操作系统和线程
一、黏包现象
1.黏包现象
情况一:发送方的缓存机制
发送端需要等缓冲区满才发送出去,造成粘包,发送数据时间间隔很短,数据很小,回合到一起,产生粘包。
情况二:接收方的缓存机制
接收方不及时接收缓冲区的包,造成多个包接收,客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包。
黏包现象通俗的讲解:
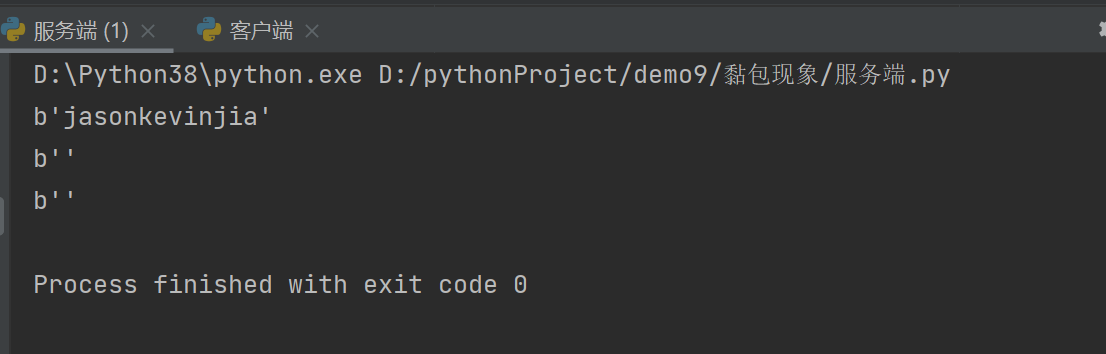
1.服务器连续执行了三次recv
2.客户端连续执行了三次send
出现黏包现象的原因:
1.不清楚数据真实多大
2.TCP协议会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送
解决黏包现象的关键点:
主要是明白数据具体有多大
'''服务端'''
import socket
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
sock,address = server.accept()
print(sock.recv(1024))
print(sock.recv(1024))
print(sock.recv(1024))
'''客户端'''
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
client.send(b'jason')
client.send(b'kevin')
client.send(b'jia')
2.struct模块
import struct
info = b'hello baby'
print(len(info)) # 数据真实的长度(bytes) 10
res = struct.pack('i', len(info)) # 将数据打包成固定的长度 i是固定的打包模式
print(len(res)) # 报头
real_res = struct.unpack('i', res)
print(real_res)
黏包问题的解决方案:
字典作为报头打包,效果好
客户端:
1.制作真实的数据信息字典
2.利用struct模块制作字典的报头
3.发送固定长度的报头(解析出来是字典的长度)
4.发送字典数据
5.发送真实数据
服务端
1.接收固定长度的字典报头
2.解析出字典的长度并接收
3.通过字典获取到真实数据的各项信息
4.接收真实数据长度
3.黏包代码实战
'''客户端'''
import socket
import struct
import json
import os
client = socket.socket()
client.connect(('127.0.0.1',8080))
# 1.获取真实数据的大小
file_size = os.path.getsize(r'D:\pythonProject\demo9\终极实战\1.txt')
# 2.制作真实数据的字典数据
data_dict = {
'file_name' : '2.txt',
'file_size':file_size,
'file_desc':'随机乱写的',
'file_info':'嘉嘉'
}
# 3.制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8')
data_dict_len = struct.pack('i',len(data_dict_bytes))
# 4.发送字典报头
client.send(data_dict_len)
# 5.发送字典
client.send(data_dict_bytes)
# 6.最后发送真实的数据
with open(r'D:\pythonProject\demo9\终极实战\1.txt','rb') as f:
for line in f:
client.send(line)
'''服务端'''
import socket
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
sock,addr = server.accept()
# 1.接收固定长度的字典报头
data_dict_head = sock.recv(4)
# 2.根据报头解析吃字典的长度
data_dict_len = struct.unpack('i',data_dict_head)[0]
# 3.接收字典数据
data_dict_bytes = sock.recv(data_dict_len)
data_dict = json.loads(data_dict_bytes) # 自动解码再反序列化
# 4.获取真实数据的各项信息
total_size = data_dict.get('file_size')
with open(data_dict.get('file_name'), 'wb') as f:
f.write(sock.recv(total_size))
二、UDP协议
'''服务端'''
import socket
server = socket.socket(type=socket.SOCK_DGRAM) # UDP协议
server.bind(('127.0.0.1', 8080))
while True:
data, addr = server.recvfrom(1024)
print('客户端地址>>>:', addr)
print('上述地址发送的消息>>>:', data.decode('utf8'))
msg = input('>>>:').strip()
server.sendto(msg.encode('utf8'), addr)
'''客户端'''
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
server_addr = ('127.0.0.1', 8080)
while True:
msg = input('>>>:').strip()
client.sendto(msg.encode('utf8'), server_addr)
data, addr = client.recvfrom(1024)
print(data.decode('utf8'), addr)
三、并发编程理论
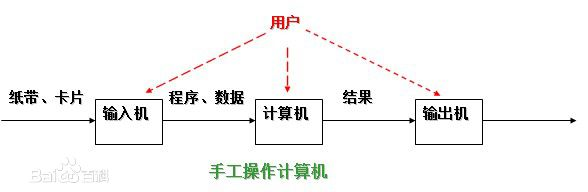
1.穿孔卡片
CPU的利用率非常低,好处就是可以让程序员独占计算机
2.联机批处理系统
提前使用磁带一次性录入多个程序员编写的程序,然后交给计算机执行
缩短录入数据的时间,让CPU连续工作的时间边长,为了提升CPU 的利用率
3.脱机批处理系统
极大地提升了CPU的利用率
# 总结:操作系统的发展史是CPU利用率提升的发展史

四、多道技术
1.单道技术
所有程序排队执行,过程不能重合,总耗时是所有程序之和

2.多道技术
计算机利用空闲时间提前准备好的一些数据,提高效率,总耗时时较短。
多道技术:切换和保存
1.切换
计算机在以下两种情况下会切换:
1.程序进入IO操作时(input,time,sleep,read,write)
2.程序长时间占用CPU(得切换一下)
2.保存状态
CPU每次切换走之前都得保存当前操作的状态,下次切换回来基于上次的进度继续执行

一个列子明白单道和多道
eg:
电饭煲煮饭:40分钟
洗衣:35分钟
烧水:10分钟
单道技术:85分钟
多道技术:40分钟
五、进程理论
进程与程序的区别:
程序:一堆四代码(没有运行起来)
进程:正在运行的程序(被运行起来了)
进程的调度算法:
1.FCFS(先来先服务的算法):
对短作业不友好(第一个程序耗时2小时,之后的程序耗时1秒)
2.短作业优先调度
对长作业不友好
3.时间片轮转法+多级反馈队列
将时间均分 然后根据进程时间长短再分多个等级
六、进程的并行与并发
并行:
多个进程同时执行,必须有多个CPU参与,单个CPU无法实现并行
并发:
多个进程看上去像同时执行,单个CPU可以实现,多个CPU肯定也可以
七、进程的三状态
就绪态:所有进程在被CPU执行之前都必须进入就绪态等待
运行态:CPU正在执行
阻塞态:进程运行过程中出现了IO操作 阻塞态无法直接进入运行态 需要先进入就绪态


 浙公网安备 33010602011771号
浙公网安备 33010602011771号