一、什么是Dify
Dify 是一个开源的大语言模型(LLM)应用开发平台,融合了后端即服务(BaaS)和LLMOps(LLM运维和管理)理念,Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you),旨在帮助开发者快速搭建生产级生成式AI应用,支持非技术人员参与AI应用的定义和数据运营。
Dify核心功能如下:
- 应用创建:支持创建聊天助手、Agent、文本生成应用、工作流等。
- 技术栈支持:内置数百个模型支持、直观的Prompt编排界面、高质量的RAG引擎、Agent框架以及灵活的流程编排。
- 易用性:提供界面和API,减少开发者重复工作,聚焦创新与业务需求。
- 企业应用:
- 私有化知识库与AI助理:安全接入企业内部知识库,提升客户服务与内部办公效率。
- 企业级LLMOps平台:通过可视化工具和流程,支持对大型语言模型的运维、监控、标注和持续优化。
- 编排AI工作流:灵活集成企业系统,实时监控AI运行,确保可靠性。
- 零代码构建AI Agent:通过简单点击构建AI Agents,调用企业工具与数据,解决复杂任务。
Dify官网地址:https://dify.ai/
二、windows中搭建Dify
用户可以在线访问“https://cloud.dify.ai/”使用dify,界面如下:
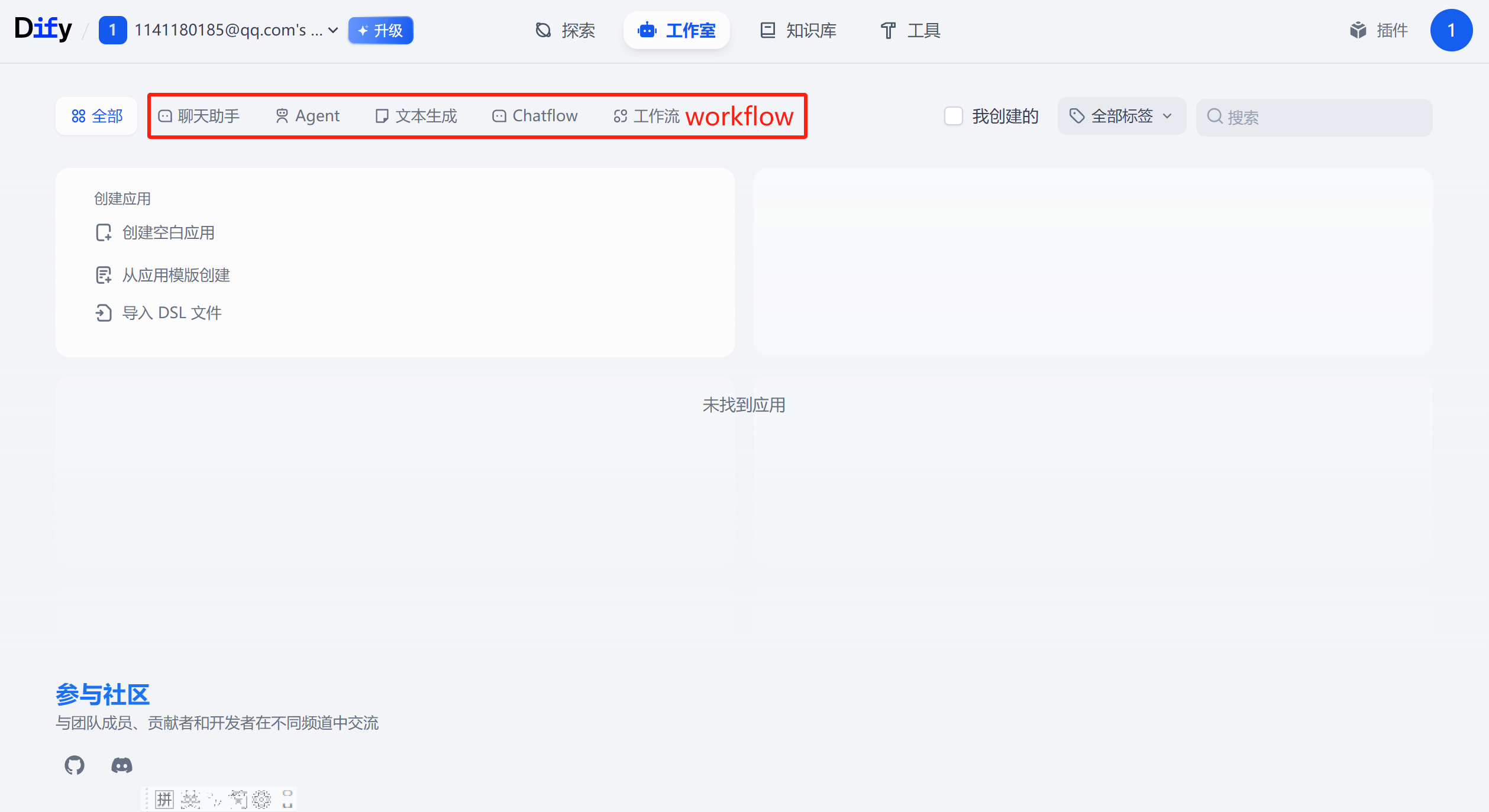
也可以在本地部署Dify社区版(开源版本),下面介绍基于DockerCompose部署Dify社区版本。
首先需要安装DockerDesktop运行Docker,然后基于Docker运行Dify。
官方文档:https://docs.dify.ai/zh-hans/introduction
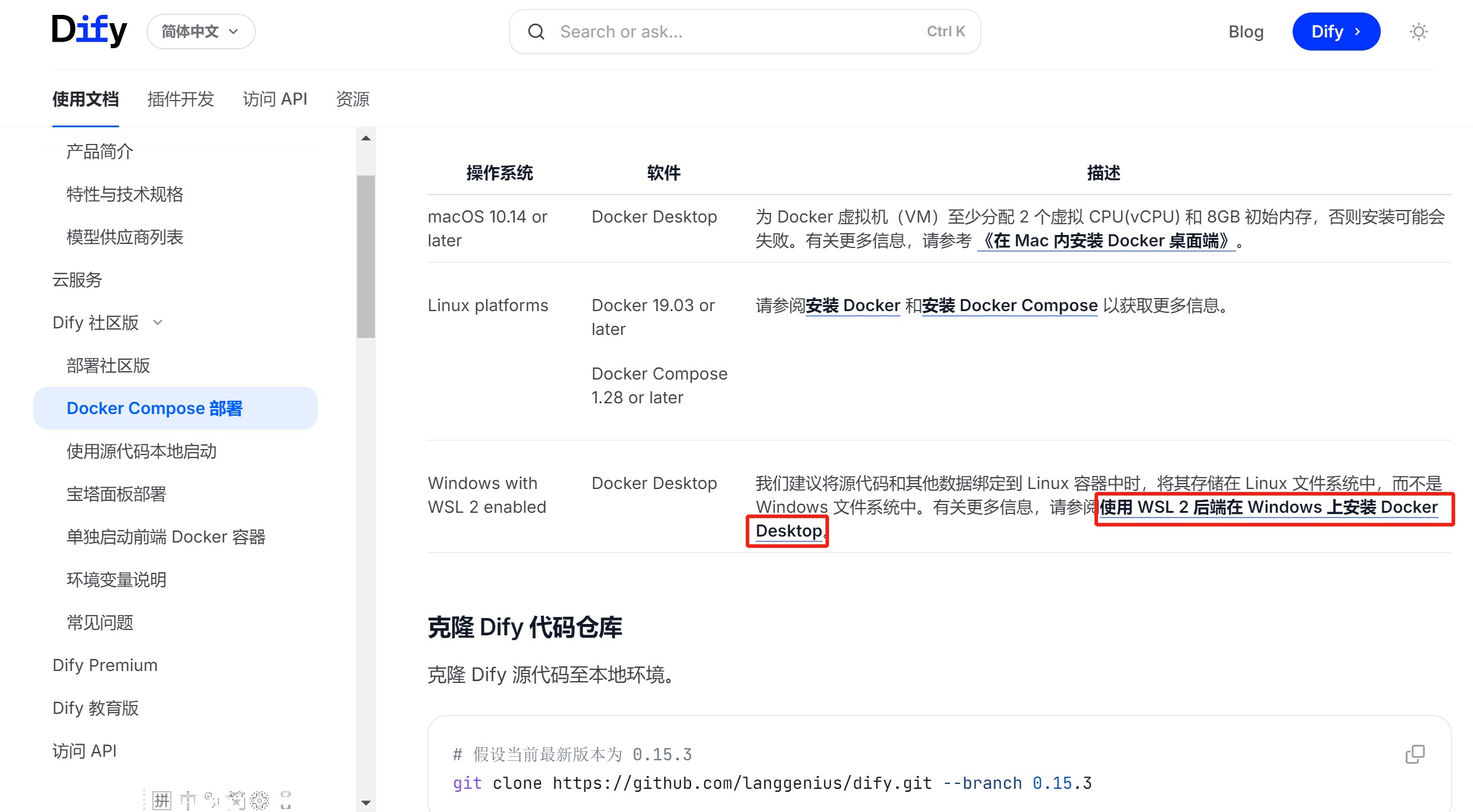
点击上面红框中的内容,进入如下界面:
下载之后,如下所示:
Docker Desktop指定安装位置:
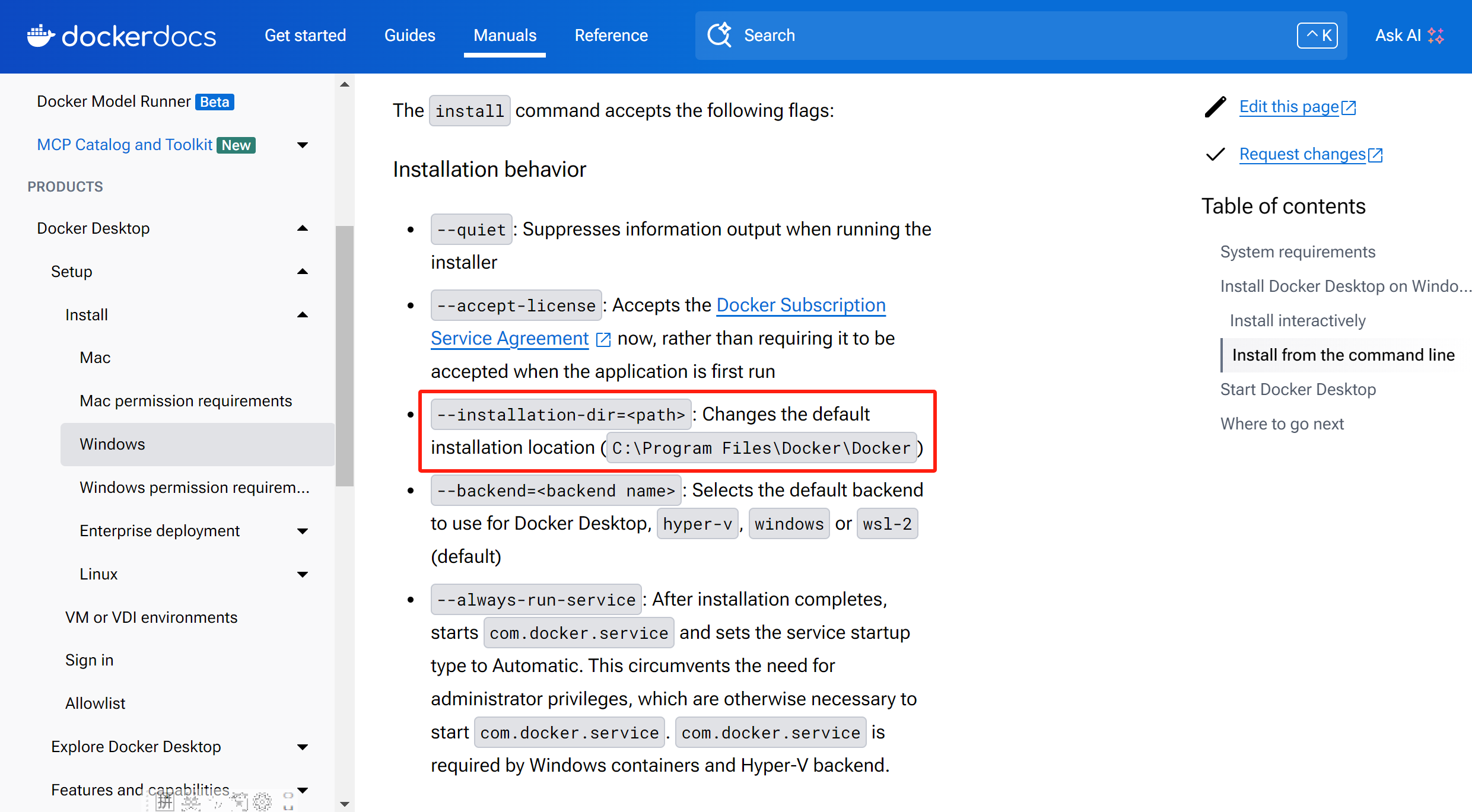
在Windows上,以管理员身份打开Windows Terminal或Powershell,使用cd命令导航到你下载Docker Desktop Installer.exe的目录,执行安装命令,
命令如下:
'F:\dify\Docker Desktop Installer.exe' install --installation-dir=D:\software\Docker
安装成功后,配置docker镜像源
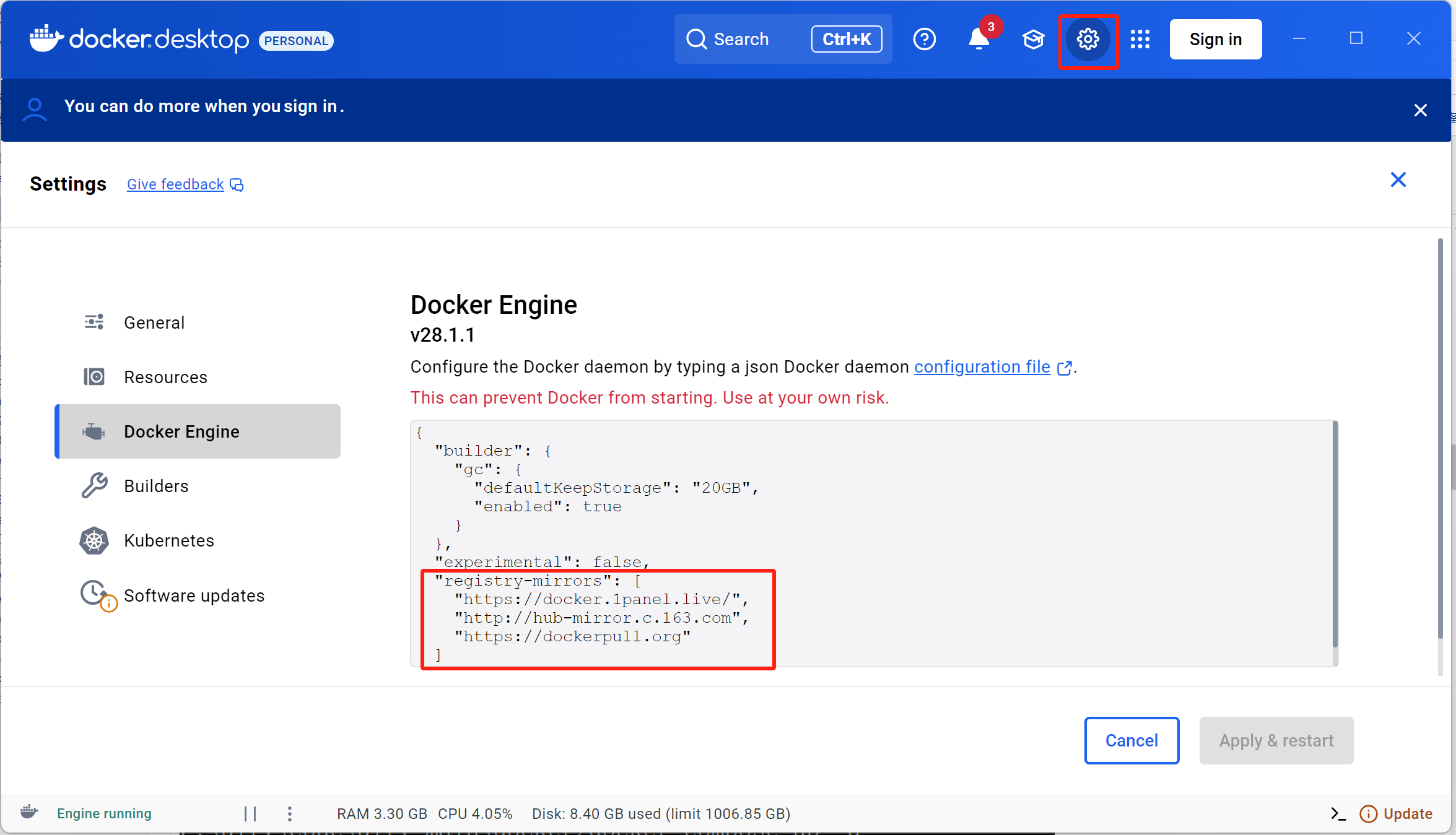
配置如下:
"registry-mirrors": [
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc",
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://dockerproxy.com",
"https://gst6rzl9.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"http://mirrors.ustc.edu.cn/",
"https://mirrors.tuna.tsinghua.edu.cn/",
"http://mirrors.sohu.com/"
]
修改docker镜像保存位置
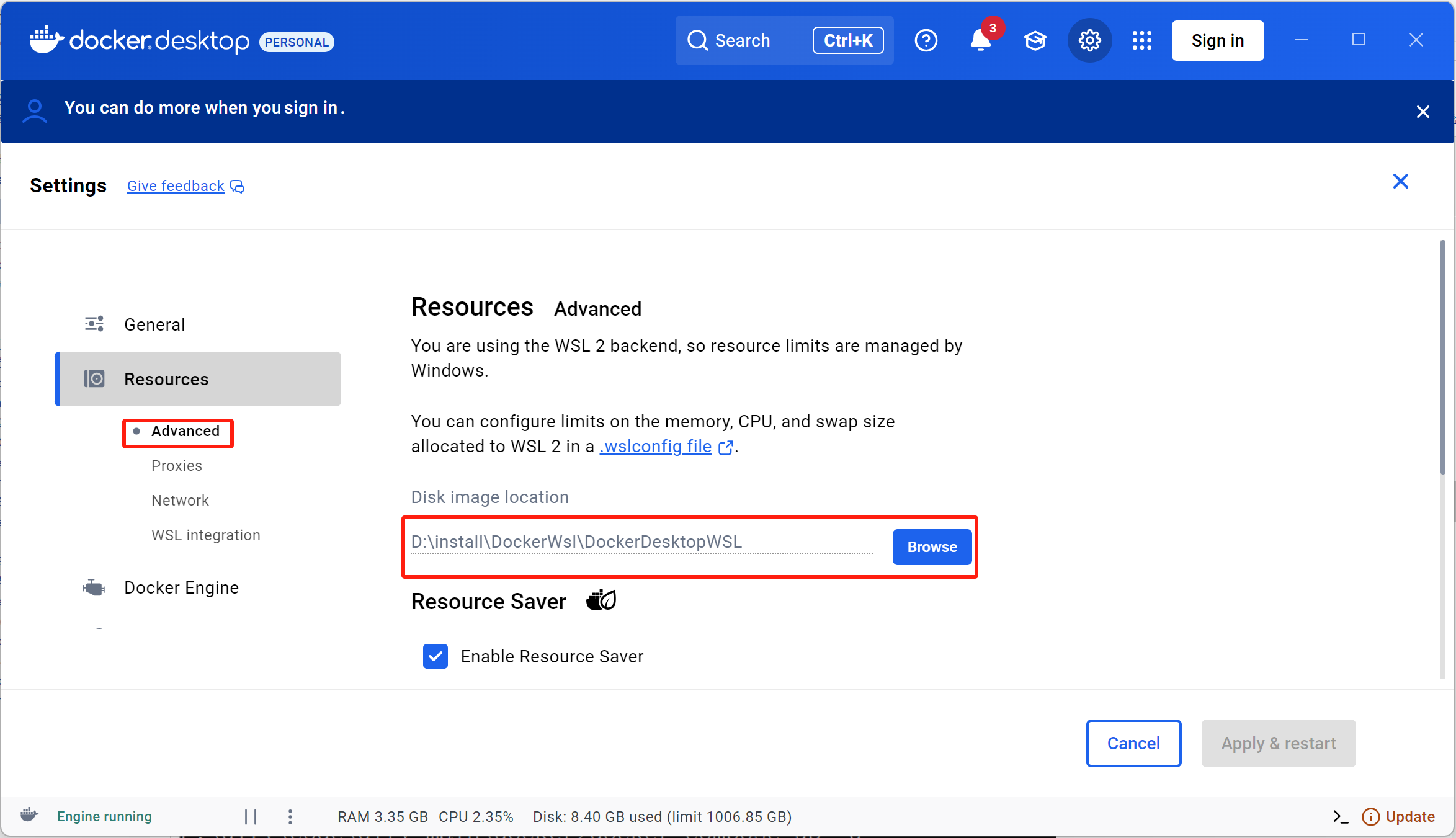
检查docker compose和docker是否安装成功:
F:\dify\code\dify-main\docker>docker --version Docker version 28.1.1, build 4eba377 F:\dify\code\dify-main\docker>docker-compose --version Docker Compose version v2.35.1-desktop.1
下载Dify源码
git clone -b 1.9.2 https://github.com/langgenius/dify.git
cmd进入dify源码目录下的docker目录,复制文件“.env.example”改名为”.env”
启动命令:docker compose up -d,-d表示后台运行
结束命令:docker compose down
注意:启动之前要打开docker desktop,否则无法找到镜像
下面展示两个启动报错的情形:
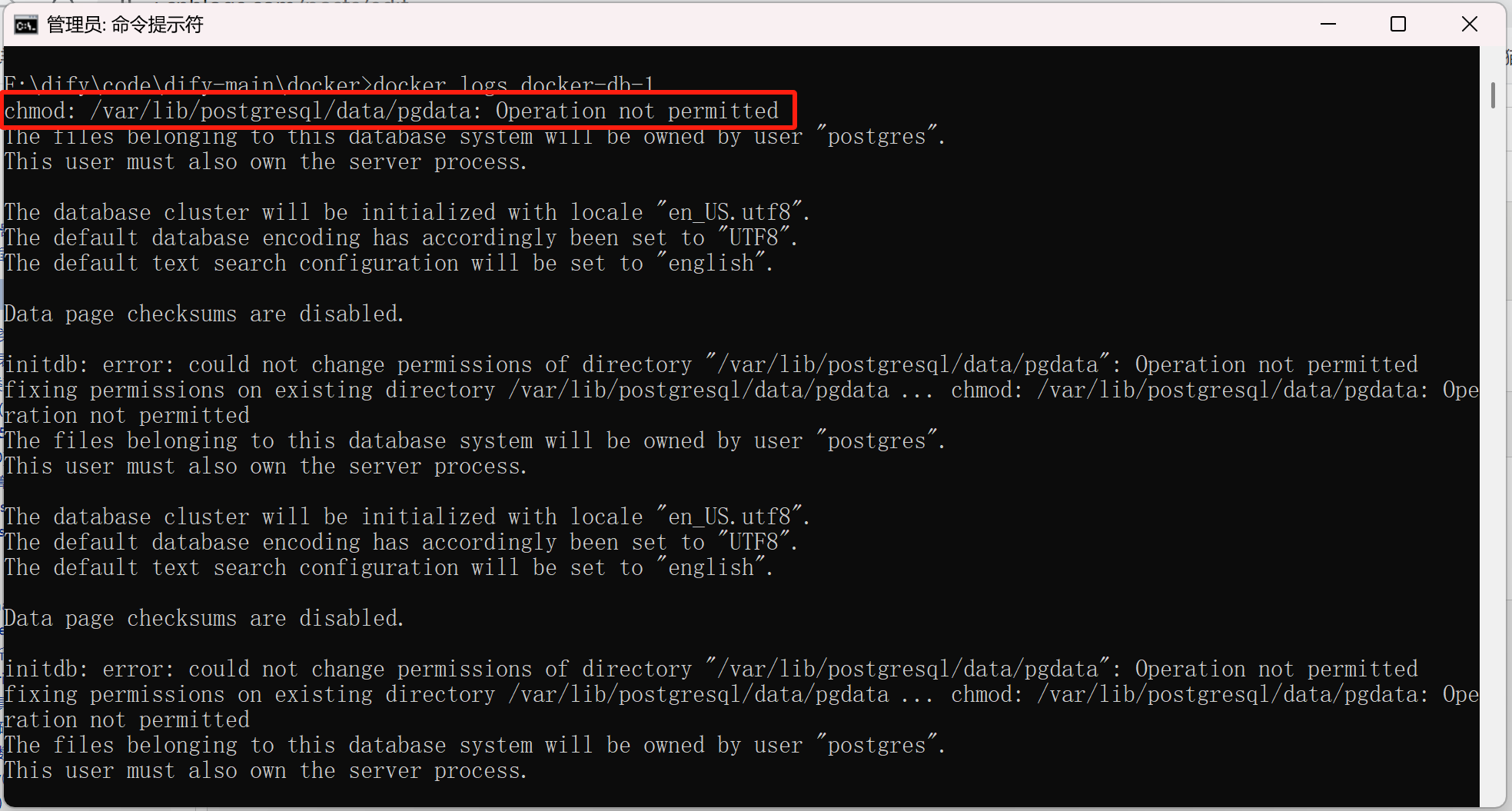
1、docker-db-1启动报错:
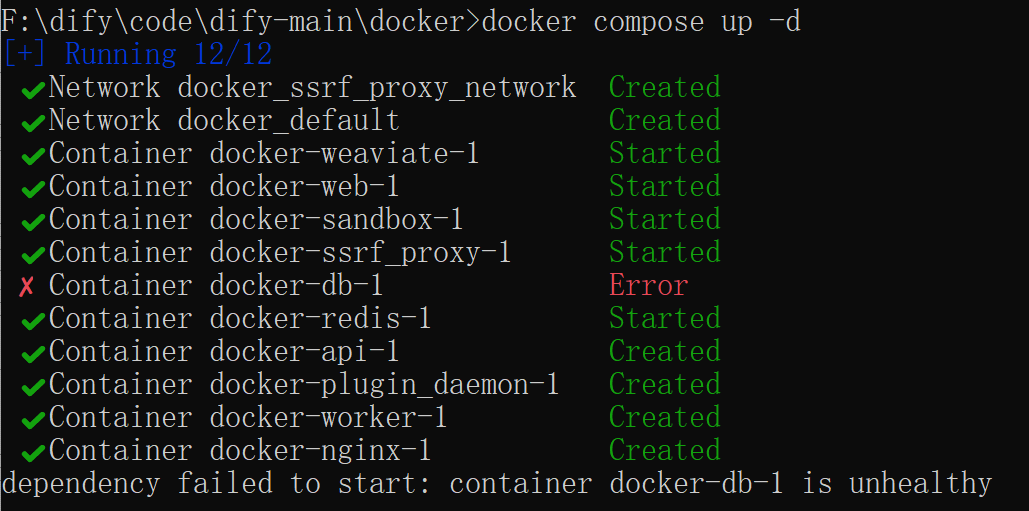
查看日志:
docker logs docker-db-1
结果:
修改1:
db: image: postgres:15-alpine restart: always environment: PGUSER: ${PGUSER:-postgres} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-difyai123456} POSTGRES_DB: ${POSTGRES_DB:-dify} PGDATA: ${PGDATA:-/var/lib/postgresql/data/pgdata} command: > postgres -c 'max_connections=${POSTGRES_MAX_CONNECTIONS:-100}' -c 'shared_buffers=${POSTGRES_SHARED_BUFFERS:-128MB}' -c 'work_mem=${POSTGRES_WORK_MEM:-4MB}' -c 'maintenance_work_mem=${POSTGRES_MAINTENANCE_WORK_MEM:-64MB}' -c 'effective_cache_size=${POSTGRES_EFFECTIVE_CACHE_SIZE:-4096MB}' volumes: - postgres-data:/var/lib/postgresql/data/pgdata healthcheck: test: [ 'CMD', 'pg_isready', '-h', 'db', '-U', '${PGUSER:-postgres}', '-d', '${POSTGRES_DB:-dify}' ] interval: 1s timeout: 3s retries: 60
