
网络爬虫 --《暧昧》、《别》网易云歌曲评论及评论用户信息爬取
一、选题的背景
众所周知,网易云音乐由于“评论”成功从众多听歌软件中成功破圈,目前已成为当下年轻人使用最多的音乐软件,上面聚集了大量的用户,可以说网易云上面的评论数据具有很高的研究价值,热门歌曲的评论更是接近百万或者是超过百万条,而且很多热评都会被流传也受到很多人的喜爱。
所以我想通过获取薛之谦最火两首歌《暧昧》和《别》评论区的评论信息和评论用户信息,从而了解到薛之谦歌曲下的评论群众和用户的组成成分,也可以通过评论数据集做中文分词等进一步地数据处理和应用。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
《暧昧》、《别》网易云歌曲评论及评论用户信息爬取
2.主题式网络爬虫爬取的内容与数据特征分析
根据搜索薛之谦网易云里评论最多的两首歌,发现是《暧昧》、《别》,所以本次爬取的内容就是这两首歌曲下的评论。然后获取这些评论数据,包括:评论用户ID,评论用户昵称,评论用户位置,评论用户评论内容,该评论被点赞人数,评论时间等信息。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
方案概述:先利用request进行访问请求,请求成功后转为json格式,然后利用第三方网站对网页进行解析,分析要爬取的内容,编写代码爬取信息,随后进行数据清洗、数据分析,最后存为csv文件、对数据进行持久化。
(1)实现思路:查看网页结构→查看网页爬取内容的位置→取出数据→数据存储→数据分析→数据可视化。
(2)技术难点:所有的分析和可视化的基础都要在有数据的前提下,所以最主要还是在于如何对网页的内容进行获取。与此同时,通过查询发现网易云采用了js加密技术,所以想要通过破解内容获取网页信息会很复杂。因此,下文我采用了网易云官方API的方法进行爬取,会更加简单。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
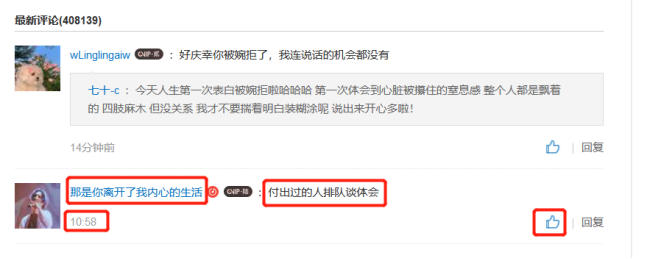
以框起来的一条评论为例,在歌曲评论区中,我们可以看到有用户的评论id、评论内容、评论时间、点赞数。
而点进用户界面就可以看到有用户id、性别、年龄、个人介绍等等。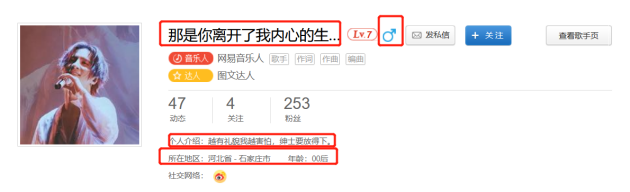
2.Htmls 页面解析
因为网易云评论使用了js加密技术,所以要构造参数去破解加密信息,然后再爬取内容。但是通过查找,我发现可以直接用网易云官方给的AIP去进行爬取,会更简单而且更方便。
网易云API地址:https://blog.51cto.com/u_15064627/2597877
本次爬取就用到了其中提到的评论和用户信息的两个API,分别是:
评论:http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit=20&offset=0
用户信息:https://music.163.com/api/v1/user/detail/{用户ID}
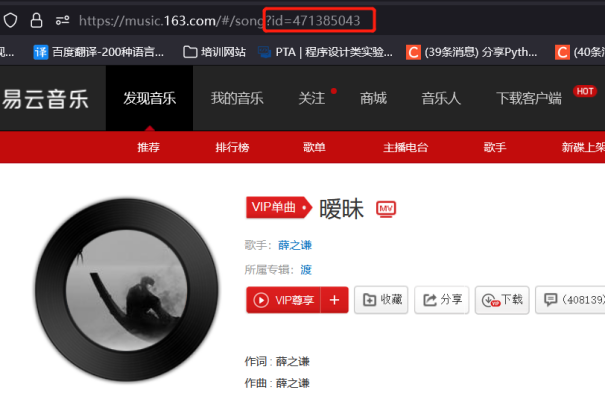
先照要求找到歌曲id
然后通过API访问到相应评论页面,发现页面格式较乱,分析较困难,所以我借助了另一个json在线解析网站(https://www.sojson.com/simple_json.html),对网页代码进行分析。
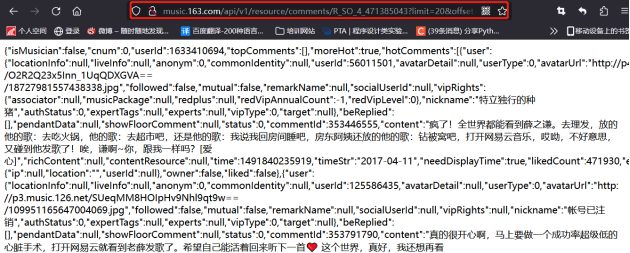
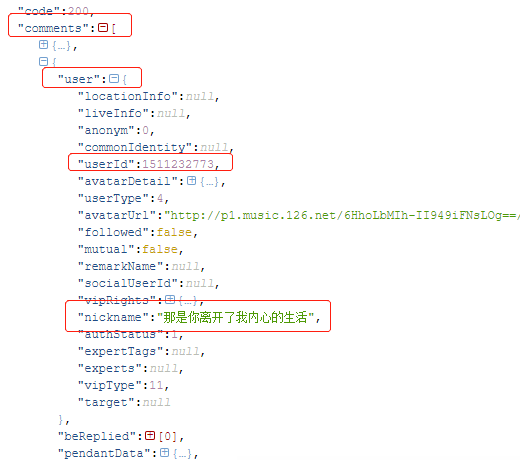 发现我们需要用户id、用户名、评论ID、评论内容、评论时间、点赞数的信息都在comments里。
发现我们需要用户id、用户名、评论ID、评论内容、评论时间、点赞数的信息都在comments里。
再去用户页看看,同样转到json在线解析里分析。
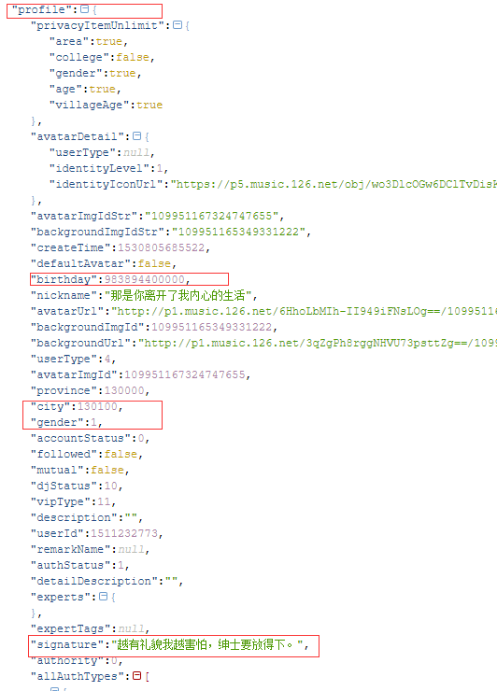
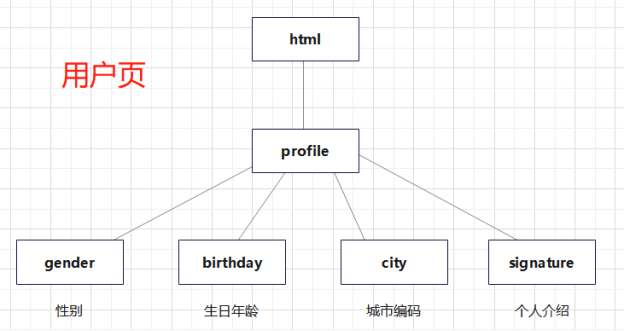
发现用户城市、性别、个人介绍、生日都在profile中。
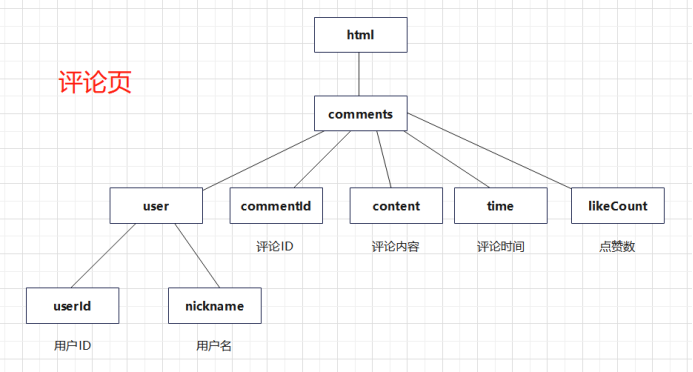
3.节点(标签)查找方法与遍历方法
根据前面对网页的分析可以画出节点查找方法,这样画出来之后取数据信息的思路会更清晰。
 四、网络爬虫程序设计
四、网络爬虫程序设计
1.数据爬取与采集
爬取两首歌前五十页的评论,切换歌曲只需改变评论API地址的id就行。
import json
import time
import requests
