八、MySQL 字符集、索引概述介绍、索引分类 、explain详解、索引的建立、MySQL存储引擎
一、字符集
1.字符集介绍
字符集:是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等
#最早的字符集:ASCII码
中国的字符集:gbk,utf8,utf8mb4,gbk2312,....
日本:shift-JIS
韩国:Euc-kr
万国编码:Unicode字符集
#数据库常用的字符集
gbk: 一个汉字占用2个字节
utf8: 一个汉字占用3个字节
utf8mb4: 一个汉字占用4个字节
#字符集修改
字符集有一个包含关系,修改时要注意小的范围可以修改为大范围的字符集
#数据库查看字符集
mysql> show charset;
2.校验规则
#查看校验规则
mysql> show collation;
| latin1_bin |
| latin1_general_ci |
| latin1_general_cs |
#校验规则区别
1.ci结尾的校验规则不区分大小写
2.bin和cs结尾的校验规则区分大小写
1.什么是字符集
#常用的字符集
gbk: 两字节
utf8:三个字节
utf8mb4:四个字节
#字符集转换
只有包含关系的字符集能够互相转换
#查看支持的字符集
mysql> show charset;
2.校验规则
#查看校验规则
mysql> show collation;
#检验规则种类
| latin1_bin
| latin1_general_ci
| latin1_general_cs
#区别
bin和cs区分大小写
ci不区分大小写
3.统一字符集
#1.xshell字符集
#2.linux系统的字符集
#永久修改:
1)centOS7:
[root@db01 ~]# vim /etc/locale.conf
LANG="zh_CN.UTF-8"
2)centOS6:
[root@db01 ~]# vim /etc/sysconfig/i18n
LANG="zh_CN.UTF-8"
#临时修改:
[root@db01 ~]# LANG="zh_CN.UTF-8
#3.cmake阶段指定字符集
#使用utf8字符集
-DDEFAULT_CHARSET=utf8
#校验规则
-DDEFAULT_COLLATION=utf8_general_ci
#4.配置文件可以修改默认的字符集
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
character-set-server=utf8
#5.创建数据库时指定字符集
mysql> create database zifuji3 charset gbk;
#6.在库下建表
在库下面建表,表的字符集随着库走,不走默认与cmake的字符集
#7.建表时指定字符集
mysql> create table test2(id int) charset utf8mb4;
#8.修改已有表的字符集
mysql> alter table test charset utf8mb4;
二、索引概述
1.什么是索引
1.索引就好比一本书的目录,它能让你更快的找到自己想要的内容。
2.让获取的数据更有目的性,从而提高数据库检索数据的性能。
2.索引的种类
1.BTREE: BTREE B+TREE B*TREE
2.HASH:HASH索引(只有memery存储引擎支持):将一句话按照逻辑关系,拆成好几个部分。
3.FULLTEXT:全文索引
4.RTREE:R树索引:R树是基于磁盘的索引结构,是B树(一维)在高维空间的自然扩展,按照坐标的经纬度。利用空间实体外接矩形建立空间索引
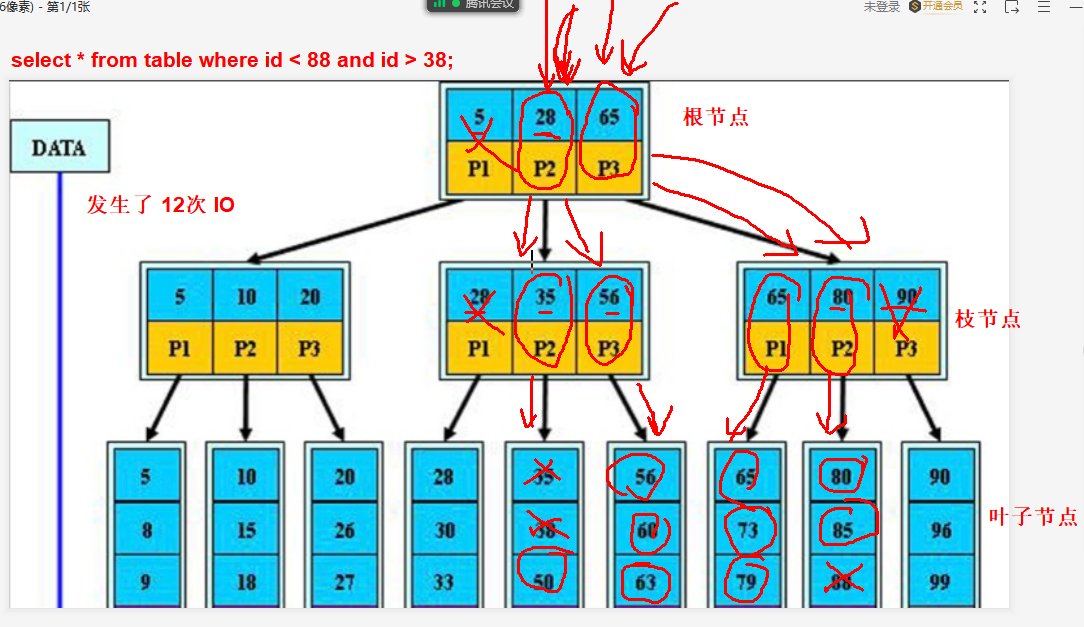
1)BTREE树索引
每次检索都得从跟节点重新发起。如图,共发起12次请求线程。
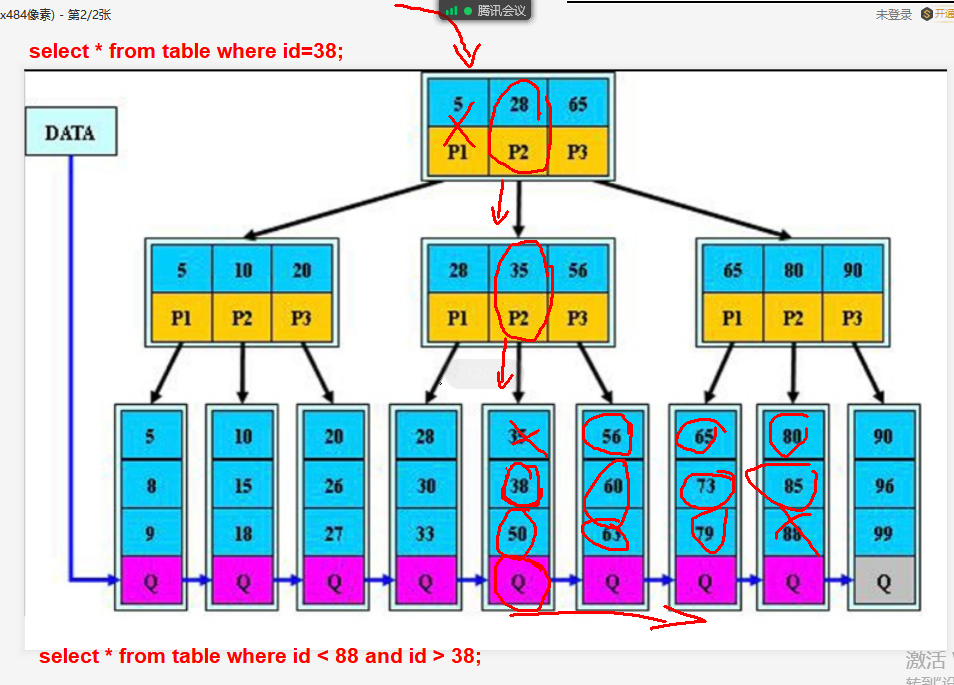
2)B+TREE树索引
在叶子节点和枝节点都增加指针,
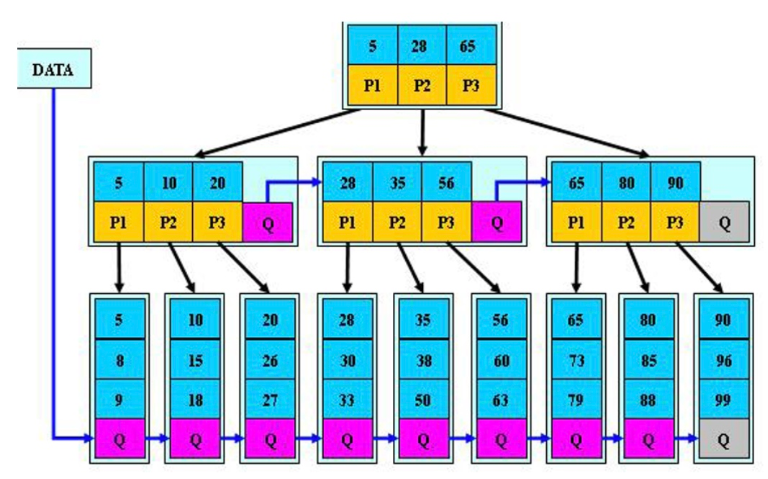
3)B*TREE树索引
在叶子节点增加指针,直接经过三次检索,直接在磁盘上跳转。避免重新从根节点再次发起检索。如图只需发起三次请求线程。
三、根据算法索引的分类
索引建立在表的列上(字段)的。
在where后面的列建立索引才会加快查询速度。
pages <---- 索引(属性)<---- 查数据。
1.主键索引(聚集索引)
#创建主键索引
1.建表时创建主键索引
1)方法1:
mysql> create table student(id int unsigned primary key auto_increment comment '学生id');
2)方法2:
