

python爬虫——深圳市租房信息数据分析
一、选题背景
因为深圳经济非常不错,想必想要去深圳工作的人也不少。衣食住行是生活的基本需求。衣和食好解决,不喜欢的衣服可以买新的,不好吃的食物可以换一家吃。可是在住宿上,买房和租房的置换成本都相对较高,因此房源选择尤为慎重。作为目前买不起房的人自然是以租房为主,但是租房我们一般是通过中介或者是网站来实现租房的需求。以我通过python以行政区为单位,对比分析各行政区房源数量分布情况的爬起,就可以可视化的去比较多个房源对于租房也更有利,可以说是更快更方便的找到各个方面都符合自己心意房子。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
深圳各个区域租房信息爬取
2.主题式网络爬虫爬取的内容与数据特征分析
在"https//:sz.zufun.com"网站中爬取数据放入D盘命名是“house_info.csv”将其中租房信息数据按以下要求进行分析:
导入数据并对数据进行预处理;
分析各行政区的房源分布情况;
以小区为单位,分析各小区的房源数量;
对整个租房数据的户型进行分析;
分析租房数据的租金分布情况;
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实验思路:
确定目标:分析深圳市租房信息,探索租房市场趋势、租金分布、热门区域等相关信息。
数据收集:
网络爬虫:使用Python编写网络爬虫,从"https//:sz.zufun.com"租房信息网站获取深圳市的租房数据。
数据存储:将爬取房子信息的数据存储到本地文件中,以便后续分析使用。
数据清洗和预处理:将数据先导入库进行预处理。
数据清洗:对爬取的数据进行清洗,去除重复项、缺失值等,确保数据的准确性和完整性。
数据格式转换:将数据转换成适合分析的格式,如将字符串类型的租金转换为数值类型。
特征提取:从租房信息中提取关键特征,如租金、面积、房型、位置等。
数据分析:
租金分布分析:通过统计和可视化方法,探索租金的分布情况,包括平均租金、租金区间、不同区域租金对比等。
区域分析:分析不同区域的租房情况,包括热门区域、租金水平、供需关系等,可以使用地图可视化工具展示结果。
趋势分析:根据时间信息,分析租房市场的趋势变化,如季节性变化、价格波动等。
结果展示:
数据可视化:使用Python的数据可视化库(如Matplotlib、Seaborn等)对分析结果进行可视化,生成直方图、折线图、散点图等,直观展示数据分析结果。
报告撰写:编写数据分析报告,将关键的分析结果和发现进行总结和解释,以便后续参考和决策。
定期更新:定期运行爬虫程序,获取最新的租房数据,并进行数据分析,以保持数据的实时性和准确性。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
目标内容界面:

2.Htmls 页面解析

3.节点(标签)查找方法与遍历方法
打开网页的源码,然后用鼠标检查工具找打对应大概位置进行查找,先找大标签,再找其中的小标签。
我们这里把要获取的数据找着之后,然后在元素中对应位置分析。

四、网络爬虫程序设计
1.数据爬取与采集
以下为数据爬取过程代码
1 import requests 2 from bs4 import BeautifulSoup 3 #导入前两个库为爬虫所需要的库 4 5 import pandas as pd 6 #导入后面将数据转化格式的库 7 8 from retry.api import retry_call 9 10 url = "https//:sz.zufun.com" 11 #所需要访问的网页为https//:sz.zufun.com 12 13 14 15 response = requests.get(url) 16 if response.status_code==200: 17 print("请求成功") 18 # 发送GET请求获取页面内容 若请求成功则继续 否则输出请求失败 19 20 21 soup = BeautifulSoup(response.content, 'html.parser') 22 # 使用BeautifulSoup解析页面内容 并用'html.parser'的方法解析 23 #在页面的检查界面的元素找到需要的表格信息的html所在地 24 25 table = soup.find('div', attrs={"class": 'chart'}) 26 #在页面寻找到表格的总体class="chart" 所以用soup.find寻找chart总表 27 28 rows = table.find_all('tr') 29 #在检查界面发现所有的表格信息都在tr里面 所以用find_all寻找所有tr的信息放到rows里面 30 31 data = [] 32 # 先创建一个空的DataFrame来存储数据 33 34 35 for row in rows: 36 # 遍历每一行,并提取数据 37 38 cells = row.find_all('td') 39 #找到所有的单元格是td的 40 #用print(cells)查看有多少td 41 #发现是15个 让td长度为15的才通过录入到date里面 否则无法进入 42 43 if len(cells) == 15: 44 date=cells[0].text 45 Front_Area_1=cells[1].text 46 Front_Area_2=cells[2].text 47 Front_Area_3=cells[3].text 48 Front_Area_4=cells[4].text 49 Front_Area_5=cells[5].text 50 Back_Area_1 =cells[6].text 51 Back_Area_2 =cells[7].text 52 