headers = {
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
def get_comments(page):
"""获取评论信息"""
#评论API地址 第一首《暧昧》:471385043 第二首《别》:515803379
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_471385043?limit=100&offset=' + str(page)
response = requests.get(url=url, headers=headers)
# 将字符串转为json格式
result = json.loads(response.text)
#只提取comments的内容
items = result['comments']
for item in items:
# 用户名
user_name = item['user']['nickname'].replace(',', ',')
# 用户ID
user_id = str(item['user']['userId'])
# 评论内容
comment = item['content'].strip().replace('\n', '').replace(',', ',')
# 评论ID
comment_id = str(item['commentId'])
# 评论点赞数
praise = str(item['likedCount'])
# 评论时间
date = time.localtime(int(str(item['time'])[:10]))
date = time.strftime("%Y-%m-%d %H:%M:%S", date)
# 获取用户信息
user_message = get_user(user_id)
# 用户年龄
user_age = str(user_message['age'])
# 用户性别
user_gender = str(user_message['gender'])
# 用户所在地区
user_city = str(user_message['city'])
# 个人介绍
user_introduce = user_message['sign'].strip().replace('\n', '').replace(',', ',')
print(user_name, user_id, user_age, user_gender, user_city, user_introduce, comment, comment_id, praise, date)
#保存到本地
with open('comments data.csv', 'a', encoding='utf-8-sig') as f:
f.write(user_name + ',' + user_id + ',' + user_age + ',' + user_gender + ',' + user_city + ',' + user_introduce + ',' + comment + ',' + comment_id + ',' + praise + ',' + date + '\n')
f.close()
def get_user(user_id):
""" 获取用户注册时间"""
data = {}
#用户API
url = 'https://music.163.com/api/v1/user/detail/' + str(user_id)
response = requests.get(url=url, headers=headers)
# 将字符串转为json格式
js = json.loads(response.text)
if js['code'] == 200:
# 性别
data['gender'] = js['profile']['gender']
# 年龄
if int(js['profile']['birthday']) < 0:
data['age'] = 0
else:
data['age'] = (2018 - 1970) - (int(js['profile']['birthday']) // (1000 * 365 * 24 * 3600))
if int(data['age']) < 0:
data['age'] = 0
# 城市
data['city'] = js['profile']['city']
# 个人介绍
data['sign'] = js['profile']['signature']
else:
data['gender'] = '无'
