


第一章 数据载入与初步观察
第一节 载入数据:
1.1 导入库
# 导入相关的库,绘图库有多种,视需而定,且pandas自身有绘图的函数 import numpy as np import pandas as pd import matplotlib.plplot as plt %matplotlib inline # 省略plt.show()
1.2 读取数据
# 根据数据文件的类型,选择相应的函数进行加载 data=pd.read_csv()
注意:
(1) csv文件一般是以逗号分隔,tsv文件是用制表符分隔,用pandas读取时对应不同的加载函数。但两者的差别主要在于分隔符,所以可通过设置sep或delimiter参数,所以pd.read_table()与pd.read_csv()均可加载这两种类型的数据文件
(2) chunksize参数:有时由于数据文件太大,一次性加载会占据过多内存,因此读取时可设置chunksize参数,分块读取。生成的对象是一个迭代器,而不是dataframe类型的数据,通过for循环遍历
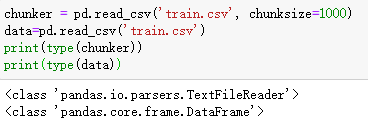
(3) 对索引与列名可进行适当的调整
# 设置行索引与列名 #1.读取时通过names参数与index_col参数设置 data=pd.read_csv('filaname.csv',names=['编号','产品名称', '订单数量', '订单金额'],set_index='index1') # sex_index的参数可以是列名,也可以是数值索引(第几列) # 2.使用rename()函数,columns和index都是字典,键为原来的标签,值为新的标签 data = data.rename(columns = {'订单编号':'编号', '产品':'产品名称', '数量':'订单数量', '金额':'订单金额'}, index = {0:'A', 1:'B', 2:'C', 3:'D', 4:'E', 5:'F'}) #3. 通过index属性与columns属性 data.columns = ['编号', '产品名称', '订单数量', '订单金额'] data.index = ['A', 'B', 'C', 'D', 'E', 'F'] # 4.通过set_index()函数修改行标签 data = pd.read_excel('订单表.xlsx', sheet_name = 3) data.set_index('订单编号')
1.3 观察数据
加载好数据之后,可通过head函数或tail函数,看数据的某些行
df.head() # 默认前5行,可指定行数 df.tail() # 默认后5行,可指定行数
需要注意数据中是否含有缺失值、重复值,也要注意数据的分布情况。如果想要快速了解数据集的信息,可通过pd.info()或pd.describe()函数
data.info() # 返回各列索引、列名、非空值的个数、数据类型 data.describe() # 返回一些描述统计的指标,包含数据个数、均值、标准差、最小值、1/4的百分位数、中位数、3/4的百分位数、最大值。可指定某列
第二节 探索性数据分析
2.1筛选数据
有些数据是分析中不需要的,所以要选出待分析的相应数据
# 选择行数据 # 1.loc与iloc data.loc['indexname1'] # 输入行标签 data.iloc[2] # 输入索引 # 2.选择多行 data.loc[['indexname1','indexname2']] # 输入行标签 data.iloc[[2,3]] # 输入索引 # 3.条件判断,以该判断结果为索引,进而选择数据 # 选择列数据 #1.指定列标签 data['columnsname1'] #2.属性 data.columnsname1 #3.选择多列,同选择多行类似 # 同时选择。loc与iloc均可,同时给出相应行列
2.2排序
# 依据某一或某些列的数值进行排序,by后可接列名或列表,ascending指定排序方式 dataframe.sort_values(by='columnnames1',ascending=True) #y依据索引进行排序,axis指定轴,ascending指定排序方式 dataframe.sort_index(axis=0,ascending=True)
2.3 dataframe运算
# 两数据框进行加法运算,相同索引、列进行运算,其他地方用None填充 df1=pd.Dataframe(np.random.randint(1,10,(4,2),columns=['a','b']) df2=pd.Dataframe(np.random.randint(5,15,(3,3),columns=['a','b','c']) # 对数据框进行统计运算:求和、求均值、求极值 df.sum() df.mean(). df.min() df.max() #整体 df['columnname'].sum() df['columnname'].mean() # 某列 df['columnname'].min() df['columnname'].max()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号