

结对编程
结对编程
| github地址 | github地址 |
|---|---|
| 结对编程伙伴 | 喻诗祺 |
| 伙伴学号 | 201831061418 |
1、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 230 | 303 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 25 |
| Design Spec | 生成设计文档 | 20 | 25 |
| Design Review | 设计复审 (和同事审核设计文档) | 5 | 8 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 25 | 25 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 50 | 45 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 80 | 105 |
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 30 | 35 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 50 |
| - | 合计 | 330 | 428 |
2、计算模块接口的设计与实现过程
这次作业我与喻诗祺同学一起完成的,使用c++,而且对c++还不熟悉,就对相应的功能简单实现。
编程的功能要求:
*统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
输出的单词统一为小写格式
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的格式为
· characters: number
· words: number
· lines: number
· : number
· : number
· …
只写了一个主函数,手动输入一段小短句,设置相应的变量与数组来记录字符数、单词数以及单词出现的个数。对要求的功能也只完成了一部分,在下列代码中给出详细的代码注释。
char str[1000]; //用于接收用户输入的字符串 char s[1000][40] = { 0 }; //用于储存每一个不同的单词 int i = 0; //字符串下标 int m = 0; //行 int n = 0; //列 char temp[40] = { 0 }; //用于临时储存字符串中方每个单词 int len = 0; //记录单词的长度 int count[1000] = { 0 }; //记录每个单词出现次数 int k; //单词每个字符下表 int flag = -1; //判断能否找到 int cnt[3] = { 0 }; //统计字符数、单词数、行数 int x = 0; cin.getline(str, 1000);
将所有字母统一小写化
for (int i = 0; i < 1000; i++) { if (str[i] >= 'A' && str[i] <= 'Z') str[i] += 32; }
进入文本,有空格就过滤掉,然后在进入字母与数字区,在遇到下一次空格或分隔符前将单词用一个数组所记录,再用二维数组统计所有单词,一维数组只用于统计单词长度以及与二维中比较再统计出现次数,然后在进行对一维数组的清零,直到文本结束。
``` while (str[i] == ' ') //作用是把开头的空格给过滤掉 { i++; cnt[2]++; } while (str[i] != 0) //外层循环判断str是否结束 { k = 0; //temp长度清零 flag = -1; //是否找到相同单词打标志位重置 while (str[i] >= 0 && str[i] <= 9 && str[i] != 0 || str[i] >= 'a' && str[i] <= 'z') //每一个非''位存入temp { temp[k] = str[i]; k++; //每次加一,用于计算单词长度 i++; cnt[2]++; } //if(temp[0]>=0&&temp[0]<=9||k<4) int x=0;x++; 不符合的单词数 cnt[0]++; if (temp[0] >= 0 && temp[0] <= 9 || k < 4) x++; //不符合的单词数 if (str[i - 1] != ' ') //一个单词录完后str[i]的值是空,find函数可以在s[][]中找到,会出现错乱 { //找到单词为单词在s[][]中的行号,否则为-1 for (int x = 0; x < m; x++) //传入了行号,每个都要比较 { if (strcmp(s[x], temp) == 0) flag = x; } if (flag == -1) { //若是-1就在s[][]中加入新单词 for (int j = 0; j < k; j++) { s[m][j] = temp[j]; } for (int j = 0; j < k; j++) //要清空,不然前面长的单词会影响后面的短的单词 { temp[j] = '\0'; } count[m] = 1; //count[]要记录单词出现一次 m++; //s[][]行号加一 } else { for (int j = 0; j < k; j++) { s[flag][j] = temp[j]; } for (int j = 0; j < k; j++) { temp[j] = '\0'; } count[flag] += 1; } } else { break; } while (str[i] == ' ' || str[i] == '.' || str[i] == ',' || str[i] == '?' || str[i] == '!') { i++; cnt[2]++; } } ```
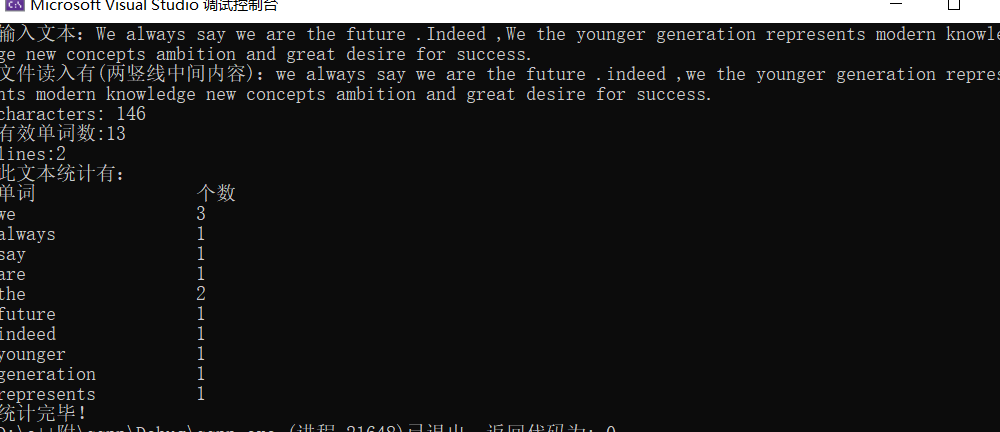
运行截图:
3、代码复审
- 由于我们使用的是C++语言,参考该博客介绍的编程规范
- 总的来说编写的代码还是比较粗糙,仅仅停留在可以完成规定的任务之上
- 我们在审核代码的时候发现有些功能函数并没有完成要求的全部,比如四个字母不算一个单词,大小写算一个单词。解决方面我们是在读取文件后把每个字母都换成大写字母。
4、性能分析测试
其中只有一个主函数,所以就没有什么多的分析以及探讨。


5、结对编程过程
在结对编程中可以看出两人的合作是大于一人的,我的结对伙伴喻诗祺与我在C++的知识领域里掌握程度太低,但仍然以自己C的功底来实现其中的一部分功能,附加功能没有操作。两人的工作效率还是十分高的(在且限的知识范围),还是在接近期限所完成的。在结对编程中,一人陷入深思时,另一个人的思想会带他走出思维盲区,这点是十分值得肯定的,两人的交流互帮互助会使两人对知识的模糊更清晰,而且也大大的减少了设计时间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号