
声纹识别算法阅读之d-vector
论文:
End-to-End Text-Dependent Speaker Verification
思想:
google提出的文本相关的说话人确认,通过DNN或LSTM的网络结构提取说话人特征表达;然后注册阶段输入说话人的多个文本相关句子(考虑环境噪声等干扰)得到的特征表达取平均值作为该说话人的embedding;然后验证时输入test句子得到特征表达后,与说话人注册embedding计算cosine相似度,超过阈值(一般0.5)进行确认操作,否则拒绝。
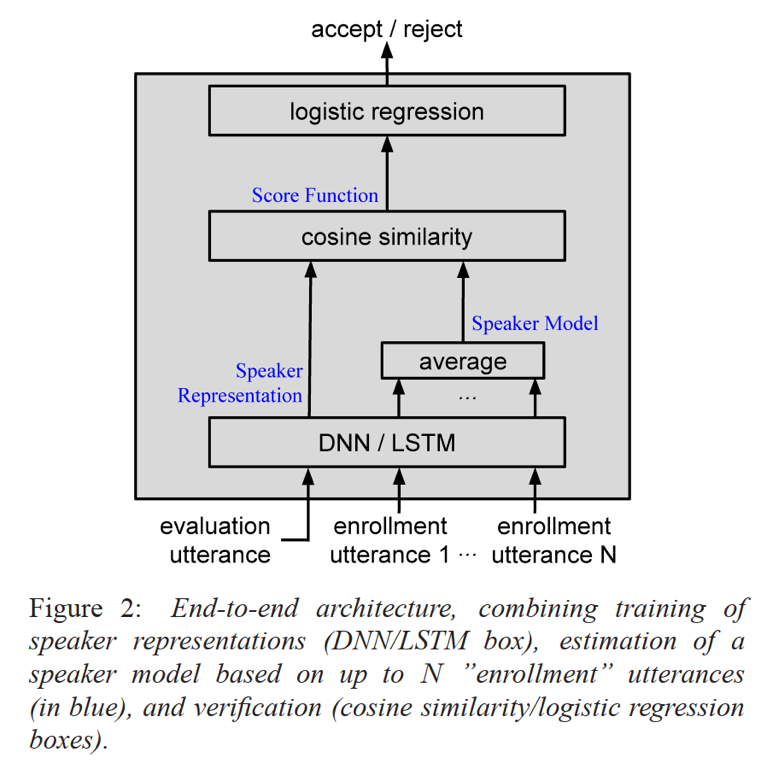
模型:
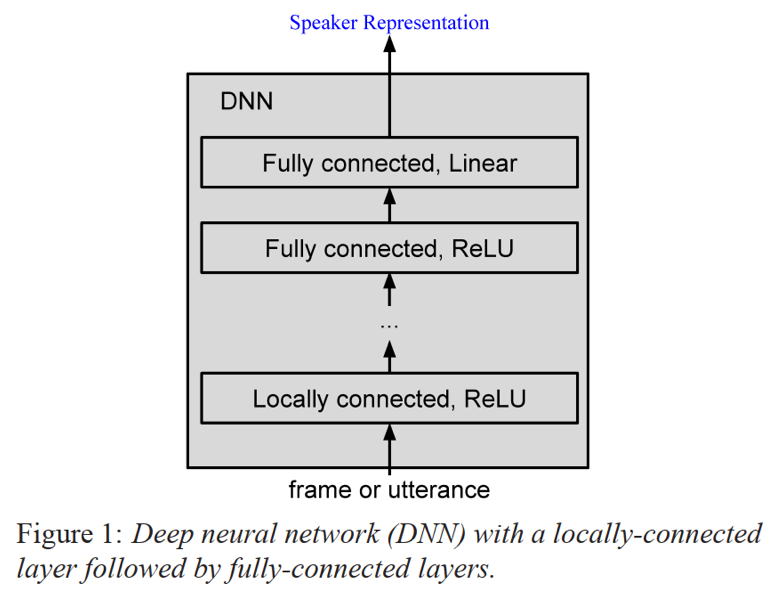
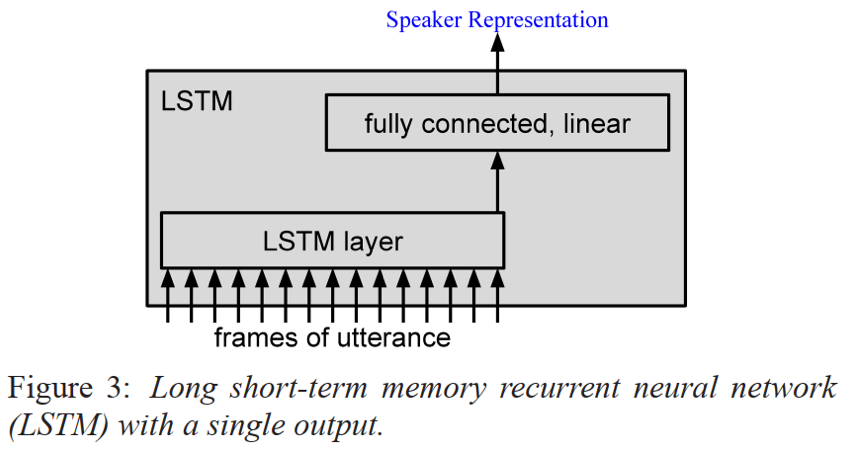
网络模型采用多层DNN或多层LSTM的结构;其中DNN结构包含1层local connected层和多层full connected层外加一层线性层,其中非线性层激活函数为ReLU;LSTM结构为多层LSTM结构+1层线性层;损失函数包括softmax和e2e loss;这里,参考[1] local connected的作用主要是降低模型参数,在几乎不影响精度条件下可有效减少30%的参数量;
- DNN结构:1*local connected[1]+m*full connected+1*linear layer
