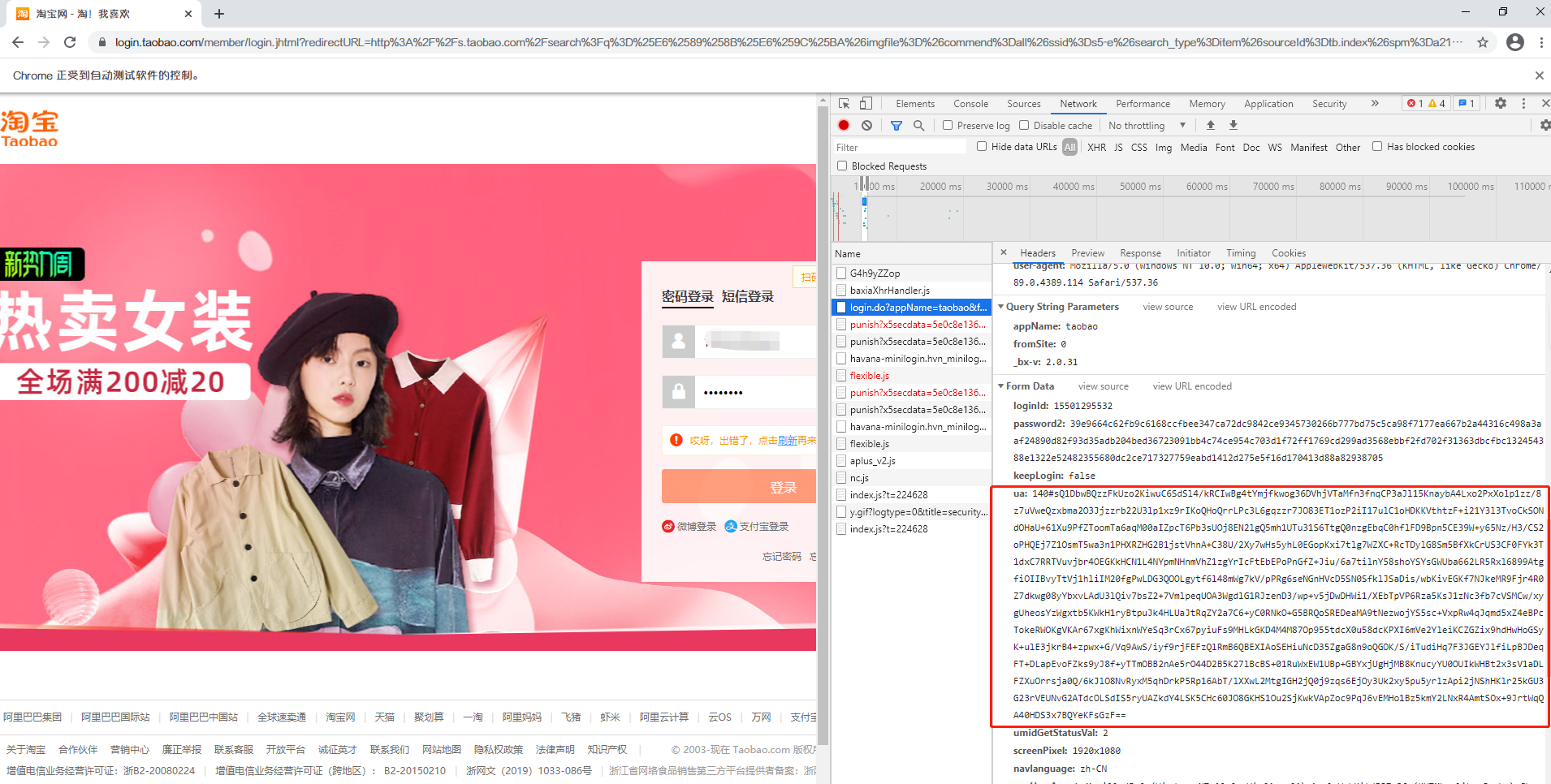 只有前几位是相同的,其他完全不同,这个post请求中有一个关键信息ua,至于ua怎么生成目前还未分析出,他的出处在全局对象window[UA_Opt.LogVal]、或者window["_n"],并且每次输出都不一样。
只有前几位是相同的,其他完全不同,这个post请求中有一个关键信息ua,至于ua怎么生成目前还未分析出,他的出处在全局对象window[UA_Opt.LogVal]、或者window["_n"],并且每次输出都不一样。

浏览器window对象,他是出于一个私有属性_n,但是怎么做到每次输出的值都不一样的。
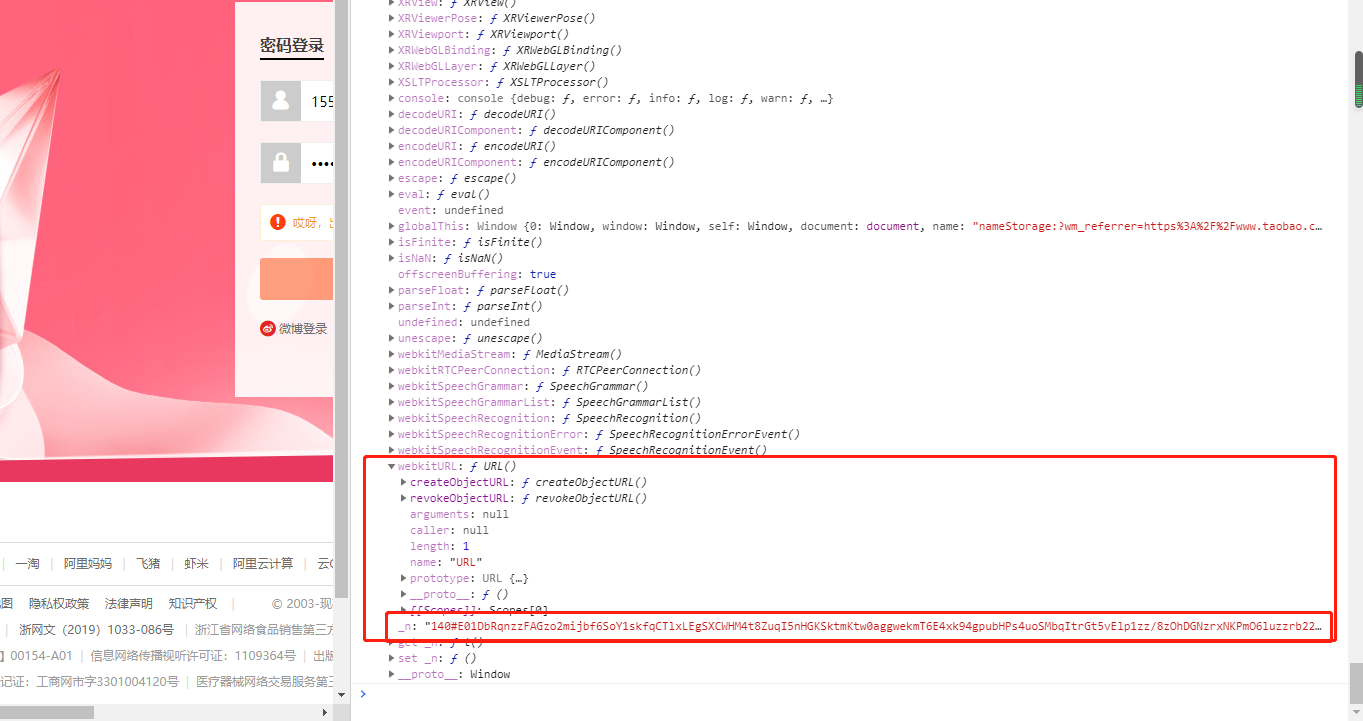
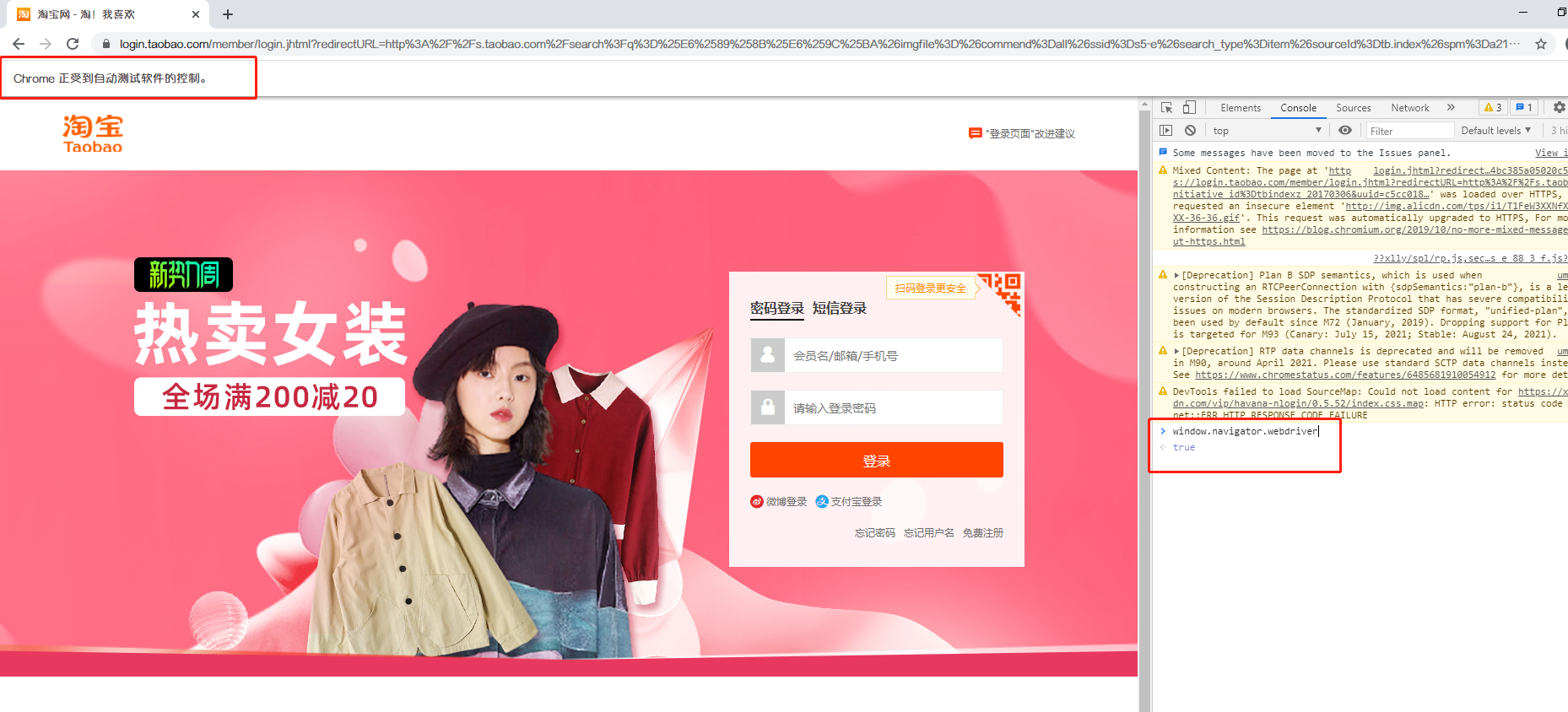
使用正常浏览器打开浏览器的,window.navigator.webdriver这个值为undefined,在JavaScript中undefined为未定义,即该值不存在,而false表示一布尔值。
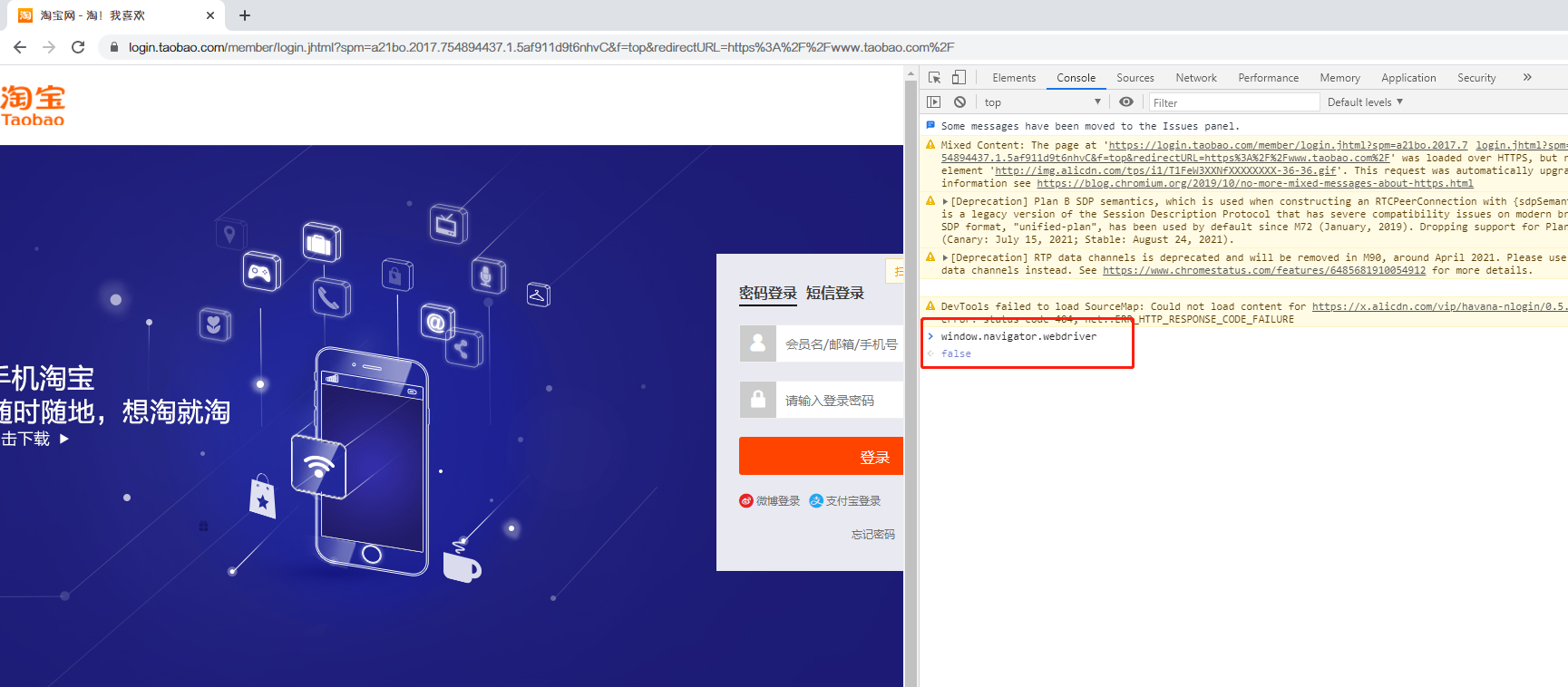
而使用selenium打开的浏览器,这个值为true
所以淘宝就是根据这个值进行滑块的弹出和不弹出,当拖动滑块的时候,会有一个滑块验证的请求,请求中有个参数t

