数据采集与融合技术实践第五次实验作业
数据采集与融合技术实践第五次实验作业
作业①:
1.题目
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。 使用Selenium框架爬取京东商城某类商品信息及图片。
-
候选网站:http://www.jd.com/
-
关键词:学生自由选择
-
输出信息:MySQL数据库存储和输出格式如下:
mNo mMark mPrice mNote mFile 000001 三星Galaxy 9199.00 三星Galaxy Note20 Ultra5G... 000001.jpg 000002......
2.实验思路
if __name__ == "__main__":
threads = []
url="http://www.jd.com/"
driver = OpenDriver(url)
db = DB()
db.openDB()
#搜索手机
Search("手机")
#获取数据部分
for page in range(1,3):
PullDown()
GetInfo()
if page == 2:
break
#翻页部分
ToNextPage()
for t in threads:
t.join()
db.closeDB()
driver.close()
print("爬取结束")
大题流程为进入首页、搜索关键词、获取两页的手机商品信息并存入MySQL数据库中
def OpenDriver(url):
chrome_options = Options()
# chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get(url) # 浏览器访问首页
return driver
该函数为打开浏览器进入首页
def Search(s):
locator = (By.XPATH, '//*[@id="key"]')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
InputText = driver.find_element(By.XPATH, '//*[@id="key"]')
InputText.send_keys(s)
FindButtom = driver.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button')
FindButtom.click()
time.sleep(5)
改函数传入一个s参数,为搜索的关键词,然后在首页中通过XPATH搜索搜索栏和搜索按钮,进行搜索关键词的操作
def PullDown():
time.sleep(0.5)
for i in range(100):
# Wwindow.scrollTo(x,y) x水平拖动,y垂直拖动
js = 'window.scrollTo(0,%s)' % (i * 200)
driver.execute_script(js)
time.sleep(0.07)#每下拉一次停0.07秒等待加载
该函数为网页下拉操作,用于加载所有商品信息
no = 1
def GetInfo():
global no
div = driver.find_element(By.XPATH, '//*[@id="J_goodsList"]/ul')
lis = div.find_elements(By.XPATH, './li')
for li in lis:
phone = li.find_element(By.XPATH,'./div')
note = phone.find_element(By.XPATH,'./div[@class="p-name p-name-type-2"]/a/em').text
mark = note.split(" ")[0]
mark = mark.replace("京品手机\n", "").replace(",", "").replace("\n", "")
note = note.replace("京品手机\n", "").replace(",", "").replace("\n", "")
#print(note)
#print(mark)
price = phone.find_element(By.XPATH,'./div[@class="p-price"]/strong/i').text
#print(price)
imgPath = phone.find_element(By.XPATH,'./div[@class="p-img"]/a/img').get_attribute("src")
#print(file)
db.insert("{0:{1}>6}".format(no,0),mark,price,note,"{0:{1}>6}.jpg".format(no,0))
T = threading.Thread(target=SaveImg, args=(imgPath, "{0:{1}>6}.jpg".format(no,0)))
T.setDaemon(False)
T.start()
threads.append(T)
no += 1
该函数为获取所需的信息,并将信息存储的数据库中,并采用多线程方法下载商品图片
def ToNextPage():
locator = (By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
NextPage = driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]')
#driver.execute_script('scrollBy(0,-200)')
NextPage.click()
该函数为查找“下一页”的按钮,实现翻页操作
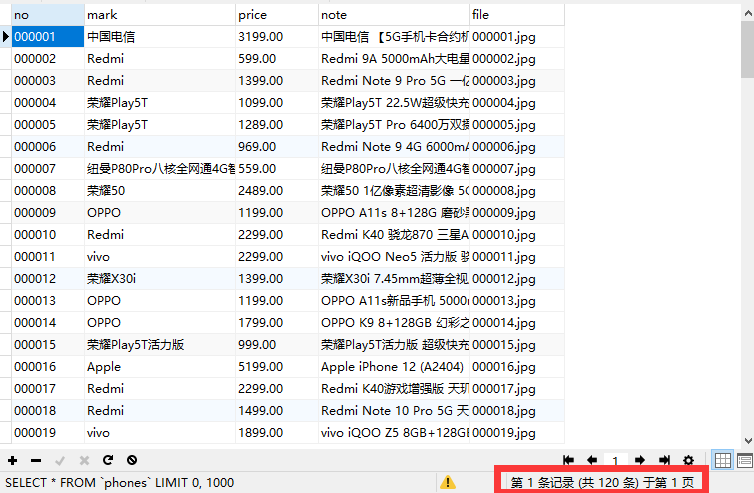
控制台输出、数据库存放结果、下载的图片如图所示
3.心得体会
作业①使用selenium来进行爬取信息,本次作业过程遇到的问题是爬取时有的图片url无法获取,原因是下拉速度太快导致图片还没加载,在每次下拉时停顿0.07秒即可解决问题
作业②:
1.题目
-
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待 HTML元素等内容。 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学 进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹 中,图片的名称用课程名来存储。
-
候选网站:中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义 设计表头:
Id cCourse cCollege cSchedule cCourseStatus cImgUrl 1 Python网络爬虫与信息提取 北京理工大学 已学3/18课时 2021年5月18日已结束 http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg 2......
2.实验思路
if __name__ == "__main__":
threads = []
url="https://www.icourse163.org/"
driver = OpenDriver(url)
db = DB()
db.openDB()
account = input("请输入账号:")
password = input("请输入密码:")
Login(account,password)
#获取数据部分
GetInfo()
for t in threads:
t.join()
db.closeDB()
driver.close()
print("爬取结束")
大体过程为进入首页、进行登录操作、获取信息并存入数据库
def Login(account,password):
#点登陆/注册
locator = (By.XPATH,'/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[2]/div/div/div/a')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
LoginButton = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[2]/div/div/div/a')
LoginButton.click()
#点其他登录方式
locator = (By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div[2]/span')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
LoginButton = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div[2]/span')
LoginButton.click()
#点手机号登录
locator = (By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
LoginButton = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]')
LoginButton.click()
#输入账号密码
iframe = driver.find_element(By.XPATH,"/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe")
driver.switch_to.frame(iframe)
locator = (By.XPATH, '//*[@id="phoneipt"]')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
InputText = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')
InputText.send_keys(account)
InputText = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
InputText.send_keys(password)
locator = (By.XPATH, '//*[@id="submitBtn"]')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
LoginButton = driver.find_element(By.XPATH, '//*[@id="submitBtn"]')
LoginButton.click()
#点我的课程
locator = (By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[4]/div')
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located(locator))
LoginButton = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[4]/div')
LoginButton.click()
该函数为模拟依次点击登录/注册、其他登录方式、手机号登录、输入账号密码、点击登录的操作,然后进入我的课程。
(过多重复代码可以用函数实现)
no = 1
def GetInfo():
time.sleep(2)
global no
divss = driver.find_element(By.XPATH, '//*[@id="j-coursewrap"]/div/div[1]')
divs = divss.find_elements(By.XPATH, './/div[@class="box"]')
for div in divs:
course = div.find_element(By.XPATH,'./a/div[@class="body"]//div[@class="title"]//span[@class="text"]').text
#print(course)
college = div.find_element(By.XPATH,'./a/div[@class="body"]//div[@class="school"]/a').text
#print(college)
schedule = div.find_element(By.XPATH,'./a/div[@class="body"]/div[@class="personal-info"]//a').text
#print(schedule)
courseStatus = div.find_element(By.XPATH,'./a/div[@class="body"]/div[@class="personal-info"]/div[@class="course-status"]').text
#print(courseStatus)
imgUrl = div.find_element(By.XPATH,'./a/div[@class="img"]/img').get_attribute("src")
#print(imgUrl)
db.insert(no,course,college,schedule,courseStatus,imgUrl)
T = threading.Thread(target=SaveImg, args=(imgUrl, course+".jpg"))
T.setDaemon(False)
T.start()
threads.append(T)
no += 1
该函数为获取需要的信息,并存入数据库,然后用多线程方法下载图片