data['age'] = '无'
data['city'] = '无'
data['sign'] = '无'
return data
def main():
for i in range(0, 1050, 20):
print('\n---------------第 ' + str(i // 20 + 1) + ' 页---------------')
get_comments(i)
if __name__ == '__main__':
main()
经过爬出的结果和实际结果对比,发现是匹配的,所以爬虫过程中没有出现错误。
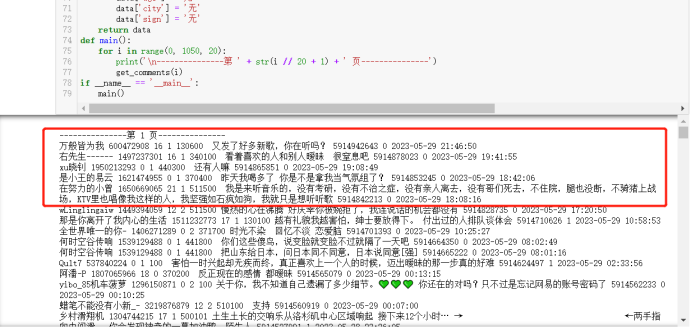
同时翻到代码最下面,可以发现52.53是没有爬到的,然后去搜索后才知道目前网易云音乐评论还是具有反爬虫机制的,只能够读取到的评论为前51页,第52页会终止脚本运行。所以51页后面的,都因为反爬机制的存在,爬不到。
 打开保存的csv文件,可以看到两首歌最后爬出来的评论一共有10268条。
打开保存的csv文件,可以看到两首歌最后爬出来的评论一共有10268条。
2.对数据进行清洗和处理
import pandas as pd
#按照读取顺序设置列名,读取数据为data
data = pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
data.duplicated()#查看是否有重复值
data = data.drop_duplicates()#去重复值
data=data.dropna()#去空值
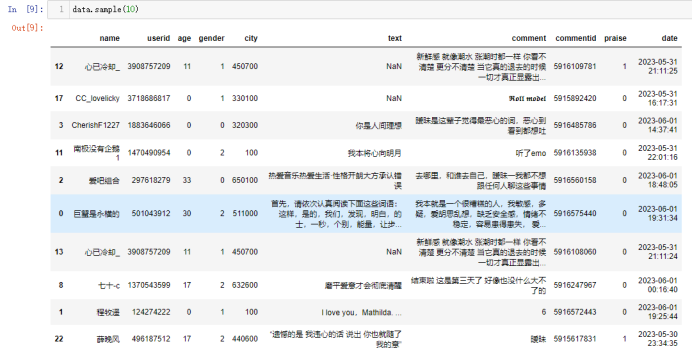
data.sample(10)#随机抽取10个看看
查看数据是否有重复值,根据结果可以看出是没有的,但是为了保险起见,也是对数据进行了去重复值和空值的操作。
随后通过随机抽取数据,发现数据没有缺失也没有异常,且都是按照设定的列名存储的。
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
#两首歌都存在一个文档里,前面有记录爬第一首歌到评论多少条,所以这里直接分开做两个词云
#第一首歌
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import random
import jieba
from PIL import Image
# 设置文本随机颜色
def random_color_func(word=None, font_size=None, position=None, orientation=None, font_path=None, random_state=None):
h, s, l = random.choice([(188, 72, 53), (253, 63, 56), (12, 78, 69)])
return "hsl({}, {}%, {}%)".format(h, s, l)
words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword'])
# 分词
text = ''
music1=data[0:715]
for line in music1['comment']:
text += ' '.join(jieba.cut(str(line), cut_all=False))
# 停用词
stopwords = set('')
stopwords.update(words['stopword'])
backgroud_Image = np.array(Image.open('2.png'))
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\STXIHEI.TTF',
max_words=2000,
max_font_size=250,
min_font_size=15,
color_func=random_color_func,
prefer_horizontal=1,
random_state=50,
stopwords=stopwords
)
wc.generate_from_text(text)
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
#print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file("网易云音乐评论词云1.jpg")
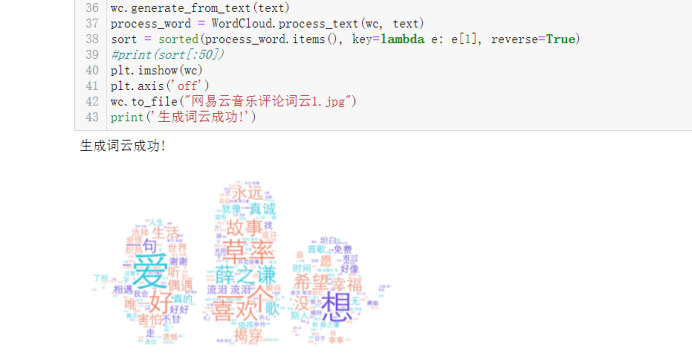
print('生成词云成功!')