mysql> create table student1(id int unsigned NOT NULL AUTO_INCREMENT COMMENT '学生id', PRIMARY KEY (id));
2.已经有的表,添加主键索引
#建表
mysql> create table student2(id int unsigned NOT NULL COMMENT '学生id',name varchar(10) NOT NULL COMMENT '学生姓名');
#添加主键索引
mysql> alter table student2 add primary key pri_key(id);
2.唯一建索引
1)创建表时添加唯一键索引
1.方法1:
mysql> create table student3(id int unsigned NOT NULL unique key COMMENT '学生id');
2.方法2:
mysql> create table student4(id int unsigned NOT NULL AUTO_INCREMENT COMMENT '学生id', unique key (id));
2)已经有的表,添加唯一键索引
#建表
mysql> create table student5(id int unsigned NOT NULL COMMENT '学生id',name varchar(10) NOT NULL COMMENT '学生姓名');
#添加主键索引
mysql> alter table student2 add unique key uni_key(id);
3)如何确定哪一列可以创建唯一键
#1.查看表中某一字段的总数据
mysql> select count(name) from country;
+-------------+
| count(name) |
+-------------+
| 239 |
+-------------+
1 row in set (0.00 sec)
#2.去重查看表中某一列数据
mysql> select distinct(name) from country;
mysql> select distinct(count(name)) from country;
+---------------+
| (count(name)) |
+---------------+
| 239 |
+---------------+
1 row in set (0.00 sec)
#3.查看以上两个值是否完全相同
#4.如果相等则可以创建唯一建索引
mysql> alter table country add unique key uni_key(name);
4)函数
now() #当前时间的函数
database() #查看当前库的函数
count() #查看数据总数的函数,count(主键)
distinct() #去重数据的函数
PASSWORD() #数据库密码加密函数
max() #取某一列最大值
min() #取某一列最小值
avg() #取某一列平均值
sum() #取某一列总数
3.普通索引(辅助索引)
1)创建索引
1.方法1:
mysql> alter table city add index index_key(name);
2.方法2:
mysql> create index idx_key on city(District);
4.全文索引
1)建表时创建全文索引
mysql> create table xiaoshuo(id int,bookname varchar(20),author varchar(10),content text,FULLTEXT(content));
2)插入数据
mysql> insert into xiaoshuo values('1','西游演义','lhd','上回书说到张飞长坂坡三打白骨精救宋江');
Query OK, 1 row affected (0.00 sec)
mysql> select * from xiaoshuo;
+------+--------------+--------+--------------------------------------------------------+
| id | bookname | author | content |
+------+--------------+--------+--------------------------------------------------------+
| 1 | 西游演义 | lhd | 上回书说到张飞长坂坡三打白骨精救宋江 |
+------+--------------+--------+--------------------------------------------------------+
