torch.nn.Embedding使用
在RNN模型的训练过程中,需要用到词嵌入,而torch.nn.Embedding就提供了这样的功能。我们只需要初始化torch.nn.Embedding(n,m),n是单词数,m就是词向量的维度。
一开始embedding是随机的,在训练的时候会自动更新。
举个简单的例子:
word1和word2是两个长度为3的句子,保存的是单词所对应的词向量的索引号。
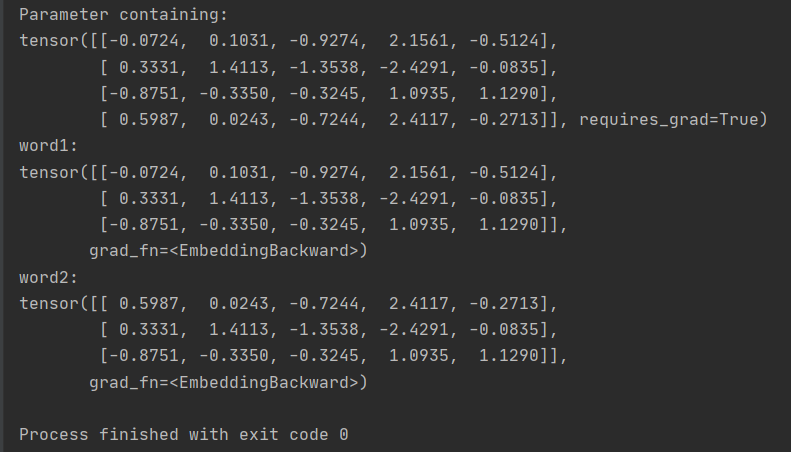
随机生成(4,5)维度大小的embedding,可以通过embedding.weight查看embedding的内容。
输入word1时,embedding会输出第0、1、2行词向量的内容,word2同理。
import torch
word1 = torch.LongTensor([0, 1, 2])
word2 = torch.LongTensor([3, 1, 2])
embedding = torch.nn.Embedding(4, 5)
print(embedding.weight)
print('word1:')
print(embedding(word1))
print('word2:')
print(embedding(word2))
除此之外,我们也可以导入已经训练好的词向量,但是需要设置训练过程中不更新。
如下所示,emb是已经训练得到的词向量,先初始化等同大小的embedding,然后将emb的数据复制过来,最后一定要设置weight.requires_grad为False。
self.embedding = torch.nn.Embedding(emb.size(0), emb.size(1))
self.embedding.weight = torch.nn.Parameter(emb)
# 固定embedding
self.embedding.weight.requires_grad = False

 浙公网安备 33010602011771号
浙公网安备 33010602011771号