all_bonus =cells[8].text 53 first_note =cells[9].text 54 first_prize =cells[10].text 55 second_note =cells[11].text 56 second_prize=cells[12].text 57 Current_bankroll=cells[13].text 58 Award_date =cells[14].text 59 #将每一元素的地址放到不同的单元里面 并且转化为text形式 60 #转化为text形式是为了将数据更好的放到表格中 61 62 data.append([date, Front_Area_1, Front_Area_2, Front_Area_3, Front_Area_4, Front_Area_5, Back_Area_1 , Back_Area_2, 63 all_bonus, first_note, first_prize, second_note, second_prize, Current_bankroll, Award_date]) 64 #将所有数据放入到前面创建的data里面 65 66 df = pd.DataFrame(data, columns=['价格', '面积', '编号', '楼层', '位置1', '位置2', '小区', '地铁',]) 67 # 再将数据转换为DataFrame,加上列名 68 69 df.info_csv(' house_info.csv', index=True) 70 # 然后将文件导出为csv文件 71 else: 72 print("请求失败") 73 #若请求失败则直接返回请求失败
house_info.csv的部分如下
1)导入数据并清洗
将 house_info.csv文件导入
1 import pandas as pd 2 import numpy as np 3 detail = pd.read_csv(r"D:\house_info.csv", encoding="utf-8") 4 5 # print(detail.head()) 6 7 print("清洗前缺失值的数目:\n",detail.isnull().sum()) 8 9 # 删除detail的缺失值 10 11 d1 = detail.dropna(axis=0, how="any") 12 # 以d1 为数据源 13 14 # print(d1) 15 16 print("清洗后缺失值的数目:\n",d1.isnull().sum()) 17 18 # 从前向后查找和判断是否有重复值 19 20 print("重复值:",d1.duplicated().sum())
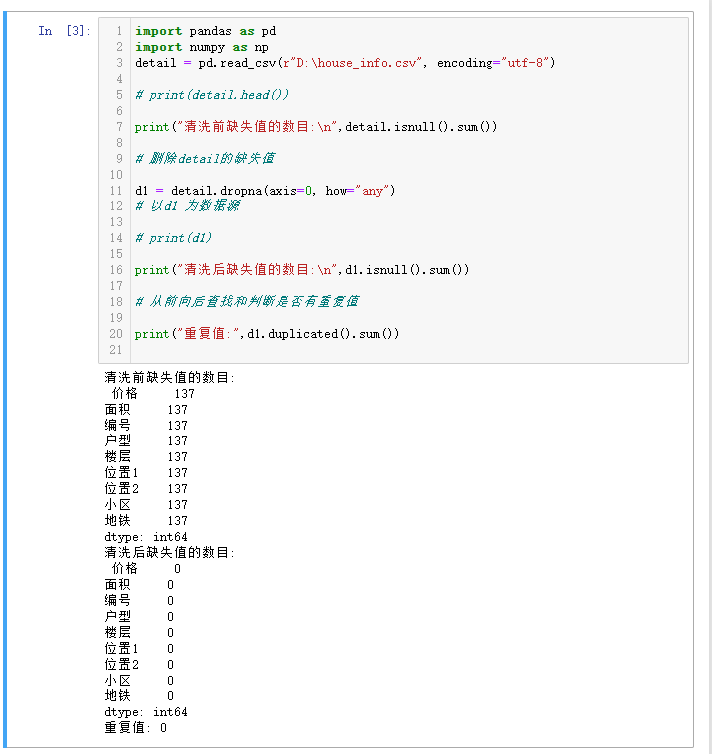
这里清洗了表格所缺失的内容
2)以下是各行政区房源分布
1 area = set(d1["位置1"]) 2 3 # 统计多少个行政区 4 5 print(area) 6 7 # 创建一个DataFrame 对象,筛选需要数据{行政区,房源数量} 8 9 d2 = pd.DataFrame({'行政区':d1["位置1"].unique(),'房源数量':[0]*len(area)}) 10 print(d2) 11 print('-'*20) 12 13 # groupby统计房源数量,并从小到大排序 14 15 groupby_area = d1.groupby(by="位置1").count() 16 print(groupby_area) 17 d2["房源数量"] = groupby_area.values 18 d2 = d2.sort_values(by=["房源数量"],ascending=True) 19 print(d2)

3).以下为小区房源数量TOP10代码以及运行结果
1 area_small = set(d1["小区"]) 2 3 # 统计多少个小区 4 # print(area_small) 5 6 7 # 创建一个DataFrame 对象,筛选需要数据{小区,小区房源数量} 8 9 d_samll = pd.DataFrame({"小区":d1["小区"].unique(),"小区房源数量":[0]*len(area_small) }) 10 print(d_samll) 11 print('-'*40) 12 13 # groupby统计小区房源数量,并从大到小排序 14 15 groupby_area = d1.groupby(by="小区").count() 16 17 # print(groupby_area) 18 19 d_samll["小区房源数量"] = groupby_area.values 20 d_samll = d_samll.sort_values(by=["小区房源数量"],ascending=False) 21 print(d_samll) 22 d_top10 = d_samll.head(10) 23 24 # 取前十 25 26 print("小区房源数量TOP10是:\n",d_top10)

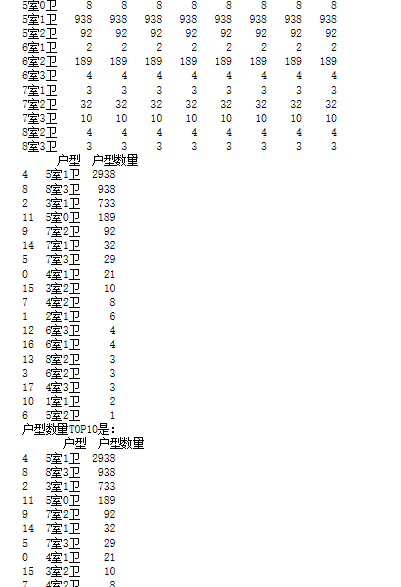
4).以下是户型TOP10分布代码以及运行结果