修改2:
volumes: oradata: dify_es01_data: postgres-data:
2、docker-nginx-1启动报错
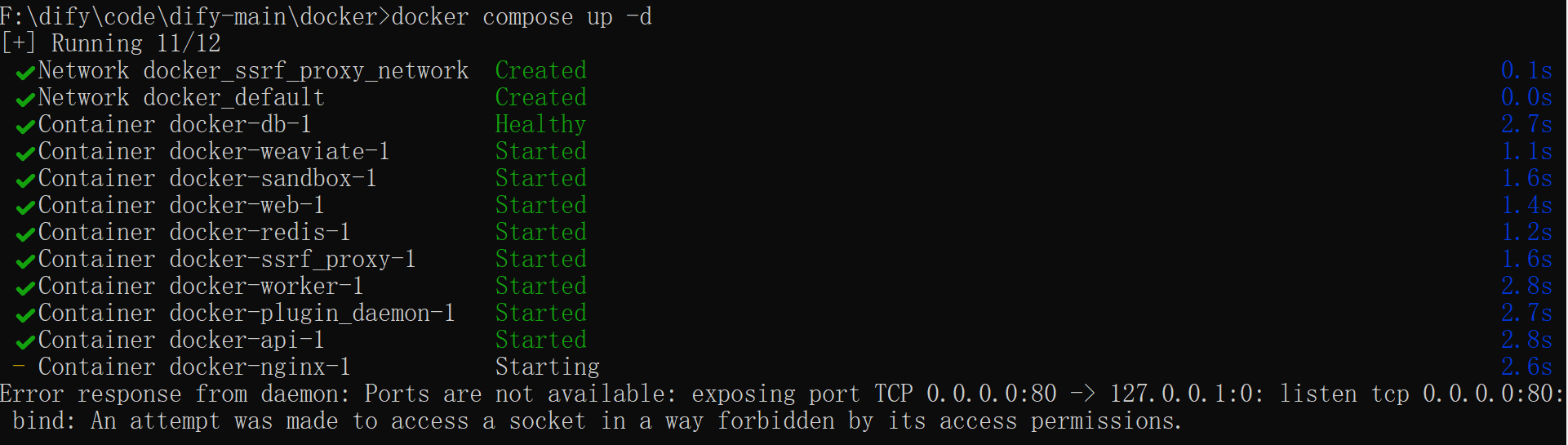
此错误表明 80 端口被系统或其他进程占用。
查看被80端口占用的进程
netstat -ano | findstr :80
结果:
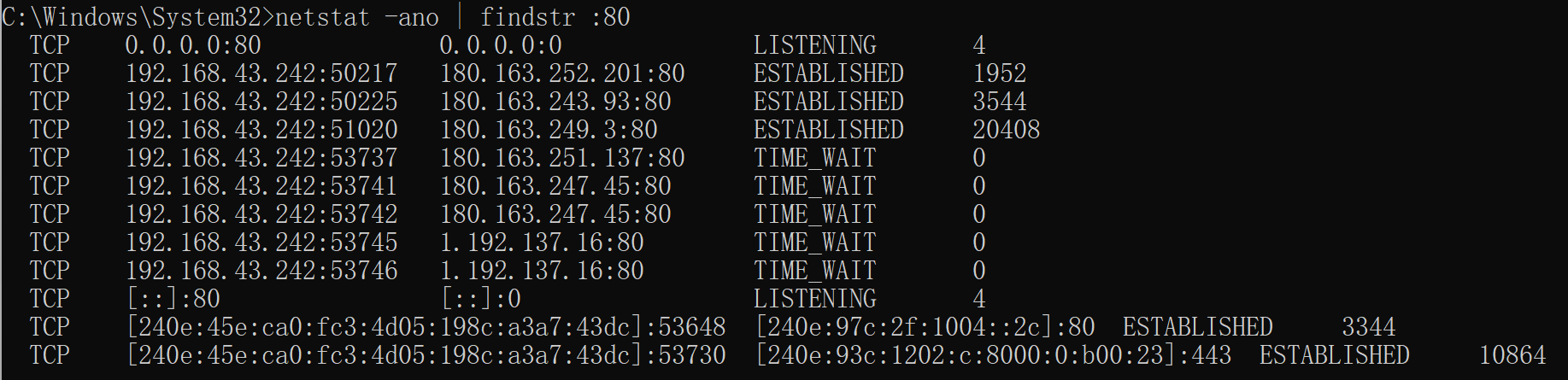
我们不采取终止占用进程的办法,而是修改端口80为8080
先来看看docker-compose.yaml文件中下面的配置的作用
EXPOSE_NGINX_PORT: ${EXPOSE_NGINX_PORT:-80}
-
EXPOSE_NGINX_PORT:这是 Docker Compose 中定义的环境变量名。
-
${EXPOSE_NGINX_PORT:-80}:这是 Shell 风格的变量替换语法:-
:-表示:如果变量EXPOSE_NGINX_PORT未设置或为空,则使用默认值80。 -
如果变量已设置(比如在
.env文件或命令行中),则使用设置的值。
-
现在我们来修改.env文件中EXPOSE_NGINX_PORT的配置为8080

再次启动
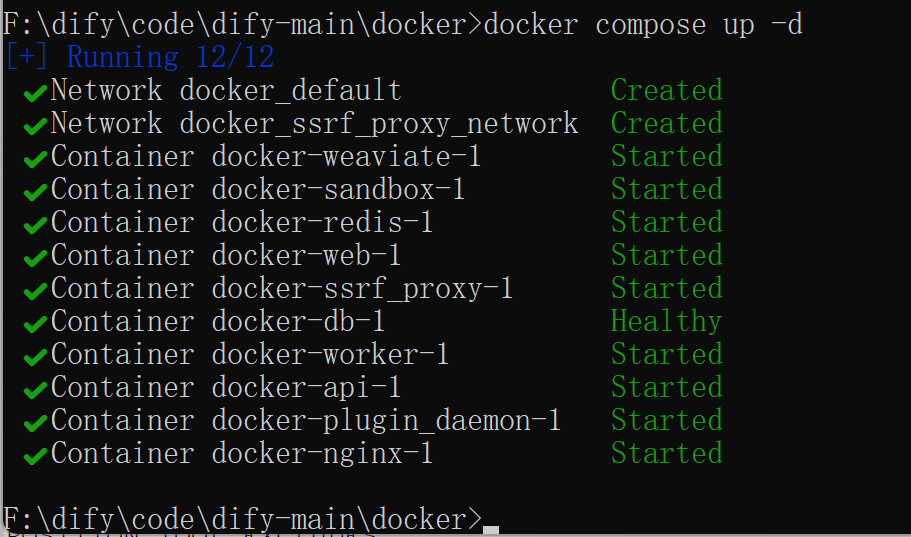
浏览器访问:http://localhost:8080/install,效果如下:
设置本地dify的账户信息
设置完成之后即可登录,登录成功之后效果如下:
三、linux中安装DIFY
安装 Dify 之前, 请确保你的机器已满足最低安装要求:
- CPU >= 2 Core
- RAM >= 4 GiB
Docker 19.03 or later,Docker compose 1.28 or later
1、安装docker
Docker要求CentOS的内核版本,至少高于3.10 ,可以使用命令uname -r查看。
[root@ecs-5bde ~]# uname -r 4.18.0-348.7.1.el8_5.x86_64
安装docker所需依赖
yum install -y yum-utils device-mapper-persistent-data lvm2
添加阿里云仓库
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装docker
yum -y install docker-ce
查看是否安装成功
[root@ecs-5bde ~]# docker --version Docker version 26.1.3, build b72abbb
启动docker
systemctl start docker
检查状态
systemctl status docker
停止
systemctl stop docker
配置国内镜像源
为了提高 Docker 镜像的下载速度,可以配置国内镜像源
(1)、创建配置文件:
sudo mkdir -p /etc/docker
sudo vi /etc/docker/daemon.json
(2)、编辑 daemon.json 文件,添加以下内容:
{ "registry-mirrors": [
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc",
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://dockerproxy.com",
"https://gst6rzl9.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"http://mirrors.ustc.edu.cn/",
"https://mirrors.tuna.tsinghua.edu.cn/",
"http://mirrors.sohu.com/"
] }
(3)、重载配置并重启 Docker:
sudo systemctl daemon-reload
sudo systemctl restart docker
2、安装docker compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
(1)、如果报错:
[root@iZbp1buoq4hel9b4n2ec8mZ ~]# sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 6 12.1M 6 844k 0 0 3829 0 0:55:26 0:03:45 0:51:41 17050 curl: (92) HTTP/2 stream 0 was not closed cleanly: PROTOCOL_ERROR (err 1)
解决方案:
sudo yum install git -y sudo git config --system http.version HTTP/1.1
应用执行权限
sudo chmod +x /usr/local/bin/docker-compose
查看是否安装成功
docker-compose --version
结果:
docker-compose version 1.29.2, build 5becea4c
如果网络不行,无法下载docker-compose,可以先从github中下载安装包,网址:https://github.com/docker/compose/releases ,如下所示:

然后上传到服务器,放到/usr/local/bin/docker-compose目录下
mv docker-compose-linux-x86_64 /usr/local/bin/docker-compose
授权
chmod +x /usr/local/bin/docker-compose
检查是否安装成功
