04 Hadoop思想与原理
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算.
1、Hadoop的整体框架
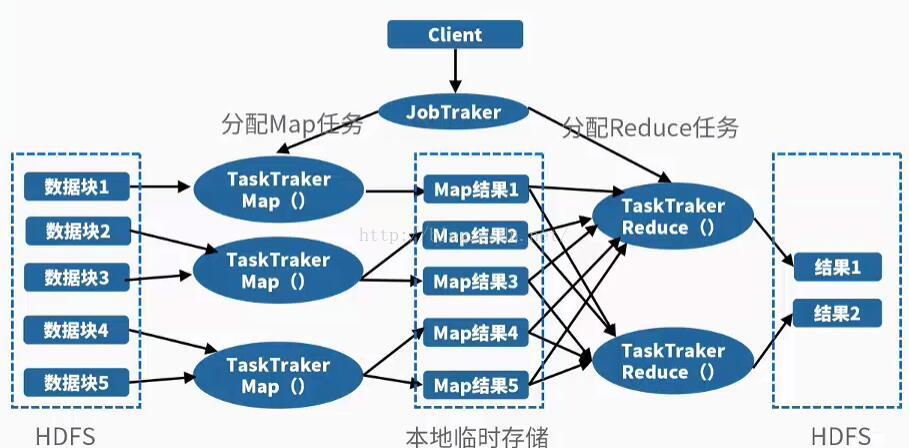
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
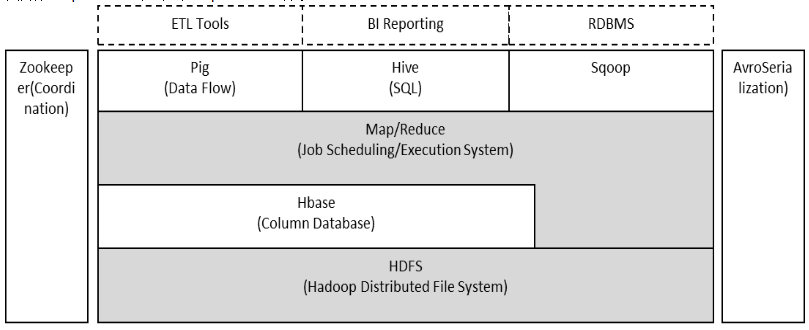
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
下图是一个典型的Hadoop集群的部署结构: 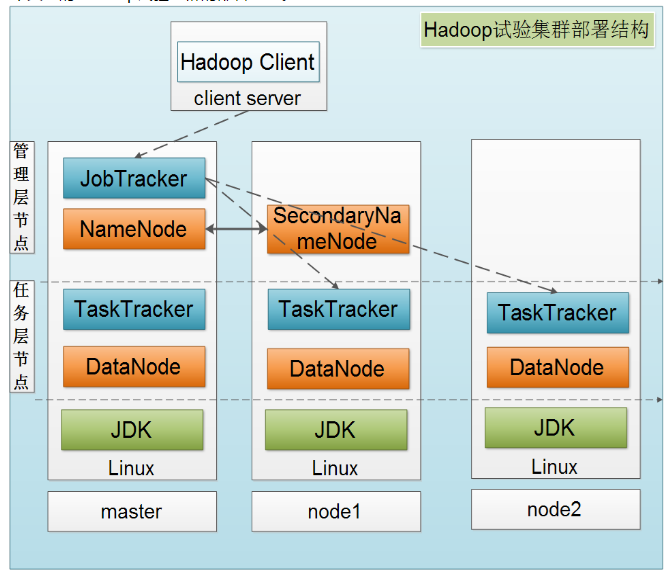
接着给出Hadoop各组件依赖共存关系: 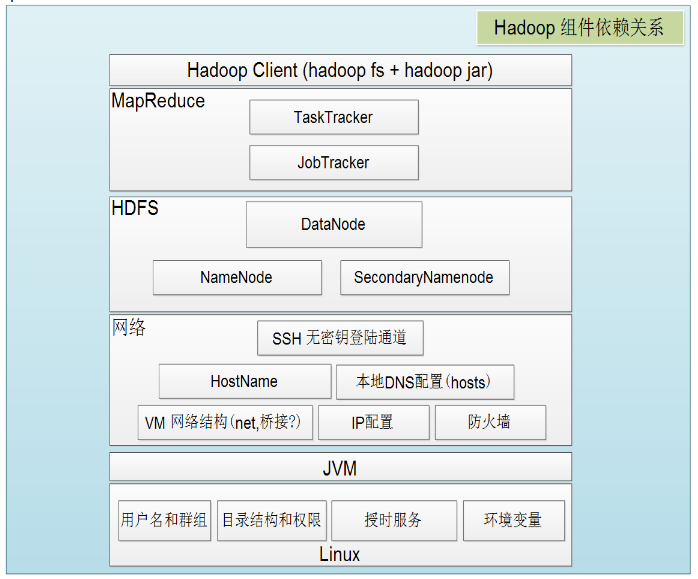
2、Hadoop的核心设计 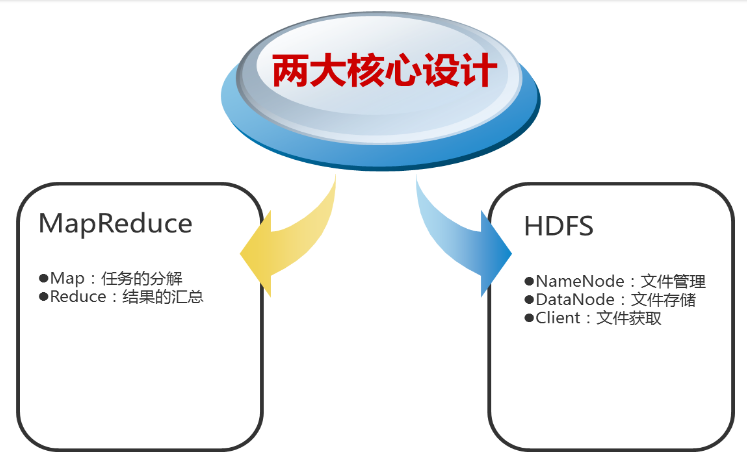
(1)HDFS
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
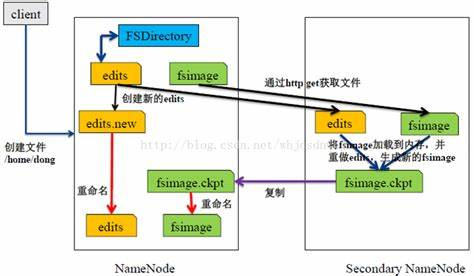
