

结对编程--第四次作业
一.Fork仓库的地址和伙伴的地址
| github项目地址 | https://github.com/yatangtang/WordCount |
|---|---|
| 结对伙伴作业地址 | https://www.cnblogs.com/sunnyyt/p/11639271.html |
| 结对伙伴学号 姓名 | 201731062505 颜依婷 |
二.psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 1540 | 1750 |
| Estimate | 估计这个任务需要多少时间 | 1540 | 1750 |
| Development | 开发 | 450 | 540 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 60 |
| Design Spec | · 生成设计文档 | 60 | 40 |
| Design Review | · 设计复审 (和同事审核设计文档) | 50 | 60 |
| Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | · 具体设计 | 50 | 70 |
| Coding | · 具体编码 | 480 | 550 |
| Code Review | · 代码复审 | 50 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 130 |
| Reporting | 报告 | 100 | 100 |
| Test Report | · 测试报告 | 40 | 30 |
| Size Measurement | · 计算工作量 | 40 | 50 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1540 | 1750 |
三.项目代码设计包括测试代码部分设计
1.项目实现的基础功能:
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 英文字母:A-Z,a-z
- 字母数字符号:A-Z,a-z,0-9
- 分割符:空格,非字母数字符号
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
新增功能: - 词组统计:能统计文件夹中指定长度的词组的词频