1 house_type = set(d1["户型"]) 2 # 统计多少个户型 3 4 print(house_type) 5 6 7 # 创建一个DataFrame 对象,筛选需要数据{户型,户型数量} 8 9 d_house = pd.DataFrame({"户型":d1["户型"].unique(),"户型数量":[0]*len(house_type) }) 10 print(d_house) 11 print('-'*40) 12 13 # groupby统计户型数量,并从大到小排序 14 15 groupby_area = d1.groupby(by="户型").count() 16 print(groupby_area) 17 d_house["户型数量"] = groupby_area.values 18 d_house = d_house.sort_values(by=["户型数量"],ascending=False) 19 print(d_house) 20 d_top10 = d_house.head(10) 21 # 取前十 22 print("户型数量TOP10是:\n",d_top10)

5)以下是租金分布代码以及运行结果
1 # 对每个行政区,进行租金价格平均分析 2 # 新建一个DataFrame对象,设置房租总金额和总面积初始值为0 3 4 5 print(area) 6 avg_rent = pd.DataFrame({'行政区':d1["位置1"].unique(),'房租总金额':[0]*len(area),'总面积':[0]*len(area) }) 7 print(avg_rent) 8 print('-'*40) 9 10 11 # 求总金额和总面积 12 13 sum_price = d1["价格"].groupby(d1["位置1"]).sum() 14 sum_area = d1["面积"].groupby(d1["位置1"]).sum() 15 avg_rent["房租总金额"] = sum_price.values 16 avg_rent["总面积"] = sum_area.values 17 print(avg_rent) 18 19 20 # 计算各区域每平方米房租价格,并保留2位小数 21 avg_rent['每平方米租金(元)'] = round(avg_rent['房租总金额']/avg_rent['总面积'],2) 22 print(avg_rent) 23 print("*-"*25) 24 25 26 # 合并需要的数据 27 rent_merge = pd.merge(d2,avg_rent) 28 rent_merge 29 30 # print(rent_merge)

4.数据分析与可视化
1)各行政区房源分布柱形图
1 # 绘图 2 3 import matplotlib.pyplot as plt 4 import matplotlib 5 matplotlib.rcParams['font.sans-serif']=['SimHei'] 6 matplotlib.rcParams['axes.unicode_minus']=False 7 8 X = d_top10["小区"] 9 print(X) 10 Y = d_top10["小区房源数量"] 11 print(Y) 12 plt.figure(figsize=(8,6),dpi=300) 13 plt.bar(X, Y, width=0.5, linewidth=2) 14 for i,j in zip(X, Y): 15 16 plt.text(i, j, "%d" % j, fontsize=12) 17 plt.xlabel("小区") 18 plt.ylabel("小区房源数量") 19 plt.title("小区房源数量TOP10") 20 plt.xticks(rotation=335) 21 plt.savefig(r"C:\Users\烤小鹅\Desktop\小区房源数量TOP10.png",dpi=400) 22 plt.show()
运行后得出以下
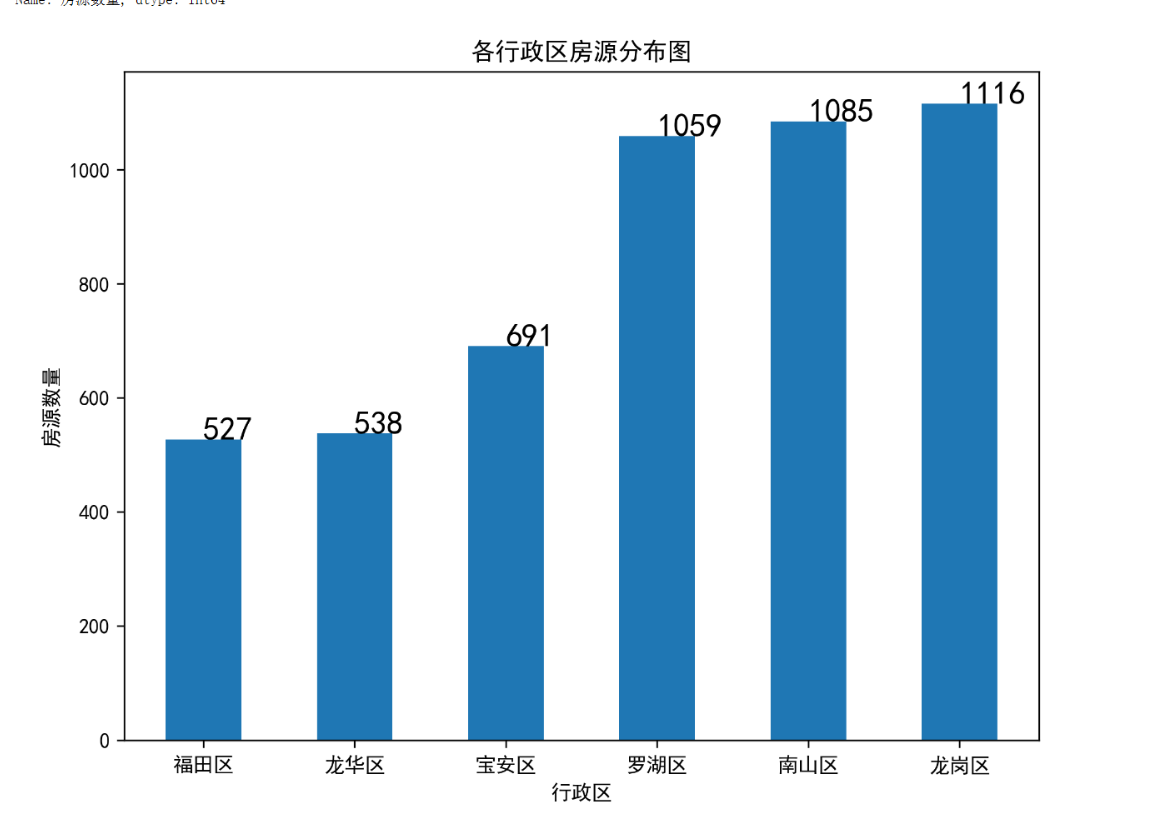
从数据可以看出:从行政区的福田区到龙岗区,房源的数量是逐渐增加的。
2)小区房源数量TOP10
1 # 绘图 2 3 import matplotlib.pyplot as plt 4 import matplotlib 5 matplotlib.rcParams['font.sans-serif']=['SimHei'] 6 matplotlib.rcParams['axes.unicode_minus']=False 7 8 X = d_top10["小区"] 9 print(X) 10 Y = d_top10["小区房源数量"] 11 print(Y) 12 plt.figure(figsize=(8,6),dpi=300) 13 plt.bar(X, Y, width=0.5, linewidth=2) 14 15 16 for i,j in zip(X, Y): 17 plt.text(i, j, "%d" % j, fontsize=12) 18 plt.xlabel("小区") 19 plt.ylabel("小区房源数量") 20 plt.title("小区房源数量TOP10") 21 plt.xticks(rotation=335) 22 plt.savefig(r"C:\Users\烤小鹅\Desktop\小区房源数量TOP10.png",dpi=400) 23 plt.show()
运行后得出

从图可知,小区的房源数量从 丰湖花园到 名仕阁逐渐递减,而且丰湖花园小区房源是其他小区的两倍左右,丰湖花园的房源很多,在该竞争领域很大优势。
3).小区户型TOP10分布
代码如下