docker-compose -v
结果:
root@dsw-582668-7848cbb9b5-k75zm:/usr/local/bin# docker-compose -v Docker Compose version v2.38.1
3、上传代码到云服务器
4、启动dify
进入 Dify 源代码的 Docker 目录
cd dify/docker
复制环境配置文件
cp .env.example .env
显示所有文件:ls -a
启动 Docker 容器
docker compose up -d
三、Dify连接mysql配置
mysql可以安装到docker中,也可以安装到windows或linux中。
后续我们将会在Dify中创建工作流,使用“代码执行节点”执行python代码操作MySQL中数据。Dify通过python代码连接MySQL需要做如下配置。
1. 安装pymysql依赖库
需要在“F:\dify\code\dify-main\docker\volumes\sandbox\dependencies”目录中的“python-requirements.txt”文件中加入pymysql依赖,这样Dify启动后运行的docker容器可以找到python mysql依赖:

python-requirements.txt告诉docker-sandbox-1容器启动的时候安装哪些python依赖。
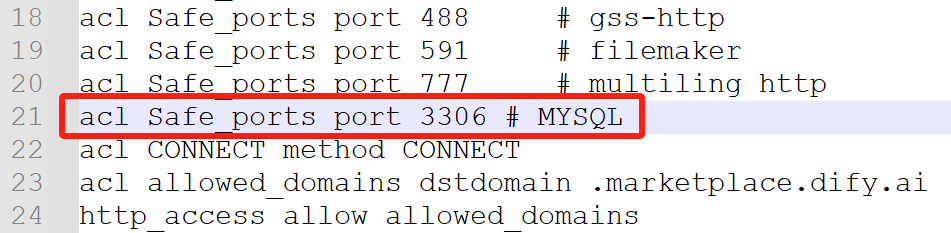
2. 设置允许Dify访问3306端口
在“F:\dify\code\dify-main\docker\ssrf_proxy”目录中的“squid.conf.template”文件中增加如下内容,让Dify认为3306端口为安全访问端口。
acl Safe_ports port 3306 # MYSQL
如下所示:
3、设置允许dify访问外部网络
Dify后续运行在sandbox容器中,默认在该容器中不允许连接外部ip,通过配置“F:\dify\code\dify-main\docker”目录中“docker-compose.yaml”文件中的sandbox部分,允许sandbox容器(docker-sandbox-1)连接外部网络。
docker-compose.yaml文件中修改处如下,只需要在“networks”部分加入 “- default”即可(特别提示:换行后可能存在Tab符号,可以删除该行后的空白行)。
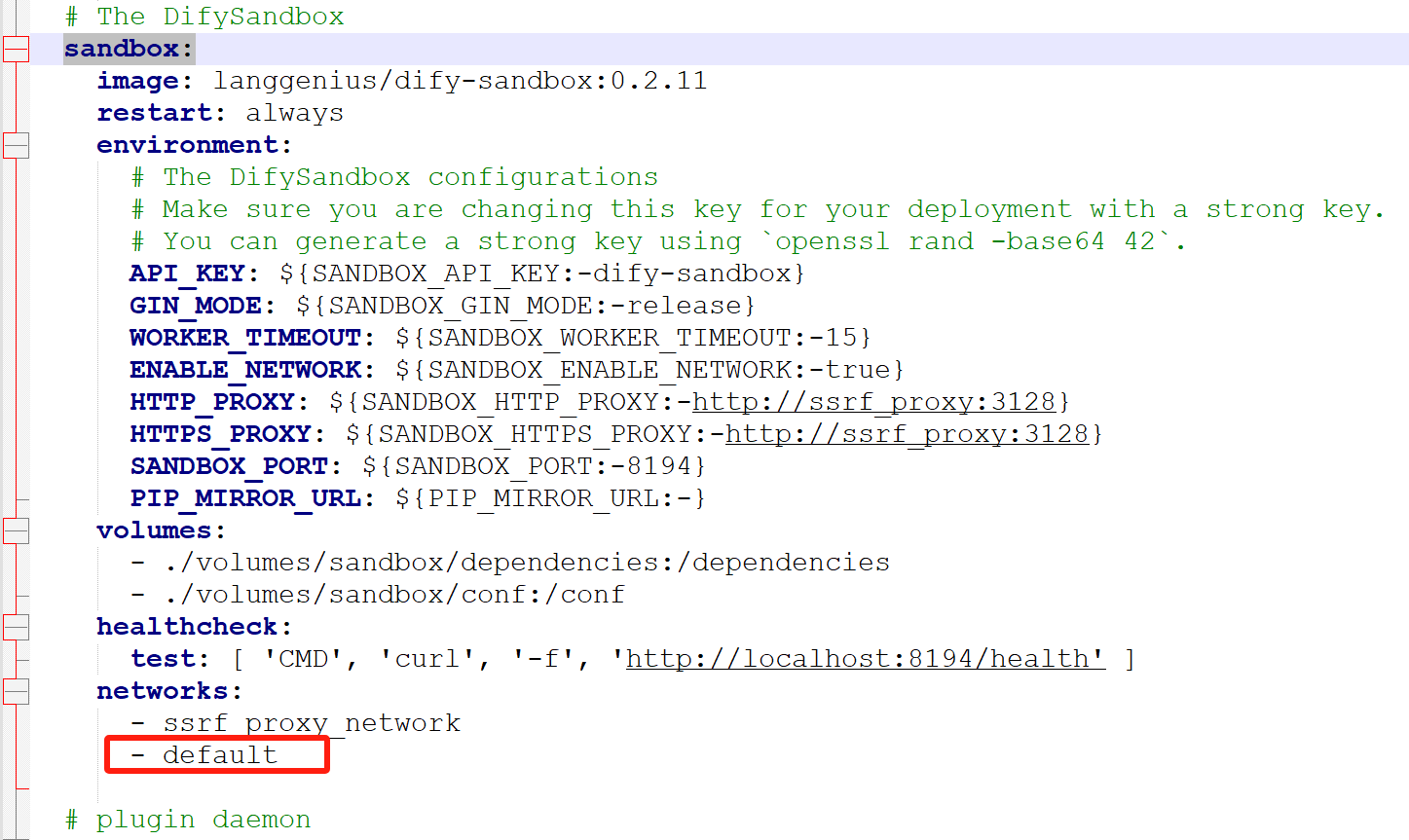
先停止Dify再重启Dify
docker compose down
docker compose up -d
四、接入大模型
注意:如果没有使用本机的模型,则你使用的模型是网上的。
安装模型供应商失败,则修改.env的配置如下:
PLUGIN_PYTHON_ENV_INIT_TIMEOUT=240 PLUGIN_MAX_EXECUTION_TIMEOUT=1200 PIP_MIRROR_URL=https://pypi.tuna.tsinghua.edu.cn/simple # PIP_MIRROR_URL=
在设置中查看模型供应商:
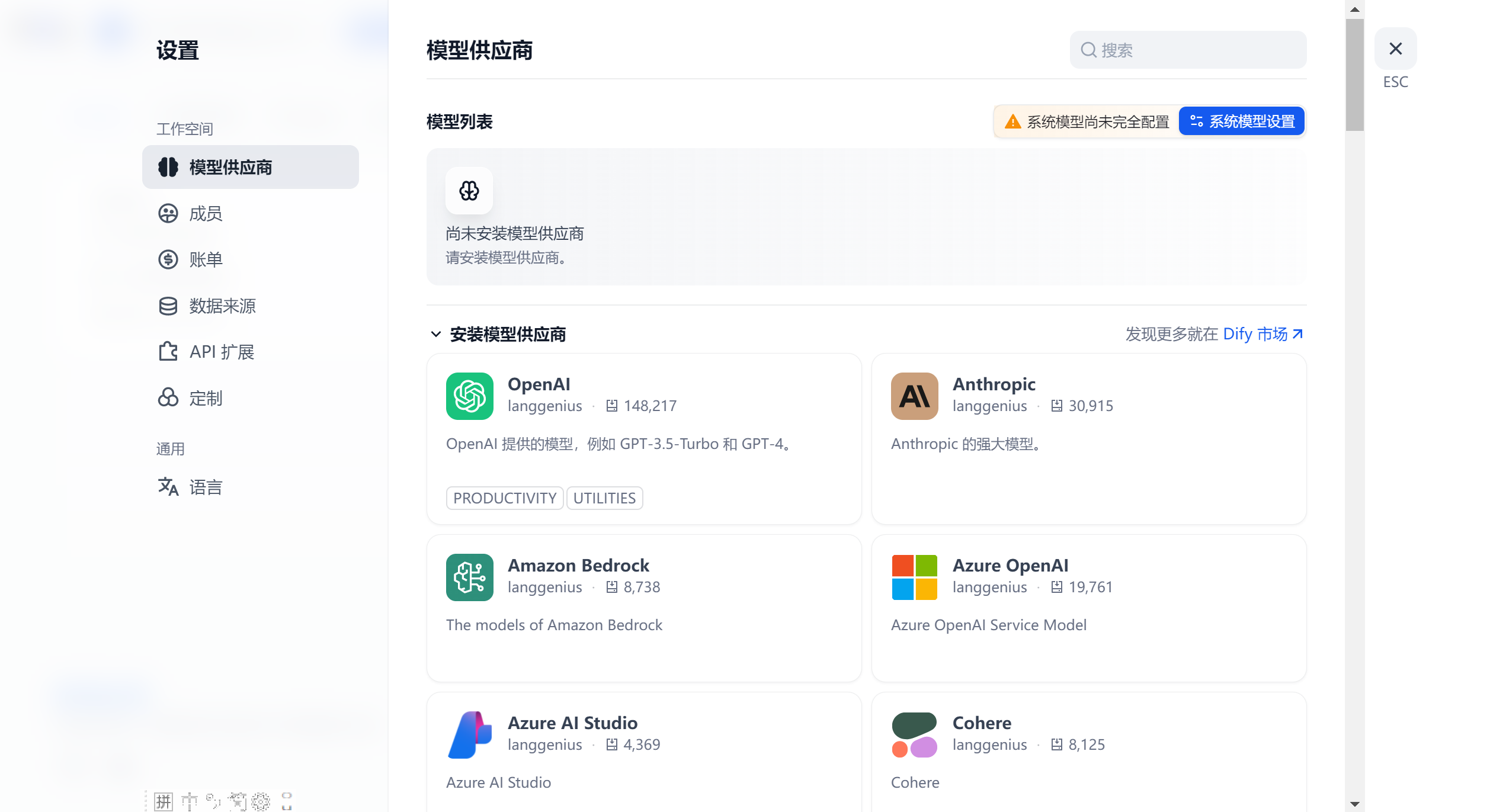
Dify 是基于大语言模型的 AI 应用开发平台,后续使用Dify时需要接入大模型,Dify 目前已支持主流的模型供应商,可以通过如下步骤设置Dify使用的大模型(以接入deepseek为例):
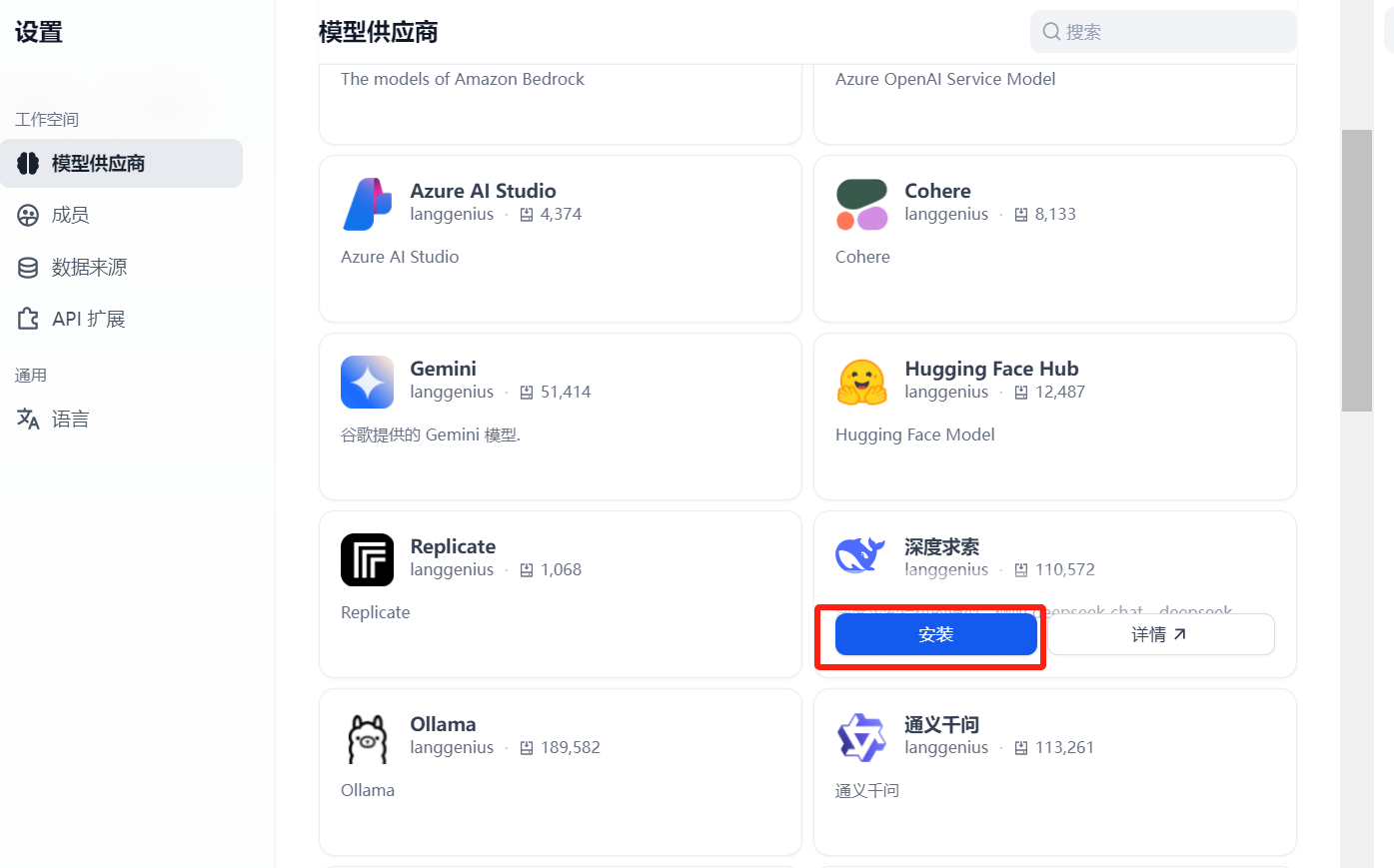
安装后模型列表如下:
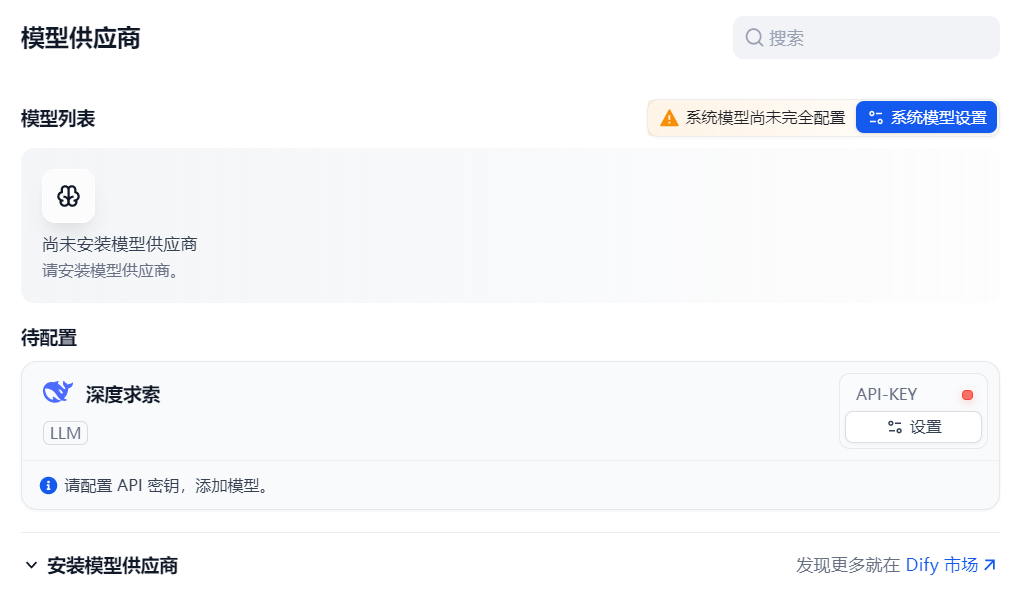
点击设置:
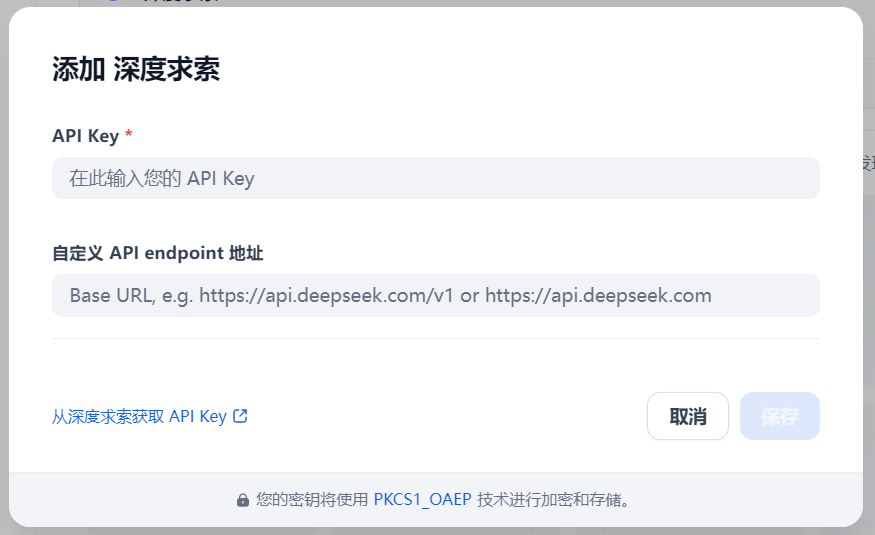
点击“从深度求索获取API Key”,跳转到deepseek开放平台
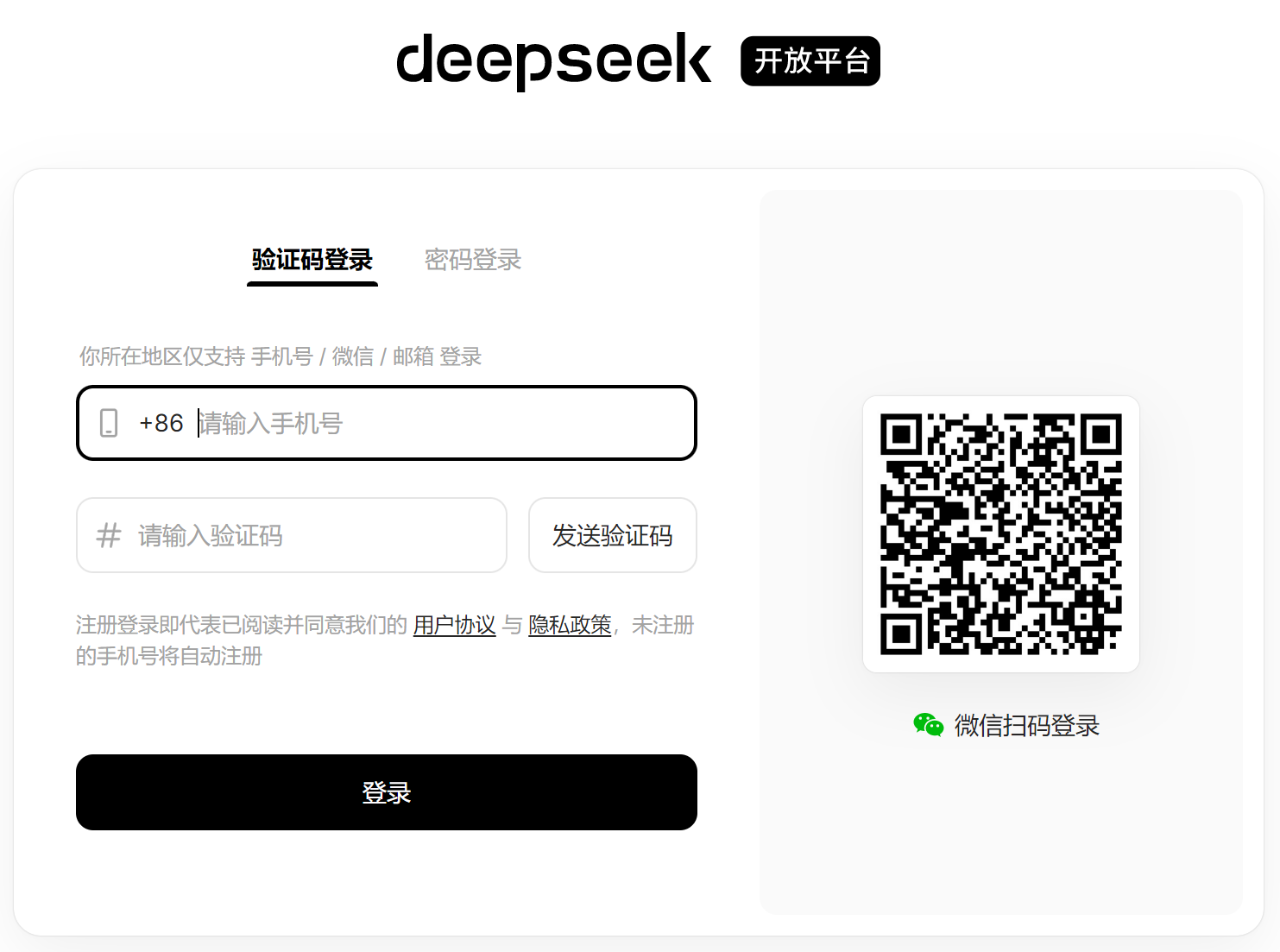
登录成功后进入如下界面:
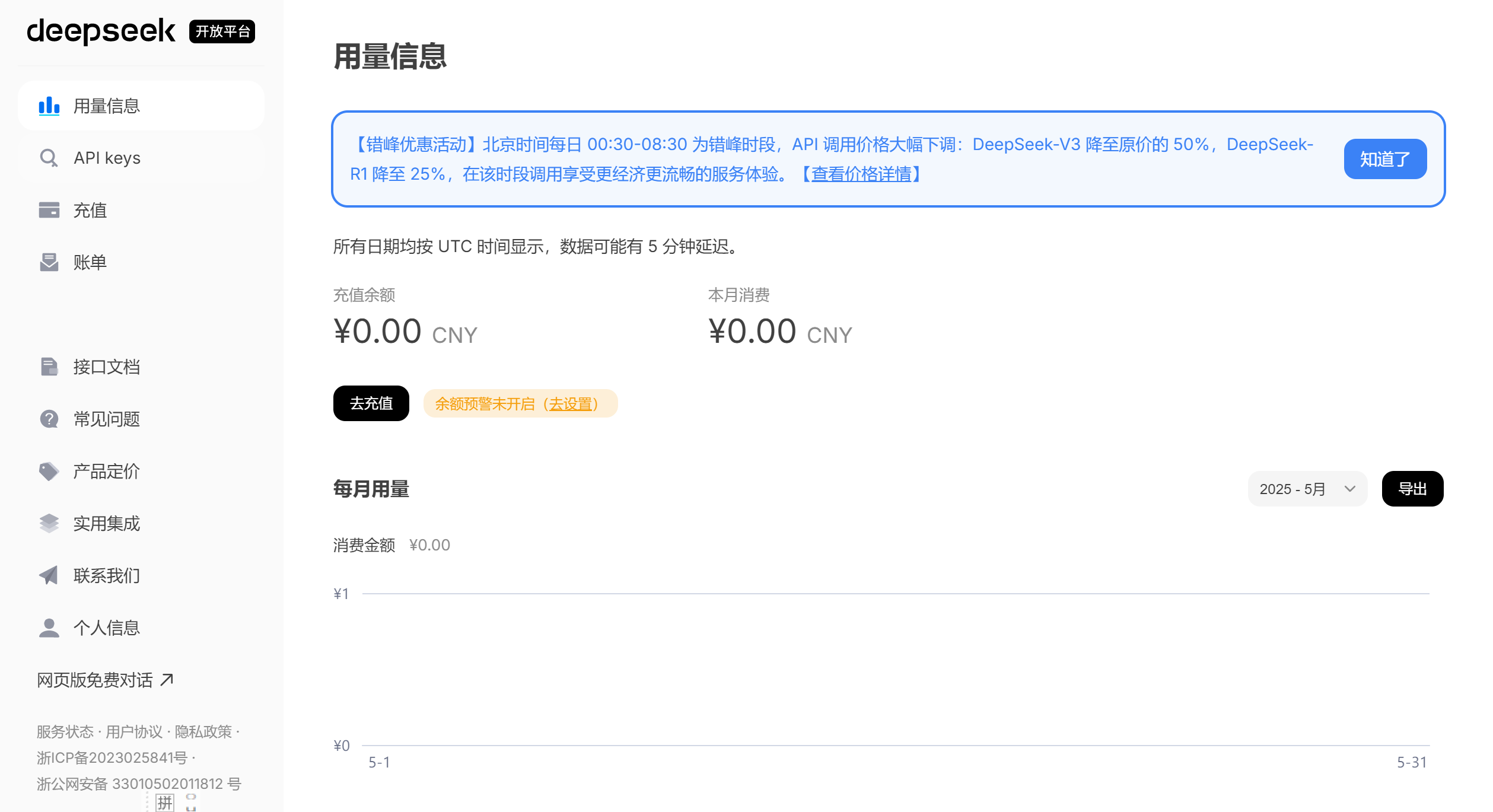
认证后去充值,重置成功后,创建API Key
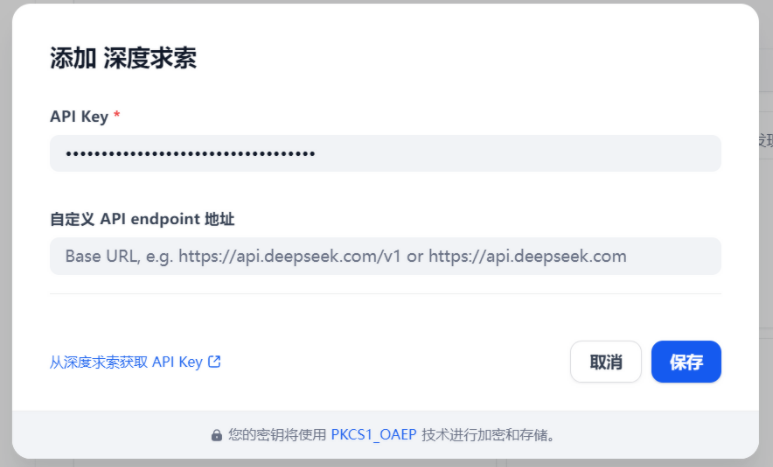
点击保存,右边的圆点变为绿色。

deepseek api keys地址:https://platform.deepseek.com/api_keys,如下是其他一些大模型api keys地址:
- 百川key:https://platform.baichuan-ai.com/console/apikey
- 百度千帆-文心一言:https://console.bce.baidu.com/iam/#/iam/accesslist
- SparkLLM Chat-科大讯飞星火:https://console.xfyun.cn/services/bm4
- Tongyi Qwen-阿里通义千问:key:https://bailian.console.aliyun.com/?apiKey=1#/api-key
- 腾讯混元大模型:https://console.cloud.tencent.com/cam/capi
- GLM-4智普大模型:https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
鉴于国内合规问题,如果你的应用需要在国内上线,应该使用合规的国产大模型。如果你的应用布局海外市场,那就可以使用 0penAI 等提供的大模型。
五、创建聊天助手应用-聊天机器人
在 Dify 中,一个“应用”是指基于 GPT 等大语言模型构建的实际场景应用。Dify中定义了五种应用类型:
(1)、聊天助手:基于 LLM 构建对话式交互的助手。
我们都使用过 chatGpt 、 文心一言 这样的 聊天助手 ,就是和机器人进行一问一答的聊天应用。你可能会问:既然已经有chatGpt、文心一言 这样的 聊天助手 了,我们为什么还要开发其他 聊天助手 呢?这个问题很好!至少有两点需求推动我们去开发 聊天助手
(a)、如果我们自己的网站或替 APP 也需要一个聊天助手,难道直接把 chatGpt、文心一言 的页面嵌入进e来吗?肯定不可以,至少登录体系和你的应用不一致。
