
51job 数据采集和分析
一.网络爬虫设计方案:
1.主题网络爬虫名称:51job 招聘网站信息数据采集
2.主题网络爬虫爬取的内容:采集python岗位薪资,职位,城市,学历等信息
3.主题式网络爬虫设计方案概述:进入网站搜索python并勾选对应学历,确定网址url后翻页获取每一页的html代码并解析出对应数据,期间进行数据清洗,将不规范数据从源头去除,然后保存至字典,再利用 xlsxwriter 模块存入excel表格,最后进行数据可视化处理,绘制各城市薪资占比,各学历岗位热度,各学历薪资分布等信息图
二.主题页面的结构特征分析:
1.主题页面结构特征分析:每一条对应的岗位信息都在class='el' 的div标签中,我们可使用xpath解析出每一个div再对每一条岗位进行解析,这样可以避免结构不同所带来的数据不精准现象。
2.页面解析
三:网络爬虫程序设计:
1.数据采集
import requests
from lxml import etree
from xlsxwriter import Workbook
# urls_0*列表存放的网址是通过修改url参数page实现的,循环100次即得到前100页的url,这里我们爬取四种学历对应的所以页数
# 博士学历,06
urls_06 = []
for page in range(1, 5):
urls_06.append("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=06&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(page))
"https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=03&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
"https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=04&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
# 硕士学历,05
urls_05 = []
for page in range(1, 59):
urls_05.append("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=05&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(page))
# 本科学历,04
urls_04 = []
for page in range(1, 407):
urls_04.append("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=04&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(page))
# 专科学历,03
urls_03 = []
for page in range(1, 103):
urls_03.append("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=03&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(page))
# 定义获取数据的函数
def get_data(tablename):
# 声明四种学历,判断传入的tablename是哪种学历,对应取出urls
educ = ['专科', '本科', '硕士', '博士']
url_infos = [urls_03, urls_04, urls_05, urls_06]
urls = []
# 遍历判断出正确的学历目标url信息
for k, i in enumerate(educ):
if tablename == i:
urls = url_infos[k]
# infos用来存储所有信息
infos = []
# 取出一页的链接逐条爬取
for url in urls:
# 打印链接
print(url)
# 获取页面源码
con = requests.get(url).content.decode("gbk")