1 # 绘图 2 3 4 import matplotlib.pyplot as plt 5 import matplotlib 6 matplotlib.rcParams['font.sans-serif']=['SimHei'] 7 matplotlib.rcParams['axes.unicode_minus']=False 8 9 X = d_top10["户型"] 10 # print(X) 11 Y = d_top10["户型数量"] 12 # print(Y) 13 plt.figure(figsize=(12,8),dpi=300) 14 # plt.bar(X, Y, width=0.5, linewidth=2) 15 b = plt.barh(X, Y, height=0.6, linewidth=1) 16 17 18 for i in b: 19 plt.text(i.get_width(),i.get_y()+0.2,i.get_width() ) 20 plt.ylabel("户型") 21 plt.xlabel("户型数量") 22 plt.title("户型数量TOP10") 23 plt.savefig(r"C:\Users\烤小鹅\Desktop\户型数量TOP10.png",dpi=400) 24 plt.show()
运行后得出以下
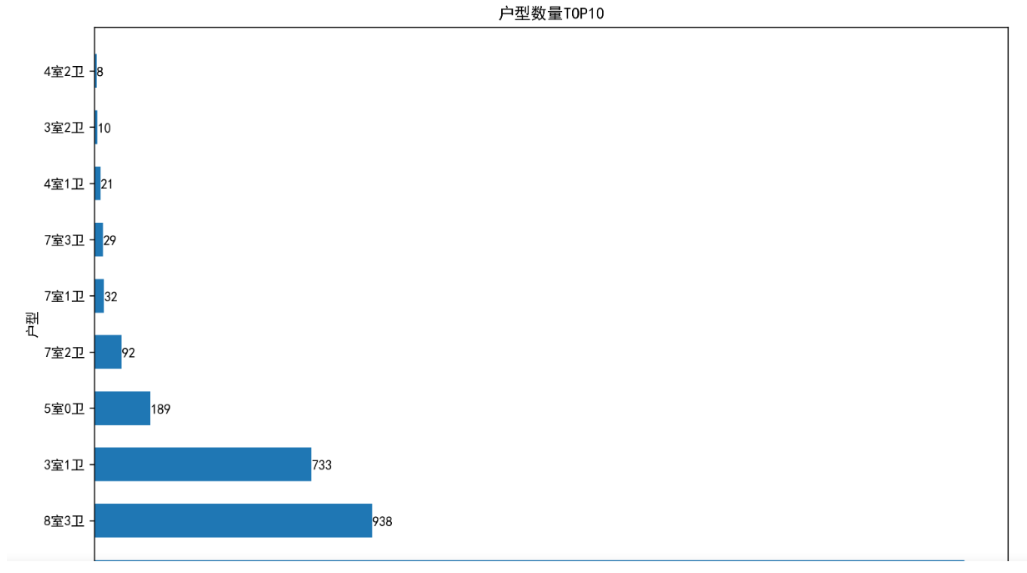
从图可知,众多户型中 5室1卫户型数量远远超过其他户型,可以看出这个户型是很多购买者喜欢的。
(4)租金分布图
1 #绘图 2 3 4 import matplotlib 5 import matplotlib.pyplot as plt 6 import matplotlib.ticker as mtick 7 from matplotlib.font_manager import FontProperties 8 matplotlib.rcParams['font.sans-serif']=['SimHei'] 9 matplotlib.rcParams['axes.unicode_minus']=False 10 num = rent_merge['房源数量'] 11 # 数量 12 13 price = rent_merge['每平方米租金(元)'] 14 # 价格 15 16 17 X = rent_merge["行政区"] 18 print(X) 19 20 21 # Y = rent_merge["房源数量"] 22 # print(Y) 23 fig = plt.figure(figsize=(8,6)) 24 axl = fig.add_subplot(111) 25 axl.plot(X, price,'or-',label = '价格') 26 axl.set_ylim([0,210]) 27 axl.set_ylabel('价格') 28 for i,j in zip(X, price): 29 plt.text(i, j, "%d" % j, fontsize=16) 30 plt.title("租金分布情况") 31 ax2 = axl.twinx() 32 plt.bar(X,num,width=0.4,color = 'green',label = '数量', linewidth=2) 33 ax2.set_ylabel('数量') 34 ax2.set_ylim([0,2000]) 35 36 37 for i,j in zip(X, num): 38 plt.text(i, j, "%d" % j, fontsize=16) 39 plt.title("租金分布情况") 40 plt.savefig(r"C:\Users\烤小鹅\Desktop\租金分布情况图.png",dpi=400) 41 plt.show()
得出以下结果
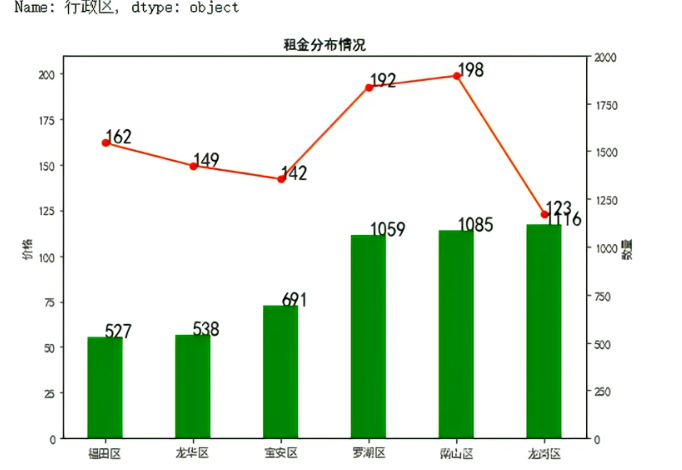
从折线图可以看出,罗湖区与南山区 房源数量比较多,但是租金价格平均是高的,龙岗区的房源数量多而且租金相比其他行政区是价廉的,适合毕业生、求职者去租房。
5.数据持久化
以下为数据持久化代码
1 import requests 2 from bs4 import BeautifulSoup 3 import sqlite3 4 import pandas as pd 5 6 7 response = requests.get(url) 8 if response.status_code == 200: 9 print("请求成功") 10 11 soup = BeautifulSoup(response.content, 'html.parser') 12 table = soup.find('div', attrs={"class": 'chart'}) 13 rows = table.find_all('tr') 14 15 data = [] 16 for row in rows: 17 cells = row.find_all('td') 18 if len(cells) == 15: 19 date = cells[0].text 20 Front_Area_1 = cells[1].text 21 # ... 继续提取其他数据 22 23 24 data.append([date, Front_Area_1, ...]) 25 26 df = pd.DataFrame(data, columns=['期号', '前区号码1', ...]) 27 28 29 # 连接到SQLite数据库 30 conn = sqlite3.connect('lottery_data.db') 31 cursor = conn.cursor() 32 33 34 # 创建表 35 create_table_query = ''' 36 CREATE TABLE IF NOT EXISTS lottery ( 37 id INTEGER PRIMARY KEY AUTOINCREMENT, 38 价格 TEXT, 39 面积 TEXT, 40 编号 TEXT, 41 户型 TEXT, 42 楼层 TEXT, 43 位置1 TEXT, 44 位置2 TEXT, 45 小区 TEXT, 46 地铁 TEXT, 47 48 49 ); 50 ''' 51 cursor.execute(create_table_query) 52 53 54 # 插入数据 55 insert_query = 'INSERT INTO lottery (期号, 前区号码1, 前区号码2, ..., 开奖日期) VALUES (?, ?, ?, ..., ?);' 56 cursor.executemany(insert_query, df.values.tolist()) 57 58 59 # 提交事务并关闭连接 60 conn.commit() 61 conn.close() 62 63 print("数据已保存到数据库") 64 else: 65 print("请求失败")