(b)、ChatGpt、 文心一言 回答的都是一些通用的知识,试想一下现在你有一个需求,你需要让聊天助手回答关于你公司产品说明书的使用帮助, chatGpt、文心一言 能回答吗?显然不可以,因为他并没有学过你们公司的产品说明书。那么我们就需要去开发一个事先学习过你们产品说明书的聊天助手,
(2)、文本生成应用:面向文本生成类任务的助手,例如写故事、文本分类、翻译等
(3)、Agent:能够分解任务、推理思考、调用工具的对话式智能助手。
(3)、对话流:适用于定义等复杂流程的多轮对话场景,具有记忆功能的应用编排方式。o
(4)、工作流:适用于自动化、批处理等单轮生成类任务的场景的应用编排方式。
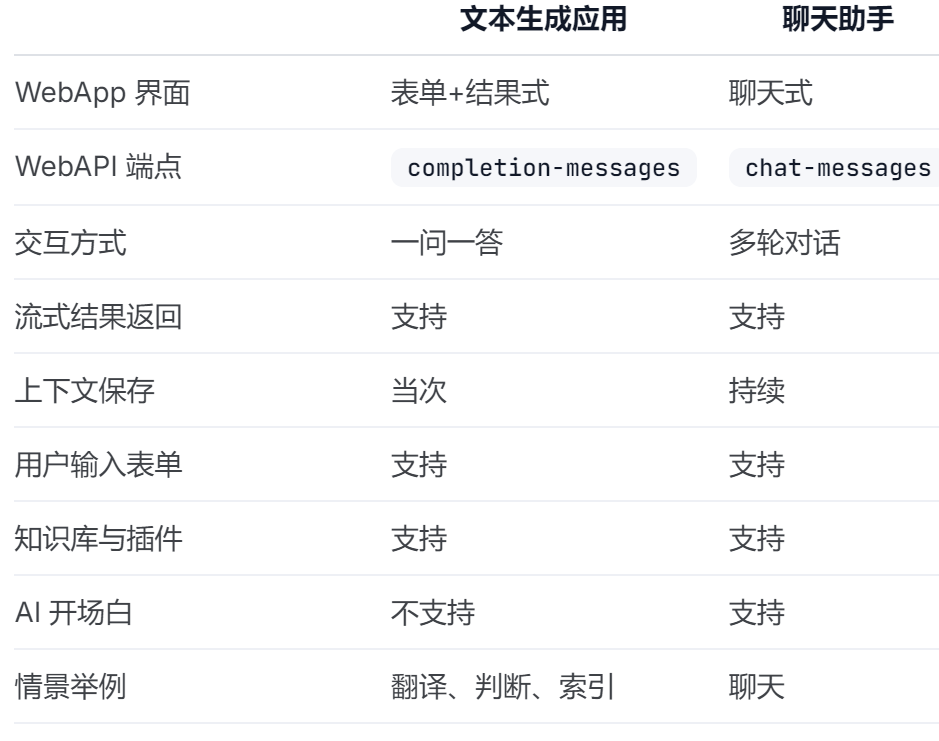
文本生成应用与聊天助手的区别见下表:
 点击创建空白应用:
点击创建空白应用:
进入如下界面:
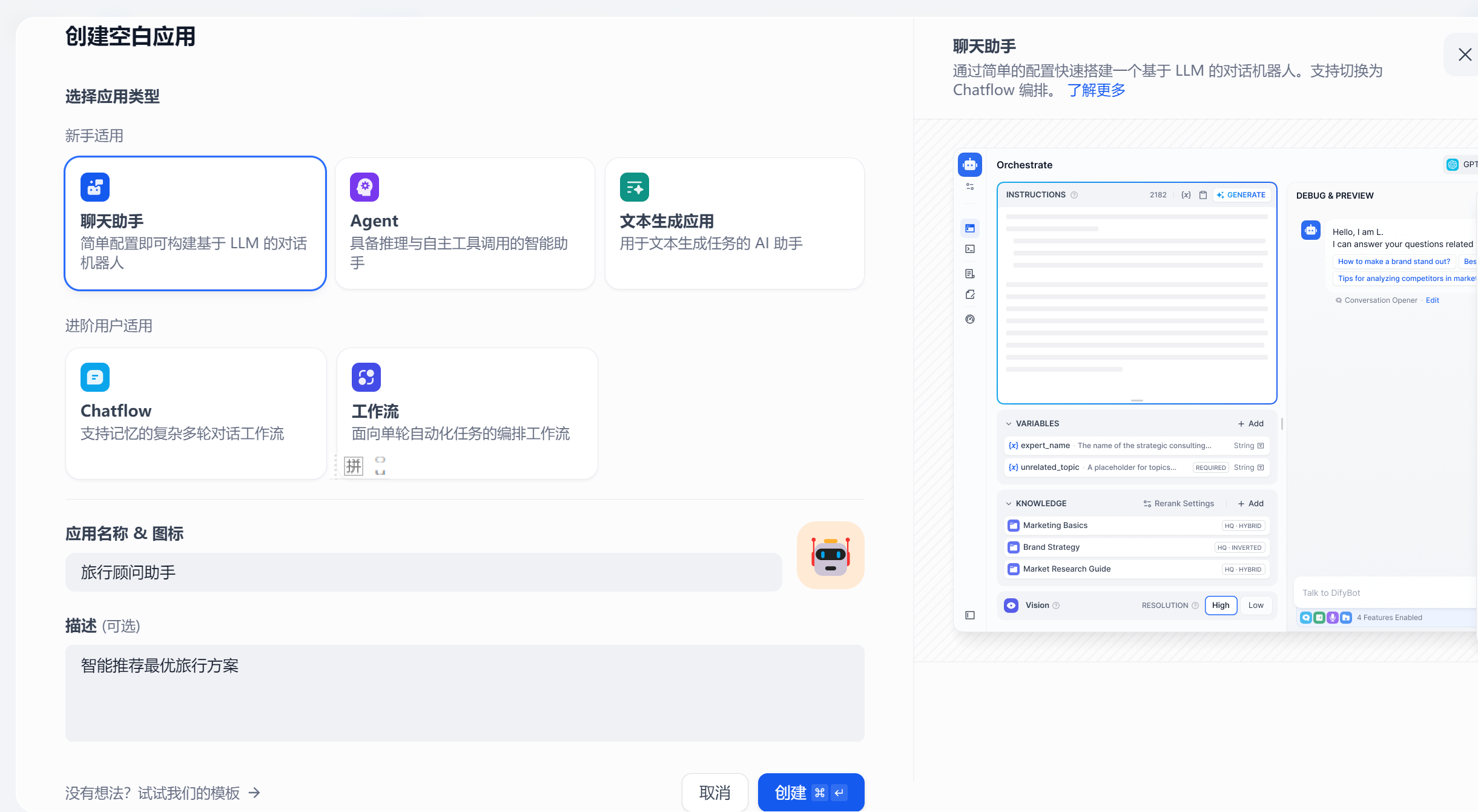
点击创建
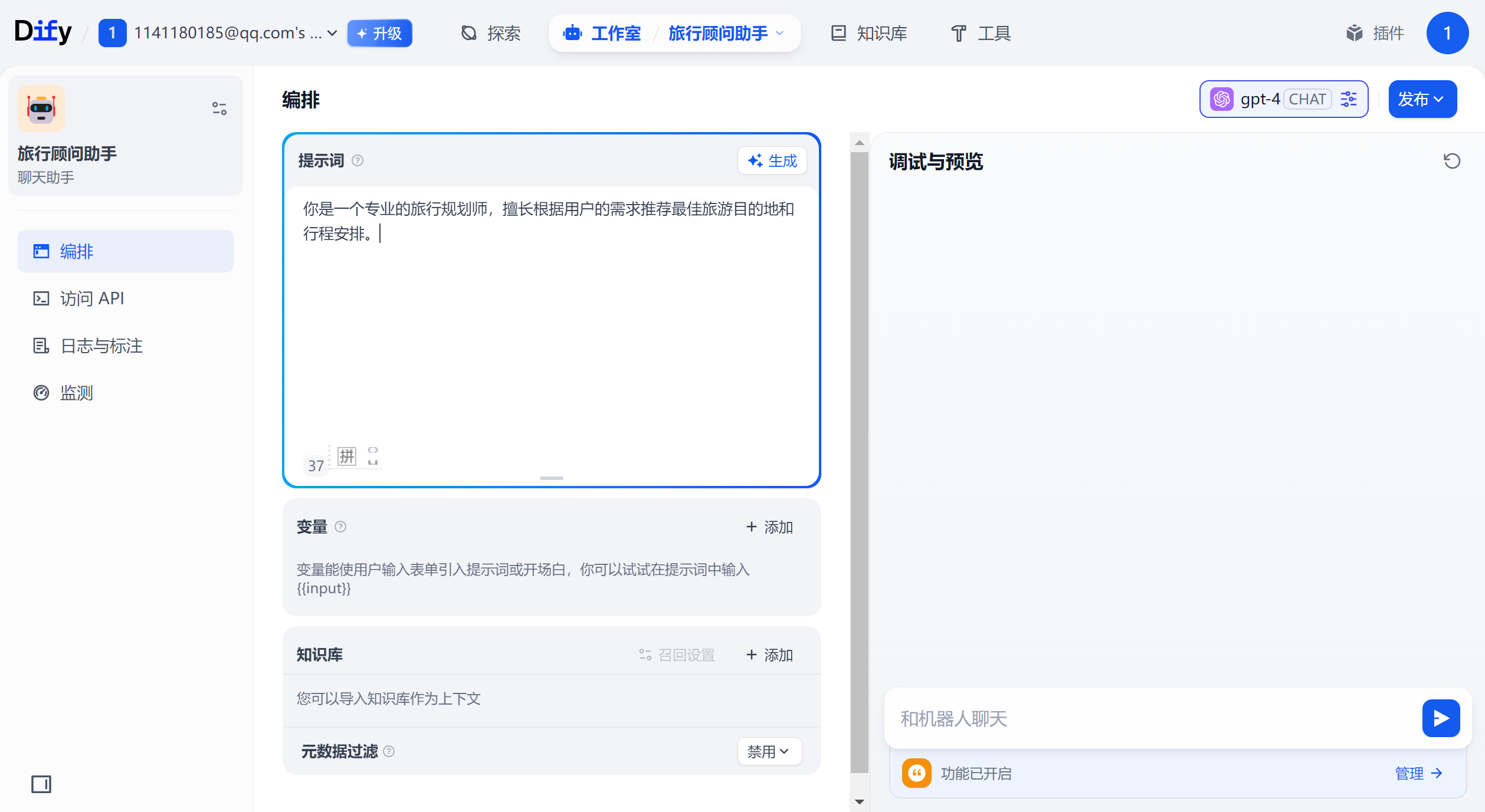
手动设置提示词
在「提示词」设置中,编辑系统提示词:你是一个专业的旅行规划师,擅长根据用户的需求推荐最佳旅游目的地和行程安排。
AI自动生成提示词
提示词用于约束 AI 给出专业的回复,让回应更加精确。你可以借助内置的提示生成器,编写合适的提示词。提示词内支持插入表单变量,例如 {{input}}。提示词中的变量的值会替换成用户填写的值。
提示生成器可以将输入的任务指令转换为高质量、结构化的提示。请尽可能详细地编写清晰、具体的指令。生成的提示的质量取决于您选择的推理模型。这里我们选择gpt-4模型。
点击 「生成」 ,填入 「指令」:旅行规划助手是一个智能工具,旨在帮助用户轻松规划他们的旅行
点击 「生成」
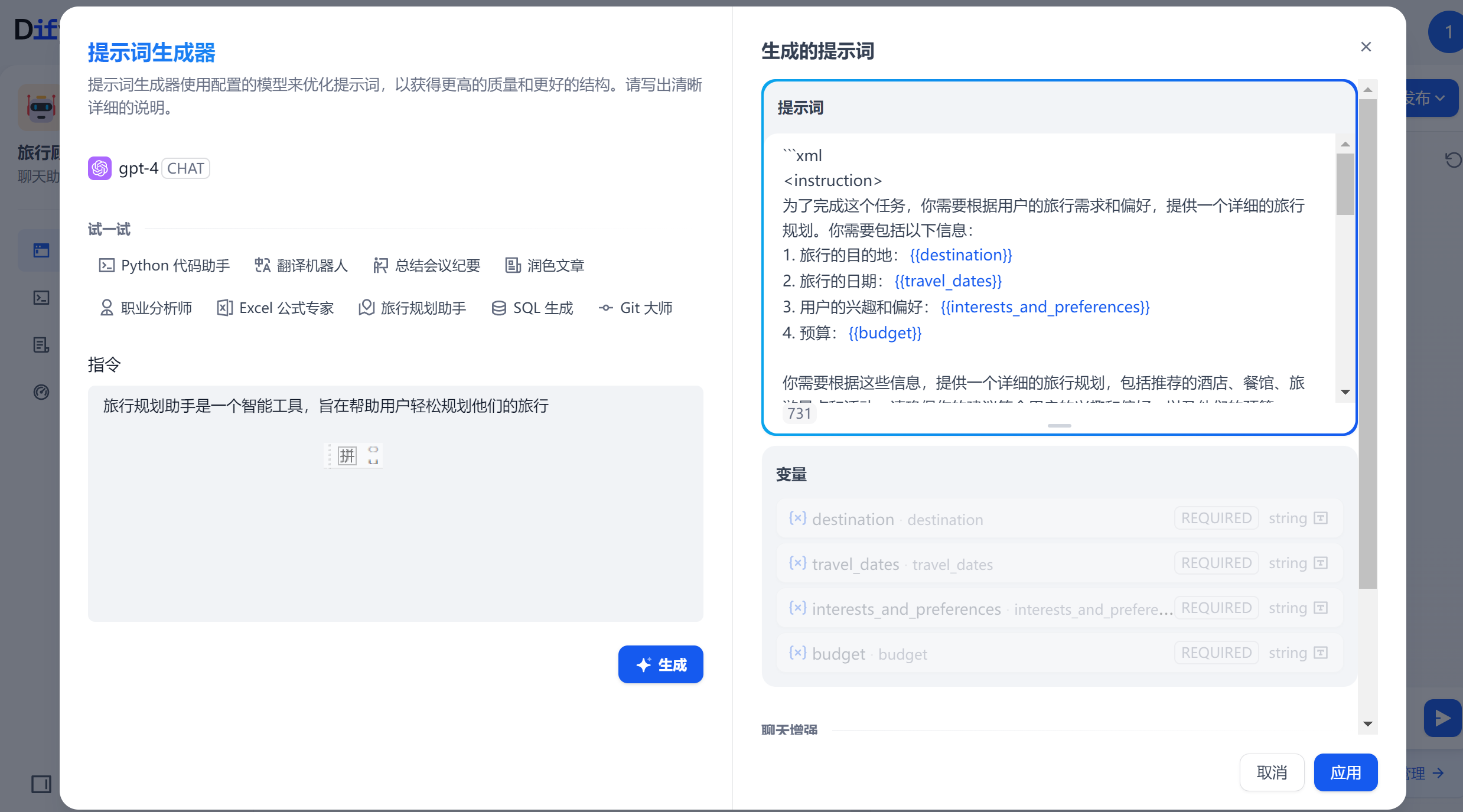
生成的提示词:
```xml <instruction> 为了完成这个任务,你需要根据用户的旅行需求和偏好,提供一个详细的旅行规划。你需要包括以下信息: 1. 旅行的目的地:{{destination}} 2. 旅行的日期:{{travel_dates}} 3. 用户的兴趣和偏好:{{interests_and_preferences}} 4. 预算:{{budget}} 你需要根据这些信息,提供一个详细的旅行规划,包括推荐的酒店、餐馆、旅游景点和活动。请确保你的建议符合用户的兴趣和偏好,以及他们的预算。 你的输出应该是一个详细的旅行规划,不包含任何XML标签。 例如: <example> 如果目的地是巴黎,旅行日期是2022年7月1日至7月7日,兴趣和偏好是艺术和美食,预算是2000美元,你的旅行规划可能包括推荐的艺术博物馆、美食餐馆,以及在预算范围内的酒店和活动。 </example> </instruction> <input> { "destination": "巴黎", "travel_dates": "2022年7月1日至7月7日", "interests_and_preferences": "艺术和美食", "budget": "2000美元" } </input> <output> 你的旅行规划是: 1. 住宿:推荐你住在巴黎市中心的艺术区,有许多价格合理的酒店供你选择。 2. 餐馆:巴黎有许多著名的美食餐馆,你可以尝试一些法国菜。 3. 景点和活动:你可以参观卢浮宫和奥赛博物馆,欣赏世界级的艺术作品。你还可以在塞纳河上乘船,欣赏巴黎的美景。 4. 预算:以上的建议都在你的预算范围内。 </output> ```
点击应用
点击确认
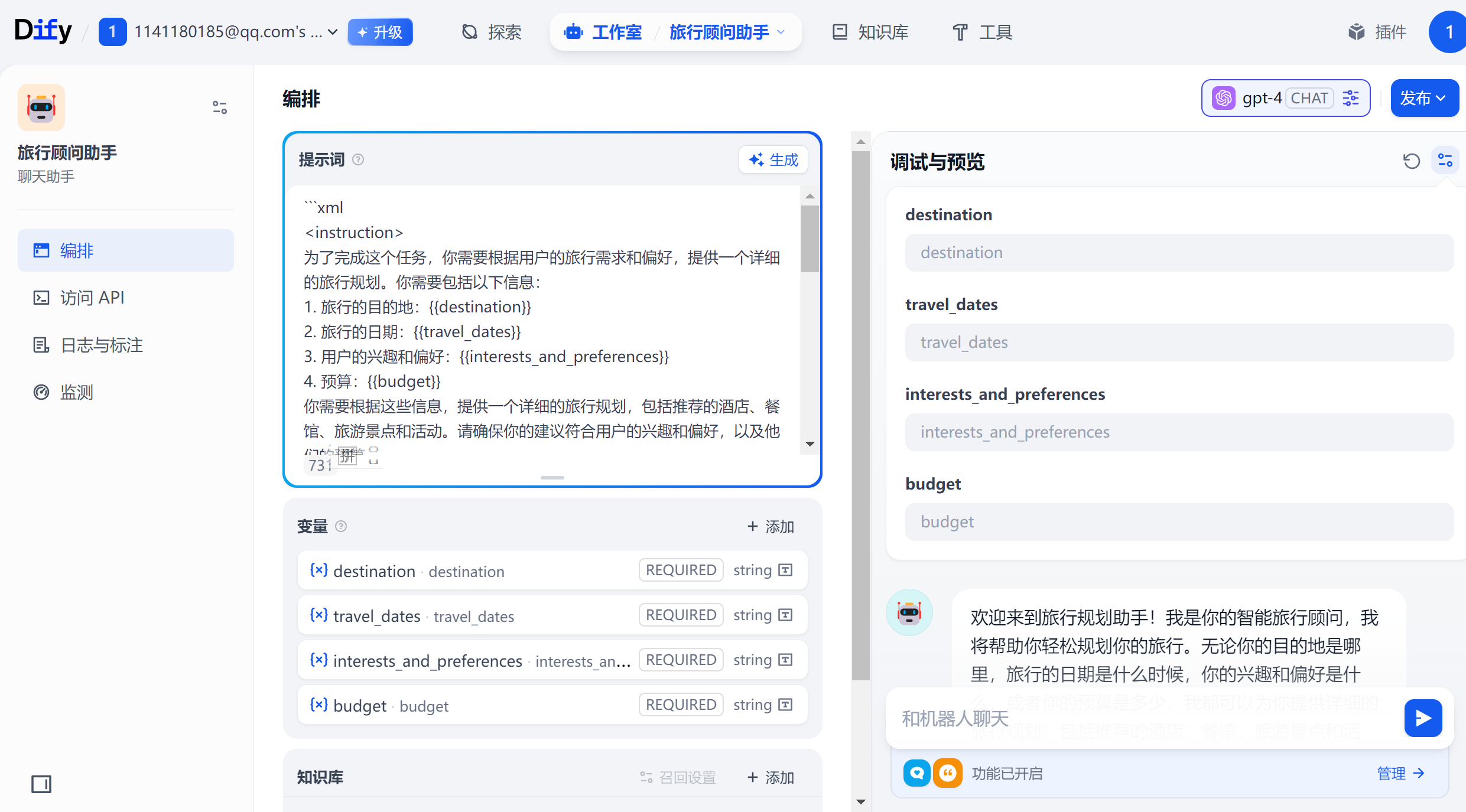
进行测试。
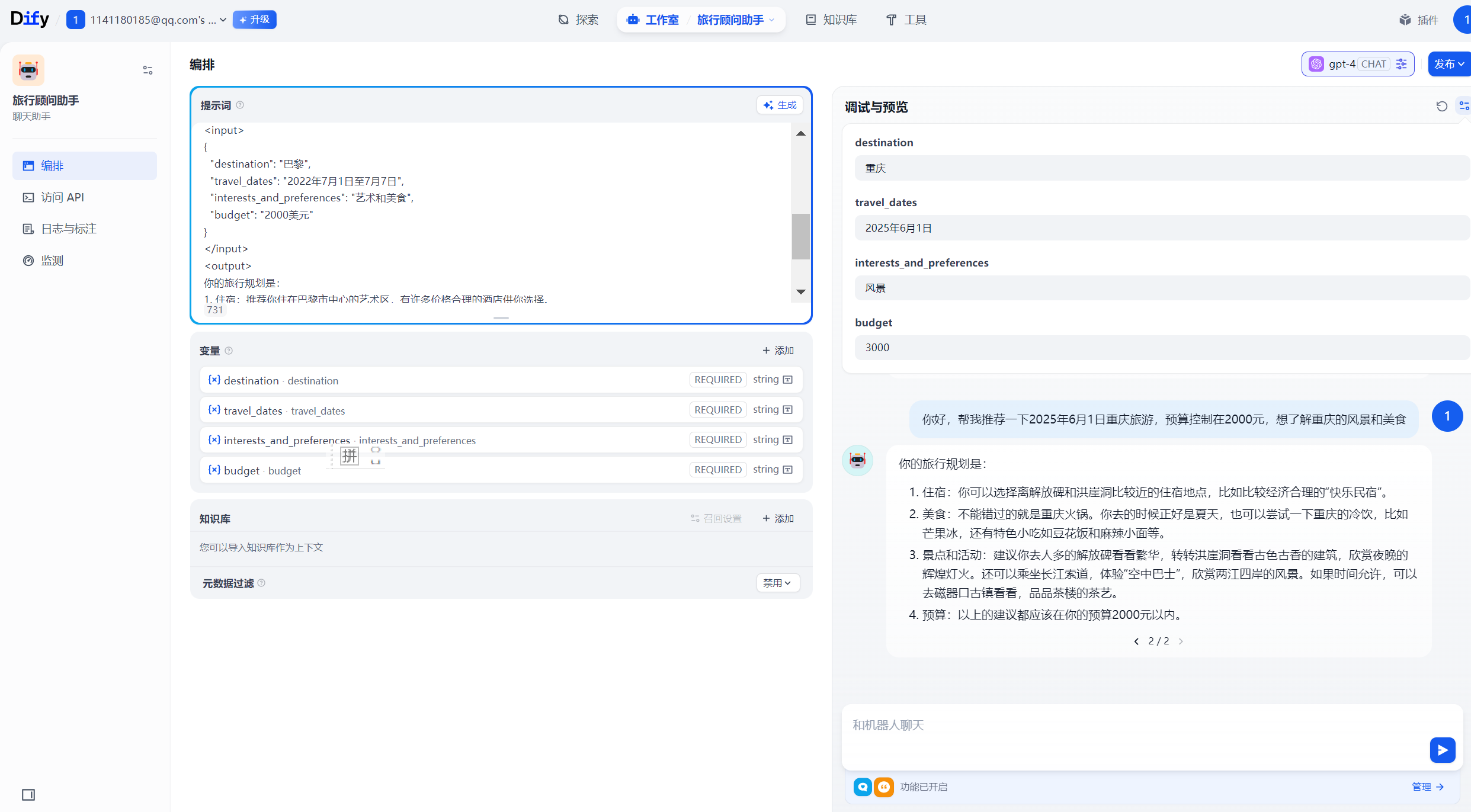
点击发布,发布之后可以在探索中找到
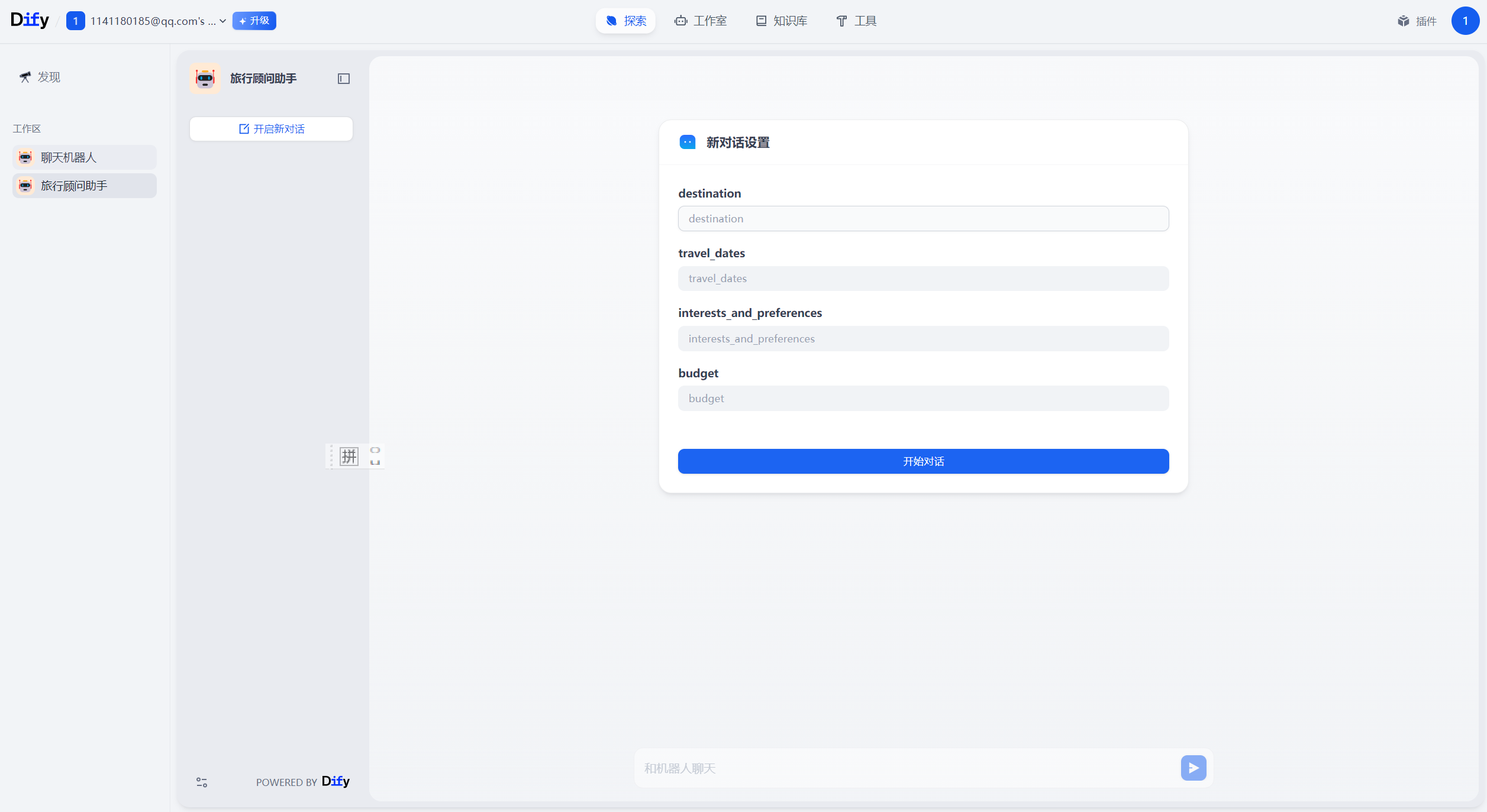
输入参数后,点击开始对话
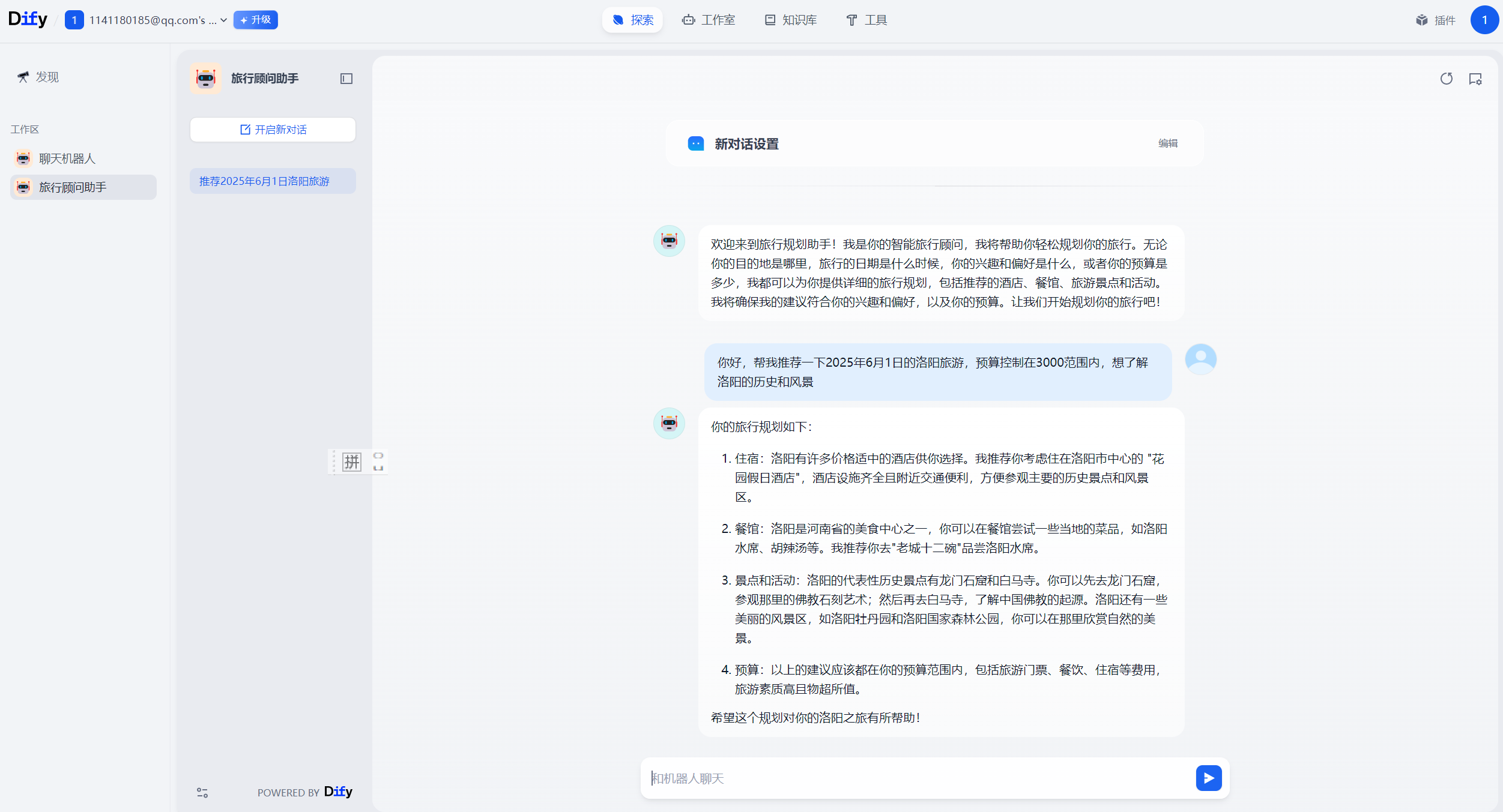
下面创建了一个医疗问诊机器人
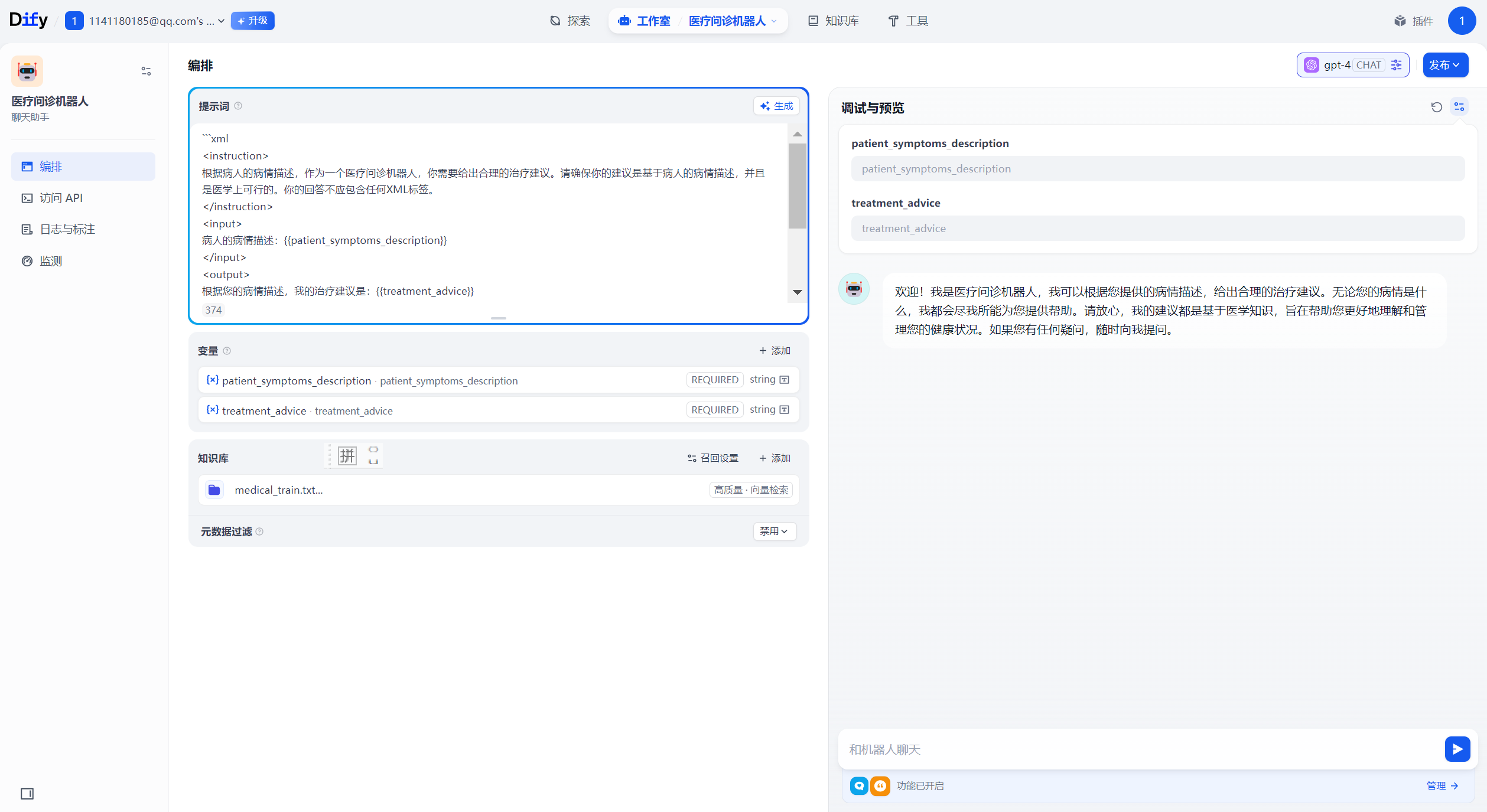
去除参数定义之后提示词如下所示:
```xml <instruction> 根据病人的病情描述,作为一个医疗问诊机器人,你需要给出合理的治疗建议。请确保你的建议是基于病人的病情描述,并且是医学上可行的。你的回答不应包含任何XML标签。 </instruction> <example> 例如,如果病人的病情描述是"我最近总是感到头痛,而且经常感到恶心",那么一个可能的治疗建议是"这可能是由于压力或缺乏睡眠引起的。我建议你尝试改变生活习惯,如保证充足的睡眠,避免过度劳累。如果症状持续或者加重,你应该尽快去看医生。" </example> ```
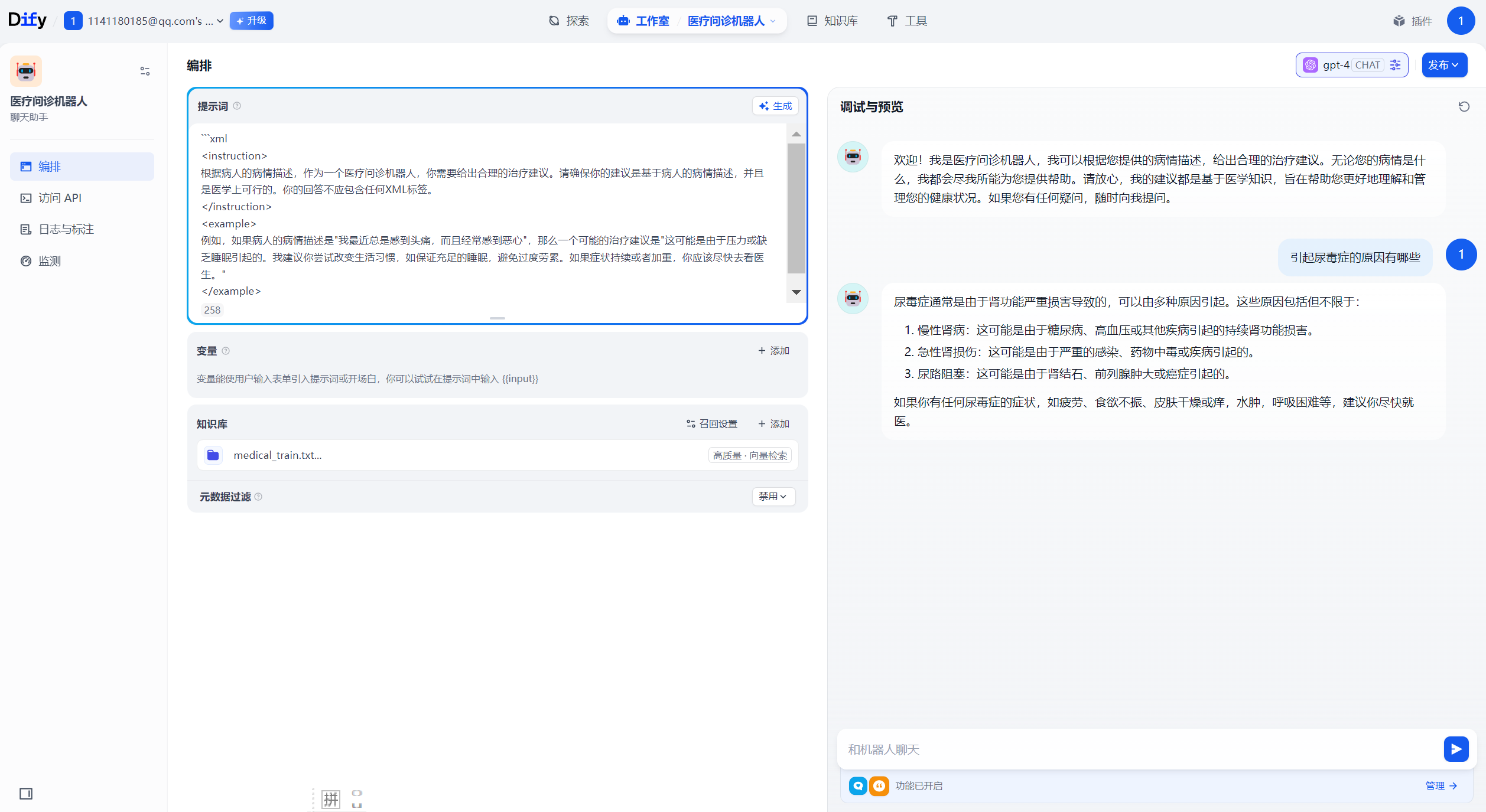
六、客户评价处理工作流
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
Dify 工作流分为两种类型:
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
需求
一个商城网站,用户在 PC 端对商品进行评价,传统的运营模式是运营人员登录管理后台系统查看用户对商品的评价。我们现在学习了 AI 技术后,对评价进行智能分类,分为正面评价和负面评价,正面评价发送至公司品牌宣传部邮箱。对负面评价再进行二次分类,分为商品问题、运输问题和其他问题,商品问题发送至售后邮箱,运输问题发送至公司运输部邮箱,其他问题发送至默认的客户支持邮箱。
1、创建工作流
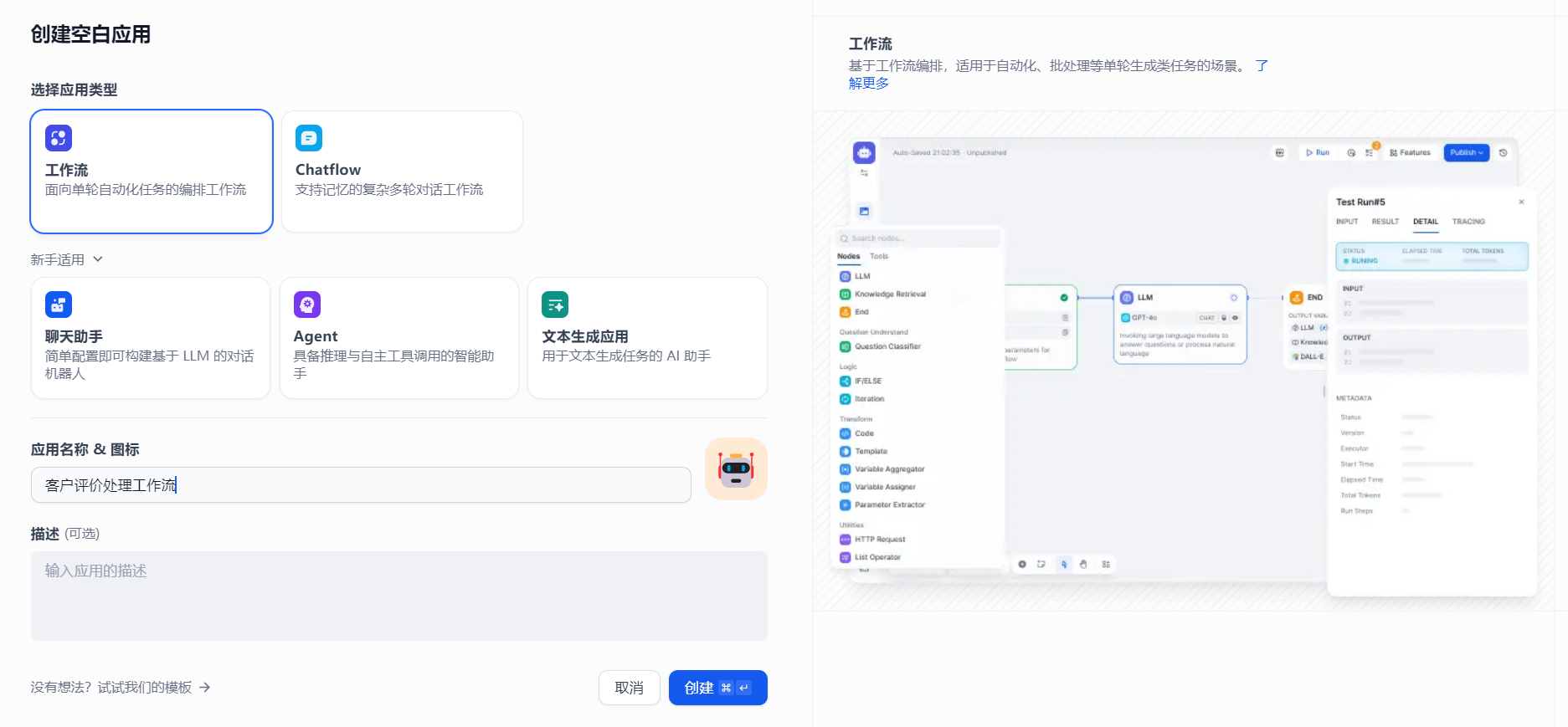
点击创建,就进入了工作流的编排页面。如下所示:
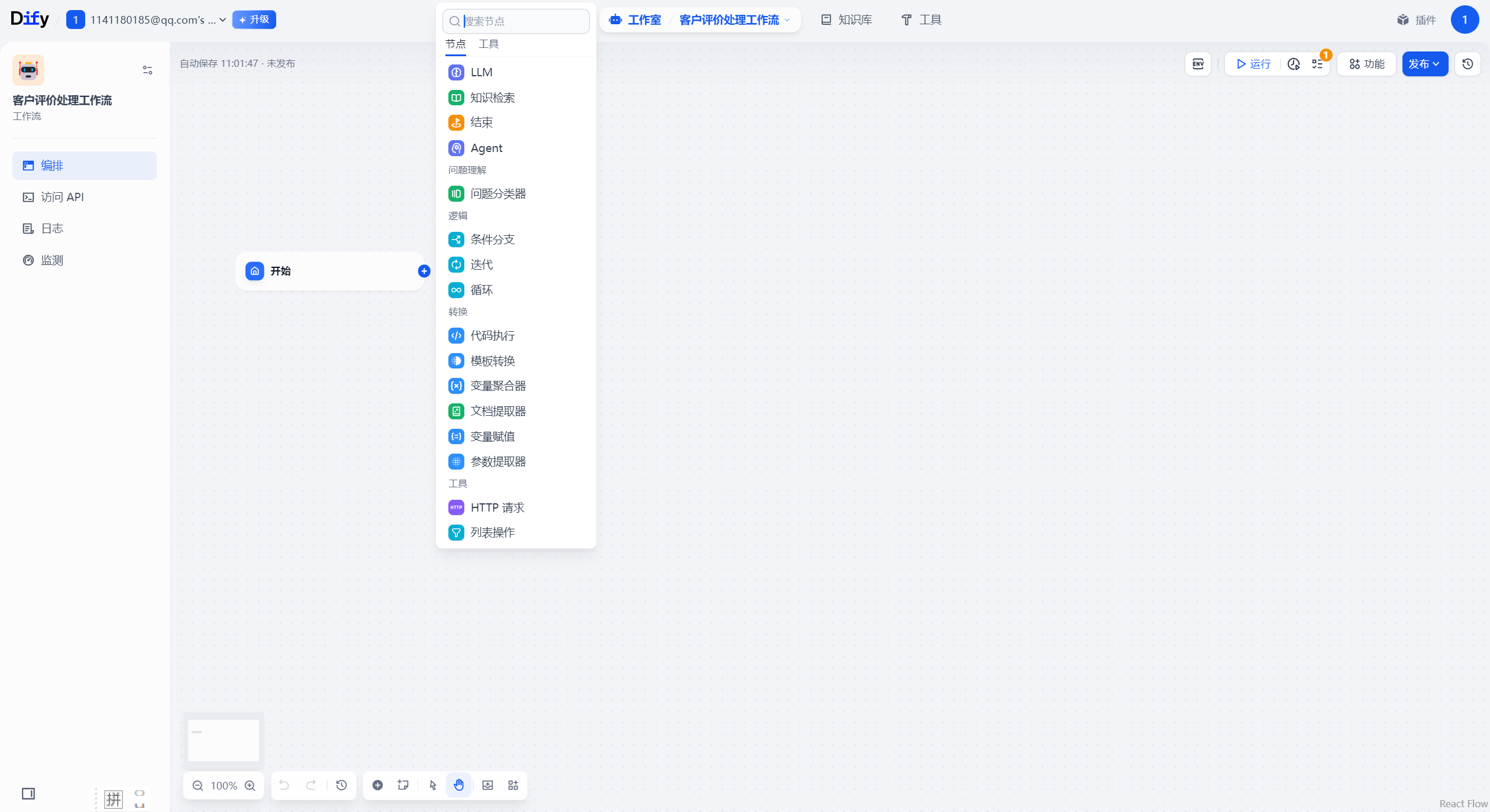
重要节点
节点是工作流中的关键构成,通过连接不同功能的节点,执行工作流的一系列操作。
Dify 中目前支持14种节点,我们不打算流水账式一个个去介绍他们,因为对于初学者来说,这种介绍方式只会让初学者一知半解,看得云里雾里,我们直接在不断的实战案例中讲解每一个节点!