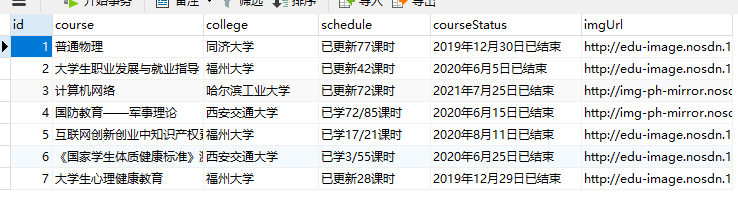
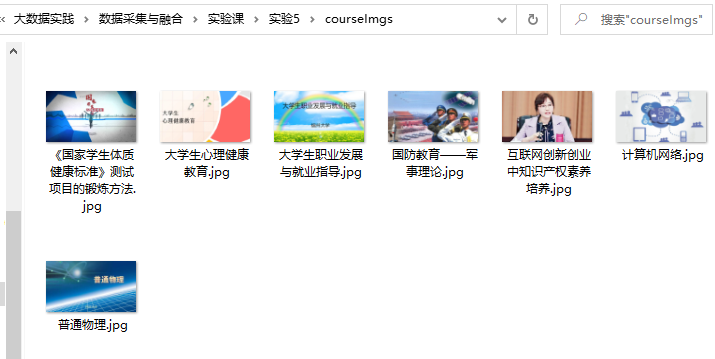
控制台输出、数据库存放结果、下载的图片如图所示
3.心得体会
作业②也使用selenium进行爬取信息,本次作业主要遇到的问题是部分按钮在复制xpath路径时为“//*[@id="auto-id-1637753529472"]”,但是该id中的数字是会变化的,因此在下一次运行的时候找不到该按钮,这时候copy full xpath即可,例如:
“/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[2]/div/div/div/a”
作业③:
1.题目
要求: 理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。 完成Flume日志采集实验,包含以下步骤: 任务一:开通MapReduce服务 任务二:Python脚本生成测试数据 任务三:配置Kafka 任务四:安装Flume客户端 任务五:配置Flume采集数据
2.实验思路
1、开通MapReduce服务

