word2vec公式推导及python简单实现
简介
word2vec实现的功能是将词用$n$维的向量表示出来,即词向量。一般这个词向量的维度为100~300。
word2vec有两种训练模型: (1) CBOW:根据中心词$w(t)$周围的词来预测中心词
(2) Skip-gram:根据中心词$w(t)$来预测周围词
word2vec有两种加速算法: (1) Hierarohical Softmax
(2) Negative Sampling
本文只实现了Skip-gram,所以这里只介绍该模型。
算法推导
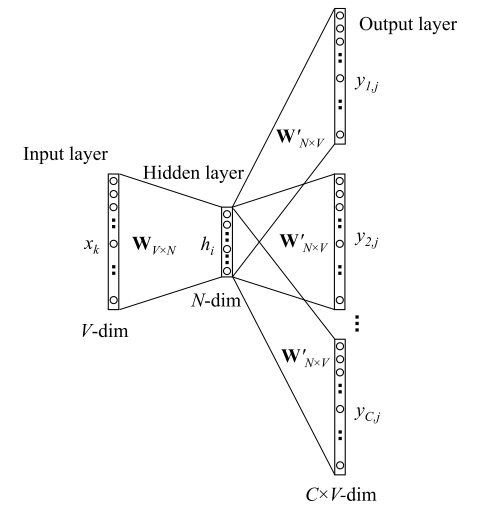
Skip-gram的模型如上图所示,分为Input layer、Hidden layer和Output layer三层。
$$h = W^{T}·X$$
$$z = W'^{T}·h$$
$$a = softmax(z)$$
$$loss=-\sum_{i=0}^{V}y_ilna_i$$
最后$a$向量中概率最大的即为我们所预测的,因为最后的预测词中只有一位为$1$,其余都是$0$,所以用交叉熵作为损失函数正好。
在对$W$以及$W'$求导之前,首先来看一下$\frac{\partial a_j}{\partial z_i}$的值:
如果$ j = i:$
$$\frac{\partial a_j}{\partial z_i} = \frac{\partial (\frac{e^{z_j}}{\sum_{k}e^{z_k}})}{\partial z_i} = \frac{(e^{z_j})'·\sum_{k}e^{z_k}-e^{z_j}·e^{z_j}}{(\sum_{k}e^{z_k})^2} = \frac{e^{z_j}}{\sum_{k}e^{z_k}}-\frac{e^{z_j}}{\sum_{k}e^{z_k}}·\frac{e^{z_j}}{\sum_{k}e^{z_k}}=a_j(1-a_j)$$
如果$ j ≠ i:$
$$\frac{\partial a_j}{\partial z_i} = \frac{\partial (\frac{e^{z_j}}{\sum_{k}e^{z_k}})}{\partial z_i} = \frac{0·\sum_{k}e^{z_k}-e^{z_j}·e^{z_i}}{(\sum_{k}e^{z_k})^2} = -\frac{e^{z_j}}{\sum_{k}e^{z_k}}·\frac{e^{z_i}}{\sum_{k}e^{z_k}}=-a_ja_i$$
接下来求梯度:
$$\frac{\partial loss}{\partial z_i} = \frac{\partial loss}{\partial a_1}\frac{\partial a_1}{\partial z_i} + \frac{\partial loss}{\partial a_2} \frac{\partial a_2}{\partial z_i} ··· \frac{\partial loss}{\partial a_v}\frac{\partial a_v}{\partial z_i}$$
因为$a$是经过softmax得到的,所以所有的$a$都与$z_i$有关,又目标词的y中只有一位为1,假设是$j$位,此时$loss =-lna_j$,所以在上式中,只有对$a_j$的偏导不为0,其余的皆为0。所以上式可以简化为:
$$ \frac{\partial loss}{\partial z_i} = -\frac{1}{a_j}\frac{\partial a_j}{\partial z_i}$$
而$\frac{\partial a_j}{\partial z_i}$的值,我们已经在上面分类讨论过了,在乘上$-\frac{1}{a_j}$后,即为:
如果$ j = i:$, $\frac{\partial a_j}{\partial z_i} = a_j - 1$
如果$ j ≠ i:$, $\frac{\partial a_j}{\partial z_i} = a_i$
所以如果现在我们已经求得向量$a$的值,那么向量$z$的偏导就是$a-y$。
然后:
$$\frac{\partial loss}{\partial W'} = \frac{\partial loss}{\partial z}\frac{\partial z}{\partial W'} = h(a-y)^T$$
$$\frac{\partial loss}{\partial W} = \frac{\partial loss}{\partial z}\frac{\partial z}{\partial h}\frac{\partial h}{\partial W} = xW'(a-y)$$
代码实现
所需要的库及超参数设置:
import numpy as np
from collections import defaultdict
settings = {'window_size': 2,
'n': 3,
'epochs': 500,
'learning_rate': 0.01}
使用的语句为
corpus = ['natural language processing and machine learning is fun and exciting']
生成训练数据:
def generate_training_data(self, corpus):
'''
:param settings: 超参数
:param corpus: 语料库
:return: 训练样本
'''
word_counts = defaultdict(int) # 当字典中不存在时返回0
for row in corpus:
for word in row.split(' '):
word_counts[word] += 1
self.v_count = len(word_counts.keys()) # v_count:不重复单词数