# 创建xpath对象解析页面
xp = etree.HTML(con)
# 因为在招聘平台上有个别公司没有给出薪资,所以我们不可以直接去所有信息,需要逐条判断
html = xp.xpath("//div[@class='dw_table']//div[@class='el']")
# 取出单条信息对应的xpath对象
for h in html:
# 解析出岗位名称
title = h.xpath('p/span/a/text()')
if title:
# 将多余空格字符去除
title = title[0].replace(' ', '')
# 取出公司名称
gs_name = h.xpath('span[@class="t2"]/a/text()')[0]
# 取出工作地址
work_address = h.xpath('span[@class="t3"]/text()')[0]
# 取出薪资
money = h.xpath('span[@class="t4"]/text()')
# 判断该岗位是否开出薪资范围,如果有则取出,没有则用暂无提示
if money:
money = money[0]
else:
# money = '暂无'
# 如果该公司没有给出明确的薪资范围则不在我们爬取的目标中,跳过此层循环
continue
# 将一个公司的对应信息存入infos列表中
infos.append({
'职位': title,
'公司名': gs_name,
'地址': work_address,
'薪资': money
})
# 将信息列表infos存入excel表格,表格名称即tablename
players = infos
ordered_list = ["职位", "公司名", "地址", "薪资"]
wb = Workbook("./excels/%s.xlsx" % tablename)
ws = wb.add_worksheet("New Sheet")
first_row = 0
for header in ordered_list:
col = ordered_list.index(header)
ws.write(first_row, col, header)
row = 1
for player in players:
for _key, _value in player.items():
col = ordered_list.index(_key)
ws.write(row, col, _value)
row += 1
wb.close()
# 定义列表存入四种学历
educ = ['专科', '本科', '硕士', '博士']
for v in educ:
# 取出一条学历传入get_data函数
get_data(v)
保存成功:


2.数据清洗和处理
为减少代码冗余,我们在采集过程中就引入了数据的处理和清洗
3.数据分析与可视化
(1)地区热度词云图
import io
import sys
import jieba
from matplotlib import pyplot as plt
import matplotlib as mpl
from wordcloud import WordCloud
from xlrd import open_workbook
f = ''
for filename in ['专科','本科','硕士','博士']:
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
workbook = open_workbook(r'./excels/{}.xlsx'.format(filename)) # 打开xls文件
sheet_name= workbook.sheet_names() # 打印所有sheet名称,是个列表
sheet = workbook.sheet_by_index(0) # 根据sheet索引读取sheet中的所有内容
content = sheet.col_values(2)[0:] # 第3列内容
for i in content:
f += i[:2]
# 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
cut_text = " ".join(jieba.cut(f))