#第二首歌
# 分词
text = ''
music2=data[715:]
for line in music2['comment']:
text += ' '.join(jieba.cut(str(line), cut_all=False))
# 停用词
stopwords = set('')
stopwords.update(words['stopword'])
backgroud_Image = np.array(Image.open('6433028c89b941979694288fe2df1b95.png'))
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='C:\Windows\Fonts\STXIHEI.TTF',
max_words=2000,
max_font_size=250,
min_font_size=15,
color_func=random_color_func,
prefer_horizontal=1,
random_state=50,
stopwords=stopwords
)
wc.generate_from_text(text)
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
#print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file("网易云音乐评论词云2.jpg")
print('生成词云成功!')
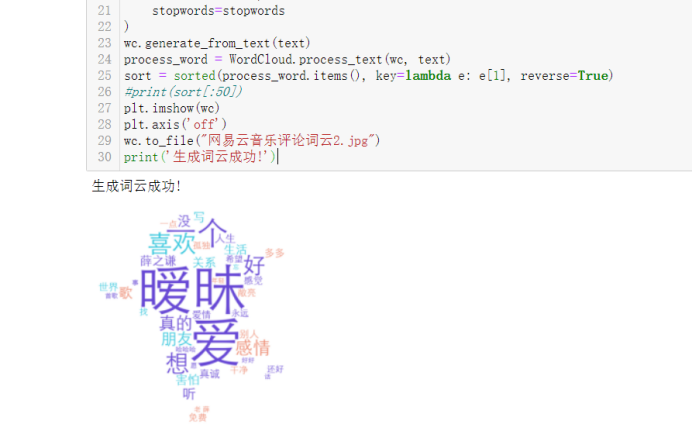 通过分词可以发现,出现最多的是爱、想、草率、喜欢、薛之谦、暧昧、一个这类的词,也可以很明显的发现歌曲下面的评论都是偏感情的多点,还大多数都是爱情,也很符合薛式情歌。
通过分词可以发现,出现最多的是爱、想、草率、喜欢、薛之谦、暧昧、一个这类的词,也可以很明显的发现歌曲下面的评论都是偏感情的多点,还大多数都是爱情,也很符合薛式情歌。
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
4.1 评论用户的年龄分布
import pandas as pd
from pyecharts import Pie
# 读取数据
data= pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 去除无性别信息的
data = data[data.gender != 0]
data = data[data.gender != 3]
# 分组汇总
gender_message = data.groupby(['gender'])
gender_com = gender_message['gender'].agg(['count'])
gender_com.reset_index(inplace=True)
attr = ['男', '女']
v1 = gender_com['count']
v1=v1[1:3]
pie = Pie("评论用户的性别情况", title_pos='center', title_top=0)
pie.add("", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left", legend_top="%10")
pie.render("评论用户的性别情况.html")
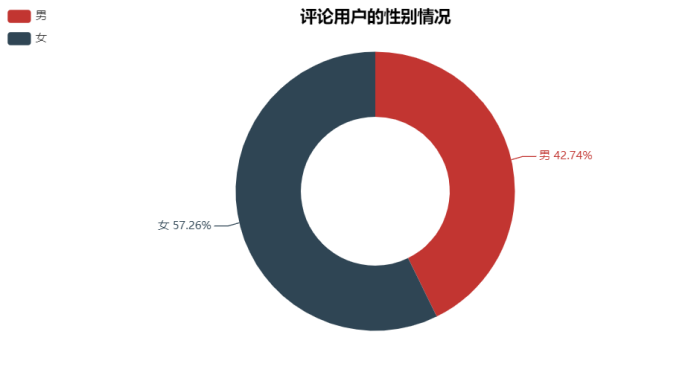
可以发现评论用户大多都是女生,也很正常,因为女生都比较感性,也比较喜欢听歌,由此可以猜测薛之谦的粉丝可能大多数都是女性。
4.2 评论歌曲日期分布
import pandas as pd
from pyecharts import Line
import webbrowser
# 读取数据
data = pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 获取评论日期
data ['time']=data ['date'].str.split(' ', expand=True)[0]
# 分组汇总
date_message = data .groupby(['time'])
date_com = date_message['time'].agg(['count'])
date_com.reset_index(inplace=True)
# 绘制走势图
attr = date_com['time']
v1 = date_com['count']
line = Line("近期歌曲评论的日期分布", title_pos='center', title_top='18', width=800, height=400)
line.add("", attr, v1, is_smooth=True, is_fill=True, area_color="#000", is_xaxislabel_align=True, xaxis_min="dataMin", area_opacity=0.3, mark_point=["max"], mark_point_symbol="pin", mark_point_symbolsize=55)
#用上面数据生成html文件
line.render("近期歌曲评论的日期分布.html")
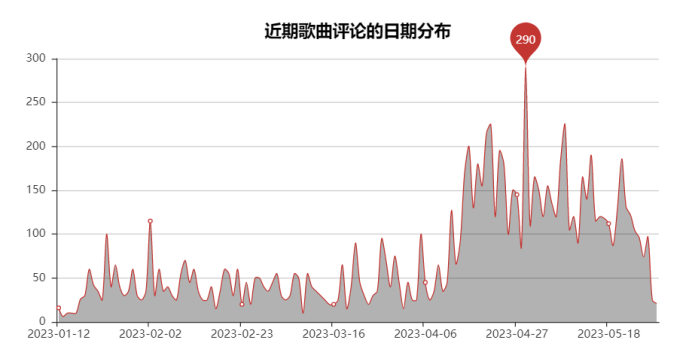
2023年4月27日左右的评论最多,经过查询发现那天薛之谦在举办演唱会,然后这首歌也很火,因此我猜测可能是因为演唱会的原因造成了这天之后的评论高峰。
4.3 评论歌曲时间分布
import pandas as pd
from pyecharts import Line
# 读取数据
data = pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 根据评论ID去重
data = data.drop_duplicates('commentid')
# 获取时间
data['time']=data['date'].str.split(' ', expand=True)[1]
data['time']=data['time'].str.split(':', expand=True)[0]
# 分组汇总
date_message = data.groupby(['time'])
date_com = date_message['time'].agg(['count'])
date_com.reset_index(inplace=True)
# 绘制走势图
attr = date_com['time']
v1 = date_com['count']
line = Line("歌曲评论的时间分布", title_pos='center', title_top='18', width=800, height=400)
line.add("", attr, v1, is_smooth=True, is_fill=True, area_color="#000", is_xaxislabel_align=True, xaxis_min="dataMin", area_opacity=0.3, mark_point=["max"], mark_point_symbol="pin", mark_point_symbolsize=55)
line.render("歌曲评论的时间分布.html")
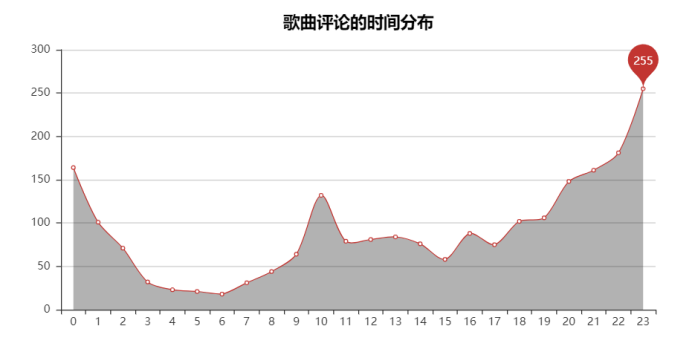
可以发现在21点-0点的时间人最多,且23点是其中人最多的时候,在我看来第一个原因是因为晚上都到了大家上床放松的时间有空听歌刷评论,其次就是到了“网抑云”时间,夜猫子开始emo了。