HDFS的架构如图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据的保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。 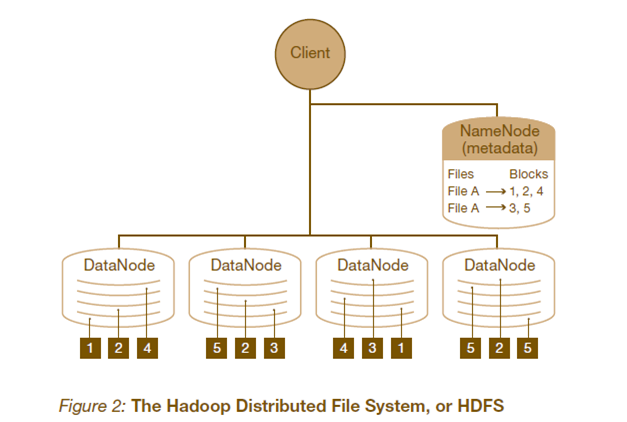
•NameNode
可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
•DataNode
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
•Client
就是需要获取分布式文件系统文件的应用程序。
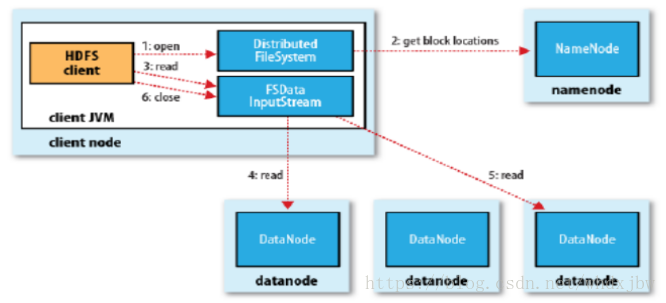
以下来说明HDFS如何进行文件的读写操作: 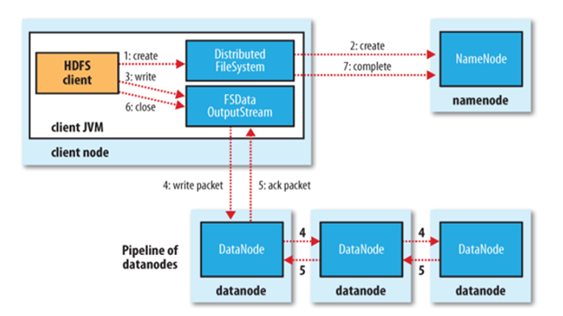
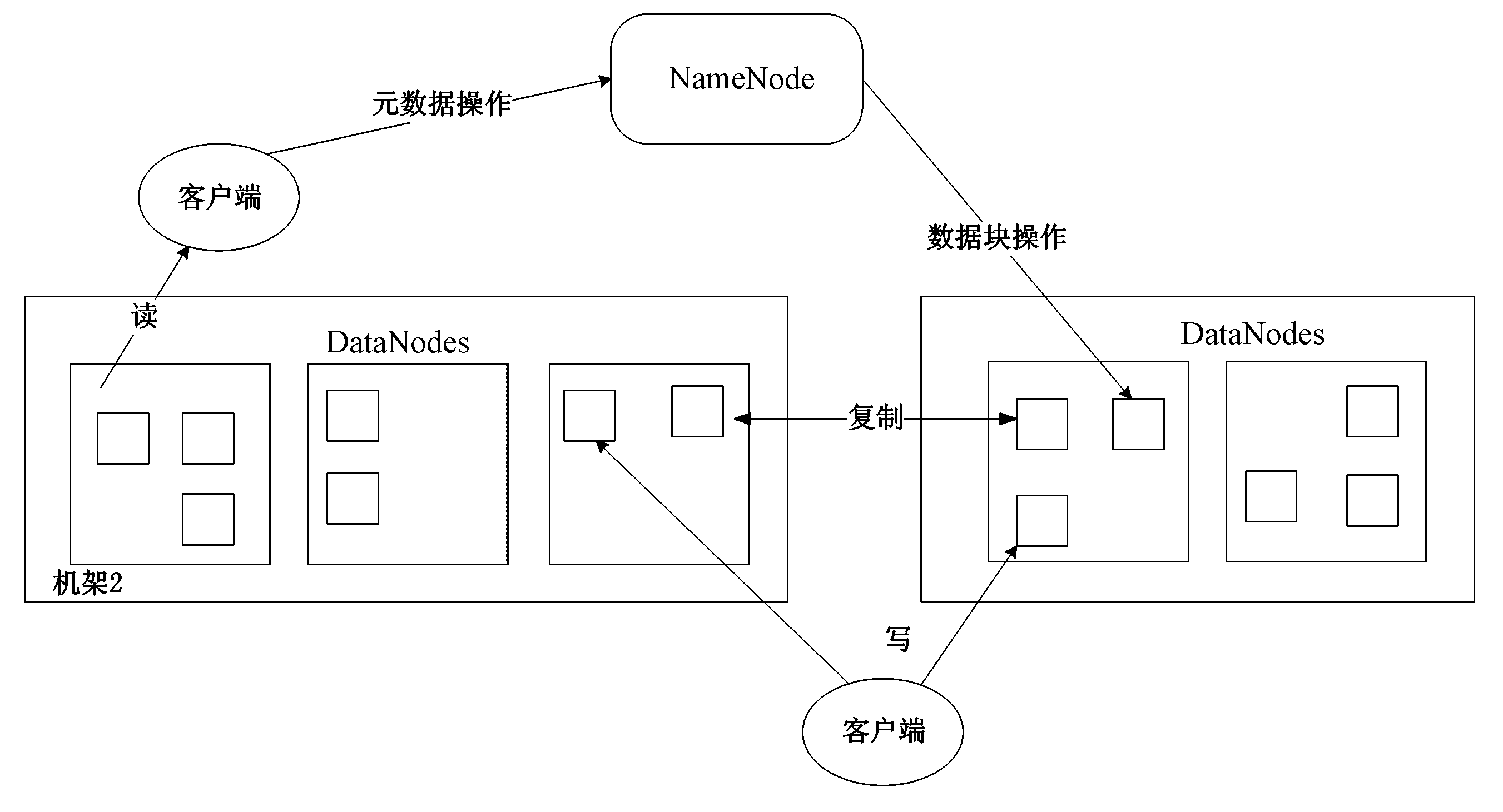
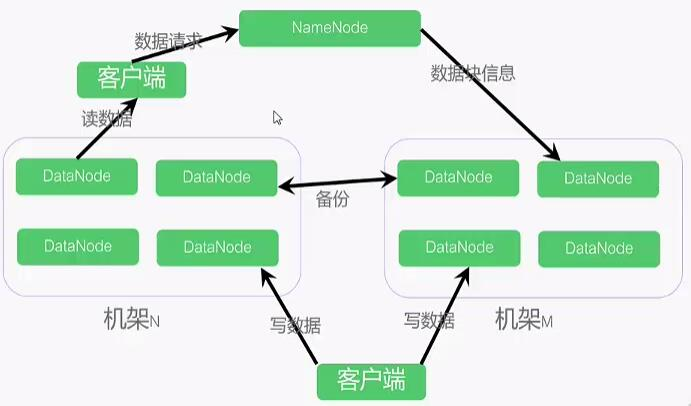
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