1 row in set (0.00 sec)
3)使用索引查询数据
mysql> select * from xiaoshuo where match(content) against('上回书说到张飞长坂坡三打白骨精救宋江');
+------+--------------+--------+--------------------------------------------------------+
| id | bookname | author | content |
+------+--------------+--------+--------------------------------------------------------+
| 1 | 西游演义 | lhd | 上回书说到张飞长坂坡三打白骨精救宋江 |
+------+--------------+--------+--------------------------------------------------------+
1 row in set (0.00 sec)
5.查看索引
1.方式1:
mysql> desc city;
+-------------+----------+------+-----+
| Field | Type | Null | Key |
+-------------+----------+------+-----+
| ID | int(11) | NO | PRI | #主键索引
| Name | char(35) | NO | MUL | #普通索引
| CountryCode | char(3) | NO | UNI | #唯一键索引
| District | char(20) | NO | MUL |
| Population | int(11) | NO | |
+-------------+----------+------+-----+
2.方式2:
mysql> show index from city;
6.删除索引
mysql> alter table city drop index idx_key;
四、根据设置方法分类
1.创建索引时会对数据进行重新排序
2.建立索引会占用磁盘空间,所以索引不是越多越好
3.在同一列避免创建多个索引
4.避免在大数据的列创建索引,如果非要创建就创建前缀索引
1.前缀索引
#创建根据District列前三个字符进行排序的索引
mysql> alter table city add index District_key(District(3));
#查看表的索引
mysql> show index from city;
2.联合索引
1)案例
#1.创建一个库
mysql> create database xiangqin;
#2.创建一个表
mysql> use xiangqin;
mysql> create table user(id int,name varchar(10),sex enum('male','fmale'),age tinyint,weight int,height int,money int,look varchar(10));
#3.插入数据
mysql> insert into user values('1','qiudao','male','38','180','120','-100000','very ugly'),('2','dawei','male','18','130','182','10000','Handsome'),('3','bingbing','fmale','30','110','170','100000000','beautiful');
#4.查看数据
mysql> select * from user;
+------+----------+-------+------+--------+--------+-----------+-----------+
| id | name | sex | age | weight | height | money | look |
+------+----------+-------+------+--------+--------+-----------+-----------+
| 1 | qiudao | male | 38 | 180 | 120 | -100000 | very ugly |
| 2 | dawei | male | 18 | 130 | 182 | 10000 | Handsome |
| 3 | bingbing | fmale | 30 | 110 | 170 | 100000000 | beautiful |