4.4 评论用户年龄分布
import pandas as pd
from pyecharts import Bar
# 读取数据
data= pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig')
# 根据评论ID去重
data=data.drop_duplicates('commentid')
# 去除无年龄信息的
data = data[data.age != 0]
#转换格式
data['age'] = pd.to_numeric(data['age'], errors='coerce')
data=data.replace([0,1],[18,20])
# 分组汇总
age_message = data.groupby(['age'])
age_com = age_message['age'].agg(['count'])
age_com.reset_index(inplace=True)
# 生成柱状图
attr = age_com['age']
v1 = age_com['count']
bar = Bar("评论用户的年龄分布", title_pos='center', title_top='18', width=800, height=300)
bar.add("", attr, v1, is_stack=True, is_label_show=False)
bar.render("评论用户的年龄分布.html")
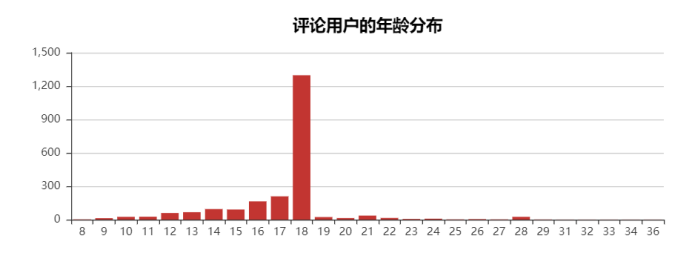
可以发现,底下评论的多数人都是14-18岁,18岁居多,也挺正常,青春期对感情比较懵懂,也比较也更喜欢听这些歌。
4.5 评论用户的地区分布图
import pandas as pd
from pyecharts import Map
def city_group(cityCode):
"""
城市编码
"""
city_map = {
'11': '北京',
'12': '天津',
'31': '上海',
'50': '重庆',
'5e': '重庆',
'81': '香港',
'82': '澳门',
'13': '河北',
'14': '山西',
'15': '内蒙古',
'21': '辽宁',
'22': '吉林',
'23': '黑龙江',
'32': '江苏',
'33': '浙江',
'34': '安徽',
'35': '福建',
'36': '江西',
'37': '山东',
'41': '河南',
'42': '湖北',
'43': '湖南',
'44': '广东',
'45': '广西',
'46': '海南',
'51': '四川',
'52': '贵州',
'53': '云南',
'54': '西藏',
'61': '陕西',
'62': '甘肃',
'63': '青海',
'64': '宁夏',
'65': '新疆',
'71': '台湾',
'10': '湖北',
'00':'河南',
'无':'福建'
}
cityCode = str(cityCode)
return city_map[cityCode[:2]]
df['location']=df['city'][:].apply(city_group)
# 分组汇总
loc_message = df.groupby(['location'])
loc_com = loc_message['location'].agg(['count'])
loc_com.reset_index(inplace=True)
# 绘制地图
value = [i for i in loc_com['count']]
attr = [i for i in loc_com['location']]
map = Map("评论用户的地区分布图", title_pos='center', title_top=0)
map.add("", attr, value, maptype="china", is_visualmap=True, visual_text_color="#000", is_map_symbol_show=True, visual_range=[0, 100])
map.render('评论用户的地区分布图.html')
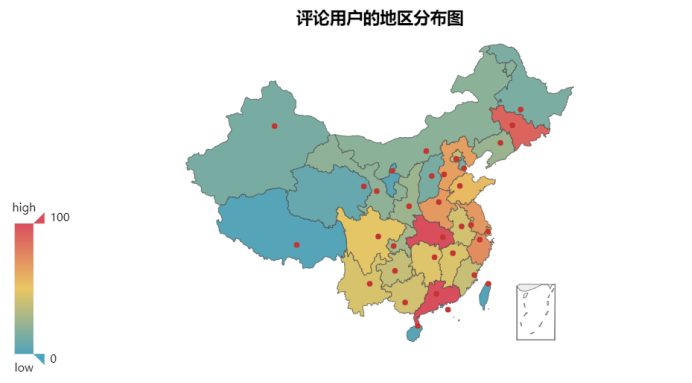
通过图,可以发现,人数最多的地区是广东、湖北、吉林,但是看不出什么规律。
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)。
#评论最多ID数
import pandas as pd
# 分组汇总
user_message = data.groupby(['userid'])
user_com = user_message['userid'].agg(['count'])
user_com.reset_index(inplace=True)
user_com_last = user_com.sort_values('count', ascending=False)[0:10]
user_com_last = user_com_last.astype(object)#转换类型
user_com_last['count']
plt.figure(figsize=(20,5))#画布大小
plt.grid()#画方格
sns.regplot(x=user_com_last['userid'],y=user_com_last['count'],fit_reg=False)
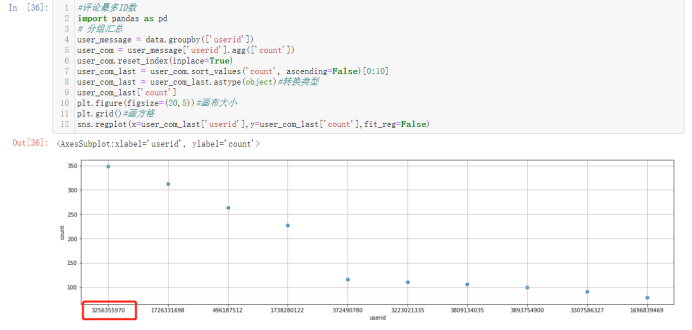
可以发现最多的id数3256355970,然后去数据集中看看它都评论了什么。
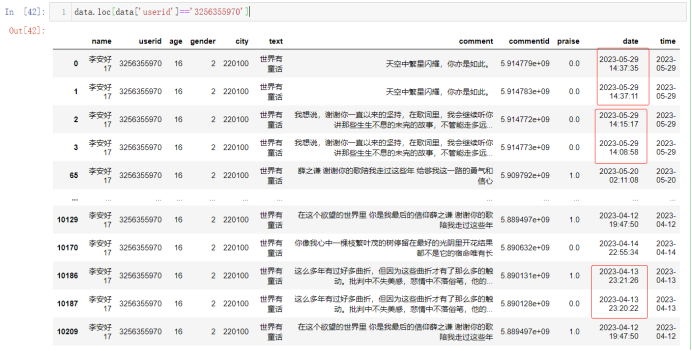
可以从头和尾中看出,它很多条评论都重复了,但是时间不一样,可能就是单纯的为了喜欢歌手刷评论或者是水军。
与此同时,通过对数据进行观察,发现没有任何两列之间存在数学间的联系,所以也就没有做建立两个变量之间的回归方程。
6.数据持久化
因为在一开始爬虫的时候就对数据进行了保存,所以这就不再运行了
with open('comments data.csv', 'a', encoding='utf-8-sig') as f:
f.write(user_name + ',' + user_id + ',' + user_age + ',' + user_gender + ',' + user_city + ',' + user_introduce + ',' + comment + ',' + comment_id + ',' + praise + ',' + date + '\n')
f.close()
本地已经有了这个文件,而且记录也是对的。
7.将以上各部分的代码汇总,附上完整程序代码