- LSTM结构:LSTM结构逐帧输入,然后取最后一个时刻的隐层输出作为线性层的输入
- 损失函数:
- softmax:将线性层的输出输入到softmax层获得概率分布
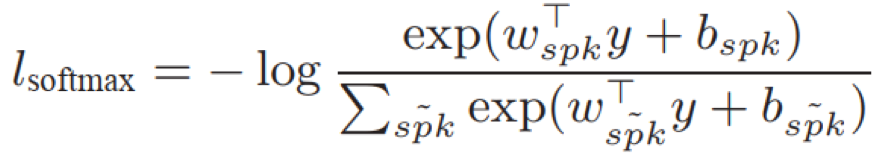
- e2e loss: 将test的特征表达和说话人注册句子特征均值计算的cosine距离,输入到逻辑斯特回归进行二分类(确认or拒绝)
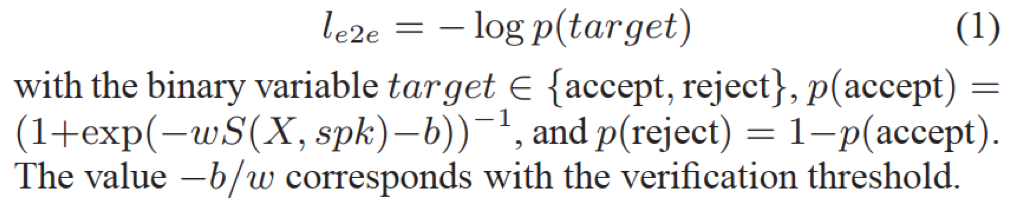
注意:e2e模型输入维度为N+1,N为说话人注册句子,1为test;其中,N个说话人注册句子得到N个特征表达取平均后与test特征表达计算cosine后再输入到逻辑斯特回归计算损失
训练:
- 数据集:google voice search场景中的‘OK Google’文本相关数据;每个句子采用后80帧,帧率100hz,每帧10ms,共80*10=800ms
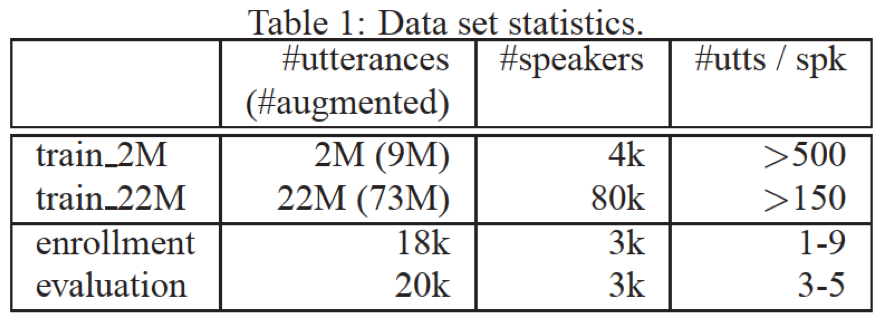
- 输入:输入特征为40log(fbanks)
- 网络结构:
- DNN:1*local connected(10*10,ReLU)+3*full connected(504,ReLU)+1*linear layer(504)
- LSTM: 1*LSTM(504)+1*linear layer(504)
- batch size=32
- 评价指标:EER,包含错误拒绝率和错误接受率,二者相等时得到等错率EER