+------+----------+-------+------+--------+--------+-----------+-----------+
3 rows in set (0.00 sec)
#5.建立联合索引
mysql> alter table user add index index_all(sex,age,money,look);
#6.查看索引
mysql> show index from user;
2)注意
where sex='' and age='' and money='' and look='';
index(sex,age,money,look)
特点:前缀生效特性
#可以走索引
sex
sex,age
sex,age,money
sex,age,money,look
#部分走索引:
只要包含联合索引的第一个条件的查询语句都部分走索引
#不走索引的情况
age,money,look
age,look
money,look
money look
age,sex ...
#原则:把最常用来做为条件查询的列放在最前面
五、explain详解
1.explain语法
mysql> explain select * from user where age='30' and money > '1000000' and look='beautiful';
#1.查看中国和美国的城市人口数量
mysql> select name,population from city where countrycode='CHN' or countrycode='USA';
mysql> select name,population from city where countrycode in ('CHN','USA');
mysql> select name,population from city where countrycode='CHN' union all select name,population from city where countrycode='USA';
#2.查看三个命令的执行计划
mysql> explain select name,population from city where countrycode='CHN' or countrycode='USA';
mysql> explain select name,population from city where countrycode in ('CHN','USA');
mysql> explain select name,population from city where countrycode='CHN' union all select name,population from city where countrycode='USA';
#3.查询结果注释
id #执行顺序
table #查询的表
type #查询使用的类型
possible_keys #可能使用的索引列
key #真正实用的索引列
key_len #索引长度,前缀索引的长度
ref #查询级别是否达到ref级别
rows #查询数据的数量
Extra
Using temporary
Using filesort #使用了默认的文件排序(如果使用了索引,会避免这类排序)order by
Using join buffer #使用了 join on
Using index condition #使用了索引
2.group by扩展
#1.插入一个表
mysql> create table jixiao(id int,name varchar(10),money int,product varchar(10));
#2.插入数据
mysql> insert into jixiao values('1','邱导','100000','汽车'),('2','laocai','80000','汽车'),('3','dawei','700000','房地产'),('4','laozhao','800000','房地产');
#3.查询不同行业总绩效
mysql> select sum(money),product from jixiao group by product;
+------------+-----------+
| sum(money) | product |
+------------+-----------+
| 1500000 | 房地产 |
| 180000 | 汽车 |
+------------+-----------+
2 rows in set (0.00 sec)
#4.查询不同行业绩效最高的那个人
3.查询数据的方式
1)全表扫描
#1.什么是全表扫描?