wordcloud = WordCloud(
# 设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
font_path="C:/Windows/Fonts/simfang.ttf",
# 设置了背景,宽高
background_color="white", width=2000, height=1200).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.savefig('地区热度词云图.png')
效果:

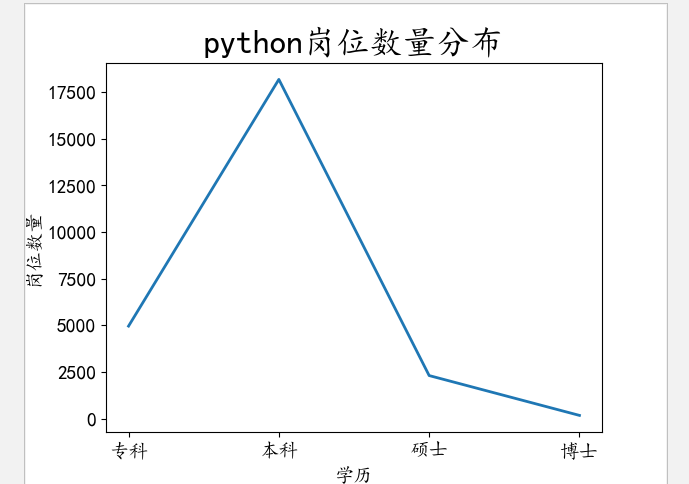
(2) 岗位数量折线图示
import io
import sys
from matplotlib import pyplot as plt
import matplotlib as mpl
from xlrd import open_workbook
nums_list = []
for i in ['专科','本科','硕士','博士']:
filename = i
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
workbook = open_workbook(r'./excels/{}.xlsx'.format(filename)) # 打开xls文件
sheet_name= workbook.sheet_names() # 打印所有sheet名称,是个列表
sheet = workbook.sheet_by_index(0) # 根据sheet索引读取sheet中的所有内容
content = sheet.col_values(0)[1:] # 第1列内容
nums_list.append(len(content))
input_values = ['专科','本科','硕士','博士']
squares = nums_list
# 生成折现图
plt.plot(input_values, squares, linewidth=2,) # 调用绘制函数,传入输入参数和输出参数
plt.title("python岗位数量分布", fontsize=24) # 指定标题,并设置标题字体大小
plt.xlabel("学历", fontsize=14) # 指定X坐标轴的标签,并设置标签字体大小
plt.ylabel("岗位数量", fontsize=14) # 指定Y坐标轴的标签,并设置标签字体大小
plt.tick_params(axis='both', labelsize=14) # 参数axis值为both,代表要设置横纵的刻度标记,标记大小为14
plt.savefig("./岗位数量折线图示.png") # 打开matplotlib查看器,并保存绘制的图形
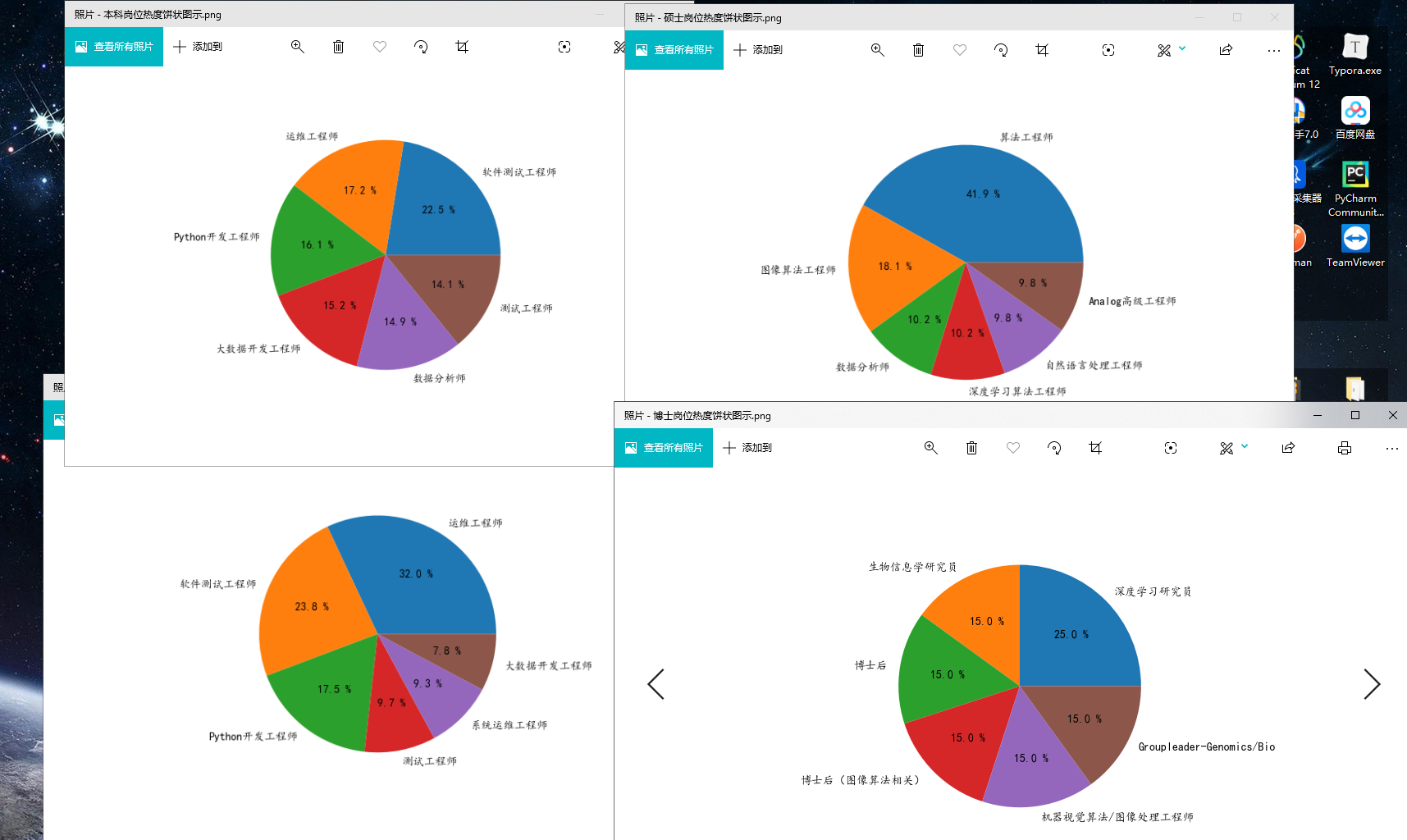
(3)各学历对应职位占比
import io
import sys
from matplotlib import pyplot as plt
import matplotlib as mpl
from xlrd import open_workbook
filename = '专科' # 替换学历名称运行程序即可得到四张图片
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
workbook = open_workbook(r'./excels/{}.xlsx'.format(filename)) # 打开xls文件
sheet_name= workbook.sheet_names() # 打印所有sheet名称,是个列表
sheet = workbook.sheet_by_index(0) # 根据sheet索引读取sheet中的所有内容
content = sheet.col_values(0)[1:] # 第1列内容
new_con = []
for i in content:
new_con.append(i.replace('\r','').replace('\n',''))
nums = []
temp = {}
