数据采集与融合技术实践第一次实验作业
数据采集与融合技术实践第一次实验作业
作业①
1.题目
– 要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
– 输出信息:
| 2020排名 | 2019排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 2 | 前2% | 中国人民大学 | 1069.0 |
| 2...... |
2.实验思路
if __name__ == "__main__":
rank,percentage,name,score = GetInfo(GetText())#获取网页源码并获取相应信息
Draw()#打印结果
主函数部分
def GetText():
try:
url = 'https://www.shanghairanking.cn/rankings/bcsr/2020/0812'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0'
}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)
data = resp.read().decode("utf-8")
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
unicodeData = dammit.unicode_markup
#print(unicodeData)
return unicodeData
except:
print("出现异常")
return None
GetText函数部分,为获取网页的源码
def GetInfo(data):
#排名
rank = []
reg = r'<div class="ranking" data-v-68e330ae>.*\n.*\n.*</div>'
for tag in re.findall(reg, data):
#筛选换行前的数字部分
reg2 = r'\d+\n'
rank.append(re.findall(reg2,tag)[0][0:-1])
GetInfo函数的第一部分

获取排名信息对应网页源码中的以上部分,用正则表达式精确定位到该位置,随后二次使用正则表达式获取其中排名的信息
#前%
percentage = []
reg = r'前.*%'
#用该reg筛选出来的前2个数据不需要
percentage = re.findall(reg, data)[2:]
GetInfo函数的第二部分
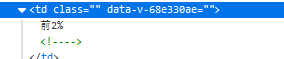
直接使用 “前”和“%”定位获取信息
#校名
name = []
reg = r'class="name-cn" data-v-b80b4d60>.*</a>'
for tag in re.findall(reg, data):
#去除所有数字字母和其他符号,只留下中文
reg2 = r'[^a-zA-Z0-9<>/"= !_:.,-]+'
name.append(re.findall(reg2, tag)[0])
GetInfo函数的第三部分

reg的信息对应以上部分,随后用二次正则提取中文部分,即校名
#总分
score = []
reg = r'<!----> <!----> <!----> <!----></div></div></td><td data-v-68e330ae>.*\n.*\n.*</td>'
for tag in re.findall(reg, data):
reg2 = r'\d+.\d\n'
score.append(re.findall(reg2, tag)[0][0:-1])
return rank,percentage,name,score
GetInfo函数的第四部分
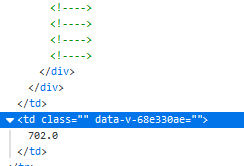
通过总分之前的四个来定位总分,从而获取总分信息
最后返回获得的4个数据
def Draw():
# 制表
print("{0:{4}<5}\t{1:{4}<10}\t{2:{4}<10}\t{3:{4}<10}".format("排名","全部层次","学校类型","总分", chr(12288)))
for i in range(len(rank)):
print("{0:{4}<5}\t{1:{4}<10}\t{2:{4}^8}\t{3:{4}^14}".format(rank[i], percentage[i], name[i], score[i], chr(12288)))
最后制表函数