实验结构:
- 句子水平的d-vector的效果明显优于基于i-vector帧水平的方法
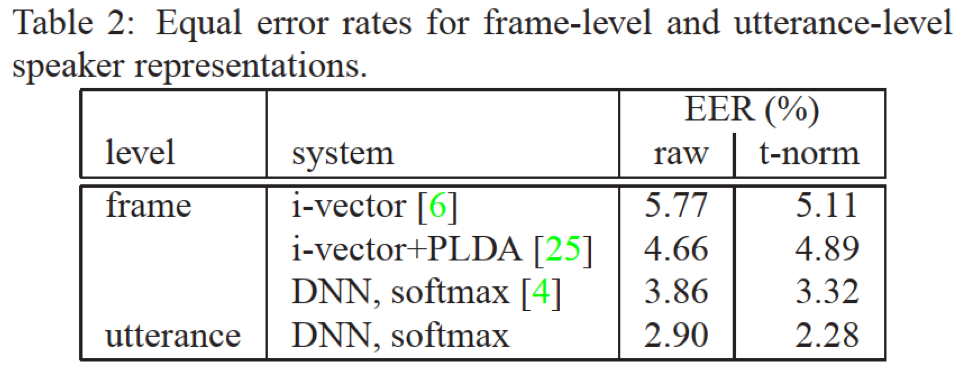
- 基于逻辑斯特回归二分类的e2e loss相比于softmax,效果稍好;个人理解e2e损失从输出类别数来看降低了任务难度,从m类(对应训练集m个说话人)降低为2分类(确认or拒绝),并且更靠近任务目的
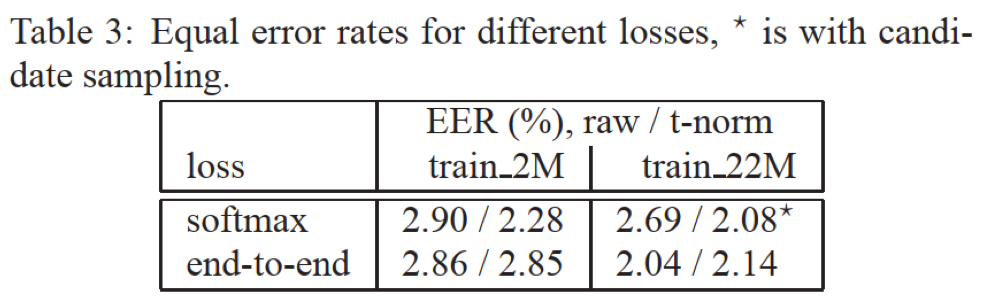
- 从效果来看,基于LSTM的模型相比于DNN效果要好,比较LSTM在时序依赖建模方面具有一定的优势

结论:
- 本文从文本相关说话人确认任务角度考虑,提出了一种基于DNN/LSTM的网络结构,该结构作为说话人文本相关语句的特征表达提取器;模型训练完成后,先进行说话人注册,即将代表说话人的N个文本相关语句(最好包含说话人内在的一些变化或外部干扰)输入网络分别提取特征表达,然后取平均值作为该说话人的特征表达;同样输入test语句也得到对应特征表达;最后二者计算consine相似度,根据相关阈值,判断该test是否为该说话人;
- 此外,论文还根据任务导向,提出了一种e2e的训练策略,策略中网络模型无需改变,但是损失函数这块引入逻辑斯特回归将注册特征表达和test表达的cosine得分转化为线性二分类任务,在一定程度上对效果有提升作用
Reference

 浙公网安备 33010602011771号
浙公网安备 33010602011771号