这个t参数就是上面所提到的ua,也就是在验证滑块是否正确的时候淘宝后台还会对ua验证一番,检验是否为正确的标识,一切selenium打开的浏览器里面'browser': {'ie': False, 'chrome': True, 'webdriver': True},当然webdriver是比较关键的参考标准,除此还有几十个其他异于正常浏览器的属性,很明显这些信息被加密在ua参数之中。淘宝后台在收到滑块验证信息的时候,会同时对ua经行验证,所有含有webdriver=True的验证都会被返回code=300。
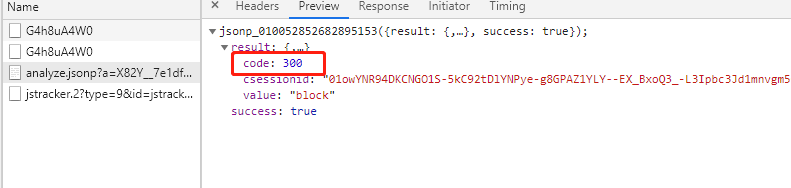
现在我们大致就清楚了淘宝对selenium的检测:通过本地的js算法生成ua,ua里面含有浏览器信息,甚至含有当前地址,当输入完账号后会把账号和ua一起post给服务器,服务器解析ua后通过智能算法识别是否是常用登陆地、常用浏览器、环境有无异常,selenium打开的浏览器是异常浏览器,一定会返回滑块验证,当完成验证后会再把ua和滑动的轨迹发给后台,后台在检测ua,一旦含有异常信息就返回code=300,验证失败。
那么问题来了,怎么来避开滑块验证呢?
一、WebDriver规范
根据WebDriver规范(https://w3c.github.io/webdriver/#x4-interface)的描述,WebDriver定义了一个标准方法,以便于文档(document)判断当前浏览器处于自动化控制之中。
这个方法就是检测window.navigator.webdriver的值,正常情况下其值为undefined,自动化控制下为true。注意,正常情况下不是false,在JavaScript中undefined为未定义,即该值不存在,而false表示一布尔值。