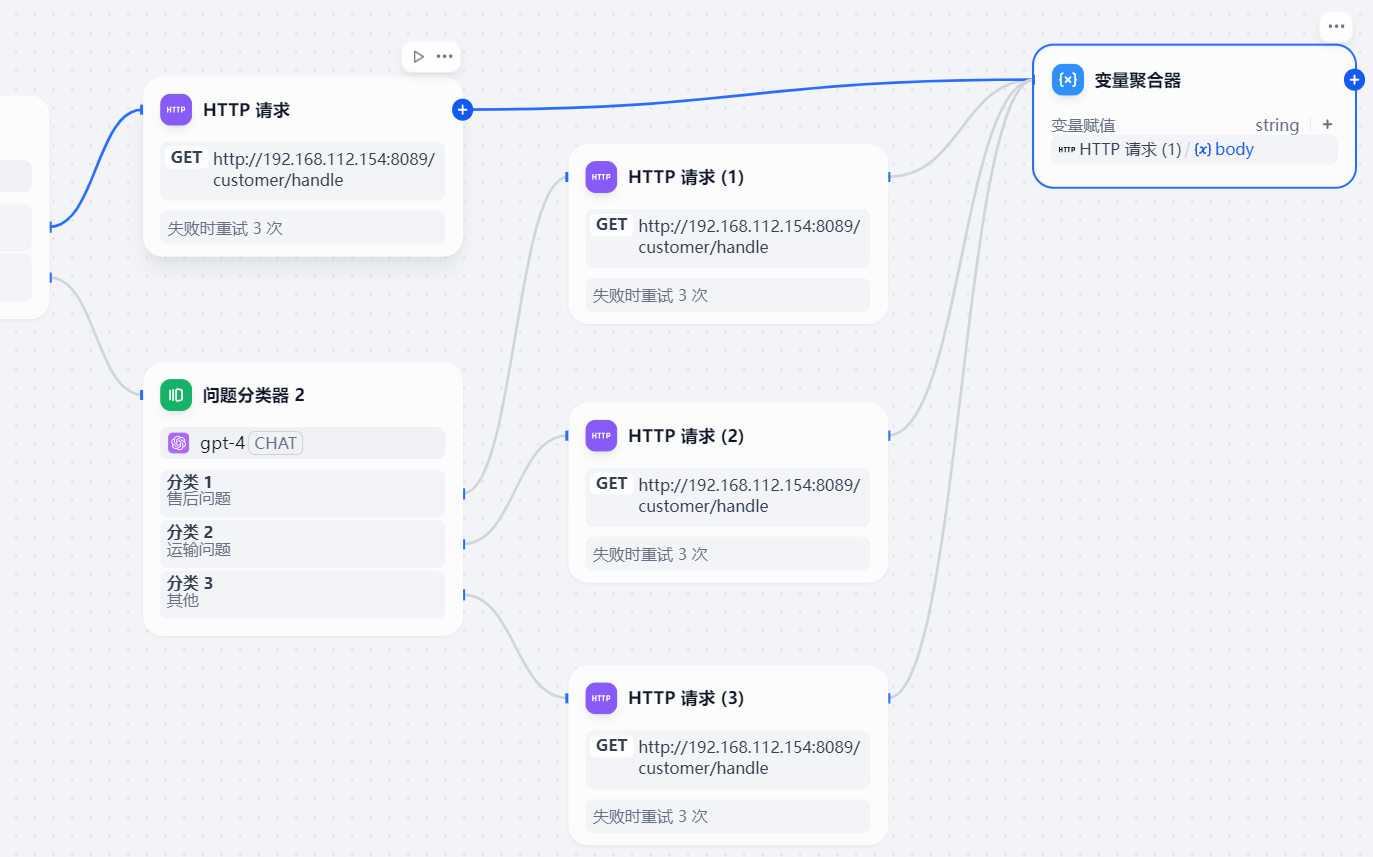
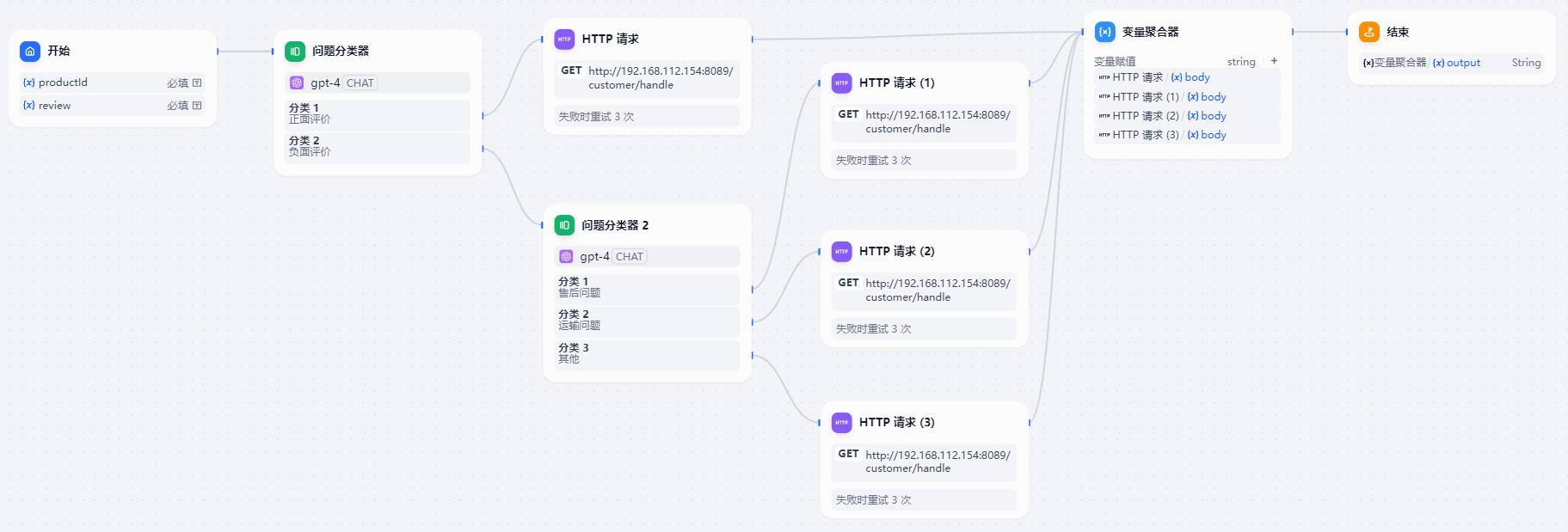
本小节的 客户评价处理工作流 包括 开始、结束、问题分类器、HTTP请求、变量聚合器 节点。
2、开始
每一个工作流都需要一个开始节点,你可以在开始节点中自定义启动工作流的输入变量。
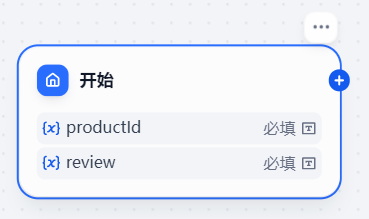
客户评价处理的工作流的开始节点定义了 productId(商品id)、review(客户评价)和默认的sys.user_id(客户id)输入变量。
默认有一个开始节点,右击空白处点击添加节点,可以看到dify有很多内置节点和工具可以添加
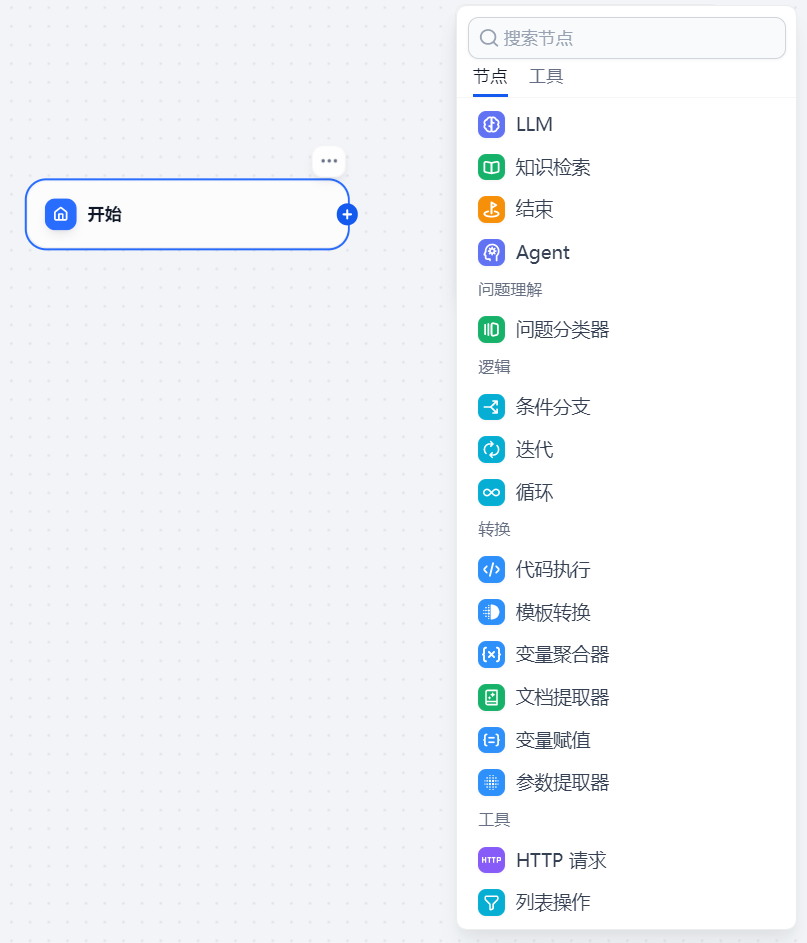
我们先添加一个结束节点,开始节点中有5个默认输入字段
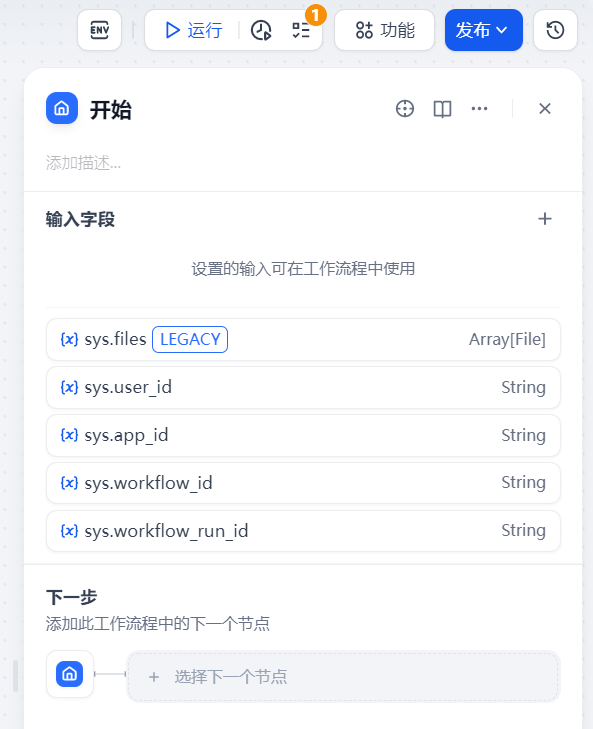
files表示用户上传的图片或文件,user_id代表这个会话的user_id,是dify默认的,我们暂时使用它默认的user_id
点击输入字段右侧的“+”号,我们输入两个新的字段
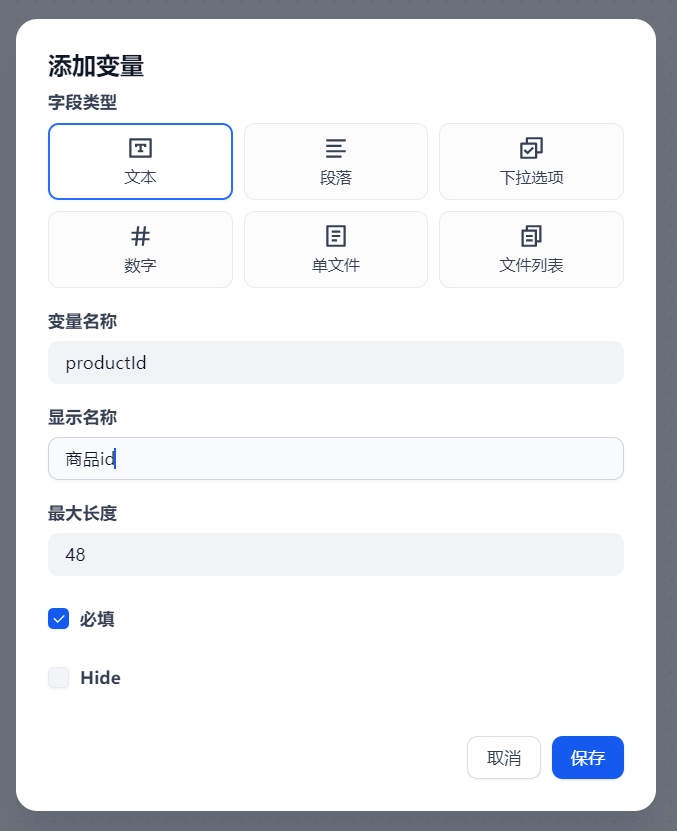
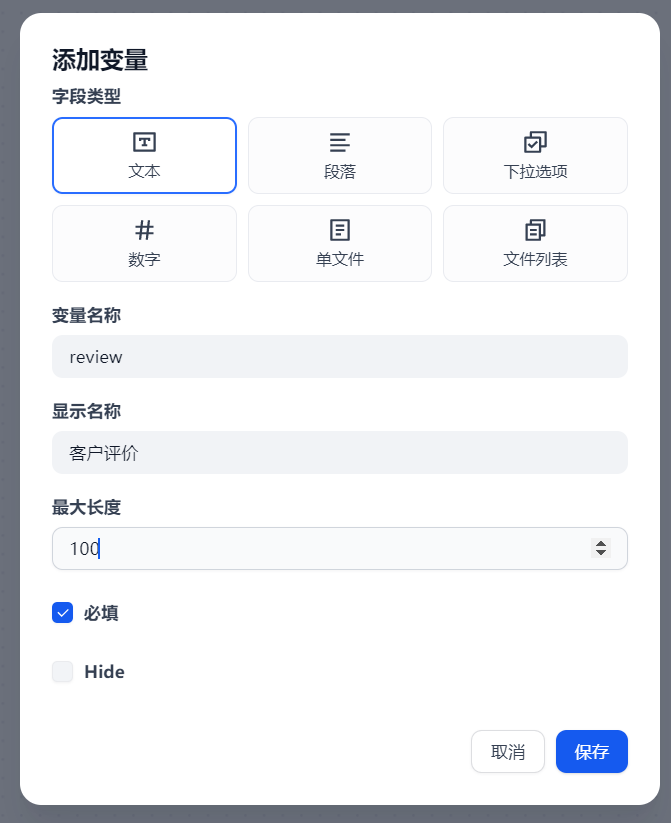
客户评价字段长度适当放大。
此时开始节点就新建完成了
3、问题分类器
通过定义分类描述,问题分类器能够根据用户输入推理与之相匹配的分类并输出分类结果。问题分类器其实就是依赖 LLM 大语言自身的能力对用户输入进行分类。
客户评价处理工作流中问题分类节点的作用是对用户输入的商品评价文本进行正面评价和负面评价分类,其中负面评价再分为售后问题、运输问题和其他问题。
输入变量是用户输入的客户评价文本,输出变量是设置的分类名称。
点击开始节点右侧的“+”,选择问题分类器节点,这样就把开始节点和问题分类器节点连接了起来。

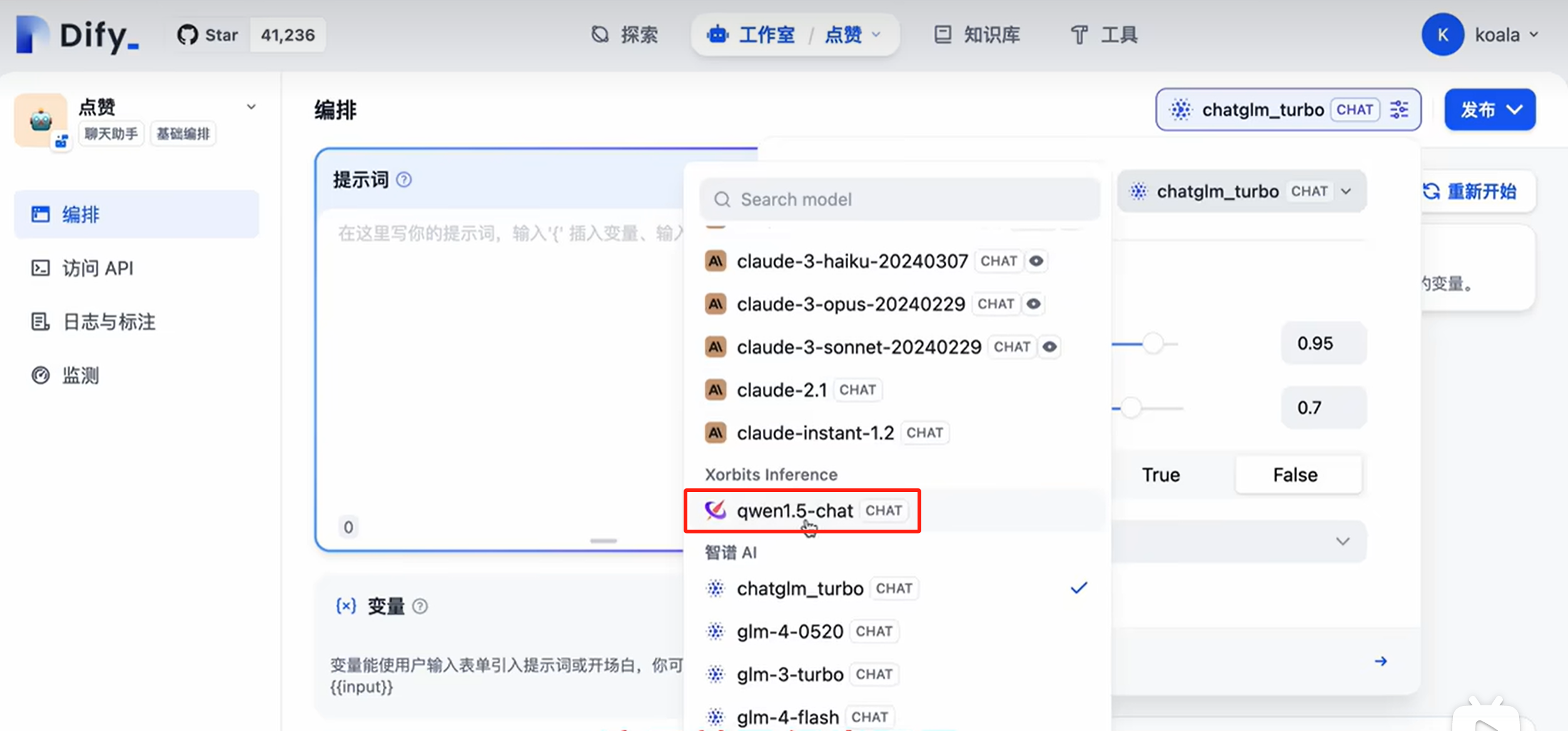
在问题分类器节点中,模型选择gpt-4,输入字段为客户评价,即review字段
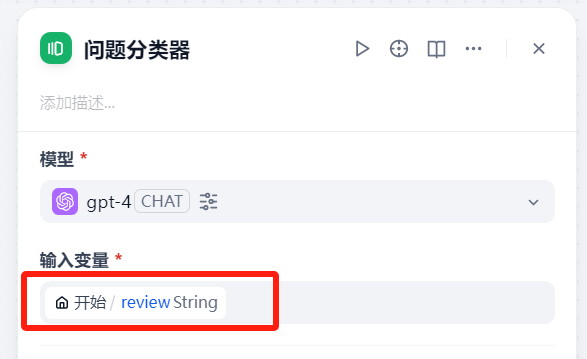
下一个节点的输入变量就是下一个节点的输出变量
分类分为正面评价和负面评价
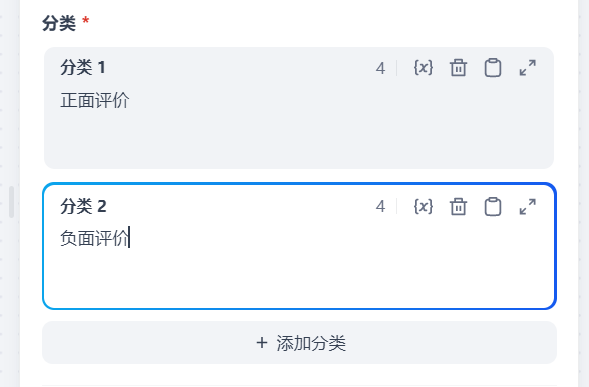
输出变量为分类名称

在负面评价这个分支上面再添加一个问题分类器,对负面评价再进行详细的分类
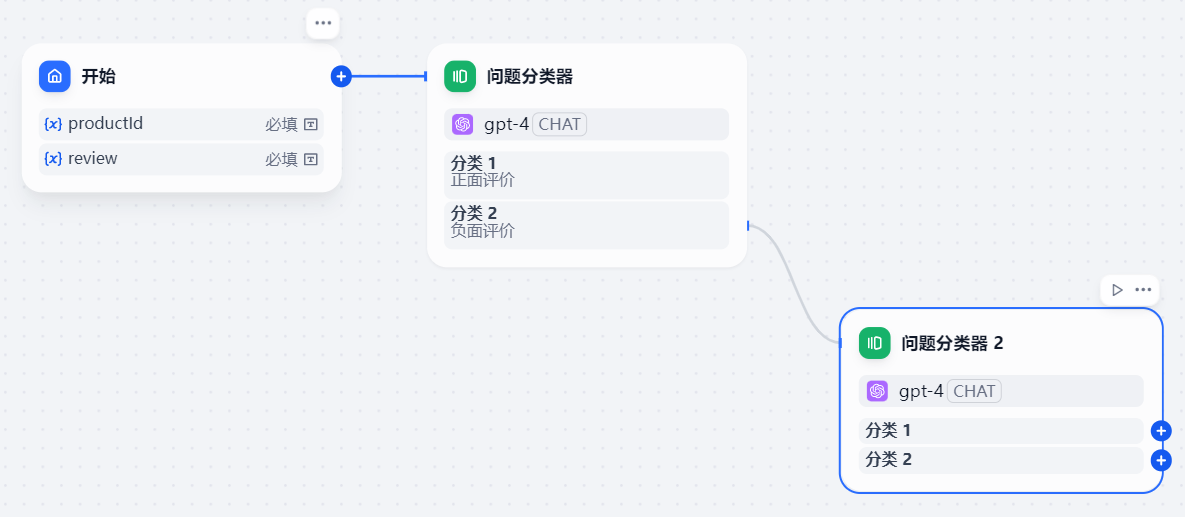
输入变量依然是review字段,模型为gpt-4
分类:售后问题、运输问题、其他
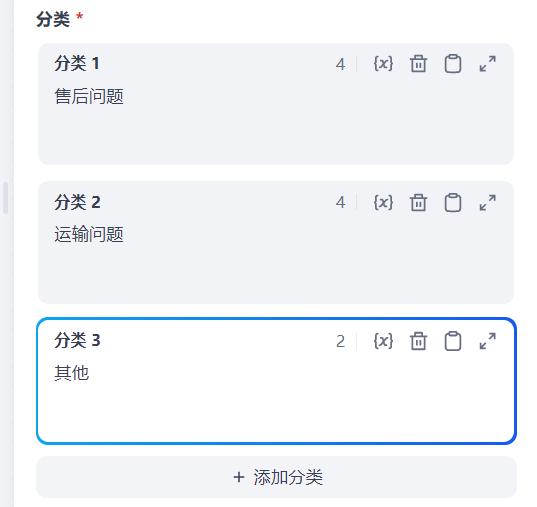
输出变量为分类名称
问题分类器的下一个节点就是http请求节点
4、http请求
作用:将分类器输出的客户评价和评价的类型提交给后台,
正面评价发送至公司品牌宣传部邮箱,商品问题发送至售后邮箱,运输问题发送至公司运输部邮箱,其他问题发送至默认的客户支持邮箱。
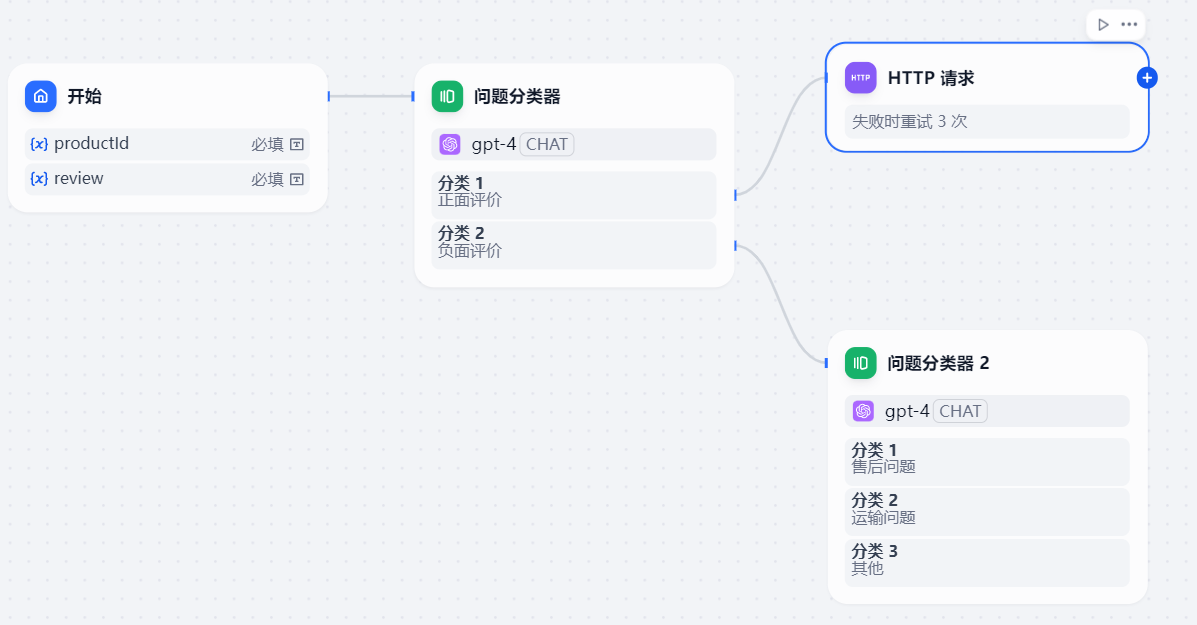
HTTP请求节点 可以支持 GET,POST,HEAD,PATCH,PUT ,DELETE 请求方法。
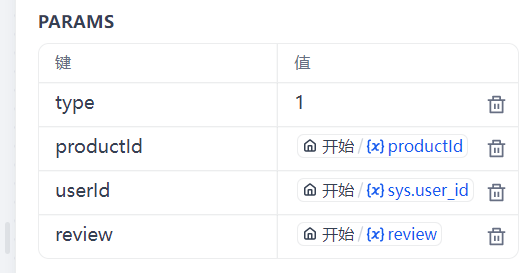
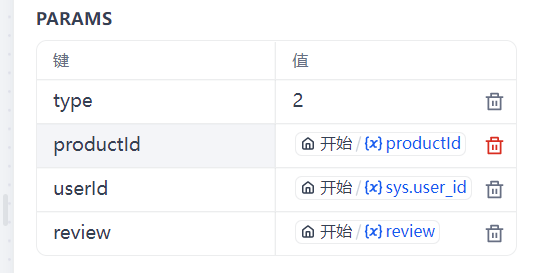
这里设置了 productId(商品id)、review(客户评价)和默认的 sys.user_id(客户id)、 type(问题类型)。
。type=1正而评价 。type=2 售后问题 。type=3 运输问题 。type=其他 其他问题