最后运行结果如上
3.心得体会
正则表达式不会默认匹配\n字符,因此在需要获取带有\n的信息时要采取相应措施,例如我在reg里添加了\n作为匹配对象。制表时通过使用chr(12288)让表格相对整齐,但使用时表头和内容部分还是对不上且找不到问题所在,最后通过微调让表头和内容相对排列整齐
作业②
1.题目
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
– 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
2.实验思路
if __name__ == "__main__":
city,aqi,pm25,so2,no2,co,pollution = GetInfo(GetSoup())
Draw()
作业②主体框架与作业①类似,通过获取网页内容,而后获取需要的信息,最后打印表格
def GetSoup():
try:
url = 'https://datacenter.mee.gov.cn/aqiweb2/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3776.400'
}
r = requests.get(url=url, headers=headers)
r.encoding = 'utf-8'#修改编码方式
#print(r.text)
soup = BeautifulSoup(r.content, 'lxml')
#print(soup)
#print(soup.prettify())
return soup
except:
print("出现异常")
return None
获取网页内容的方法从作业①的request变为requests,使用BeautifulSoup获取整理好的soup
def GetInfo(soup):
tags = soup.select('td[style="text-align: center; "]')
city = []
aqi = []
pm25 = []
#pm10 = []
so2 = []
no2 = []
co = []
#o3 = []
pollution = []
for index in range(len(tags)):
tag = tags[index].text.strip()
#print(tag)
if index%9 == 0:
city.append(tag)
if index%9 == 1:
aqi.append(tag)
if index%9 == 2:
pm25.append(tag)
# if index%9 == 3:
# pm10.append(tag)
if index%9 == 4:
so2.append(tag)
if index%9 == 5:
no2.append(tag)
if index%9 == 6:
co.append(tag)
# if index%9 == 7:
# o3.append(tag)
if index%9 == 8:
pollution.append(tag)
return city,aqi,pm25,so2,no2,co,pollution
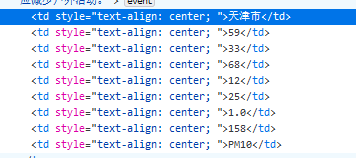
观察发现所有信息都在相同的格式里,通过select获取到所有的信息,然后遍历将信息分类存好并返回所有的信息
def Draw():
# 制表
print("{0:{8}<6}\t{1:{8}<10}\t{2:{8}<8}\t{3:{8}<10}\t{4:{8}<8}\t{5:{8}<8}\t{6:{8}<8}\t{7:{8}<8}\t".format("序号","城市","AQI","PM2.5","SO2","No2","Co","首要污染物", chr(12288)))
for i in range(len(city)):
print("{0:{8}<8}\t{1:{8}<10}\t{2:{8}<8}\t{3:{8}<8}\t{4:{8}<8}\t{5:{8}<8}\t{6:{8}<8}\t{7:{8}<8}\t".format(
i+1,city[i],aqi[i],pm25[i],so2[i],no2[i],co[i],pollution[i], chr(12288)))
最后制表部分,大体与作业①类似
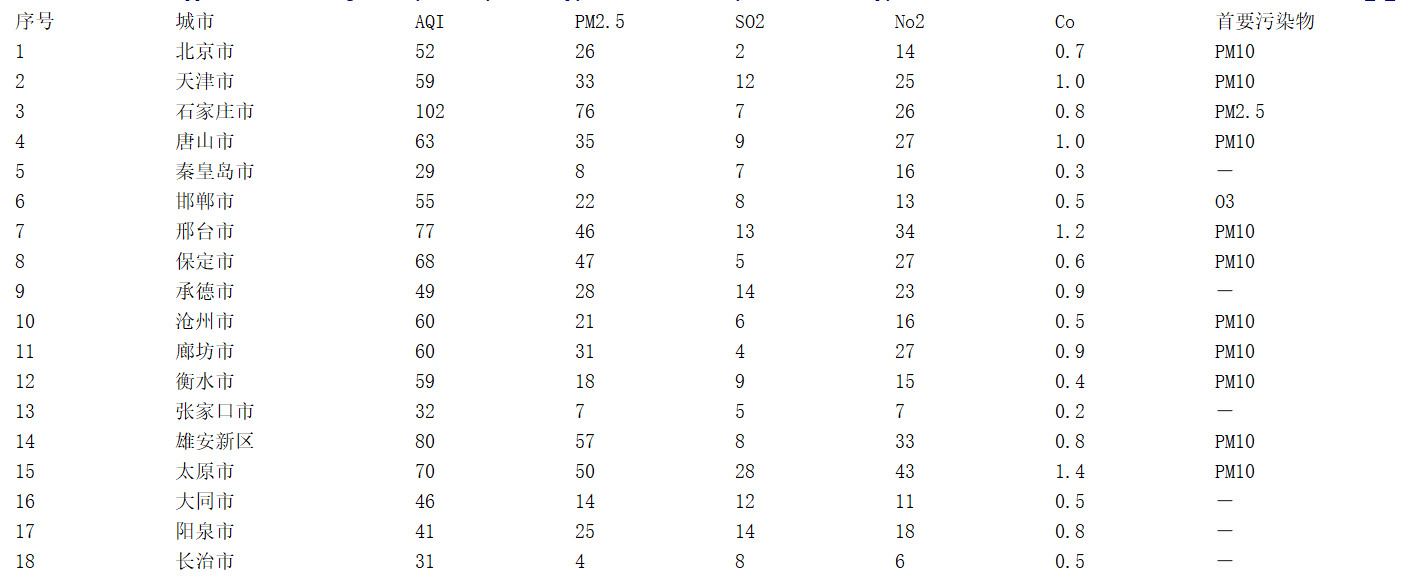
运行结果
3.心得体会
作业②巩固了有关Beautiful Soup库的用法,本次作业较为简单
作业③
1.题目
– 要求:使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/)爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
2.实验思路
if __name__ == "__main__":
imgPaths = GetInfo(GetText())
SaveImg()
框架与作业①②类似,获取网页源码、获取需要的信息、保存图片
def GetText():
try:
url = 'http://news.fzu.edu.cn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:92.0) Gecko/20100101 Firefox/92.0'
}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)
data = resp.read().decode("utf-8")
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
unicodeData = dammit.unicode_markup
#print(unicodeData)
return unicodeData
作业③使用request方法获取网页数据
def GetInfo(data):
reg = r'<img.*jpg'
imgPaths = []
for tag in re.findall(reg,data):
#print(tag)
#拼凑完整的图片路径
imgPaths.append("http://news.fzu.edu.cn" + tag[10:])
return imgPaths

观察后,用正则表达式获取所有图片路径,并拼凑成一个完整的路径
def SaveImg():
for index in range(len(imgPaths)):
imgPath = imgPaths[index]
#print(imgPath)
with open("./实验1_3_3图片/"+str(index)+ ".jpg", 'wb') as img:
img.write(requests.get(imgPath).content# 把图片的二进制数据写入文件
用requests方法获取图片信息,将图片的二进制数据写入文件

运行结果,共计12张jpg图片
3.心得体会
本实验与之前爬取商品网站图片的作业类似,需要保存图片,需要获取图片并转化为二进制数据保存下来。这次实验获取到的图片路径均为相对路径,需要自己拼成一个完整的路径才能获取到图片的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号