6.将以上各部分的代码汇总,附上完整程序代码
1 import pandas as pd 2 import numpy as np 3 detail = pd.read_csv(r"D:\house_info.csv", encoding="utf-8") 4 5 6 # print(detail.head()) 7 8 9 print("清洗前缺失值的数目:\n",detail.isnull().sum()) 10 11 12 # 删除detail的缺失值 13 14 15 d1 = detail.dropna(axis=0, how="any") 16 17 18 # 以d1 为数据源 19 20 # print(d1) 21 22 print("清洗后缺失值的数目:\n",d1.isnull().sum()) 23 24 # 从前向后查找和判断是否有重复值 25 26 print("重复值:",d1.duplicated().sum()) 27 area = set(d1["位置1"]) 28 29 30 # 统计多少个行政区 31 32 33 print(area) 34 35 36 # 创建一个DataFrame 对象,筛选需要数据{行政区,房源数量} 37 38 39 d2 = pd.DataFrame({'行政区':d1["位置1"].unique(),'房源数量':[0]*len(area)}) 40 print(d2) 41 print('-'*20) 42 43 44 # groupby统计房源数量,并从小到大排序 45 46 47 groupby_area = d1.groupby(by="位置1").count() 48 print(groupby_area) 49 d2["房源数量"] = groupby_area.values 50 d2 = d2.sort_values(by=["房源数量"],ascending=True) 51 print(d2) 52 area_small = set(d1["小区"]) 53 54 55 56 # 统计多少个小区 57 # print(area_small) 58 59 60 # 创建一个DataFrame 对象,筛选需要数据{小区,小区房源数量} 61 62 63 d_samll = pd.DataFrame({"小区":d1["小区"].unique(),"小区房源数量":[0]*len(area_small) }) 64 print(d_samll) 65 print('-'*40) 66 67 68 # groupby统计小区房源数量,并从大到小排序 69 70 71 groupby_area = d1.groupby(by="小区").count() 72 73 # print(groupby_area) 74 75 d_samll["小区房源数量"] = groupby_area.values 76 d_samll = d_samll.sort_values(by=["小区房源数量"],ascending=False) 77 print(d_samll) 78 d_top10 = d_samll.head(10) 79 80 81 # 取前十 82 83 84 print("小区房源数量TOP10是:\n",d_top10) 85 86 house_type = set(d1["户型"]) 87 # 统计多少个户型 88 89 90 print(house_type) 91 92 93 # 创建一个DataFrame 对象,筛选需要数据{户型,户型数量} 94 95 d_house = pd.DataFrame({"户型":d1["户型"].unique(),"户型数量":[0]*len(house_type) }) 96 print(d_house) 97 print('-'*40) 98 99 # groupby统计户型数量,并从大到小排序 100 101 groupby_area = d1.groupby(by="户型").count() 102 print(groupby_area) 103 d_house["户型数量"] = groupby_area.values 104 d_house = d_house.sort_values(by=["户型数量"],ascending=False) 105 print(d_house) 106 d_top10 = d_house.head(10) 107 # 取前十 108 print("户型数量TOP10是:\n",d_top10) 109 # 对每个行政区,进行租金价格平均分析 110 # 新建一个DataFrame对象,设置房租总金额和总面积初始值为0 111 112 113 114 print(area) 115 avg_rent = pd.DataFrame({'行政区':d1["位置1"].unique(),'房租总金额':[0]*len(area),'总面积':[0]*len(area) }) 116 print(avg_rent) 117 print('-'*40) 