1 #总代码 2 #爬虫 3 import json 4 import time 5 import requests 6 headers = { 7 'Host': 'music.163.com', 8 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 9 } 10 def get_comments(page): 11 """获取评论信息""" 12 #评论API地址 第一首《暧昧》:471385043 第二首《别》:515803379 13 url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_515803379?limit=100&offset=' + str(page) 14 response = requests.get(url=url, headers=headers) 15 # 将字符串转为json格式 16 result = json.loads(response.text) 17 #只提取comments的内容 18 items = result['comments'] 19 for item in items: 20 # 用户名 21 user_name = item['user']['nickname'].replace(',', ',') 22 # 用户ID 23 user_id = str(item['user']['userId']) 24 # 评论内容 25 comment = item['content'].strip().replace('\n', '').replace(',', ',') 26 # 评论ID 27 comment_id = str(item['commentId']) 28 # 评论点赞数 29 praise = str(item['likedCount']) 30 # 评论时间 31 date = time.localtime(int(str(item['time'])[:10])) 32 date = time.strftime("%Y-%m-%d %H:%M:%S", date) 33 # 获取用户信息 34 user_message = get_user(user_id) 35 # 用户年龄 36 user_age = str(user_message['age']) 37 # 用户性别 38 user_gender = str(user_message['gender']) 39 # 用户所在地区 40 user_city = str(user_message['city']) 41 # 个人介绍 42 user_introduce = user_message['sign'].strip().replace('\n', '').replace(',', ',') 43 print(user_name, user_id, user_age, user_gender, user_city, user_introduce, comment, comment_id, praise, date) 44 #保存到本地 45 with open('comments data.csv', 'a', encoding='utf-8-sig') as f: 46 f.write(user_name + ',' + user_id + ',' + user_age + ',' + user_gender + ',' + user_city + ',' + user_introduce + ',' + comment + ',' + comment_id + ',' + praise + ',' + date + '\n') 47 f.close() 48 def get_user(user_id): 49 """ 获取用户注册时间""" 50 data = {} 51 #用户API 52 url = 'https://music.163.com/api/v1/user/detail/' + str(user_id) 53 response = requests.get(url=url, headers=headers) 54 # 将字符串转为json格式 55 js = json.loads(response.text) 56 if js['code'] == 200: 57 # 性别 58 data['gender'] = js['profile']['gender'] 59 # 年龄 60 if int(js['profile']['birthday']) < 0: 61 data['age'] = 0 62 else: 63 data['age'] = (2018 - 1970) - (int(js['profile']['birthday']) // (1000 * 365 * 24 * 3600)) 64 if int(data['age']) < 0: 65 data['age'] = 0 66 # 城市 67 data['city'] = js['profile']['city'] 68 # 个人介绍 69 data['sign'] = js['profile']['signature'] 70 else: 71 data['gender'] = '无' 72 data['age'] = '无' 73 data['city'] = '无' 74 data['sign'] = '无' 75 return data 76 def main(): 77 for i in range(0, 1050, 20): 78 print('\n---------------第 ' + str(i // 20 + 1) + ' 页---------------') 79 get_comments(i) 80 if __name__ == '__main__': 81 main() 82 #数据清洗 83 import pandas as pd 84 #按照读取顺序设置列名,读取数据为data 85 data = pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig') 86 data.duplicated()#查看是否有重复值 87 data = data.drop_duplicates()#去重复值 88 data=data.dropna()#去空值 89 data.sample(10)#随机抽取10个看看 90 #做词云 91 #两首歌都存在一个文档里,前面有记录爬第一首歌到评论多少条,所以这里直接分开做两个词云 92 #第一首歌 93 from wordcloud import WordCloud 94 import matplotlib.pyplot as plt 95 import pandas as pd 96 import numpy as np 97 import random 98 import jieba 99 from PIL import Image 100 # 设置文本随机颜色 101 def random_color_func(word=None, font_size=None, position=None, orientation=None, font_path=None, random_state=None): 102 h, s, l = random.choice([(188, 72, 53), (253, 63, 56), (12, 78, 69)]) 103 return "hsl({}, {}%, {}%)".format(h, s, l) 104 words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword']) 105 # 分词 106 text = '' 107 music1=data[0:715] 108 for line in music1['comment']: 109 text += ' '.join(jieba.cut(str(line), cut_all=False)) 110 # 停用词 111 stopwords = set('') 112 stopwords.update(words['stopword']) 113 backgroud_Image = np.array(Image.open('2.png')) 114 wc = WordCloud( 115 background_color='white', 116 mask=backgroud_Image, 117 font_path='C:\Windows\Fonts\STXIHEI.TTF', 118 max_words=2000, 119 max_font_size=250, 120 min_font_size=15, 121 color_func=random_color_func, 122 prefer_horizontal=1, 123 random_state=50, 124 stopwords=stopwords 125 ) 126 wc.generate_from_text(text) 127 process_word = WordCloud.process_text(wc, text) 128 sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True) 129 #print(sort[:50]) 130 plt.imshow(wc) 131 plt.axis('off') 132 wc.to_file("网易云音乐评论词云1.jpg") 133 print('生成词云成功!') 