self.words_list = list(word_counts.keys()) # words_list:单词列表
self.word_index = dict((word, i) for i, word in enumerate(self.words_list)) # {单词:索引}
self.index_word = dict((i, word) for i, word in enumerate(self.words_list)) # {索引:单词}
training_data = []
for sentence in corpus:
tmp_list = sentence.split(' ') # 语句单词列表
sent_len = len(tmp_list) # 语句长度
for i, word in enumerate(tmp_list): # 依次访问语句中的词语
w_target = self.word2onehot(tmp_list[i]) # 中心词ont-hot表示
w_context = [] # 上下文
for j in range(i - self.window, i + self.window + 1):
if j != i and j <= sent_len - 1 and j >= 0:
w_context.append(self.word2onehot(tmp_list[j]))
training_data.append([w_target, w_context]) # 对应了一个训练样本
return training_data
生成one-hot:
def word2onehot(self, word):
"""
:param word: 单词
:return: ont-hot
"""
word_vec = [0 for i in range(0, self.v_count)] # 生成v_count维度的全0向量
word_index = self.word_index[word] # 获得word所对应的索引
word_vec[word_index] = 1 # 对应位置位1
return word_vec
forward函数:
def forward_pass(self, x):
h = np.dot(self.w1.T, x)
u = np.dot(self.w2.T, h)
y_pred = self.softmax(u)
return y_pred, h, u
softmax函数,注意这里要注意溢出的问题,一般来讲减去最大值就可以解决该问题。
def softmax(self, x):
e_x = np.exp(x - np.max(x)) # 防止上溢和下溢,减去这个数的计算结果不变
return e_x / e_x.sum(axis=0)
反向传播,这里要特别注意,在更新第二个矩阵时,我们需要全部更新,但是第一个矩阵只需要更新某一行,所以没必要去更新全部。
第一个矩阵的梯度如下图所示的那样:

def back_prop(self, e, h, x):
dl_dw2 = np.outer(h, e)
dl_dw1 = np.dot(self.w2, e.T).reshape(-1)
self.w1[x.index(1)] = self.w1[x.index(1)] - (self.lr * dl_dw1) # x.index(1)获取x向量中value=1的索引,只需要更新该索引对应的行即可
self.w2 = self.w2 - (self.lr * dl_dw2)
训练过程:
def train(self, training_data):
self.w1 = np.random.uniform(-1, 1, (self.v_count, self.n)) # 随机生成参数矩阵
self.w2 = np.random.uniform(-1, 1, (self.n, self.v_count))
for i in range(self.epochs):
self.loss = 0
for data in training_data:
w_t, w_c = data[0], data[1] # w_t是中心词的one-hot,w_c是window范围内所要预测此的one-hot
y_pred, h, u = self.forward_pass(w_t)
train_loss = np.sum([np.subtract(y_pred, word) for word in w_c], axis=0) # 每个预测词都是一对训练数据,相加处理
self.back_prop(train_loss, h, w_t)
for word in w_c:
self.loss += - np.dot(word, np.log(y_pred))
print('Epoch:', i, "Loss:", self.loss)
结果:

分析
可以看到,我们每次需要对第二个矩阵的每个值都进行更新,在数据量巨大时,这是需要花费很长的时间去计算的。而在Hierarchical Softmax 和 Negative Sampling和这两种优化方法中,不再使用$W'$这个矩阵,所以可以大大减少计算时间。关于这两个优化方法,下次再去学习了。
完整代码
import numpy as np
from collections import defaultdict
settings = {'window_size': 2,
'n': 3,
'epochs': 500,
'learning_rate': 0.01}
class word2vec():
def __init__(self):
self.n = settings['n']
self.lr = settings['learning_rate']
self.epochs = settings['epochs']
self.window = settings['window_size']