118 119 120 121 # 求总金额和总面积 122 123 sum_price = d1["价格"].groupby(d1["位置1"]).sum() 124 sum_area = d1["面积"].groupby(d1["位置1"]).sum() 125 avg_rent["房租总金额"] = sum_price.values 126 avg_rent["总面积"] = sum_area.values 127 print(avg_rent) 128 129 130 131 # 计算各区域每平方米房租价格,并保留2位小数 132 avg_rent['每平方米租金(元)'] = round(avg_rent['房租总金额']/avg_rent['总面积'],2) 133 print(avg_rent) 134 print("*-"*25) 135 136 137 # 合并需要的数据 138 rent_merge = pd.merge(d2,avg_rent) 139 rent_merge 140 141 142 # print(rent_merge) 143 import requests 144 from bs4 import BeautifulSoup 145 #导入前两个库为爬虫所需要的库 146 147 import pandas as pd 148 #导入后面将数据转化格式的库 149 150 from retry.api import retry_call 151 152 url = "https//:sz.zufun.com" 153 #所需要访问的网页为https//:sz.zufun.com 154 155 156 157 response = requests.get(url) 158 if response.status_code==200: 159 print("请求成功") 160 # 发送GET请求获取页面内容 若请求成功则继续 否则输出请求失败 161 162 163 soup = BeautifulSoup(response.content, 'html.parser') 164 # 使用BeautifulSoup解析页面内容 并用'html.parser'的方法解析 165 #在页面的检查界面的元素找到需要的表格信息的html所在地 166 167 table = soup.find('div', attrs={"class": 'chart'}) 168 #在页面寻找到表格的总体class="chart" 所以用soup.find寻找chart总表 169 170 rows = table.find_all('tr') 171 #在检查界面发现所有的表格信息都在tr里面 所以用find_all寻找所有tr的信息放到rows里面 172 173 data = [] 174 # 先创建一个空的DataFrame来存储数据 175 176 177 for row in rows: 178 # 遍历每一行,并提取数据 179 180 cells = row.find_all('td') 181 #找到所有的单元格是td的 182 #用print(cells)查看有多少td 183 #发现是15个 让td长度为15的才通过录入到date里面 否则无法进入 184 185 if len(cells) == 15: 186 date=cells[0].text 187 Front_Area_1=cells[1].text 188 Front_Area_2=cells[2].text 189 Front_Area_3=cells[3].text 190 Front_Area_4=cells[4].text 191 Front_Area_5=cells[5].text 192 Back_Area_1 =cells[6].text 193 Back_Area_2 =cells[7].text 194 all_bonus =cells[8].text 195 first_note =cells[9].text 196 first_prize =cells[10].text 197 second_note =cells[11].text 198 second_prize=cells[12].text 199 Current_bankroll=cells[13].text 200 Award_date =cells[14].text 201 #将每一元素的地址放到不同的单元里面 并且转化为text形式 202 #转化为text形式是为了将数据更好的放到表格中 203 204 data.append([date, Front_Area_1, Front_Area_2, Front_Area_3, Front_Area_4, Front_Area_5, Back_Area_1 , Back_Area_2, 205 all_bonus, first_note, first_prize, second_note, second_prize, Current_bankroll, Award_date]) 206 #将所有数据放入到前面创建的data里面 207 208 df = pd.DataFrame(data, columns=['价格', '面积', '编号', '楼层', '位置1', '位置2', '小区', '地铁',]) 209 # 再将数据转换为DataFrame,加上列名 210 211 df.info_csv(' house_info.csv', index=True) 212 # 然后将文件导出为csv文件 213 else: 214 print("请求失败") 215 #若请求失败则直接返回请求失败 216 # 绘图 217 218 219 import matplotlib.pyplot as plt 220 import