elasticsearch(lucene)索引数据过程
倒排索引存储-分段存储(lucene的功能)
在lucene中:lucene index包含了若干个segment
在elasticsearch中:index包含了若干主从shard,shard包干了若干segment
segment是elasticsearch中存储的最小文件单元,也就是分段存储,segment被设计为不可变的
新增:新创建索引时,新建一个segment存储新的数据
删除:由于segment是只读的,所以在索引文件中新增了.del文件,专门存储被删除的数据id,当查询时被删除的数据仍能被查询,进行查询结果合并时才会过滤掉,merge segment时会真正删除
更新:新增和删除的组合
segment的不可变性的优点
- 不需要锁(没有直接修改已经存在段的情况)
- 可以利用内存,由于segment不可变,所以segment被加载到内存后无需改变,只要内存足够,segment就可以长期驻村,大大提升查询性能
- 更新、新增的增量的方式很轻,性能好
segment的不可变性的缺点
- 删除操作不会马上删除有一定的空间浪费
- 频繁更新涉及到大量的删除动作,会有大量的空间浪费
- segment的数量可能非常多,对服务器的文件句柄消耗很大,查询性能会随着segment的数量增加而增加
新增数据的过程
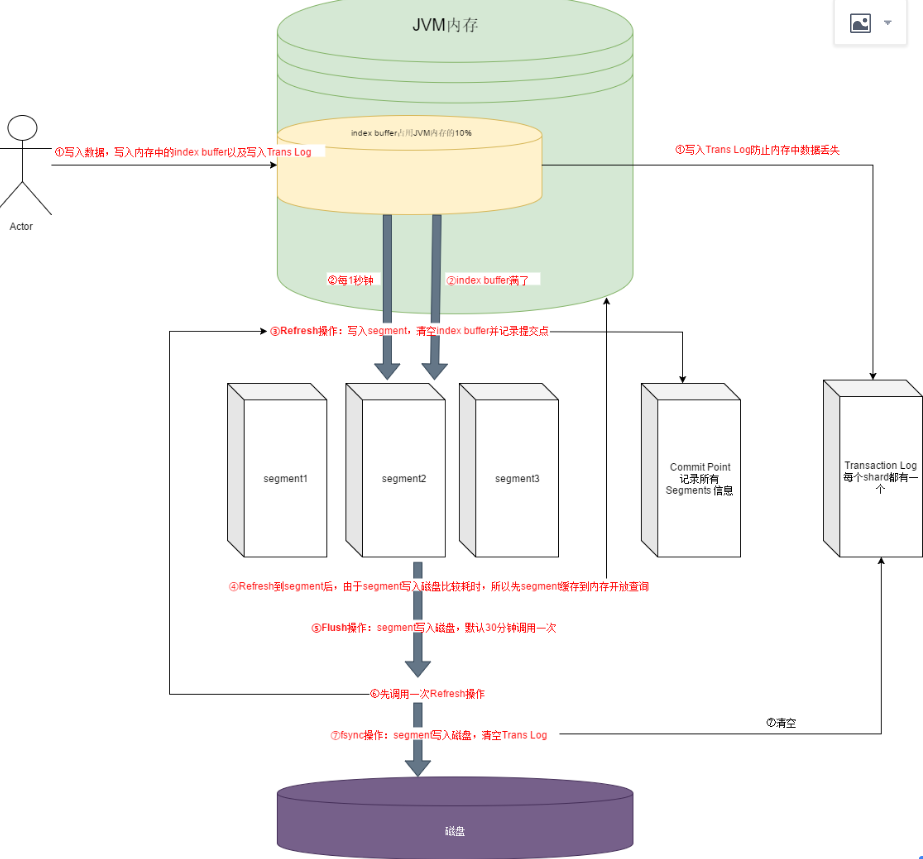
这个流程的目的是:提升写入性能(异步落盘)
1、保存到index buffer中,同时写入Transaction log(防止内存的数据丢失,有点想redo log)
2、当index buffer空间满了(默认占用jvm10%)或每1秒(通过index.refresh_interval 配置)执行Refresh操作,写入segment并清空index buffer(这里的1秒内是查不到刚保存的数据的,所以es也被成为近实时的搜索引擎)
3、于此同时将segment刷入内存,开放查询
4、flush操作将segment写入磁盘(默认30分钟执行一次)
flash操作包含:
- 调用一次refresh
- fsync:将segment写入磁盘
- 清空对应的trans log

 浙公网安备 33010602011771号
浙公网安备 33010602011771号