2、Python脚本生成测试数据

进入client编写py文件(实际是用xftp7移到里面的)
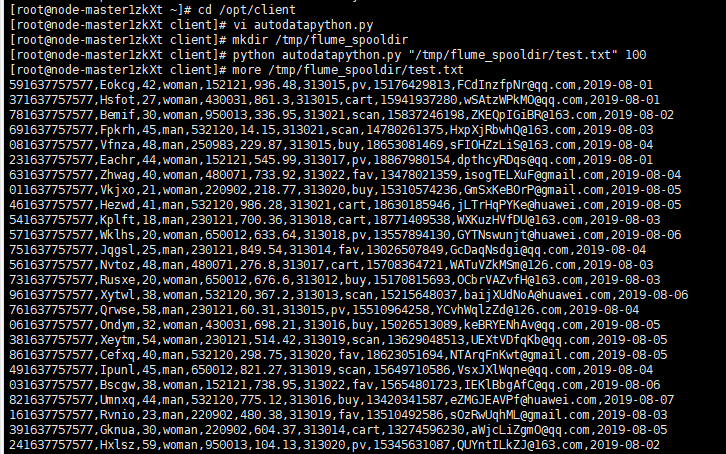
生成测试数据并查看
3、配置Kafka

配置环境变量,在kafka中创建topic

查看topic信息
4、安装Flume客户端
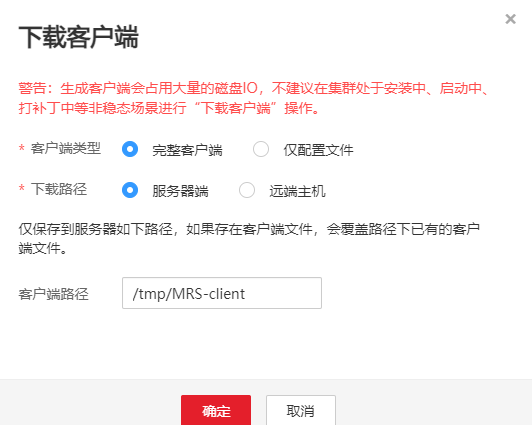
进入MRS Manager集群管理界面,打开服务管理点击flume,进入Flume服务,下载客户端
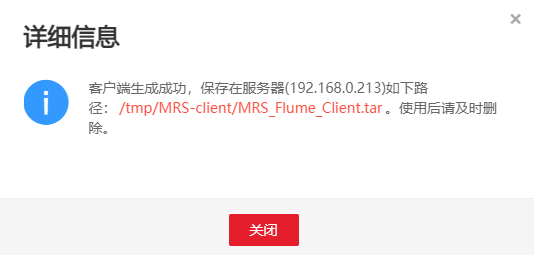
完成下载
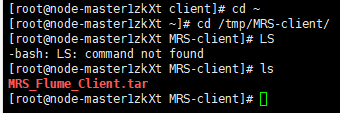