4.简述HBase与传统数据库的主要区别
1.数据类型:Hbase只有简单的数据类型,只保留字符串;传统数据库有丰富的数据类型。
2.数据操作:Hbase只有简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系;传统数据库通常有各式各样的函数和连接操作。
3.存储模式:Hbase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的,这样的好处是数据即是索引,访问查询涉及的列大量降低系统的I/O,并且每一列由一个线索来处理,可以实现查询的并发处理;传统数据库是基于表格结构和行存储,其没有建立索引将耗费大量的I/O并且建立索引和物化试图需要耗费大量的时间和资源。
4.数据维护:Hbase的更新实际上是插入了新的数据;传统数据库只是替换和修改。
5.可伸缩性:Hbase可以轻松的增加或减少硬件的数目,并且对错误的兼容性比较高;传统数据库需要增加中间层才能实现这样的功能。
6.事务:Hbase只可以实现单行的事务性,意味着行与行之间、表与表之前不必满足事务性;传统数据库是可以实现跨行的事务性。
Hbase的优点:
1.列可以动态增加,并且当列为空的时候就不存储,节省存储空间。
2.Hbase自动切分数据,使得数据存储自动具有水平扩展能力。
3.Hbase可以支持高并发顺序读写操作(因为其有内存的缓存机制)。
Hbase的缺点:
1.不能支持条件查询,只支持按照row key来查询
2.暂时不能支持Master server的故障切换,当Master宕机后,这个存储系统都会挂掉。
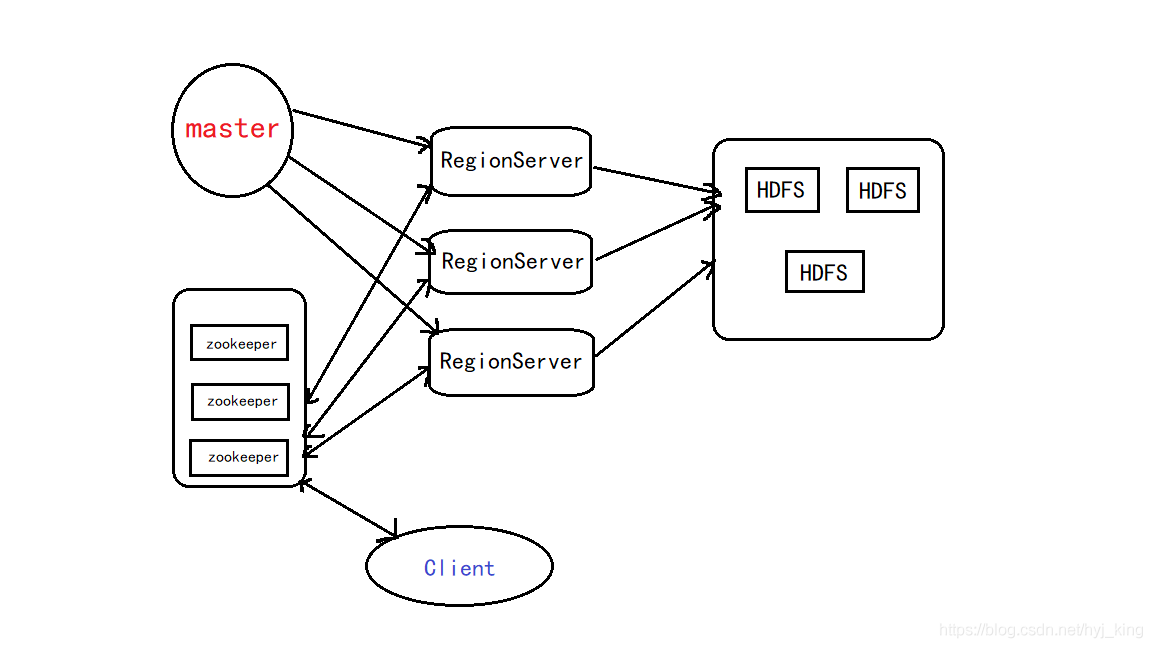
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联
- Master主服务器的功能
- 主服务器Master主要负责表和Region的管理工作:
– 管理用户对表的增加、删除、修改、查询等操作
– 实现不同Region服务器之间的负载均衡
– 在Region分裂或合并后,负责重新调整Region的分布
– 对发生故障失效的Region服务器上的Region进行迁移
- 主服务器Master主要负责表和Region的管理工作:
- Region服务器的功能
- Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
- Zookeeper协同的功能
- Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题。
- Client客户端的请求流程
![]()
- 四者之间的相系关系
1、Hbase集群有两种服务器:一个Master服务器和多个RegionServer服务器;
2、Master服务负责维护表结构信息和各种协调工作,比如建表、删表、移动region、合并等操作;
3、客户端获取数据是由客户端直连RegionServer的,所以Master服务挂掉之后依然可以查询、存储、删除数据,就是不能建新表了;
4、RegionServer非常依赖Zookeeper服务,Zookeeper管理Hbase所有的RegionServer信息,包括具体的数据段存放在那个RegionServer上;
5、客户端每次与Hbase连接,其实都是先于Zookeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer;客户端从Zookeeper获取了RegionServer的地址后,会直接从RegionServer获取数据;
- 与HDFS的关联
RegionServer保存的数据直接存储在Hadoop的HDFS上
- 与HDFS的关联
- Master主服务器的功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号