134 #第二首歌 135 # 分词 136 text = '' 137 music2=data[715:] 138 for line in music2['comment']: 139 text += ' '.join(jieba.cut(str(line), cut_all=False)) 140 # 停用词 141 stopwords = set('') 142 stopwords.update(words['stopword']) 143 backgroud_Image = np.array(Image.open('6433028c89b941979694288fe2df1b95.png')) 144 wc = WordCloud( 145 background_color='white', 146 mask=backgroud_Image, 147 font_path='C:\Windows\Fonts\STXIHEI.TTF', 148 max_words=2000, 149 max_font_size=250, 150 min_font_size=15, 151 color_func=random_color_func, 152 prefer_horizontal=1, 153 random_state=50, 154 stopwords=stopwords 155 ) 156 wc.generate_from_text(text) 157 process_word = WordCloud.process_text(wc, text) 158 sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True) 159 #print(sort[:50]) 160 plt.imshow(wc) 161 plt.axis('off') 162 wc.to_file("网易云音乐评论词云2.jpg") 163 print('生成词云成功!') 164 #评论用户的性别情况 165 import pandas as pd 166 from pyecharts import Pie 167 # 读取数据 168 data= pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig') 169 # 去除无性别信息的 170 data = data[data.gender != 0] 171 data = data[data.gender != 3] 172 # 分组汇总 173 gender_message = data.groupby(['gender']) 174 gender_com = gender_message['gender'].agg(['count']) 175 gender_com.reset_index(inplace=True) 176 attr = ['男', '女'] 177 v1 = gender_com['count'] 178 v1=v1[1:3] 179 pie = Pie("评论用户的性别情况", title_pos='center', title_top=0) 180 pie.add("", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left", legend_top="%10") 181 pie.render("评论用户的性别情况.html") 182 #评论的日期分布 183 import pandas as pd 184 from pyecharts import Line 185 import webbrowser 186 # 读取数据 187 data = pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig') 188 # 获取评论日期 189 data ['time']=data ['date'].str.split(' ', expand=True)[0] 190 # 分组汇总 191 date_message = data .groupby(['time']) 192 date_com = date_message['time'].agg(['count']) 193 date_com.reset_index(inplace=True) 194 # 绘制走势图 195 attr = date_com['time'] 196 v1 = date_com['count'] 197 line = Line("近期歌曲评论的日期分布", title_pos='center', title_top='18', width=800, height=400) 198 line.add("", attr, v1, is_smooth=True, is_fill=True, area_color="#000", is_xaxislabel_align=True, xaxis_min="dataMin", area_opacity=0.3, mark_point=["max"], mark_point_symbol="pin", mark_point_symbolsize=55) 199 #用上面数据生成html文件 200 line.render("近期歌曲评论的日期分布.html") 201 #评论的时间分布 202 import pandas as pd 203 from pyecharts import Line 204 # 读取数据 205 data = pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig') 206 # 根据评论ID去重 207 data = data.drop_duplicates('commentid') 208 # 获取时间 209 data['time']=data['date'].str.split(' ', expand=True)[1] 210 data['time']=data['time'].str.split(':', expand=True)[0] 211 # 分组汇总 212 date_message = data.groupby(['time']) 213 date_com = date_message['time'].agg(['count']) 214 date_com.reset_index(inplace=True) 215 # 绘制走势图 216 attr = date_com['time'] 217 v1 = date_com['count'] 218 line = Line("歌曲评论的时间分布", title_pos='center', title_top='18', width=800, height=400) 219 