解压压缩包获取校验文件与客户端配置包

校验文件包
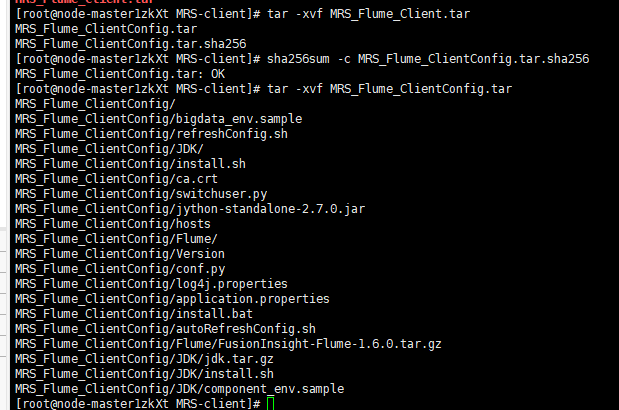
解压tar文件
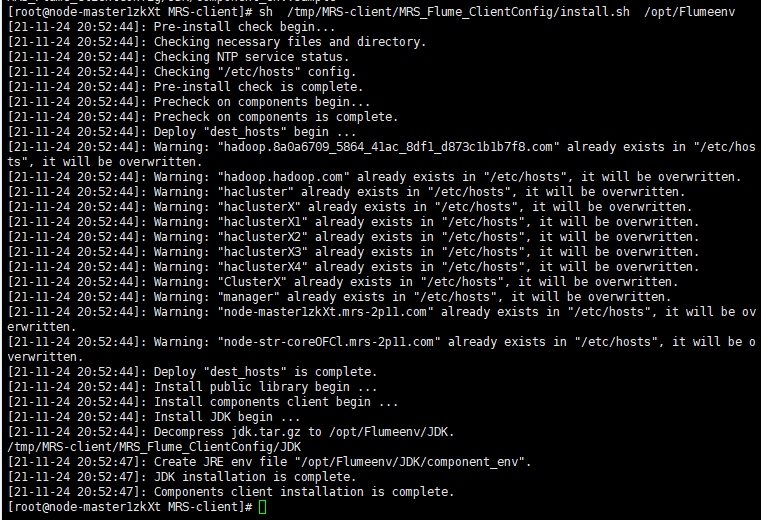
安装Flume环境变量

配置环境变量
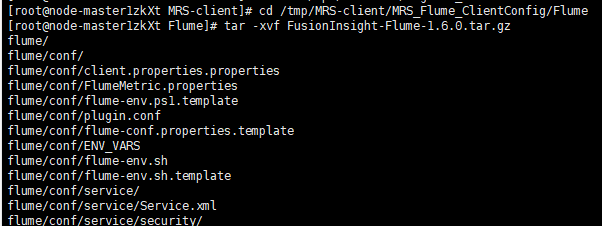
解压Flume客户端

安装Flume客户端

重启Flume服务
5、配置Flume采集数据

在conf目录下编辑文件properties.properties

执行

新开一个Xshell7窗口执行指令
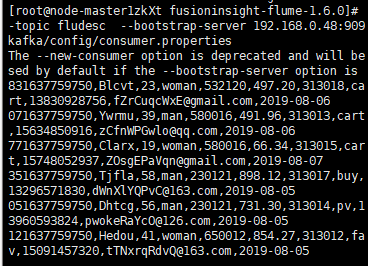
kafka中产生数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号