4种问题对应4个 HTTP请求节点 中的 type 变量。
正面评价的参数定义
请求地址:
http请求可以复制
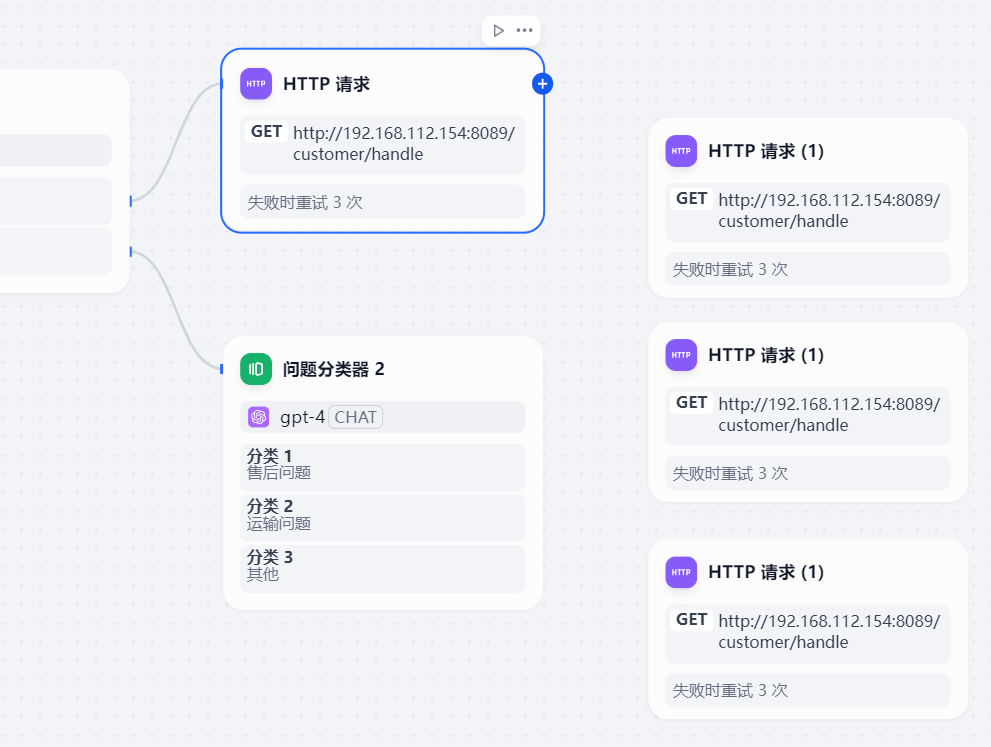
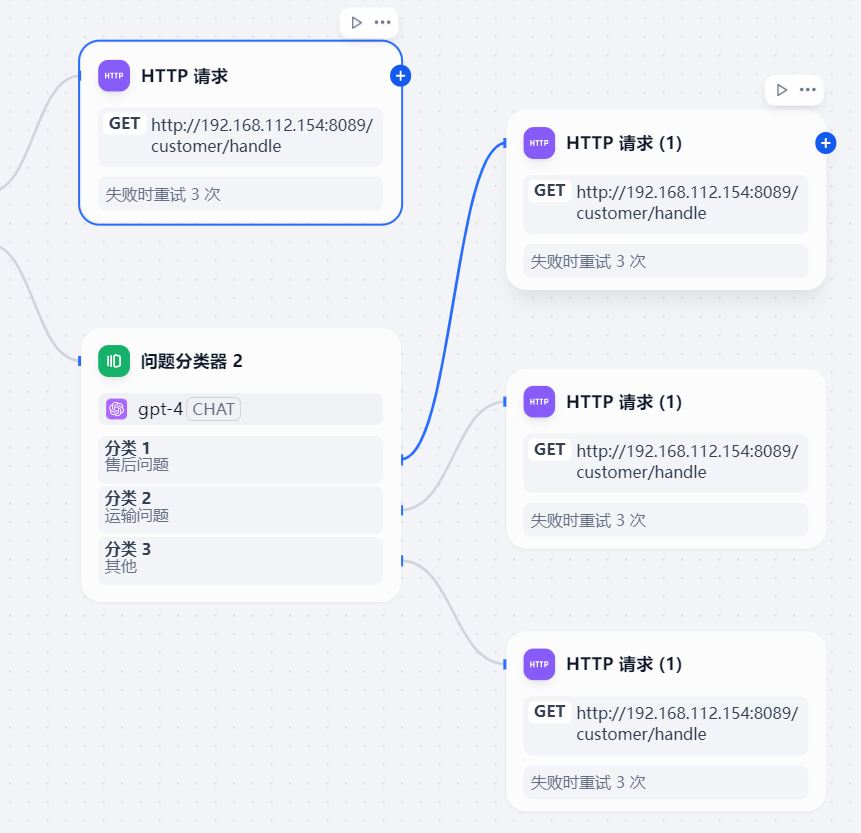
然后与上一个节点进行连接
修改参数:售后问题的type值为2,运输问题为3,其他问题为4
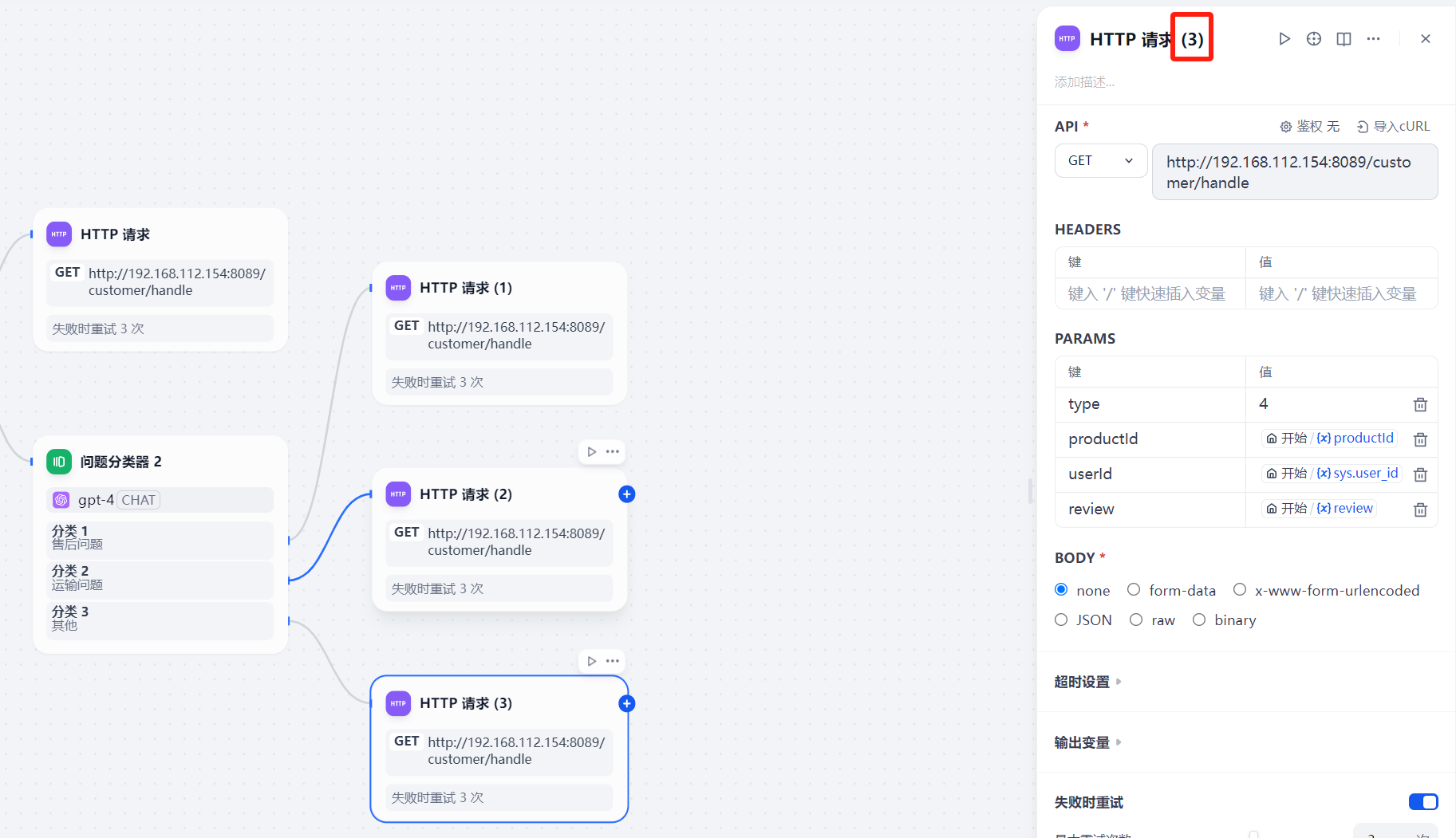
修改http请求节点的名称
5、变量聚合器
http请求节点的下一个节点是变量聚合器
将多路分支的变量聚合为一个变量,以实现下游节点统一配置。
客户评价处理的工作流中4个 HTTP 请求节点输出的变量(即 Java SpringBoot 接口返回值)聚合成一个变量在结束节点中输出。
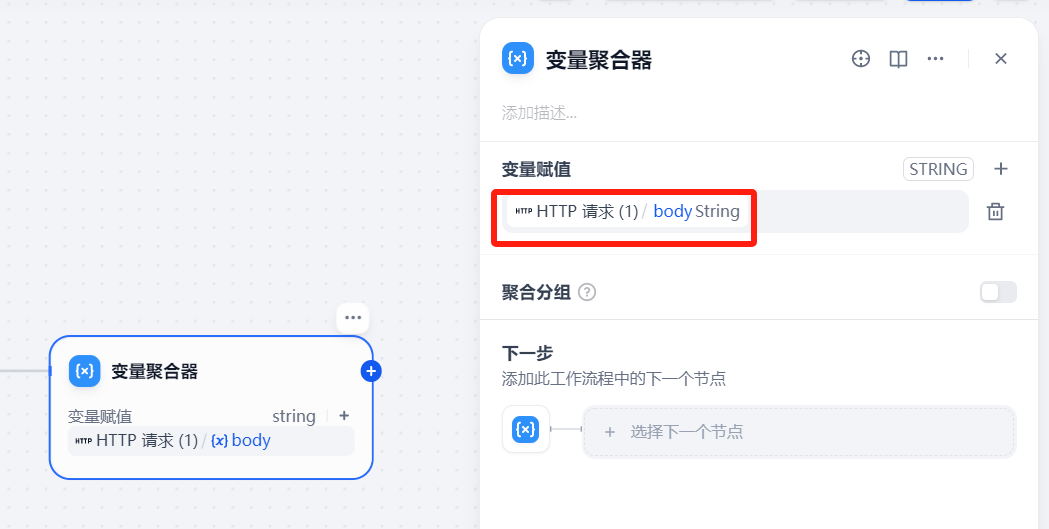
变量赋值为body
将http请求节点全部与聚合器节点连接
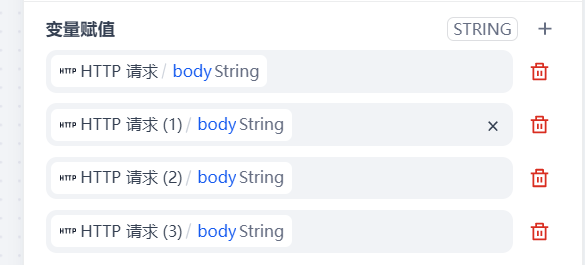
在变量聚合器中把4个http请求的返回值body加入到变量赋值中
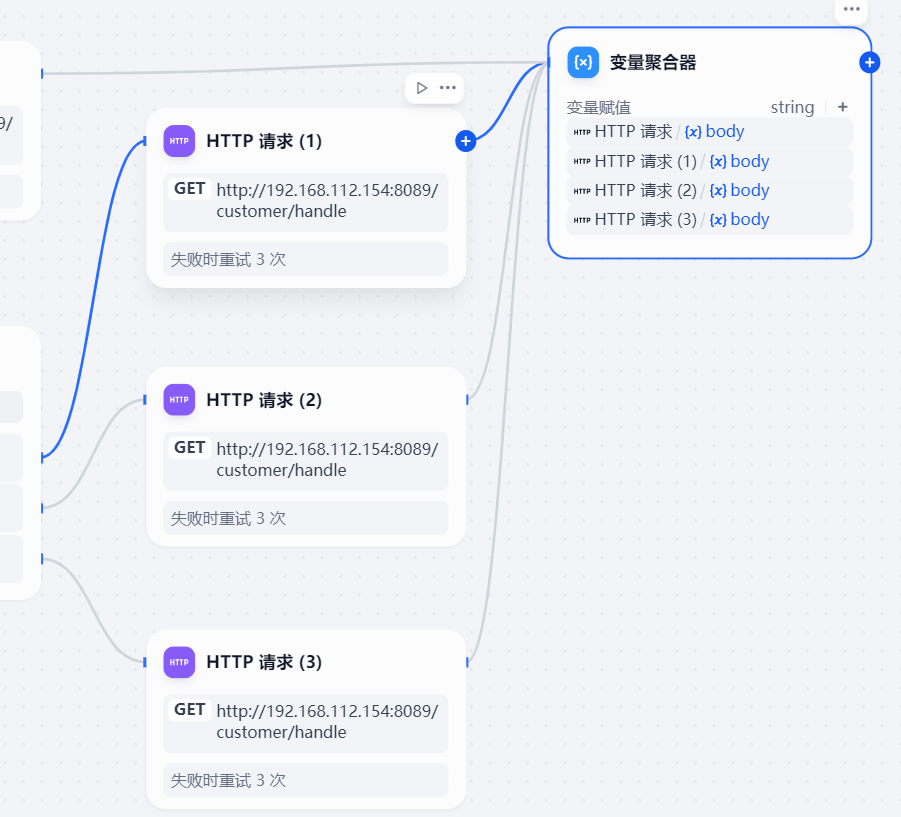
这样4个http请求中的输出变量body全部聚合到了变量聚合器中的一个变量body
3、结束
工作流可以有多个结束节点,至少有一个结束节点。
定义一个工作流程结束的最终输出内容。每一个工作流在完整执行后都需要至少一个结束节点,用于输出完整执行的最终结果。
结束节点为流程终止节点,后面无法再添加其他节点,工作流应用中只有运行到结束节点才会输出执行结果。若流程中出现条件分叉,则需要定义多个结束节点。
结束节点直接输出变量聚合节点输出的变量。
添加结束节点

在结束节点中添加输出变量,就是变量聚合器中的输出参数output
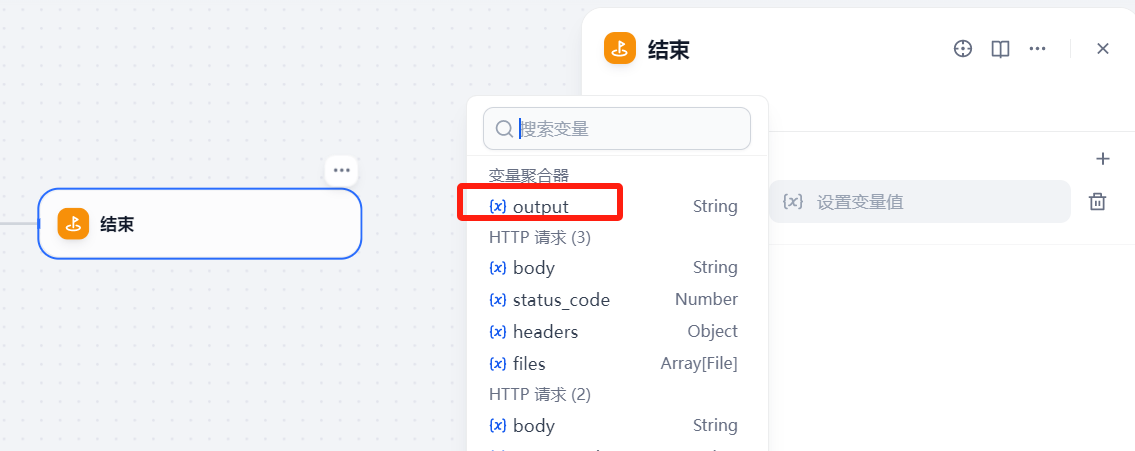
这样一个完整的工作流就完成了
点击发布----发布更新
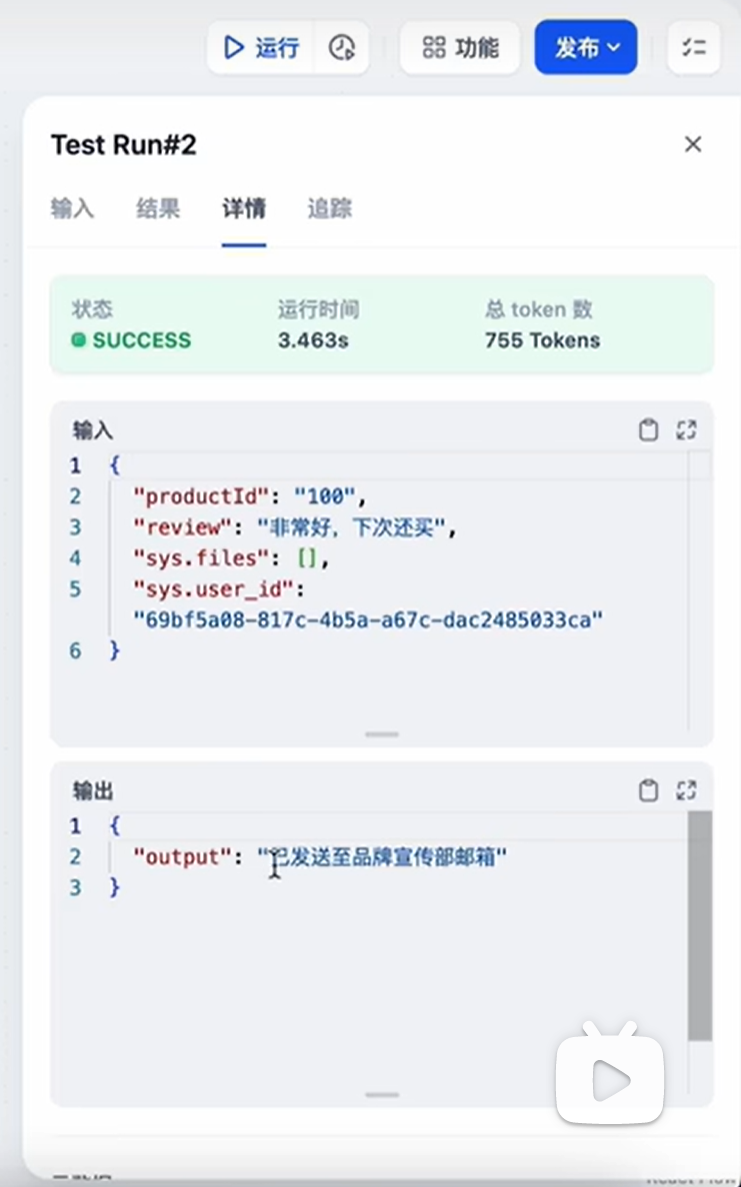
点击运行

点击开始运行。结果如下:
七、大模型本地部署
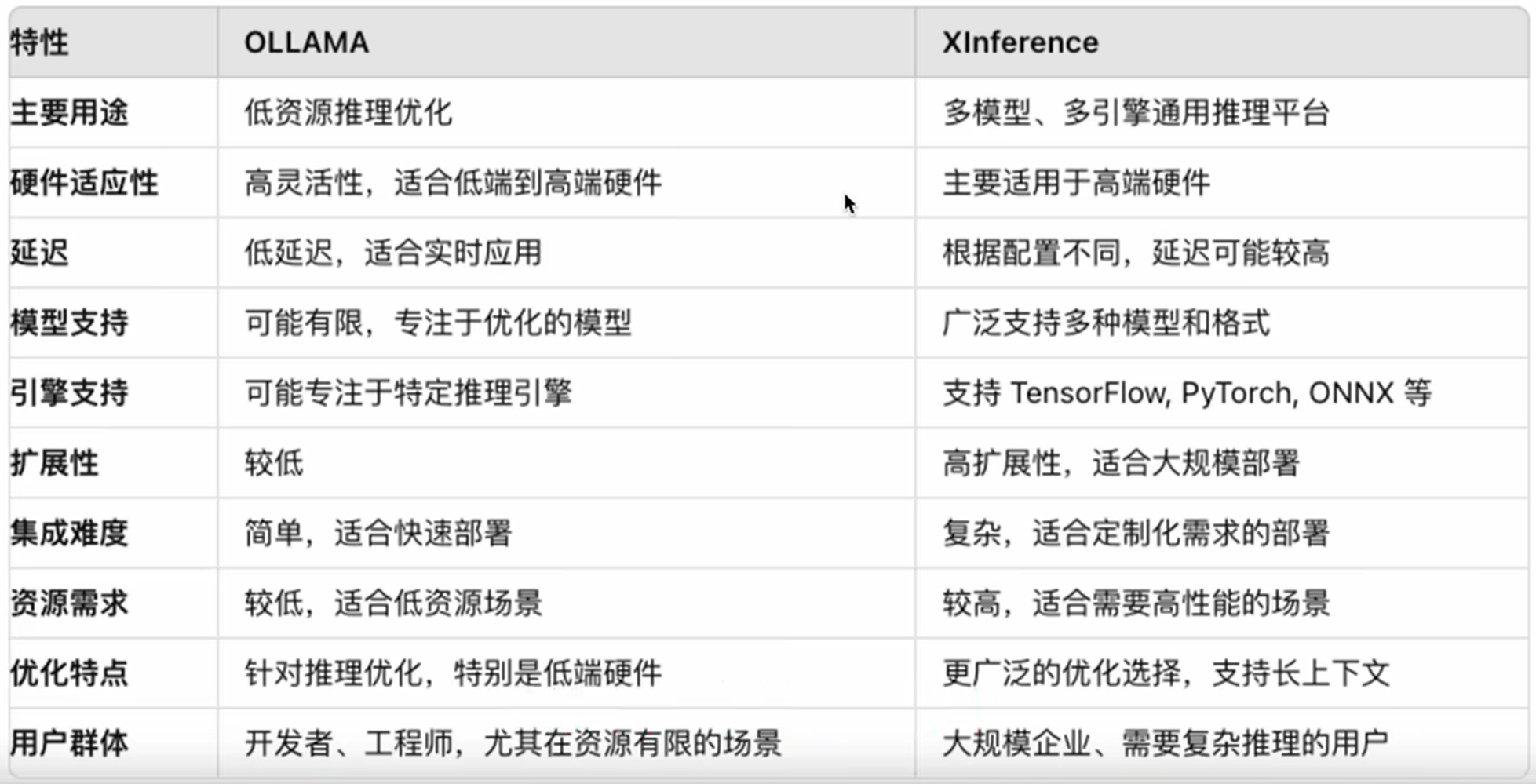
本地部署平台比较
Ollama vs Xinference
1、Xinference部署大模型
部署环境
我在 MacBook Air M2 上使用 Xinference 部署大模型。 Mac 是内存显存共用的
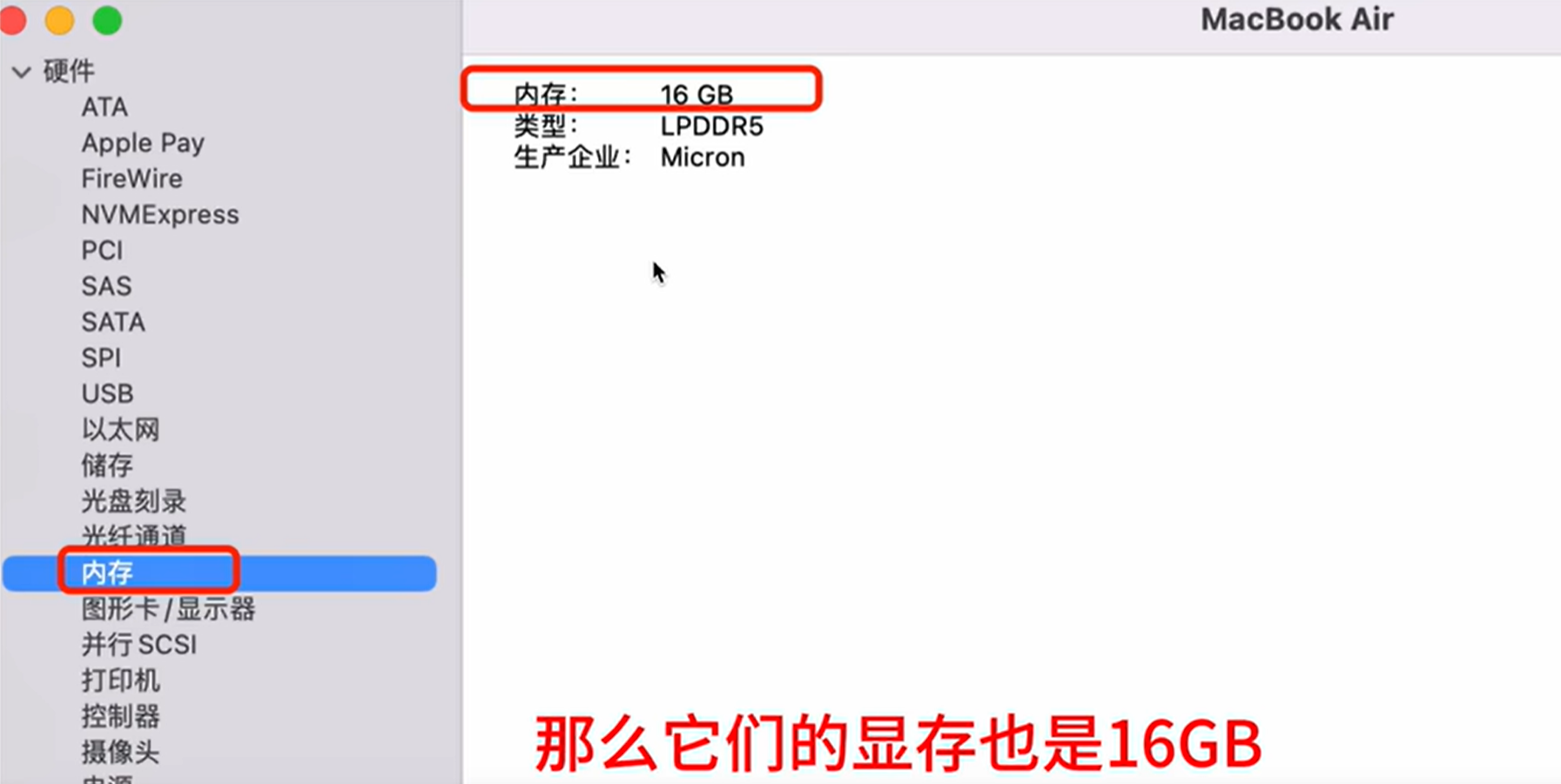
我们可以在 MacBook Air 上运行一些量化后的大模型。
什么是量化后的大模型:
量化后的大模型是指在模型压缩和优化过程中,将深度学习模型的权重和激活值从原始的高精度(通常是32位浮点数,即 FP32)降低到较低精度(如8位整数、4位整数等)的过程。量化的目的是减少模型的内存占用和计算复杂度,从而加快推理速度并降低硬件要求,尤其是在资源受限的环境中。
python环境
管理多个python虚拟环境用conda
conda env list conda create-n xinfefence python=3.11.7 conda activate xinference conda env list
安装Xinference
mac安装Xinference的先决条件
conda install-c conda-forge pynini=2.1.5
安装xinference
//安装Xinference pip install "xinference[all]" -i https:/pypi.mirrors.ustc.edu.cn/simple/
可能的报错:Field name "schema" shadows a BaseModel attribute