- 自定义输出:能输出用户指定的前n多的单词与其数量
2.项目设计思路:
拿到题目后,我们有了大概的思路,但是逻辑关系不是很明确,所以我们也去看了相关的博客和c#有关的函数资料。
仔细梳理了作业要求后我们列出了几个所需的函数要求:
函数:1.统计字符 2.统计行数 3.统计单词 4.建立单词字典 5.字典中的单词排序 6.打开文件
两个类:一个主类,一个统计类。
我将主要函数的逻辑思路大致梳理如下:
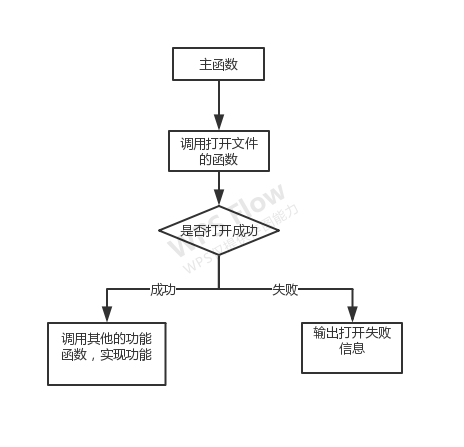
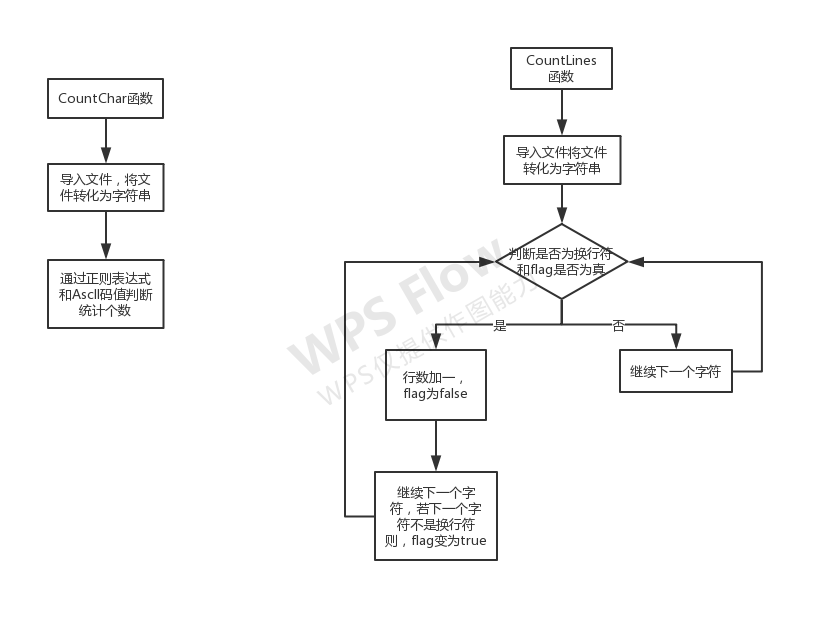
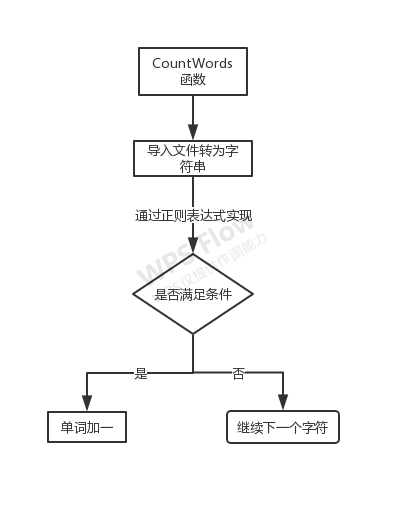
逻辑思路:
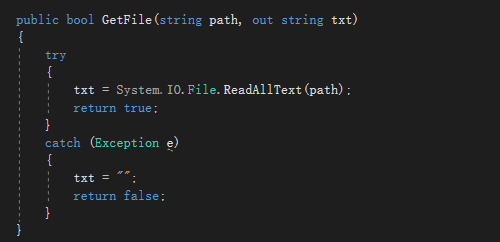
先要成功打开文件才能实现功能
具体实现各个函数的功能
建立单词词典:用字典来存储单词,首先判断是否满足单词的条件(长度大于三,是否以数字开头),以数字开头的就直接pass掉。满足长度大于4的单词存入字典。
建立完成后,调用统计单词函数通过对字典value值的来统计单词数,并对单词进行排序
输出到文件。
因为要满足用户的自定义词组长度,所以我想到在默认情况下,词组长度应该为一,而因为要进行前十个的排序所以i默认的输出单词个数应该是10,经过查阅资料发现了用out重载的方法来进行实现。
3.项目流程图
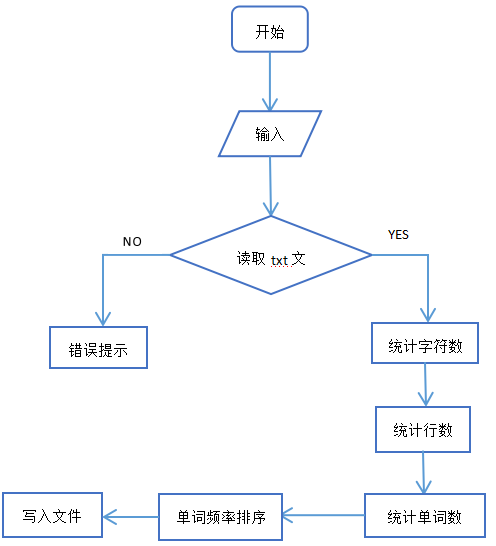
4.代码规范,和队友共同规定项目的解题代码规范。
代码规范链接https://www.cnblogs.com/sunnyyt/p/11635711.html
四.代码解析部分
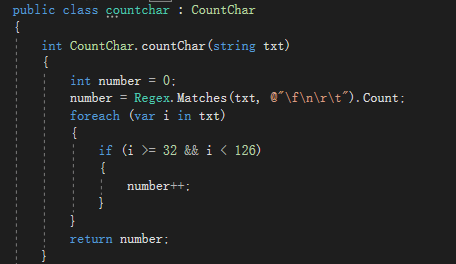
1.统计字符数方法
2.统计行数方法
3.统计单词数方法
最开始不知道应该怎么统计,也是查找资料和博客才学会了要用字典的方法来进行统计
参考链接https://www.cnblogs.com/gengaixue/p/4002244.html
参考链接https://www.cnblogs.com/wt-vip/p/5997094.html
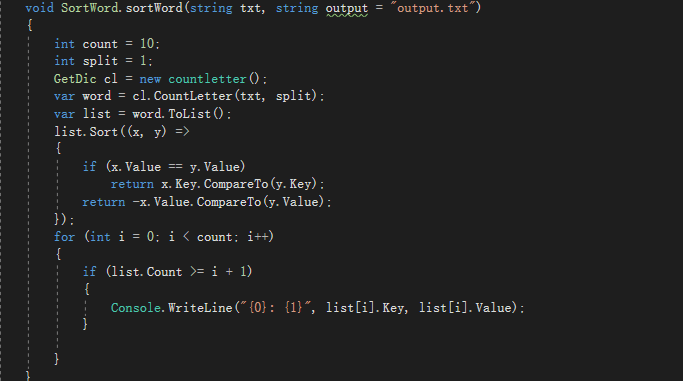
4.频率次数排序方法
对于频率次数排序,我们采用了将字典转化成list的方法来统计。
5.写入文件方法
因为上次作业也涉及到了写入文件,所以这次就比较熟悉。