line.add("", attr, v1, is_smooth=True, is_fill=True, area_color="#000", is_xaxislabel_align=True, xaxis_min="dataMin", area_opacity=0.3, mark_point=["max"], mark_point_symbol="pin", mark_point_symbolsize=55) 220 line.render("歌曲评论的时间分布.html") 221 #评论用户的年龄分布 222 import pandas as pd 223 from pyecharts import Bar 224 # 读取数据 225 data= pd.read_csv('comments data.csv', header=None, names=['name', 'userid', 'age', 'gender', 'city', 'text', 'comment', 'commentid', 'praise', 'date'], encoding='utf-8-sig') 226 # 根据评论ID去重 227 data=data.drop_duplicates('commentid') 228 # 去除无年龄信息的 229 data = data[data.age != 0] 230 #转换格式 231 data['age'] = pd.to_numeric(data['age'], errors='coerce') 232 data=data.replace([0,1],[18,20]) 233 # 分组汇总 234 age_message = data.groupby(['age']) 235 age_com = age_message['age'].agg(['count']) 236 age_com.reset_index(inplace=True) 237 # 生成柱状图 238 attr = age_com['age'] 239 v1 = age_com['count'] 240 bar = Bar("评论用户的年龄分布", title_pos='center', title_top='18', width=800, height=300) 241 bar.add("", attr, v1, is_stack=True, is_label_show=False) 242 bar.render("评论用户的年龄分布.html") 243 #评论用户的地区分布图 244 import pandas as pd 245 from pyecharts import Map 246 def city_group(cityCode): 247 """ 248 城市编码 249 """ 250 city_map = { 251 '11': '北京', 252 '12': '天津', 253 '31': '上海', 254 '50': '重庆', 255 '5e': '重庆', 256 '81': '香港', 257 '82': '澳门', 258 '13': '河北', 259 '14': '山西', 260 '15': '内蒙古', 261 '21': '辽宁', 262 '22': '吉林', 263 '23': '黑龙江', 264 '32': '江苏', 265 '33': '浙江', 266 '34': '安徽', 267 '35': '福建', 268 '36': '江西', 269 '37': '山东', 270 '41': '河南', 271 '42': '湖北', 272 '43': '湖南', 273 '44': '广东', 274 '45': '广西', 275 '46': '海南', 276 '51': '四川', 277 '52': '贵州', 278 '53': '云南', 279 '54': '西藏', 280 '61': '陕西', 281 '62': '甘肃', 282 '63': '青海', 283 '64': '宁夏', 284 '65': '新疆', 285 '71': '台湾', 286 '10': '湖北', 287 '00':'河南', 288 '无':'福建' 289 } 290 cityCode = str(cityCode) 291 return city_map[cityCode[:2]] 292 data['location']=data['city'][:].apply(city_group) 293 # 分组汇总 294 loc_message = data.groupby(['location']) 295 loc_com = loc_message['location'].agg(['count']) 296 loc_com.reset_index(inplace=True) 297 # 绘制地图 298 value = [i for i in loc_com['count']] 299 attr = [i for i in loc_com['location']] 300 map = Map("评论用户的地区分布图", title_pos='center', title_top=0) 301 map.add("", attr, value, maptype="china", is_visualmap=True, visual_text_color="#000", is_map_symbol_show=True, visual_range=[0, 100]) 302 map.render('评论用户的地区分布图.html') 303 #评论最多ID数 304 import pandas as pd 305 # 分组汇总 306 user_message = data.groupby(['userid']) 307 user_com = user_message['userid'].agg(['count']) 308 user_com.reset_index(inplace=True) 309 user_com_last = user_com.sort_values('count', ascending=False)[0:10] 310 user_com_last = user_com_last.astype(object)#转换类型 311 user_com_last['count'] 312 plt.figure(figsize=(20,5))#画布大小 313 plt.grid()#画方格 314 sns.regplot(x=user_com_last['userid'],y=user_com_last['count'],fit_reg=False)
五、总结
1.经过对网易云评论的分析与可视化,首先可以看出薛之谦火的两首偏情歌下面的用户大多都是未成年的人,而且女性偏多,在4.27日左右的评论数最多的原因就是薛之谦开了演唱会,分布地区则比较不均匀,但是网易云是个开放的平台,所以都可以理解。其次是大家听歌网易云的时间都是在半夜到凌晨,所以大家都很喜欢熬夜。那么这次获取,也比较好的达到了我预期的目标。
2.在这次实验过程中我对爬虫和数据分析也有了更进一步的了解,通过这次的实验我发现做这个还是需要很多耐心,虽然有借鉴百度,但是有些运行出来还是有问题,这就需要自己去排错,然后进行数据处理、分析,但好在最后结果是好的。同时,我想说有时候不需要去学复杂的方式,简单的方式也可以做的很好,只要能完成最终目标就都是好方法。而且要有效借助第三方工具,毕竟工具开发出来都是为了方便大家更好地解决问题。改进的建议就是这次对于实验过程中出现的问题都不是很了解,都需要去搜才能理解解决,所以今后还是要继续加强理论方面的知识,然后提高实践能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号