项目1:即时标记
接触的第一个python项目,老实说,这个好像并不容易啊,加之对python的不熟悉,确实是搞了很久。
文本文档内容如下:


1 Welcome to World Wide Spam, Inc 2 3 4 These are the corporate web pages of *World Wide Spam*, Inc. We hope you find your enjoyable, and that you will sample many of our products 5 6 A short history of the company 7 8 World Wide Spam was started in the summer of 2000. The business concept was to ride the dot-com wave and to make money both through bulk email and by selling canned meat online 9 10 After receiving several complaints from customer who weren't satisfied bu their bulk email .World Wide Spam altered their profile. and foused 100% on canned goods. Today they rank as the world's 13.892nd online suppler of SPAM 11 12 Destinations 13 14 From this page you may visit several of our interesting web pages: 15 16 -What is SPAM?(http://www.baidu.com) 17 18 -How do they make it?(http://www.baidu.com) 19 20 -Why should i eat is?(http://www.baidu.com) 21 22 How to get in touch with us 23 24 You can get in touch with us in *many* ways: By phone(555-1234), by email(wwspam@wwspam.fu) or by visiting our customer feedback page(http://wwspam.fu/feedback).
①文本块生成器(util.py)
1 def lines(file): 2 for line in file: yield line 3 yield '\n' 4 5 6 def blocks(file): 7 block = [] 8 for line in lines(file): 9 if line.strip(): 10 block.append(line) 11 elif block: 12 yield ''.join(block).strip() 13 block = []
一开始对于这段代码不是很明白,需要了解yield的用法,其实它就是每次返回一个值,然后函数冻结,下一次再从上一次的地方继续运行下去。strip()方法是移除字符串头尾指定的字符(默认就是空格),所以如果为空的话,就遇到了一个空行,也就是进入到了一个新的段,那么此时上一个段就已经寻找完了,可以返回了。这里lines函数的作用就是在文本的最后添加一个空行,否则的话最后一个块就无法返回了。
我对这段代码进行了一下测试,尝试着输出第一块的内容:
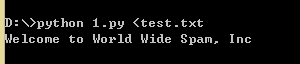
如果第一段和第二段之间没有空行,那么就会输出这样的情况:
②处理程序(handlers.py)
1 class Handler: 2 3 #判断当前类是否有对应的方法,所有的话则根据提供的额外参数使用对应方法 4 def callback(self,prefix,name,*args): 5 method = getattr(self,prefix+name,None) 6 if callable(method):return method(*args) 7 8 #callback的辅助方法,前缀就是start,只需要提供方法名即可 9 def start(self,name): 10 self.callback('start_',name) 11 #前缀为end的callback辅助方法 12 def end(self,name): 13 self.callback('end_',name) 14 15 #返回方法名subsutitution 16 def sub(self,name): 17 def substitution(match): 18 result = self.callback('sub_',name,match) 19 if result is None: result = match.group(0) 20 return result 21 return substitution 22 23 class HTMLRenderer(Handler): 24 def start_document(self): 25 print ('<html><head><title>title</title></head><body>') 26 def end_documrnt(self): 27 print ('</body></html>') 28 def start_paragraph(self): 29 print ('<p>') 30 def end_paragraph(self): 31 print ('</p>') 32 def start_heading(self): 33 print ('<h2>') 34 def end_heading(self): 35 print ('</h2>') 36 def start_list(self): 37 print ('<ul>') 38 def end_list(self): 39 print ('</ul>') 40 def start_listitem(self): 41 print ('<li>') 42 def end_listitem(self): 43 print ('</li>') 44 def start_title(self): 45 print ('<h1>') 46 def end_title(self): 47 print ('</h1>') 48 def sub_emphasis(self,match): 49 return '<em>%s</em>' % match.group(1) 50 def sub_url(self,match): 51 return '<a href="%s">%s</a>' % (match.group(1),match.group(1)) 52 def sub_mail(self,match): 53 return '<a href="mailto:%s">%s</a>' % (match.group(1),match.group(1)) 54 def feed(self,data): 55 print(data)
这段代码是有点难度的,首先是callback函数,里面getattr的作用是检验类里是否有prefix+name这个函数,有就返回它的内存地址。callable是内置函数,检验函数是否可用,如果可用的话就用调用该函数。
最难的是def sub这个函数,书上有一个例子是这样说的:
>>> handler.sub('emphasis') <function substitution at 0x168cf8>
也就是它会返回一个substitution函数。接下来重点是这个:
>>> import re >>> re.sub(r'\*(.+?)\*', handler.sub('emphasis'), 'This *is* a test') 'This <em>is</em> a test'
中间的handler.sub('emphasis')会返回substitution()函数,可是这个函数有match这个参数啊,那么这里谁来当参数呢?