五.测试代码部分设计及展示。
因为接口不能进行单元测试,所以在将函数进行接口封装前对每个函数先进行了相应的测试,以保证封装后的正确性,每个函数的测试都通过了,然后将函数分别进行了接口封装。其中在测试的时候统计字符的函数出现了错误,后来发现是因为在统计时用的Ascll值没有包含空白符,换行符之类的符号,所以产生了遗漏。 统计行数的也出现了错误,总是比实际行数多,没有判断出空行的存在,于是就加上了一个判断,判断是否连续两次出现换行符。改进后如下。
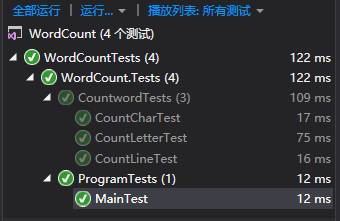
接口封装:把统计字符,行数,排序等功能分离了出来,主函数一下就轻巧了很多,而且其他函数重用率也得到了提高,每个函数之间的依赖性也很低。提高了代码的复用率。
各个函数:


运行结果:


新增功能:
对于根据用户自定义输入词组长度:采用了out重载的方法,结果如下:
但在之前的函数中是根据字典来进行排序,所以在用户输入固定词组长度时,就会按照用户规定的词组长度来统计单词个数


代码复审:
我在进行代码复审的时候,发现有几个函数出现了一些问题:
1.统计字符数方法:
在统计字符的时候,最开始是用的File Stream的Read方法,通过判断返回结果是否返回-1来统计,结果输出的结果不对,后面再看代码,再分析,发现其实可以直接用Ascll码还更加的简单。考虑到后面的函数结构以及传参方便所以采用了这种方式。我们个又通过正则表达式来判断换行符,空格等字符来统计。
2.统计行数方法
统计行数的时候,因为是通过判断换行符的方法来判断行数,但我们之前得到的结果总是比真实的情况多,而且刚好是行数加上空白行的行数,队友她用的读取文件的方法ReadLIne也是一样的情况,一直想了很久这个问题。后来才发现原来文本在转换成字符串的时候,空行变成了换行符,这样的话就统计了两次, 于是就加上了一个判断,判断是否连续两次出现换行符。
六.项目性能分析报告

七.计算模块部分异常处理说明
当用户输入错误时给出提示:
八.结对的过程:
这也是我第一次接触到结对编程的概念,于是就近和室友组成了一对,第一次体会到了结对编程的好处,对于一个项目两个人无论是效率还是质量来说都比一个人好得多,对方能够看到你看不到的地方,而且我发现当遇到问题的时候,即使对方可能也不知道答案,但在你和她说的时候,自己的思路也会越来越清晰。同时代码的规范让大家都能够更加能够读懂对方的代码,也会更加有效率。1+1确实是大于2的,但我觉得在结对编程开始进行项目之前,应该先商量好代码规范,不然在之后整合代码的时候会出现很打的问题影响效率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号