读取整个表的数据,使用explain语句查询执行计划中,type列的值是ALL
#2.什么时候使用全表扫描
1)查询表中所有数据的时候
mysql> explain select * from city;
2)没有走索引的时候
mysql> explain select name,population from city where population='92020';
2)索引扫描
#从上到下查询速度依次越来越快
1.index #全索引扫描
mysql> explain select name from city;
2.range #范围查询使用该级别,但是当查询数据量过大的时候不走索引
mysql> explain select name,population from city where countrycode='CHN' or countrycode='USA';
mysql> explain select name,population from city where population > 3000000;
3.ref #使用精确查询
mysql> explain select name,population from city where countrycode='CHN';
4.eq_ref #使用join on时可能出现该级别
mysql> explain select city.name,city.population,country.name from country join city on city.countrycode=country.code where city.population < 100;
5.const #当查询条件是主键或者唯一键的时候
mysql> explain select * from city where id='1';
6.system #跟const平级,当查询的数据所在表数据量很小的时候,并且查询条件使用主键或者唯一键
7.null #当不用读取数据库数据的时候
mysql> explain select max(population) from city;
六、索引的建立
1.建立索引的原则
1.如果可以建立唯一键索引,就建立唯一键索引
2.为经常需要排序、分组和联合操作的字段建立索引
3.为常作为查询条件的字段建立索引
4.尽量使用前缀索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索
会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度
5.限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
6.删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
2.不走索引的情况总结
1)没有查询条件,或者查询条件没有索引
#查询所有数据
mysql> explain select * from city;
#删除索引,然后查询
mysql> alter table city drop index District_key;
mysql> explain select * from city where District='heilongjiang';
2)查询结果集是原表中的大部分数据,应该是15%以上
#表中数据一共4079,查询数据539条,走索引 13.2%
mysql> explain select * from city where population > 500000;
#表中数据一共4079,查询数据737条,不走索引 18%
mysql> explain select * from city where population > 400000;
3)索引坏了
反复插入删除容易损坏索引
4)查询条件使用了运算符号
#运算符号如果在等号左边,则不走索引
mysql> explain select * from city where id-1=2;
#运算符号如果在等号右边,则走索引
mysql> explain select * from city where id=2+1;
5)隐式转换
# 1.建表
mysql> create table phone(id int,name varchar(10),number varchar(20));
#2.建立索引
mysql> alter table phone add unique key uni_key(number);
#3.插入数据
mysql> insert phone values(1,'警察局',110),(2,'消防',119),(3,'医院',120);
#4.测试查询数据是否走索引
1)不走索引
mysql> explain select * from phone where number=120;
2)走索引
mysql> explain select * from phone where number='120';
#因为120存到数据库中的字段是字符类型,那么查询时字符类型必须加引号
6)使用 like + % 的模糊匹配,当条件以%开头时
#1. % 在最前面时不走索引
mysql> explain select * from city where countrycode like '%H';
mysql> explain select * from city where countrycode like '%H%';
#2. % 在后面时走索引
mysql> explain select * from city where countrycode like 'H%';
#3. % 在中间时也走索引
mysql> select * from city where countrycode like 'C%N';
7)联合索引,插叙条件不包含建立联合索引排第一的字段时
#0.查看联合索引
mysql> show index from user;