附上规范原文:
The webdriver-active flag is set to true when the user agent is under remote control. It is initially false.
Defines a standard way for co-operating user agents to inform the document that it is controlled by WebDriver, for example so that alternate code paths can be triggered during automation.
二、如何来解除这个规范呢
旧版本
在版本79.0.3945.16之前,可用如下方法:
from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument("start-maximized") options.add_experimental_option("excludeSwitches", ["enable-automation"]) options.add_experimental_option("useAutomationExtension", False) driver = webdriver.Chrome(options=options) driver.get("YOUR_URL") # 在控制台中验证window.navigator.webdriver的值为undefined。 driver.quit()
新版本
在版本79.0.3945.16之后,ChromeDriver修正了这一“问题”。
根据注记原文:
Resolved issue 3133: window.navigator.webdriver is undefined when "enable-automation" is excluded in non-headless mode (should be true) [Pri-2]
如何破解?
execute_cdp_cmd函数来帮忙!cdp即Chrome DevTools Protocal,Chrome开发者工具协议。
通过该函数在文档加载前注入一段js代码以消去webdriver值。
from selenium import webdriver driver = webdriver.Chrome() script = ''' Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) ''' driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": script}) driver.get("YOUR_URL") # 在控制台中验证window.navigator.webdriver的值为undefined。 driver.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号