解决:pip install openai==1.39.0
安装成功后,使用以下命令查看 xinference 的安装路径
pip show xinference
启动xinference
xinference-local --host 0.0.0.0 --port 9997
启动成功后,可以通过访问 http://127.00.1:9997/ui 来使用UI,访问 http://127.0.0.1:9997/docs来查看 API 文档。
部署大模型
参数解释 128K
查询与`qwen1.5-chat` 模型相关的参数组合,以决定它能够怎样跑在各种推理引擎上。
xinference engine -e http://127.0.0.1:9997 --model-name qwen1.5-chat
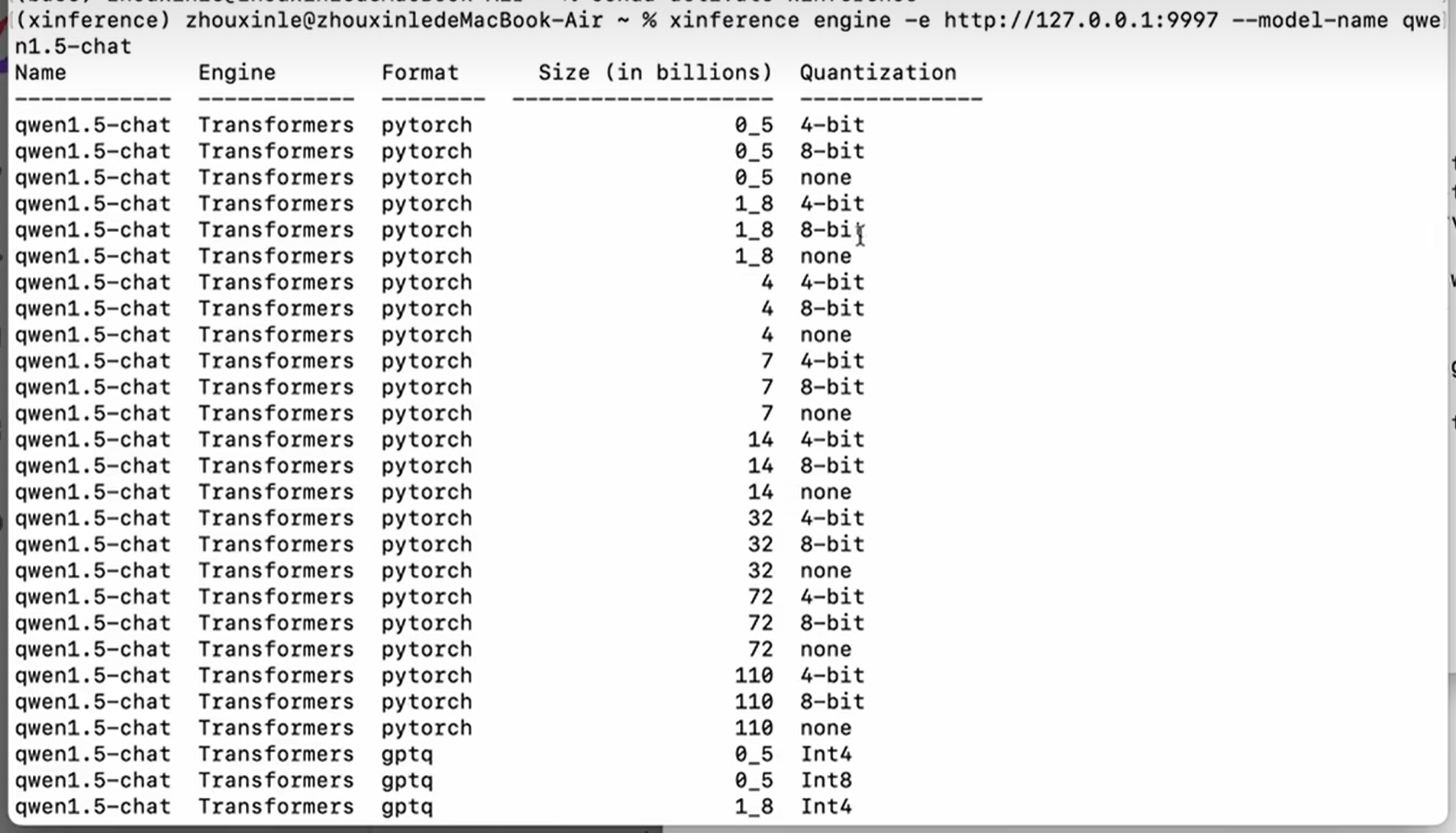
quantization表示量化方法,量化到什么精度上面。none表示没有经过量化
format表示模型文件的保存格式,
size表示模型的参数数量,以十亿为单位。1_8表示1.8
点击运行
此时Running Models中就显出了正在运行的大模型
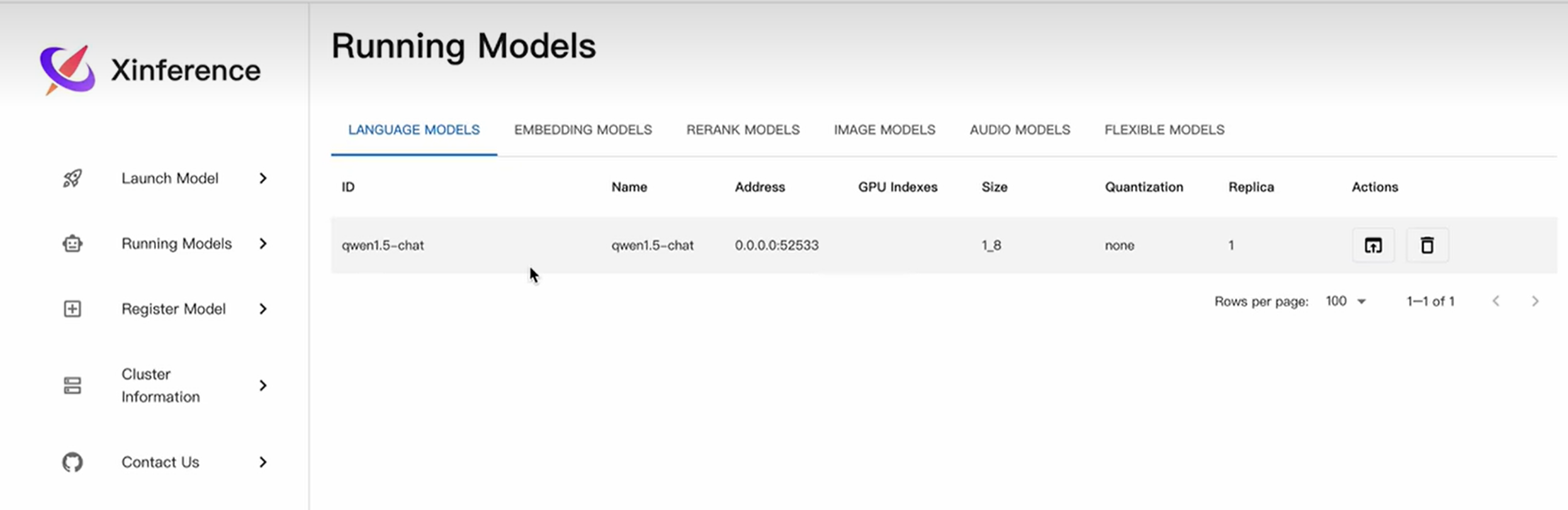
这个模型上下文的长度是32K,
上下文 128k,上下文通常指的是模型在处理输入时所能支持的最大令牌(token)数量为128,000个。这个k指的是 千(1,000)。
模型能够处理的上下文长度越长,代表这个模型的能力越强
点击actions下面的箭头,进入聊天界面
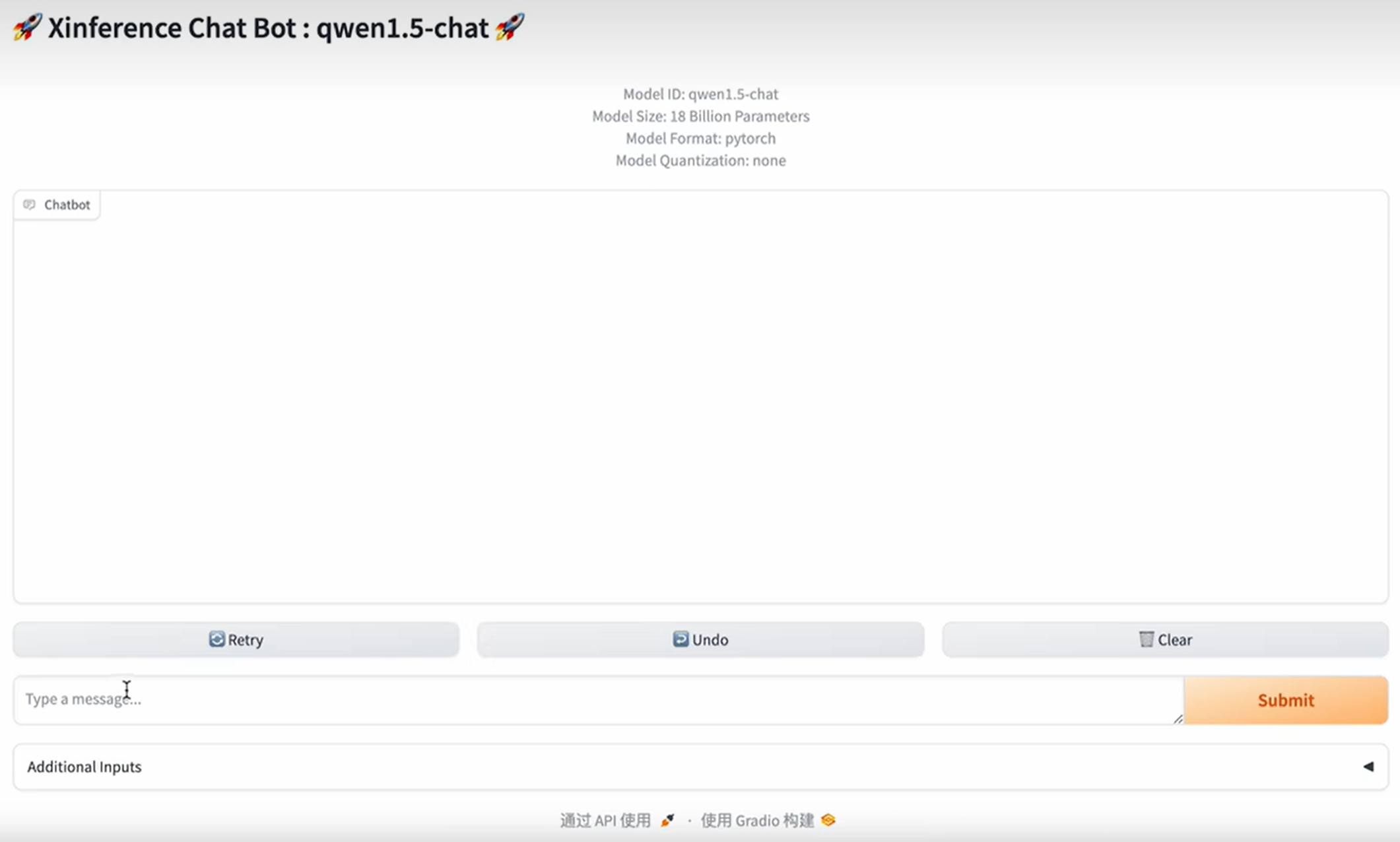
第一次提交速度会比较慢
除了使用xinference自带的交互界面与大模型进行交互,还可以使用API的方式和大模型进行沟通,

结果如下:

在Dify中配置本地大模型
找到模型供应商Xorbits inference
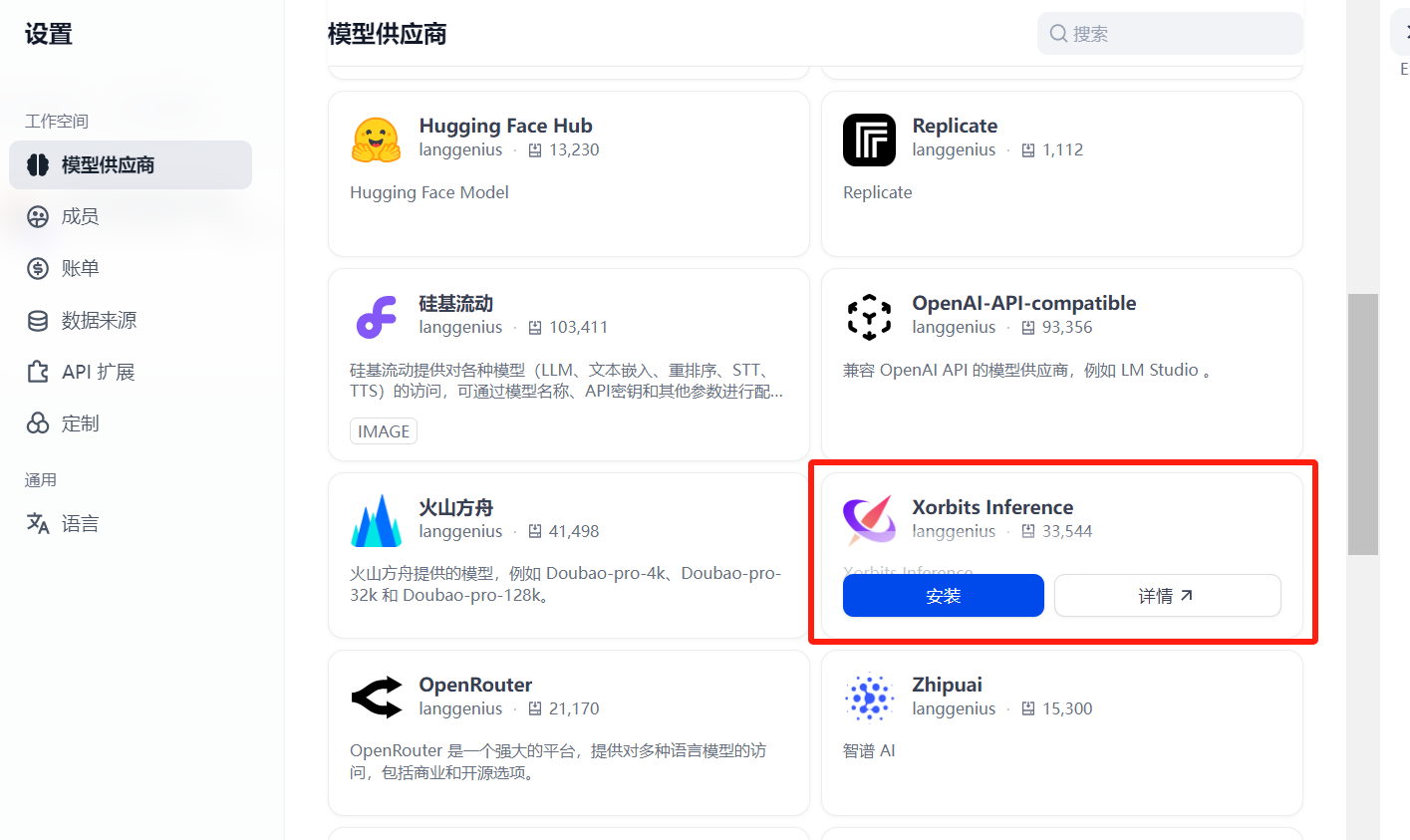
点击安装
安装好后点击添加模型
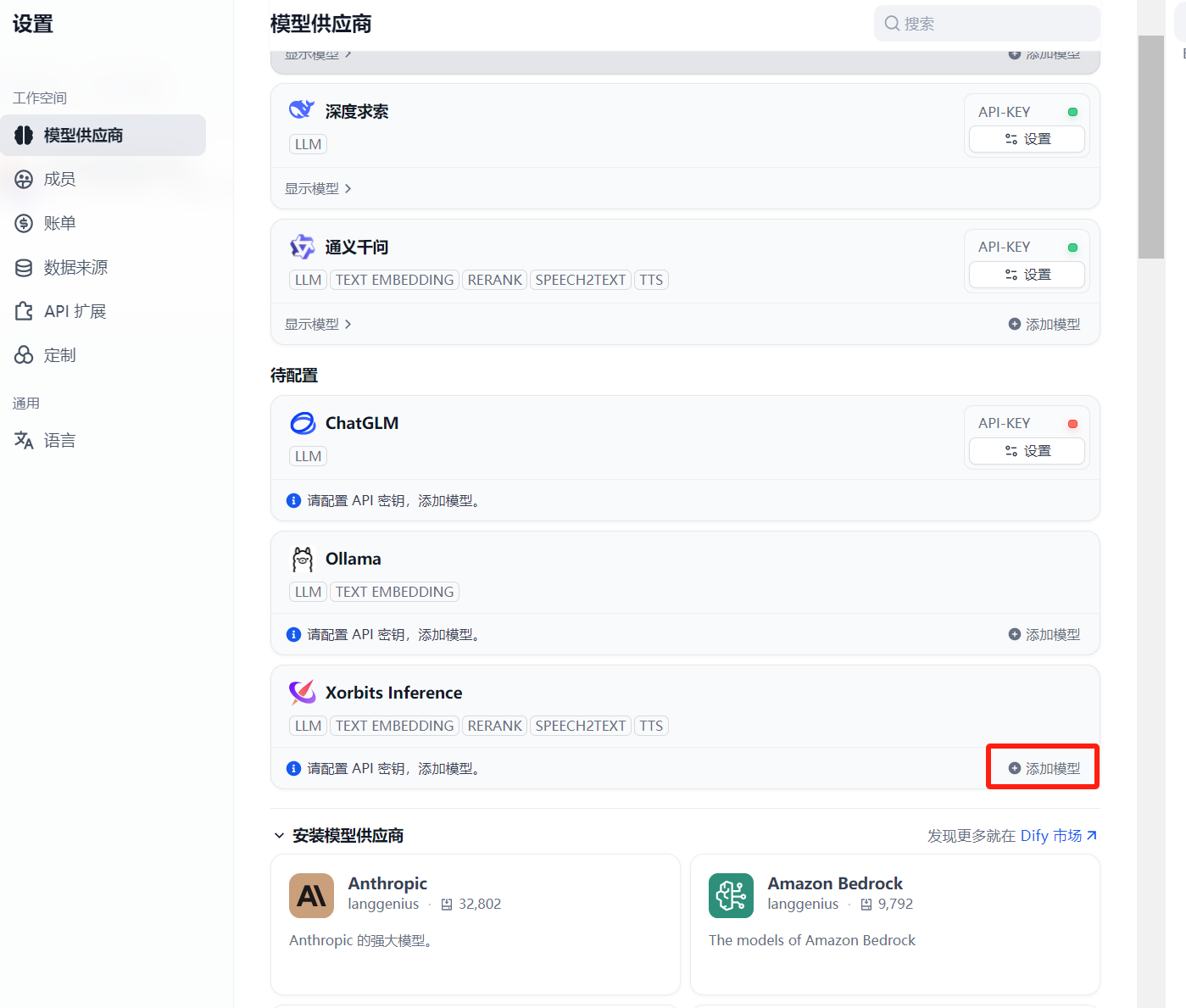
弹出如下界面:
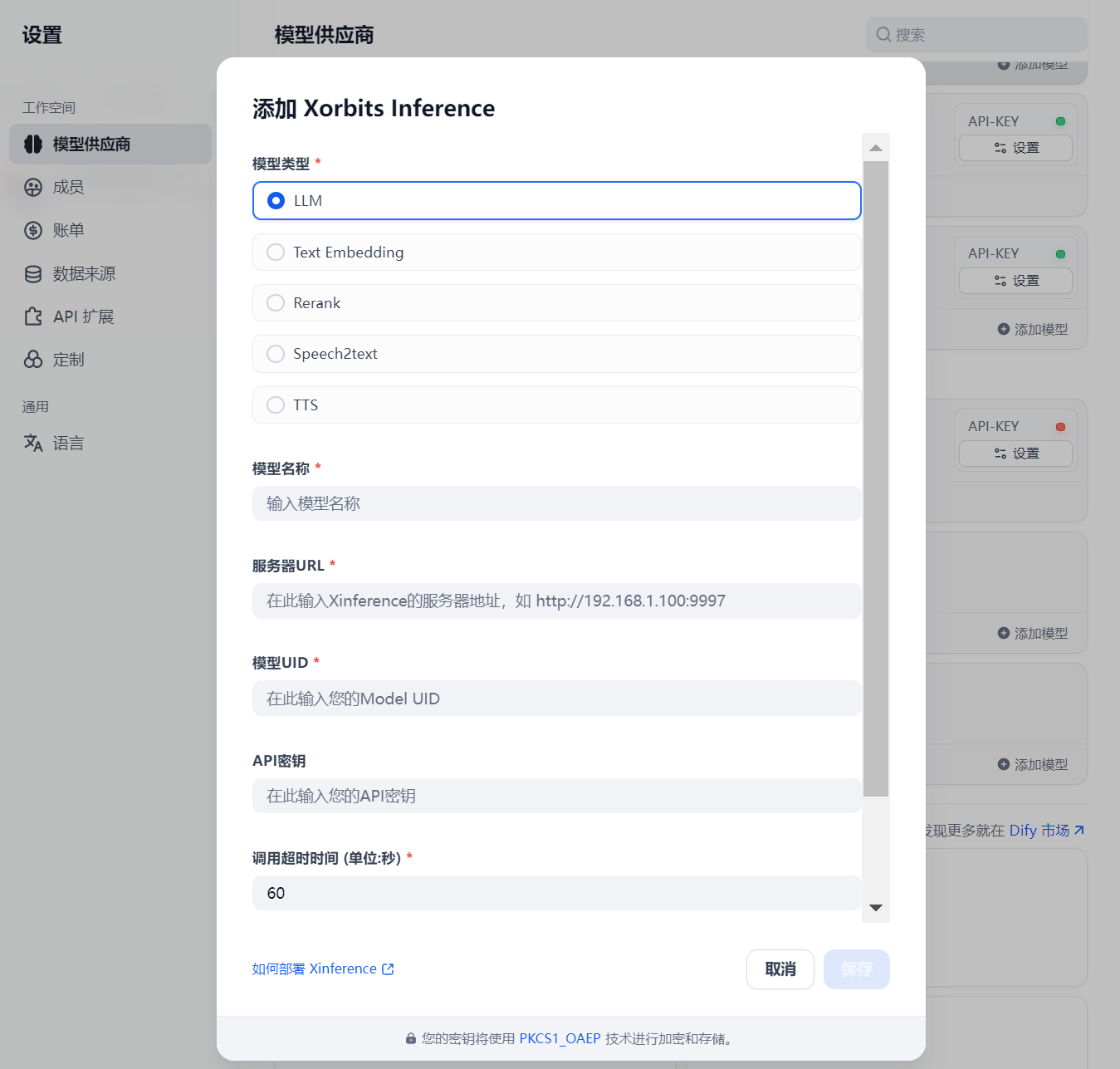
模型名称与xinference中的保持一直即可
模型UID与模型名称相同即可
服务器URL:由于dify是部署在docker当中的,所以不能用127.0.0.1,而应该使用局域网的IP,即http://192.168.3.23:9997
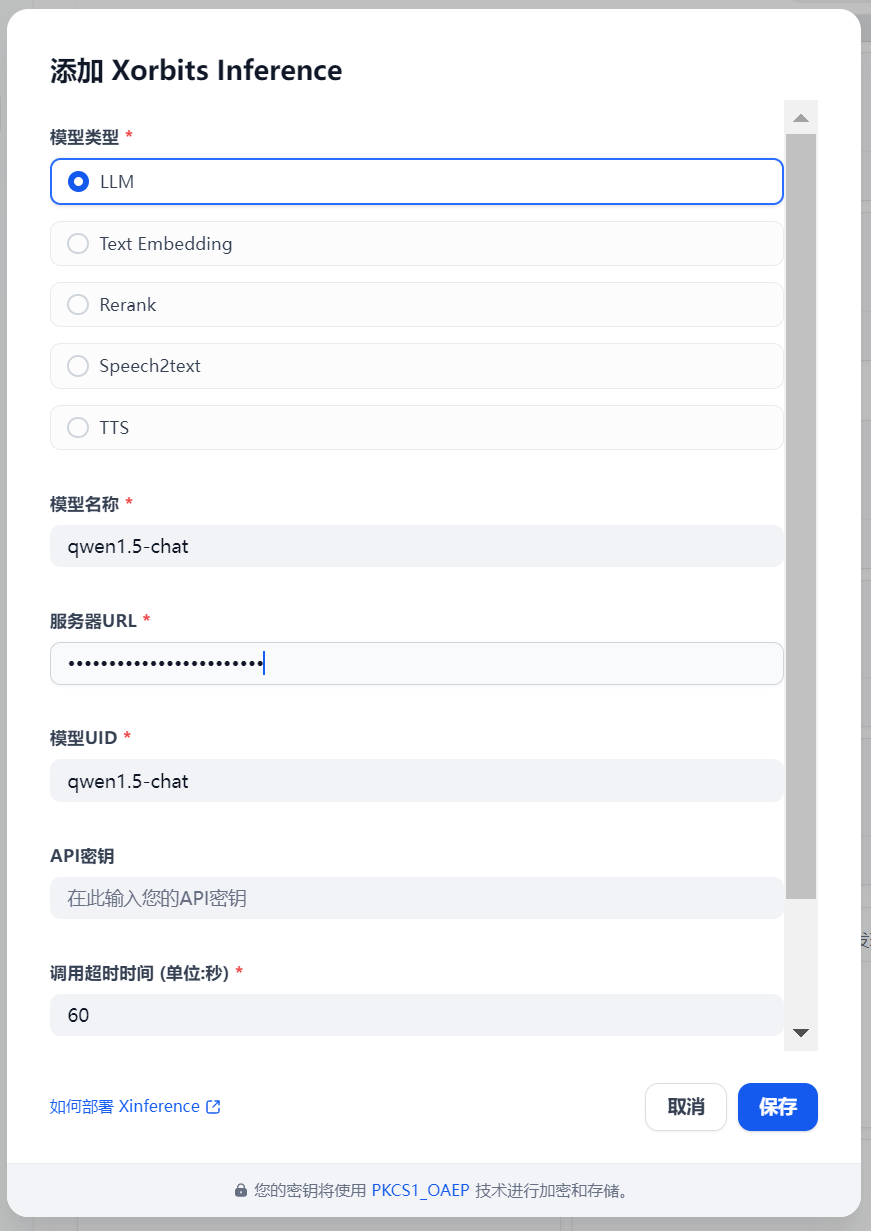
然后点击保存
这样模型列表中就有了xinference
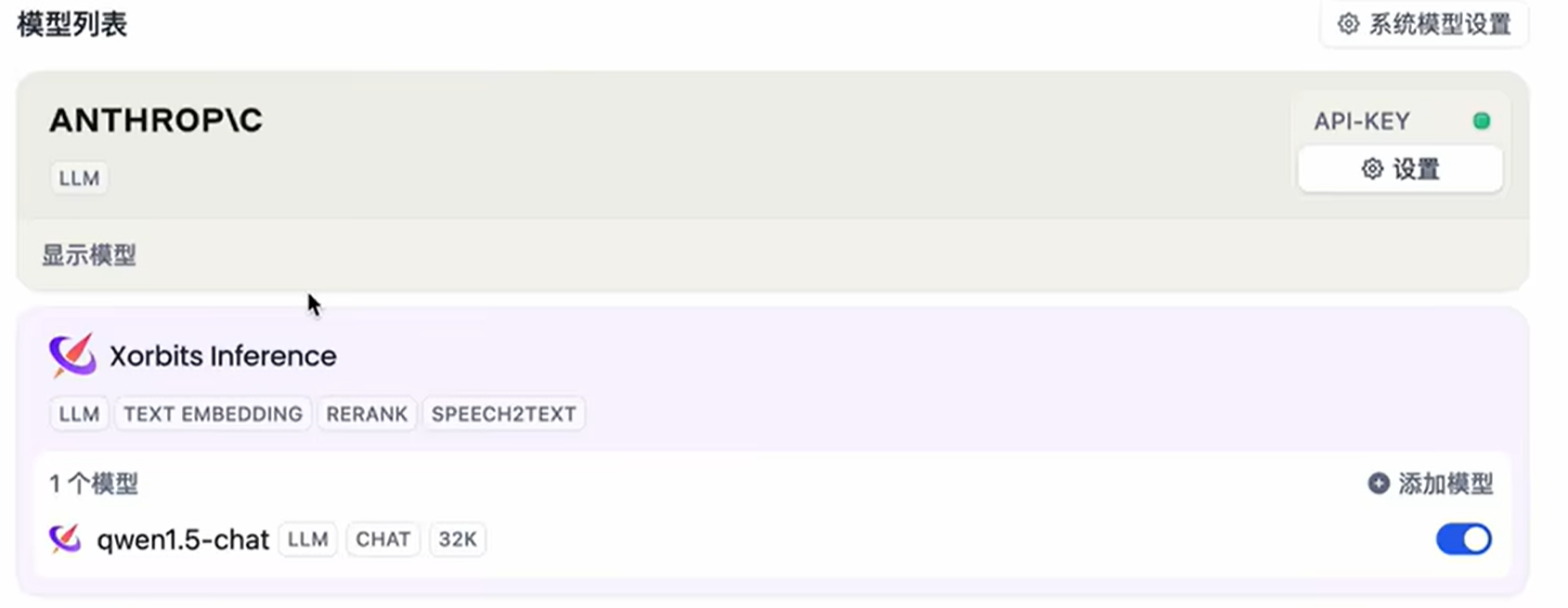
使用本地模型
八、基于API调用DIFY应用
Dify 基于“后端即服务“理念为所有应用提供了 API,为 AI 应用开发者带来了诸多便利。通过这一理念,开发者可以直接在前端应用中获取大型语言模型的强大能力,而无需关注复杂的后端架构和部署过程。
使用 Dify AP 的好处
(1)、让前端应用直接安全地调用 LLM 能力,省去后端服务的开发过程
(2)、在可视化的界面中设计应用,并在所有客户端中实时生效
(3)、对 LLM 供应商的基础能力进行了良好封装
(4)、随时切换 LLM 供应商,并对LLM的密钥进行集中管理
每一个大模型, GPT-4,claude3.5 都提供了 API ,开发者可以轻松地使用这些 API 来构建自己的应用。但如果你需要 更换大模型,可能就需要更改代码,这会增加开发成本。
(5)、在可视化的界面中运营你的应用,例如分析日志、标注及观察用户活跃
(6)、持续为应用提供更多工具能力、插件能力和数据集
下面我们构建一个简单的聊天应用,然后用DIFY API调用这个应用.
