天池新闻推荐比赛5:模型融合
排序模型
先通过召唤阶段将规模缩减,然后使用机器学习模型来对构造好的特征进行学习。再对测试集进行预测,得到测试集中的每个候选集用户点击的概率,返回点击概率最大的topk个文章,作为最终的结果。
排序阶段选择了三个比较有代表性的排序模型,它们分别是:
- LGB的排序模型
- LGB的分类模型
- 深度学习的分类模型DIN
得到了最终的排序模型输出的结果之后,还选择了两种比较经典的模型集成的方法:
- 输出结果加权融合
- Staking(将模型的输出结果再使用一个简单模型进行预测)
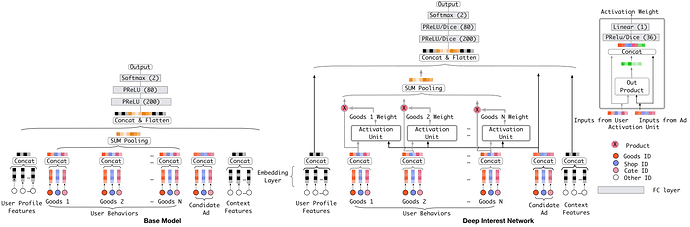
DIN模型简介
这是阿里2018年基于前面的深度学习模型无法表达用户多样化的兴趣而提出的一个模型, 它可以通过考虑【给定的候选广告】和【用户的历史行为】的相关性,来计算用户兴趣的表示向量。具体来说就是通过引入局部激活单元,通过软搜索历史行为的相关部分来关注相关的用户兴趣,并采用加权和来获得有关候选广告的用户兴趣的表示。与候选广告相关性较高的行为会获得较高的激活权重,并支配着用户兴趣。该表示向量在不同广告上有所不同,大大提高了模型的表达能力。所以该模型对于此次新闻推荐的任务也比较适合, 我们在这里通过当前的候选文章与用户历史点击文章的相关性来计算用户对于文章的兴趣。 该模型的结构如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号