matplotlib 221 matplotlib.rcParams['font.sans-serif']=['SimHei'] 222 matplotlib.rcParams['axes.unicode_minus']=False 223 224 X = d_top10["小区"] 225 print(X) 226 Y = d_top10["小区房源数量"] 227 print(Y) 228 plt.figure(figsize=(8,6),dpi=300) 229 plt.bar(X, Y, width=0.5, linewidth=2) 230 for i,j in zip(X, Y): 231 232 plt.text(i, j, "%d" % j, fontsize=12) 233 plt.xlabel("小区") 234 plt.ylabel("小区房源数量") 235 plt.title("小区房源数量TOP10") 236 plt.xticks(rotation=335) 237 plt.savefig(r"C:\Users\烤小鹅\Desktop\小区房源数量TOP10.png",dpi=400) 238 plt.show() 239 240 241 # 绘图 242 243 import matplotlib.pyplot as plt 244 import matplotlib 245 matplotlib.rcParams['font.sans-serif']=['SimHei'] 246 matplotlib.rcParams['axes.unicode_minus']=False 247 248 X = d_top10["小区"] 249 print(X) 250 Y = d_top10["小区房源数量"] 251 print(Y) 252 plt.figure(figsize=(8,6),dpi=300) 253 plt.bar(X, Y, width=0.5, linewidth=2) 254 255 256 for i,j in zip(X, Y): 257 plt.text(i, j, "%d" % j, fontsize=12) 258 plt.xlabel("小区") 259 plt.ylabel("小区房源数量") 260 plt.title("小区房源数量TOP10") 261 plt.xticks(rotation=335) 262 plt.savefig(r"C:\Users\烤小鹅\Desktop\小区房源数量TOP10.png",dpi=400) 263 plt.show() 264 265 # 绘图 266 267 268 import matplotlib.pyplot as plt 269 import matplotlib 270 matplotlib.rcParams['font.sans-serif']=['SimHei'] 271 matplotlib.rcParams['axes.unicode_minus']=False 272 273 X = d_top10["户型"] 274 # print(X) 275 Y = d_top10["户型数量"] 276 # print(Y) 277 plt.figure(figsize=(12,8),dpi=300) 278 # plt.bar(X, Y, width=0.5, linewidth=2) 279 b = plt.barh(X, Y, height=0.6, linewidth=1) 280 281 282 for i in b: 283 plt.text(i.get_width(),i.get_y()+0.2,i.get_width() ) 284 plt.ylabel("户型") 285 plt.xlabel("户型数量") 286 plt.title("户型数量TOP10") 287 plt.savefig(r"C:\Users\烤小鹅\Desktop\户型数量TOP10.png",dpi=400) 288 plt.show() 289 290 291 #绘图 292 293 import matplotlib 294 import matplotlib.pyplot as plt 295 import matplotlib.ticker as mtick 296 from matplotlib.font_manager import FontProperties 297 matplotlib.rcParams['font.sans-serif']=['SimHei'] 298 matplotlib.rcParams['axes.unicode_minus']=False 299 num = rent_merge['房源数量'] 300 # 数量 301 302 303 price = rent_merge['每平方米租金(元)'] 304 # 价格 305 306 307 308 X = rent_merge["行政区"] 309 print(X) 310 # Y = rent_merge["房源数量"] 311 # print(Y) 312 fig = plt.figure(figsize=(8,6)) 313 axl = fig.add_subplot(111) 314 axl.plot(X, price,'or-',label = '价格') 315 axl.set_ylim([0,210]) 316 axl.set_ylabel('价格') 317 318 319 for i,j in zip(X, price): 320 plt.text(i, j, "%d" % j, fontsize=16) 321 plt.title("租金分布情况") 322 ax2 = axl.twinx() 323 