+-------+------------+-----------+--------------+-------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name |
+-------+------------+-----------+--------------+-------------+
| user | 1 | index_all | 1 | sex |
| user | 1 | index_all | 2 | age |
| user | 1 | index_all | 3 | money |
| user | 1 | index_all | 4 | look |
+-------+------------+-----------+--------------+-------------+
#1.只要包含排第一的字段条件,就走索引
mysql> select * from user where sex='fmale' and age='30';
mysql> explain select * from user where age='30' and money='100000000' and look='beautiful' and sex='fmale';
#2.不包含建立联合索引排第一的字段时,不走索引
mysql> explain select * from user where age='30' and money='100000000' and look='beautiful';
8) <> ,not in 不走索引
mysql> explain select * from phone where number not in (110);
mysql> explain select * from phone where number <> '110';
七、MySQL存储引擎
1.连接层
2.sql层
3.存储引擎层
1)接收sql层传来的sql语句
2)与磁盘交互获取数据
#存储引擎就是mysql的文件系统
1.MySQL提供的存储引擎
1)MySQL 提供以下存储引擎:
1.InnoDB
数据经常添加、删除、修改、查询,使用该引擎
2.MyISAM
只对数据进行查询和添加
3.MEMORY
支持hash索引
4.ARCHIVE
5.FEDERATED
6.EXAMPLE
7.BLACKHOLE
8.MERGE
9.NDBCLUSTER
10.CSV
2)第三方存储引擎:
1.MySQL当中插件式的存储引擎类型
2.MySQL的两个分支
1)perconaDB
2)mariaDB
3)查看存储引擎
#查看当前MySQL支持的存储引擎类型
mysql> show engines
#查看innodb的表有哪些
mysql> select table_schema,table_name,engine from information_schema.tables where engine='innodb';
#查看myisam的表有哪些
mysql> select table_schema,table_name,engine from information_schema.tables where engine='myisam';
#查看某个表的信息
mysql> select * from tables where TABLE_NAME='city'\G
*************************** 1. row ***************************
TABLE_CATALOG: def #表的注册信息
TABLE_SCHEMA: world #表所在的库
TABLE_NAME: city #表名字
TABLE_TYPE: BASE TABLE #表的类型
ENGINE: InnoDB #存储引擎
VERSION: 10 #默认版本
ROW_FORMAT: Compact #行模式
TABLE_ROWS: 4188 #查询数据的量
AVG_ROW_LENGTH: 97 #行数据的平均长度
DATA_LENGTH: 409600 #数据长度
MAX_DATA_LENGTH: 0 #最大数据长度
INDEX_LENGTH: 131072 #索引的数据长度
DATA_FREE: 0 #空间碎片
AUTO_INCREMENT: 4080 #自增属性的值到了多少
CREATE_TIME: 2020-10-28 18:27:42 #创建时间
UPDATE_TIME: NULL #修改时间
CHECK_TIME: NULL #检查时间
TABLE_COLLATION: latin1_swedish_ci #表的字符集
CHECKSUM: NULL #检查次数
CREATE_OPTIONS: #建表的参数
TABLE_COMMENT: #表的注释
1 row in set (0.00 sec)
2.innodb和myisam的物理区别
#myisam存储引擎的文件
-rw-rw---- 1 mysql mysql 10684 10月 19 17:09 user.frm #表结构
-rw-rw---- 1 mysql mysql 728 10月 23 20:02 user.MYD #数据库的用户密码
-rw-rw---- 1 mysql mysql 2048 10月 27 08:51 user.MYI #数据库的用户
#innodb存储引擎的文件
-rw-rw---- 1 mysql mysql 8710 10月 28 19:53 city.frm #表结构
-rw-rw---- 1 mysql mysql 2097152 10月 28 19:54 city.ibd #表数据
#查看文件
strings user.MYI
3.innodb的核心特性
MVCC #多版本并发控制
事务 #事务的特性
备份 #mysqldump xtrabackup
故障自动恢复 #CSR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号