在这里面正则表达式匹配得到的结果是is,此时is就作为了参数去执行函数。这样应该就明白了吧。
③规则(rules.py)
1 class Rule: 2 def action(self,block,handler): 3 handler.start(self.type) 4 handler.feed(block) 5 handler.end(self.type) 6 return True 7 8 class HeadingRule(Rule): 9 type = 'heading' 10 #不包含\n,也就是说并非最后一个块;长度小于70;不以冒号结尾 11 def condition(self,block): 12 return not '\n' in block and len(block) <=70 and not block[-1] == ':' 13 14 class TitleRule(HeadingRule): 15 type = 'title' 16 #只工作一次,处理第一个快,因为处理完一次之后first的值被设置为了False,所以不会再执行处理方法了 17 first = True 18 def condition(self,block): 19 if not self.first: return False 20 self.first = False 21 return HeadingRule.condition(self,block) 22 23 class ListItemRule(Rule): 24 type = 'listitem' 25 def condition(self,block): 26 return block[0] == '-' 27 def action(self,block,handler): 28 handler.start(self.type) 29 handler.feed(block[1:].strip()) 30 handler.end(self.type) 31 return True 32 33 class ListRule(ListItemRule): 34 type = 'list' 35 inside = False 36 def condition(self,block): 37 return True 38 def action(self,block,handler): 39 if not self.inside and ListItemRule.condition(self,block): 40 handler.start(self.type) 41 self.inside = True 42 elif self.inside and not ListItemRule.condition(self,block): 43 handler.end(self.type) 44 self.inside = False 45 return False 46 47 class ParagraphRule(Rule): 48 type = 'paragraph' 49 def condition(self,block): 50 return True
这部分还是比较好懂的,看书上就可以了。
④主程序(markup.py)
1 import sys,re 2 from handlers import * 3 from util import * 4 from rules import * 5 6 class Parser: 7 def __init__(self,handler): 8 self.handler = handler 9 self.rules = [] 10 self.filters = [] 11 #向规则列表中添加规则 12 def addRule(self,rule): 13 self.rules.append(rule) 14 #向过滤器列表中添加过滤器 15 def addFilter(self,pattern,name): 16 #创建过滤器,实际上这里return的是一个替换式 17 def filter(block,handler): 18 return re.sub(pattern,handler.sub(name),block) 19 self.filters.append(filter) 20 #对文件进行处理 21 def parse(self,file): 22 self.handler.start('document') 23 #对文件中的文本块依次执行过滤器和规则 24 for block in blocks(file): 25 for filter in self.filters: 26 block = filter(block,self.handler) 27 for rule in self.rules: 28 #判断文本块是否符合相应规则,若符合做执行规则对应的处理方法 29 if rule.condition(block): 30 last = rule.action(block,self.handler) 31 if last:break 32 self.handler.end('document') 33 34 class BasicTextParser(Parser): 35 def __init__(self,handler): 36 Parser.__init__(self,handler) 37 self.addRule(ListRule()) 38 self.addRule(ListItemRule()) 39 self.addRule(TitleRule()) 40 self.addRule(HeadingRule()) 41 self.addRule(ParagraphRule()) 42 43 self.addFilter(r'\*(.+?)\*','emphasis') 44 self.addFilter(r'(http://[\.a-zA-Z/]+)','url') 45 self.addFilter(r'([\.a-zA-Z]+@[\.a-zA-Z]+[a-zA-Z]+)','mail') 46 47 handler = HTMLRenderer() 48 parser = BasicTextParser(handler) 49 50 parser.parse(sys.stdin)
addFilter的作用是向过滤器列表中添加一个过滤器,首先是创建过滤器,handler.sub(name),会返回一个函数,替换后再加入列表中。
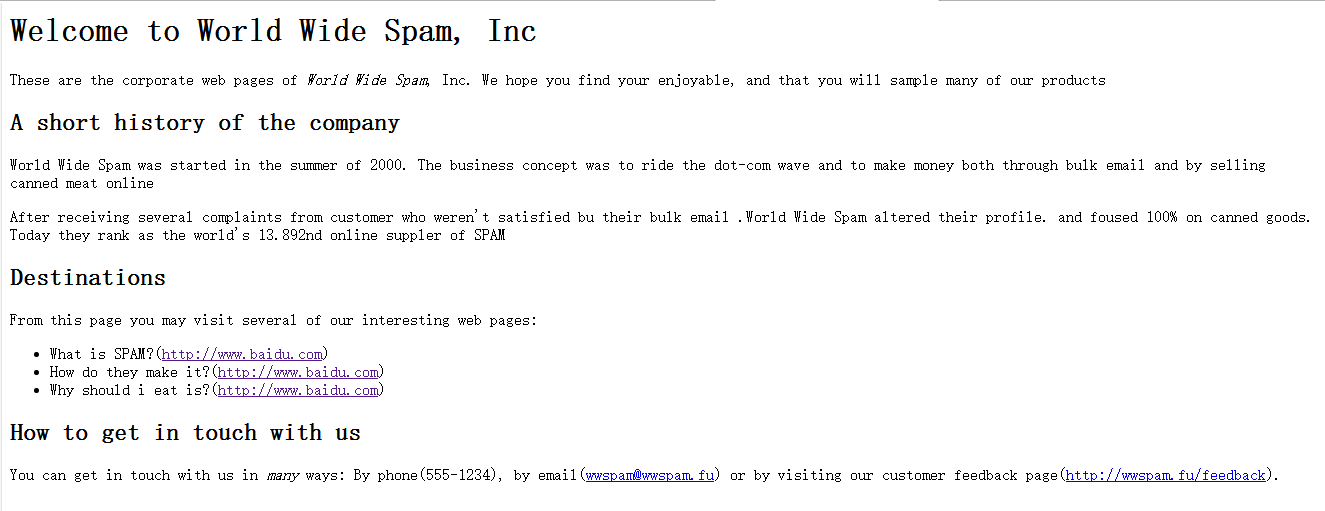
最后运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号