def generate_training_data(self, corpus):
'''
:param settings: 超参数
:param corpus: 语料库
:return: 训练样本
'''
word_counts = defaultdict(int) # 当字典中不存在时返回0
for row in corpus:
for word in row.split(' '):
word_counts[word] += 1
self.v_count = len(word_counts.keys()) # v_count:不重复单词数
self.words_list = list(word_counts.keys()) # words_list:单词列表
self.word_index = dict((word, i) for i, word in enumerate(self.words_list)) # {单词:索引}
self.index_word = dict((i, word) for i, word in enumerate(self.words_list)) # {索引:单词}
training_data = []
for sentence in corpus:
tmp_list = sentence.split(' ') # 语句单词列表
sent_len = len(tmp_list) # 语句长度
for i, word in enumerate(tmp_list): # 依次访问语句中的词语
w_target = self.word2onehot(tmp_list[i]) # 中心词ont-hot表示
w_context = [] # 上下文
for j in range(i - self.window, i + self.window + 1):
if j != i and j <= sent_len - 1 and j >= 0:
w_context.append(self.word2onehot(tmp_list[j]))
training_data.append([w_target, w_context]) # 对应了一个训练样本
return training_data
def word2onehot(self, word):
"""
:param word: 单词
:return: ont-hot
"""
word_vec = [0 for i in range(0, self.v_count)] # 生成v_count维度的全0向量
word_index = self.word_index[word] # 获得word所对应的索引
word_vec[word_index] = 1 # 对应位置位1
return word_vec
def train(self, training_data):
self.w1 = np.random.uniform(-1, 1, (self.v_count, self.n)) # 随机生成参数矩阵
self.w2 = np.random.uniform(-1, 1, (self.n, self.v_count))
for i in range(self.epochs):
self.loss = 0
for data in training_data:
w_t, w_c = data[0], data[1] # w_t是中心词的one-hot,w_c是window范围内所要预测此的one-hot
y_pred, h, u = self.forward_pass(w_t)
train_loss = np.sum([np.subtract(y_pred, word) for word in w_c], axis=0) # 每个预测词都是一对训练数据,相加处理
self.back_prop(train_loss, h, w_t)
for word in w_c:
self.loss += - np.dot(word, np.log(y_pred))
print('Epoch:', i, "Loss:", self.loss)
def forward_pass(self, x):
h = np.dot(self.w1.T, x)
u = np.dot(self.w2.T, h)
y_pred = self.softmax(u)
return y_pred, h, u
def softmax(self, x):
e_x = np.exp(x - np.max(x)) # 防止上溢和下溢。减去这个数的计算结果不变
return e_x / e_x.sum(axis=0)
def back_prop(self, e, h, x):
dl_dw2 = np.outer(h, e)
dl_dw1 = np.dot(self.w2, e.T).reshape(-1)
self.w1[x.index(1)] = self.w1[x.index(1)] - (self.lr * dl_dw1) # x.index(1)获取x向量中value=1的索引,只需要更新该索引对应的行即可
self.w2 = self.w2 - (self.lr * dl_dw2)
if __name__ == '__main__':
corpus = ['natural language processing and machine learning is fun and exciting']
w2v = word2vec()
training_data = w2v.generate_training_data(corpus)
w2v.train(training_data)
参考:
【2】An implementation guide to Word2Vec using NumPy and Google Sheets

 浙公网安备 33010602011771号
浙公网安备 33010602011771号