plt.bar(X,num,width=0.4,color = 'green',label = '数量', linewidth=2) 324 ax2.set_ylabel('数量') 325 ax2.set_ylim([0,2000]) 326 327 328 for i,j in zip(X, num): 329 plt.text(i, j, "%d" % j, fontsize=16) 330 plt.title("租金分布情况") 331 plt.savefig(r"C:\Users\锦樽\Desktop\租金分布情况图.png",dpi=400) 332 plt.show() 333 import requests 334 from bs4 import BeautifulSoup 335 import sqlite3 336 import pandas as pd 337 338 339 response = requests.get(url) 340 if response.status_code == 200: 341 print("请求成功") 342 343 soup = BeautifulSoup(response.content, 'html.parser') 344 table = soup.find('div', attrs={"class": 'chart'}) 345 rows = table.find_all('tr') 346 347 data = [] 348 for row in rows: 349 cells = row.find_all('td') 350 if len(cells) == 15: 351 date = cells[0].text 352 Front_Area_1 = cells[1].text 353 # ... 继续提取其他数据 354 355 356 data.append([date, Front_Area_1, ...]) 357 358 df = pd.DataFrame(data, columns=['期号', '前区号码1', ...]) 359 360 361 # 连接到SQLite数据库 362 conn = sqlite3.connect('lottery_data.db') 363 cursor = conn.cursor() 364 365 366 # 创建表 367 create_table_query = ''' 368 CREATE TABLE IF NOT EXISTS lottery ( 369 id INTEGER PRIMARY KEY AUTOINCREMENT, 370 价格 TEXT, 371 面积 TEXT, 372 编号 TEXT, 373 户型 TEXT, 374 楼层 TEXT, 375 位置1 TEXT, 376 位置2 TEXT, 377 小区 TEXT, 378 地铁 TEXT, 379 380 381 ); 382 ''' 383 cursor.execute(create_table_query) 384 385 386 # 插入数据 387 insert_query = 'INSERT INTO lottery (期号, 前区号码1, 前区号码2, ..., 开奖日期) VALUES (?, ?, ?, ..., ?);' 388 cursor.executemany(insert_query, df.values.tolist()) 389 390 391 # 提交事务并关闭连接 392 conn.commit() 393 conn.close() 394 395 print("数据已保存到数据库") 396 else: 397 print("请求失败")
五、总结以及遇到的问题
对本课程设计的整体完成情况做一个总结,通过这次利用python代码爬虫爬取网站数据并分析,得出(1).从行政区的福田区到龙岗区,房源的数量是逐渐增加的。(2).小区的房源数量从 丰湖花园到 名仕阁逐渐递减,而且丰湖花园小区房源是其他小区的两倍左右,丰湖花园的房源很多,在该竞争领域很大优势。(3).众多户型中 5室1卫户型数量远远超过其他户型,可以看出这个户型是很多购买者喜欢的。(4)从折线图可以看出,罗湖区与南山区 房源数量比较多,但是租金价格平均是高的,龙岗区的房源数量多而且租金相比其他行政区是价廉的,适合毕业生、求职者去租房。所以要是想要到深圳就业就可以考虑在龙岗区租房子,价格实惠,而且房源数量也很多。
这让我掌握了最基础的数据分析知识,体验了数据分析的乐趣,包括数据预处理,异常值的查找等,数据的合并和分组及聚合,还有数据可视化来直观的观察,分析数据,更加直观的获得自己想要的信息,也变得更加便捷。同样大多数人面临这样一个挑战:我们认识到数据可视化的必要性,但缺乏数据可视化方面的专业技能。部分原因可以归结于,数据可视化只是数据分析过程中的一个环节,数据分析师可能将精力花在获取数据、清洗整理数据、分析数据、建立模型。
问题:由于anaconda之前下载的版本问题,数据分析运行时缺少很多模块,根本运行不出来,我在cmd中用“pip list”查询模块想看看缺少什么模块,但是查询出来的结果并不乐观,可以说是基本上的模块都没有,想要安装运行所需要的模块也一直是安装失败。在查询“python”表示是安装成功,说明不是python的问题。之后在网上查询了才知道是我的anaconda版本问题。我将原本的anaconda彻底卸载(如果没有彻底卸载新安装的其他版本的anaconda也是不能使用的)通过“清华大学开源镜像网站”,重新下载了anaconda3-2021.11版本,之后再在cmd中查询现有的模块,但是还是缺少了两个模块,根据上网所查的知识安装了所需模块。折腾了许久之后终于解决了运行问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号