for m in new_con:
# 循环判断薪资是否在nums列表中
if m not in nums:
# 不在则添加一个值为该薪资的键
nums.append(m)
temp[m] = 0
if m in nums:
# 在则将该建对应的值加1
temp[m] = temp[m] + 1
# 利用sorted函数对该字典排序
new_title = sorted(temp.items(), key=lambda item: item[1], reverse=True)[0:6]
nums = []
input_values = []
for i in new_title:
nums.append(i[1])
input_values.append(i[0])
sum_nums = sum(nums)
squares = [x/sum_nums for x in nums]
print(input_values)
print(squares)
# 保证圆形
plt.axes(aspect=1)
plt.pie(x=squares, labels=input_values, autopct='%3.1f %%')
plt.savefig("./岗位热度图示/{}岗位热度饼状图示.png".format(filename))
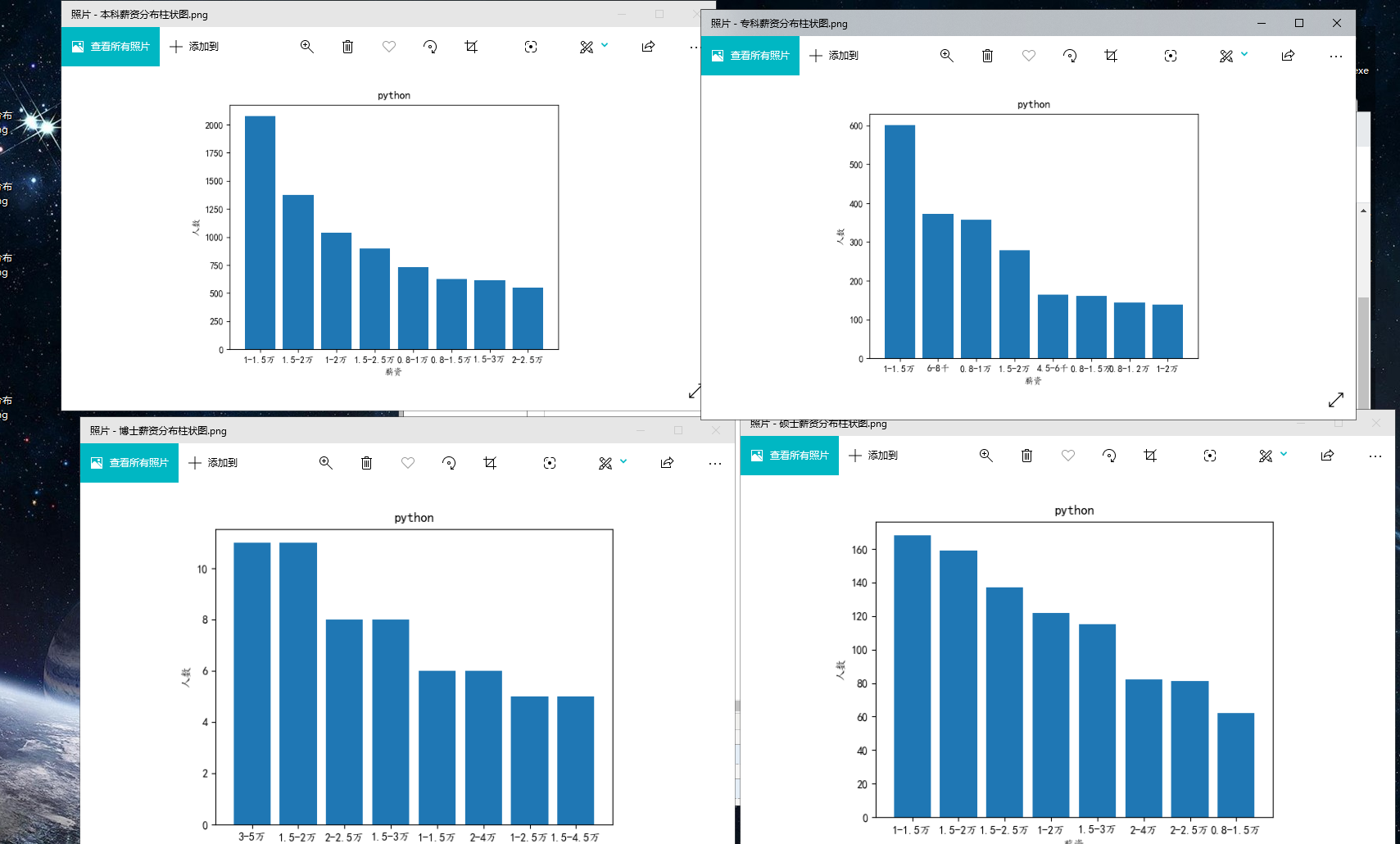
(4)各学历薪资状况
import io
import sys
from matplotlib import pyplot as plt
import matplotlib as mpl
from xlrd import open_workbook
filename = '专科' # 替换学历名称运行程序即可得到四张图片
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
workbook = open_workbook(r'./excels/{}.xlsx'.format(filename)) # 打开xls文件
sheet_name= workbook.sheet_names() # 打印所有sheet名称,是个列表
sheet = workbook.sheet_by_index(0) # 根据sheet索引读取sheet中的所有内容
content = sheet.col_values(3)[0:] # 第4列内容
moneys = []
for i in content:
if '月' in i:
moneys.append(i[:-2])
nums = [] # num为临时变量,在下方提供判定作用
# money_num用来存储薪资范围最普遍的值
money_num = {}
for m in moneys:
# 循环判断薪资是否在nums列表中
if m not in nums:
# 不在则添加一个值为该薪资的键
nums.append(m)
money_num[m] = 0
if m in nums:
# 在则将该建对应的值加1
money_num[m] = money_num[m] + 1
# 利用sorted函数对该字典排序
new_money_nums = sorted(money_num.items(), key=lambda item: item[1], reverse=True)
x = []
y = []
for i in new_money_nums[0:8]:
x.append(i[0])
y.append(i[1])
plt.bar(x, y, align='center')
plt.title('python')
plt.ylabel('人数')
plt.xlabel('薪资')
plt.savefig("./薪资范围图示/{}薪资分布柱状图.png".format(filename))
(5)代码汇总
四:结论:
从分析中可知要想得到更好的生活,就要好好学习哈哈哈,更要明白难的知识才会更有含金量,如果不刻苦学习将来可能只是初级运维师,越努力越幸运。
这次项目也让我感受到了python的魅力,获益良多,让我对后期课程更加感兴趣! 以后肯定好好学习, 把以前的不足都补上 !

 浙公网安备 33010602011771号
浙公网安备 33010602011771号