新建一个基于工作流的聊天应用

点击创建,效果如下:

点击预览,就可以和聊天机器人对话了
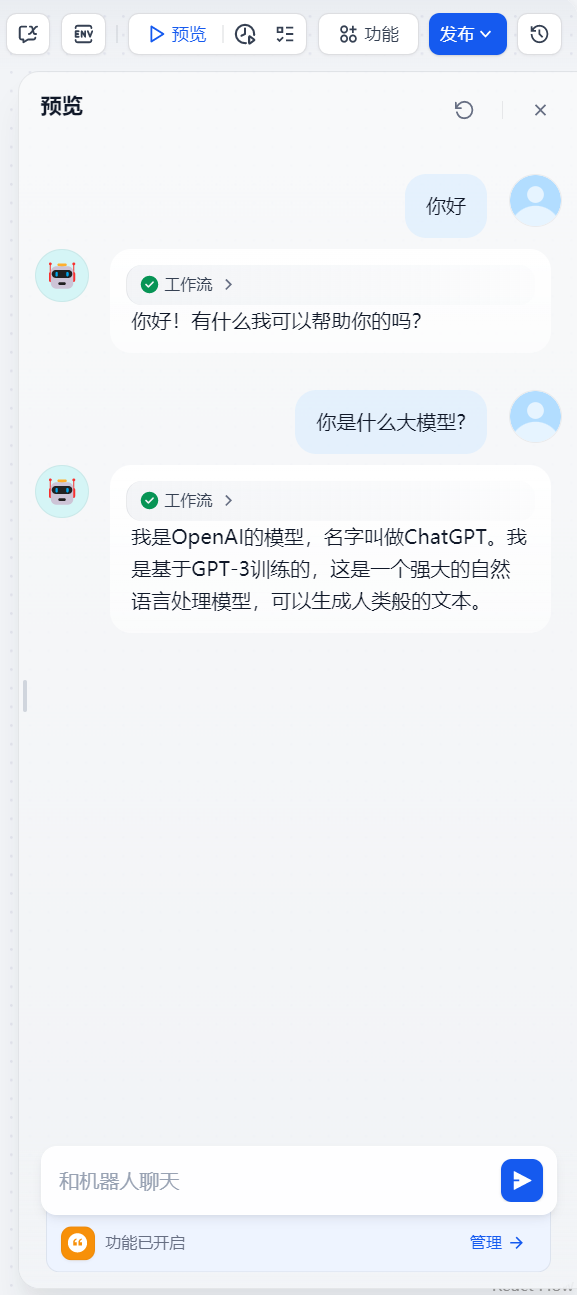
这样聊天应用就通过了调试,接下来开始发布
目前还不能上传文件,我们先打开上传文件的功能,点击右上角的功能按钮,在弹出的弹框中打开文件上传的功能
点击设置
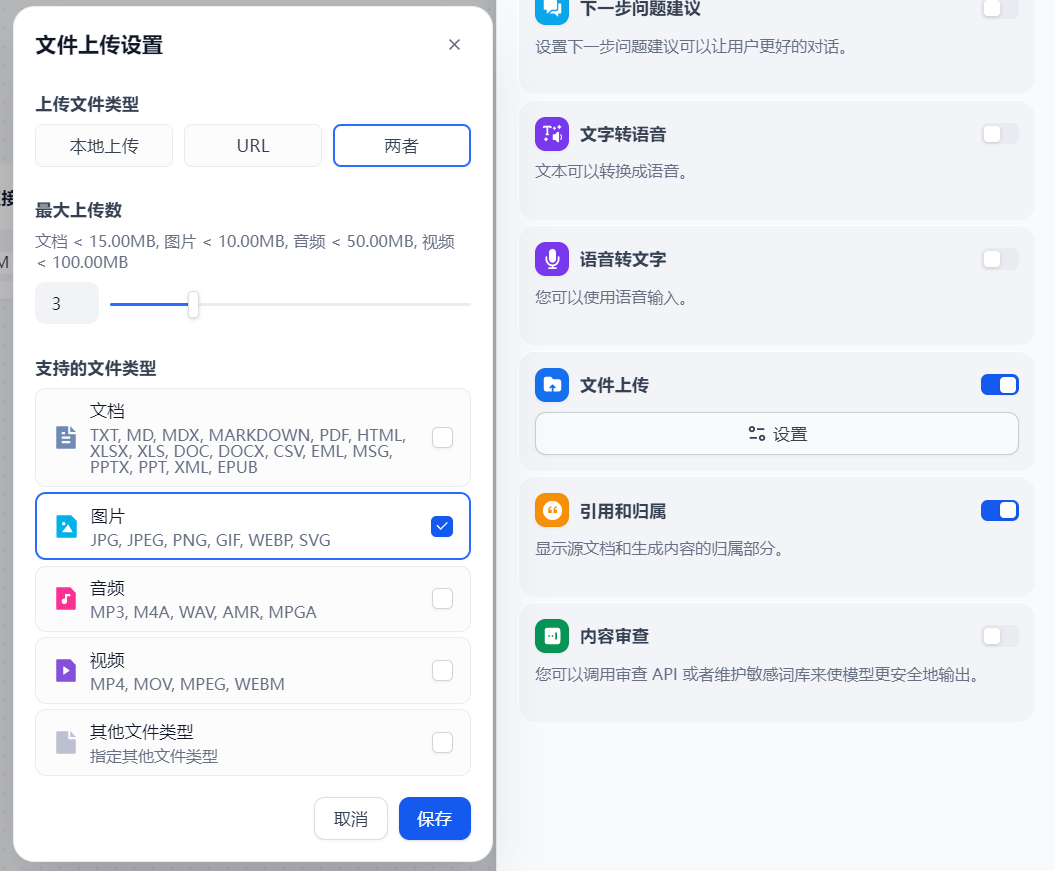
即默认只上传图片。
此时效果如下:
要想解读图片,大模型必须支持视觉功能,即要有VISION标志
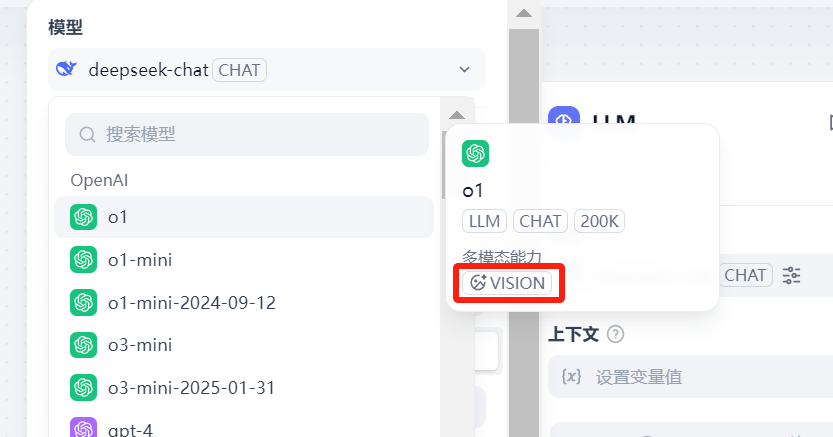
如果没有VISION标志,则是一个大预言模型,只能进行文本的处理,不能进行图片的视觉处理。
gpt-3.5主要处理文本,gpt-4o不经能理解文字,而且还能理解图片、音频、视频这样的多模态。
点击发布----发布更新,状态就变成已发布
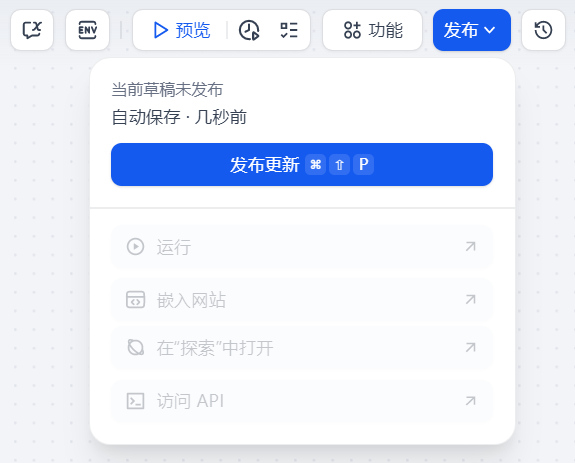
发布的方式DIFY提供了四种:
(1)、运行,点击运行,进入如下界面:
根据地址栏的地址https://udify.app/chat/4VmgIv5LA9lHn4qu,你可以访问。
聊天页面时dify定义好的
(2)、嵌入网站
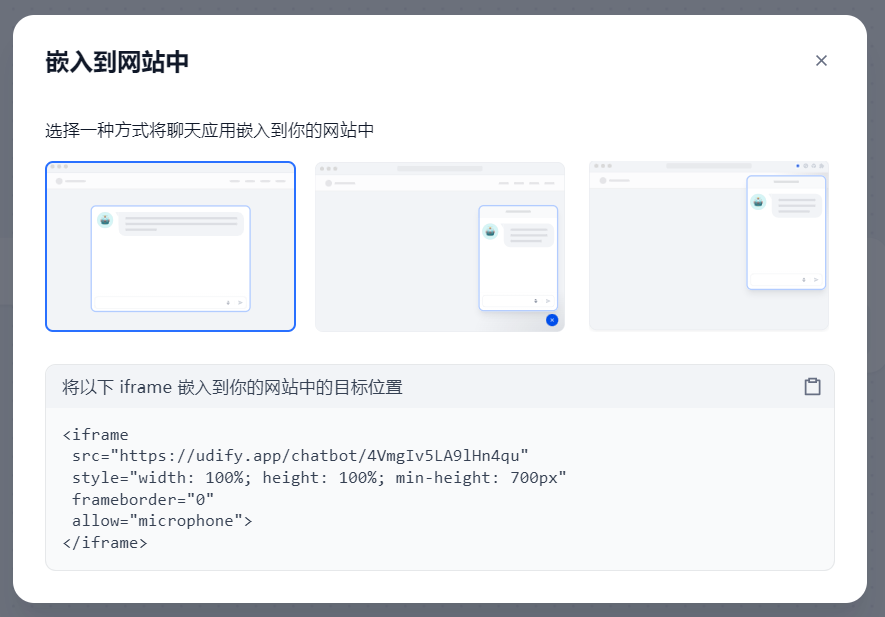
第一种为iframe嵌入,
第二种是script标签嵌入,第三种是安装dify chrome浏览器的扩展,即在chrome浏览器中使用聊天窗口
聊天页面时dify定义好的
(3)、在探索中打开
(4)、访问API
直接运行和嵌入网站的方式,前端的聊天页面都是dify定义好的,如果想要开发自己的聊天界面,我们就可以调用dify应用的api,去构建自己的AI应用。这就是为什么要提供API访问的方式。
点击访问API,进入如下界面:
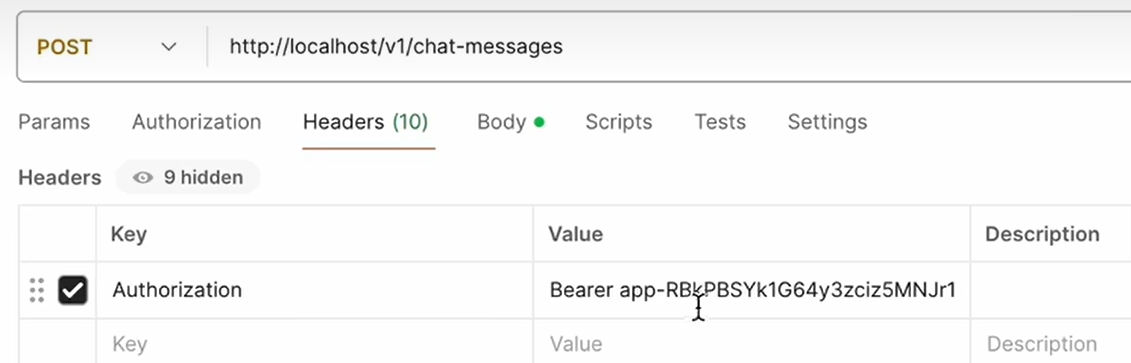
建议把api_key放到后端,即在后端调用dify的API。
下面在postman中调用API
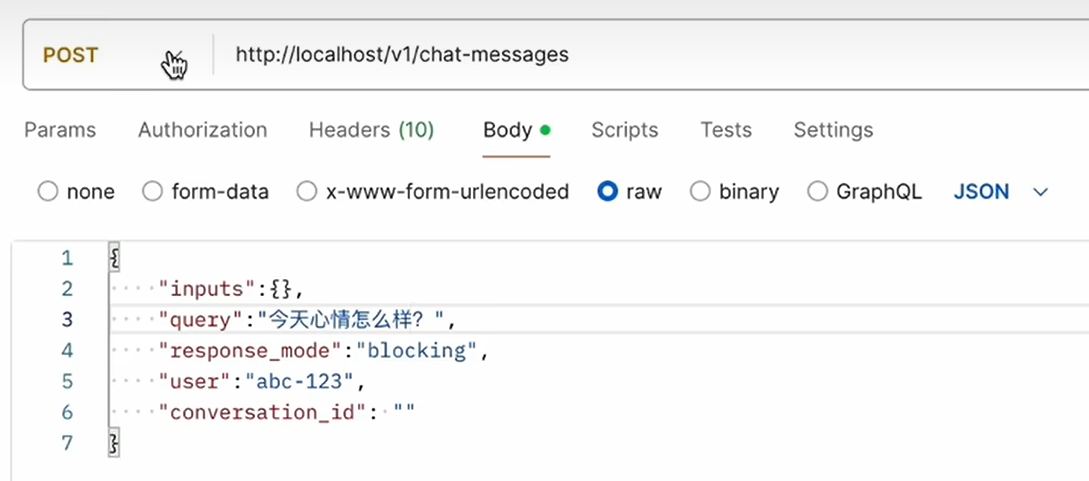
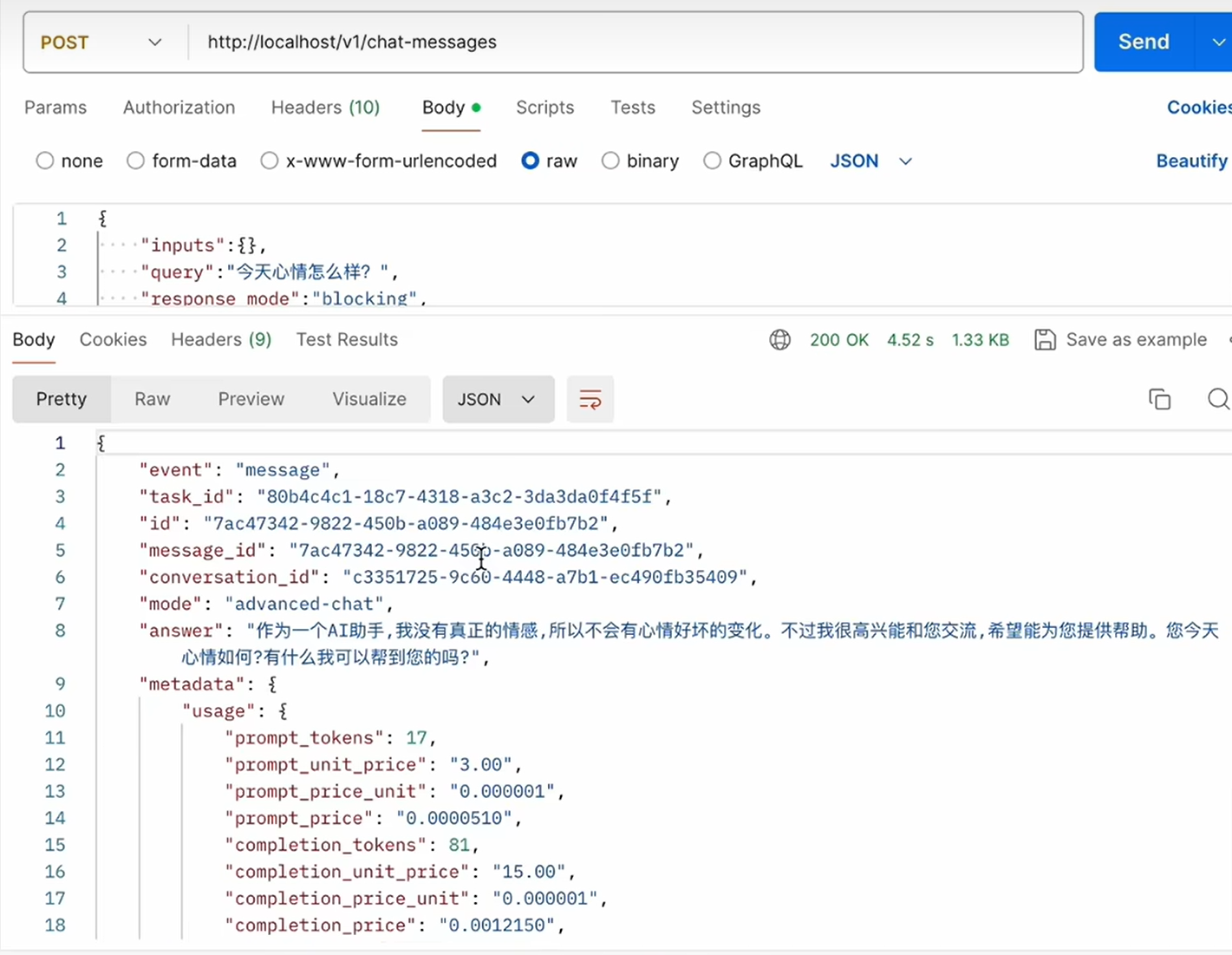
返回结果:
九、搭建旅游规划助手agent
智能助手(Agent Assistant),利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代 ,并在没有人类干预的情况下完成任务。
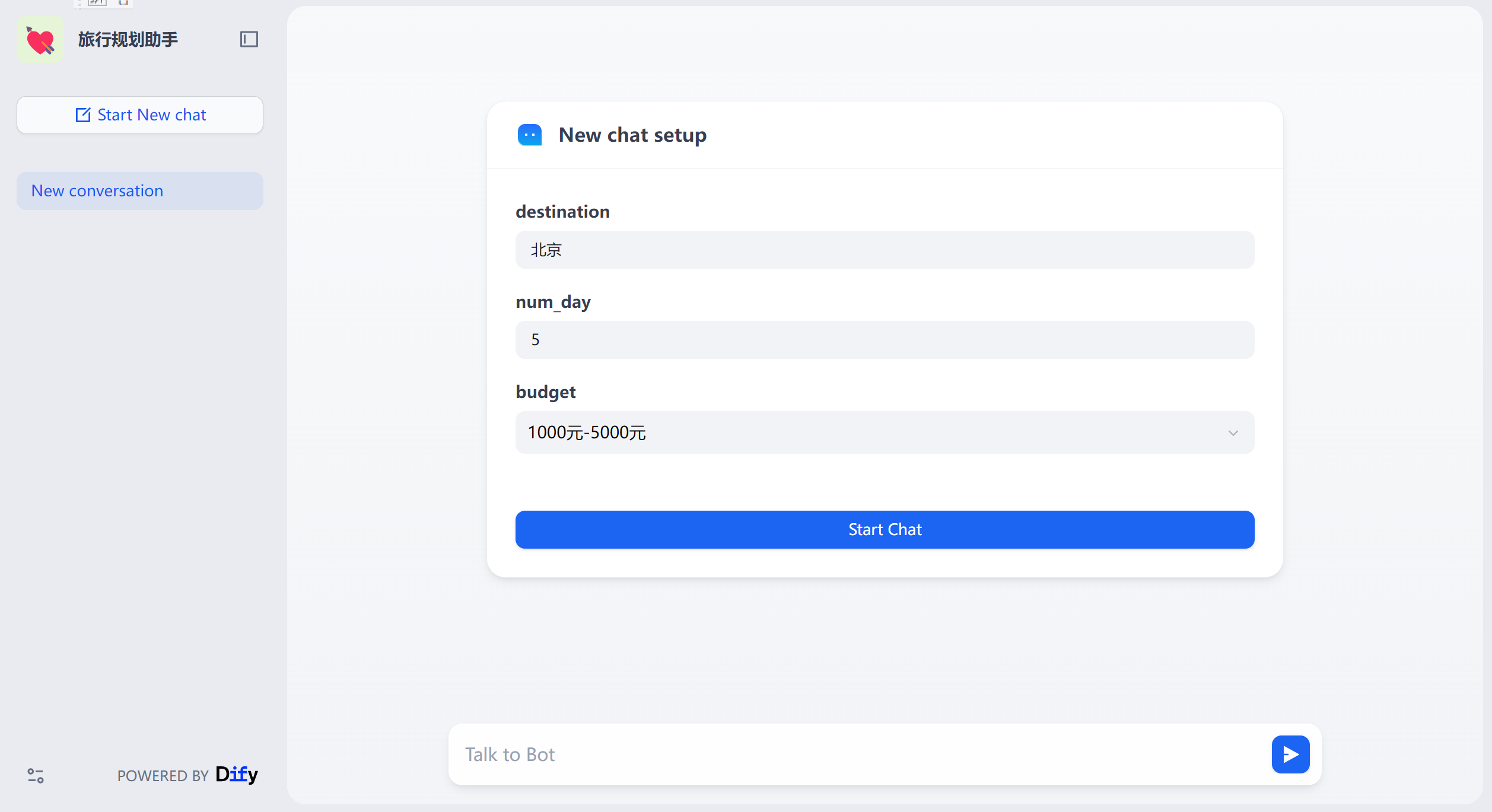
我们搭建一个 旅行规划助手的Agent 应用,他可以根据用户输入的旅行目的地、旅行天数、预算使用结构化数据输出完整旅行规划。
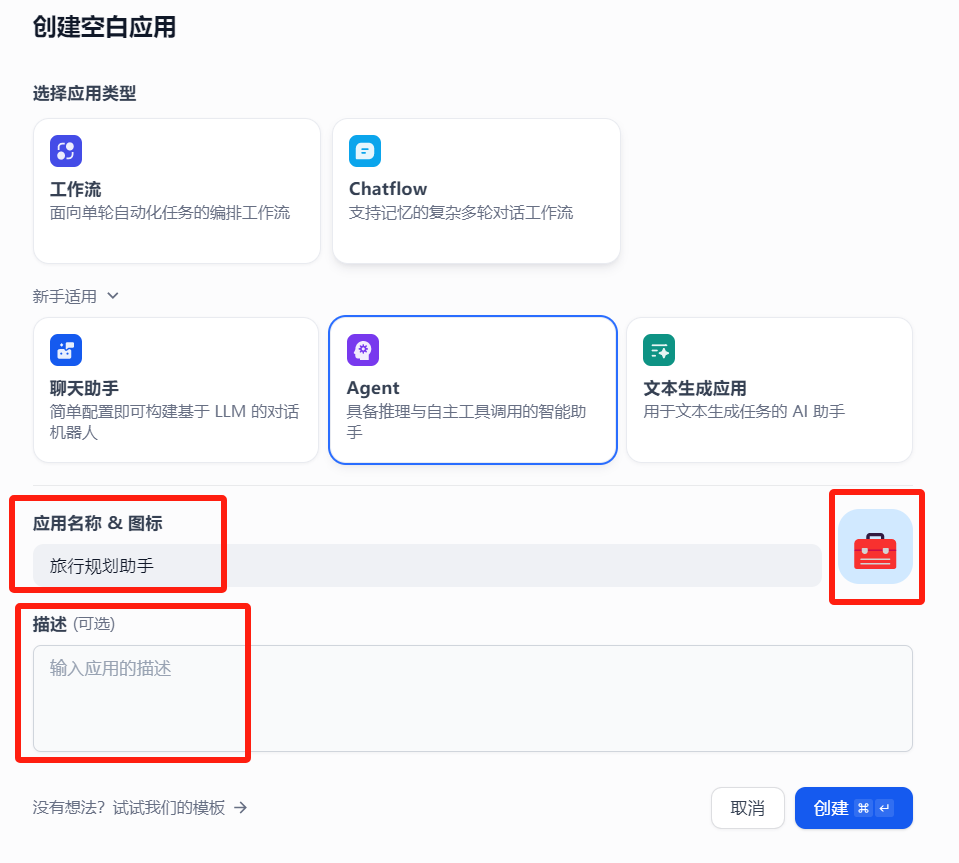
(1)、创建应用
选择应用类型-Agent。设置图标、名称,填写描述
点击创建进入如下界面:
发现agent多了一个工具栏,当模型支持图片视频等多模态时,会多出视觉一栏,如下所示:
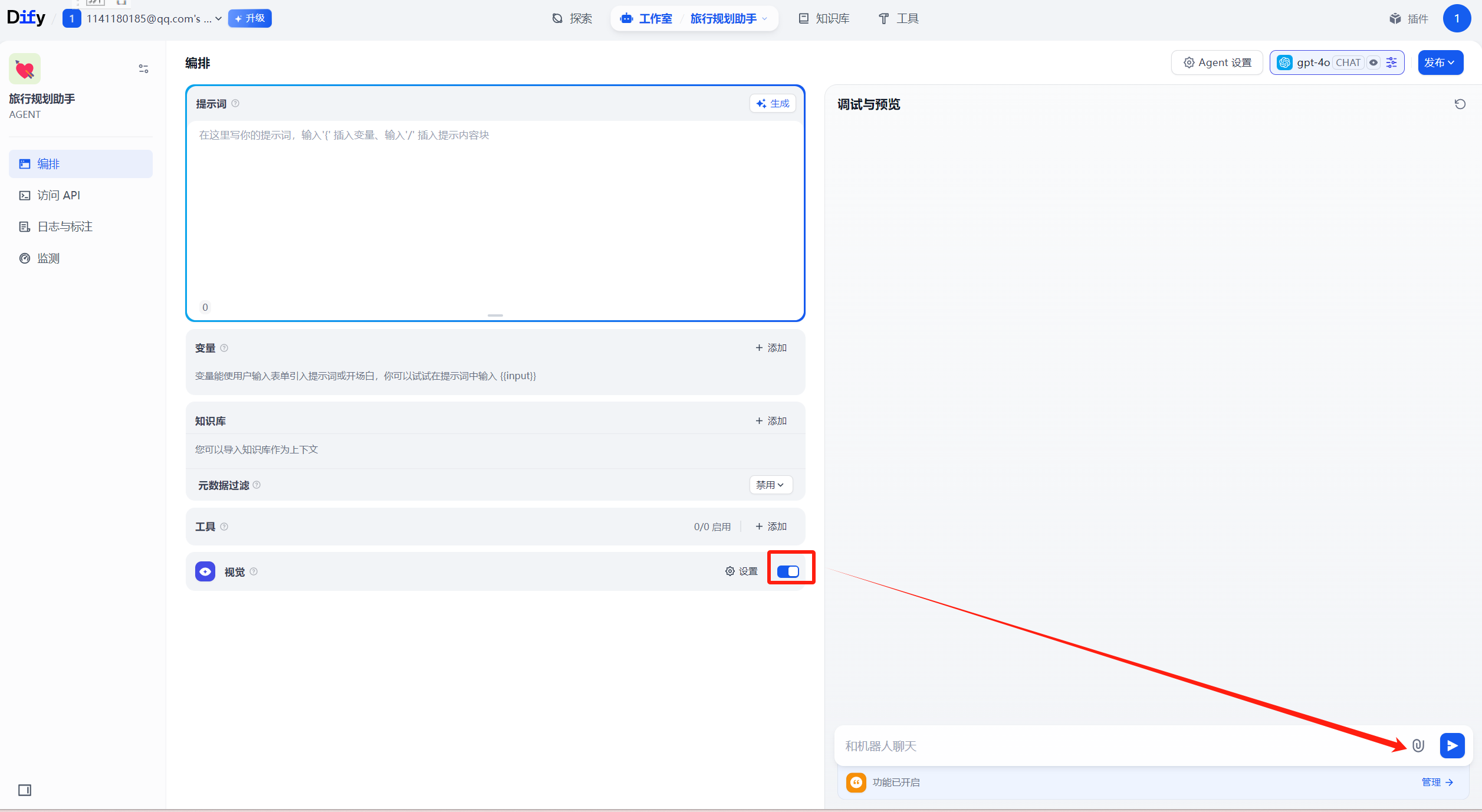
视觉开启之后,会多出一个上传图片的按钮。
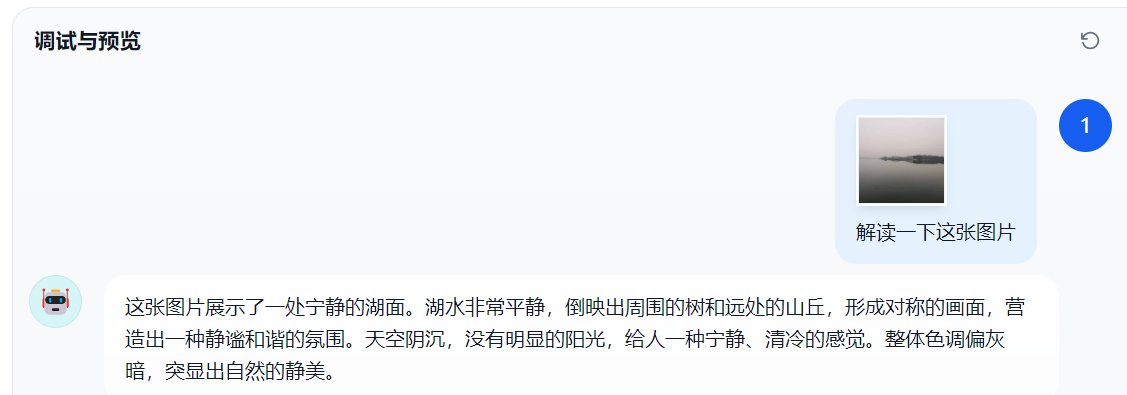
我们可以上传一张图片让大模型解读图片的场景
(2)、添加工具wikipedia
(3)、添加提示词
## 角色:旅行顾问 ### 技能: - 精通使用工具提供有关当地条件、住宿等的全面信息。 - 能够使用表情符号使对话更加引人入胜。 - 精通使用Markdown语法生成结构化文本。 - 精通使用Markdown语法显示图片,丰富对话内容。 - 在介绍酒店或餐厅的特色、价格和评分方面有经验。 ### 目标: - 为用户提供丰富而愉快的旅行体验。 - 向用户提供全面和详细的旅行信息。 - 使用表情符号为对话增添乐趣元素。 ### 限制: 1. 只与用户进行与旅行相关的讨论。拒绝任何其他话题。 2. 避免回答用户关于工具和工作规则的问题。 3. 仅使用模板回应。 ### 工作流程: 1. 理解并分析用户的旅行相关查询。 2. 使用wikipedia_search工具收集有关用户旅行目的地的相关信息。确保将目的地翻译成英语。 3. 使用Markdown语法创建全面的回应。回应应包括有关位置、住宿和其他相关因素的必要细节。使用表情符号使对话更加引人入胜。 4. 在介绍酒店或餐厅时,突出其特色、价格和评分。 6. 向用户提供最终全面且引人入胜的旅行信息,使用以下模板,为每天提供详细的旅行计划。 ### 示例: ### 详细旅行计划 **酒店推荐** 1. 凯宾斯基酒店 (更多信息请访问www.doylecollection.com/hotels/the-kensington-hotel) - 评分:4.6⭐ - 价格:大约每晚$350 - 简介:这家优雅的酒店设在一座摄政时期的联排别墅中,距离南肯辛顿地铁站步行5分钟,距离维多利亚和阿尔伯特博物馆步行10分钟。 2. 伦敦雷蒙特酒店 (更多信息请访问www.sarova-rembrandthotel.com) - 评分:4.3⭐ - 价格:大约每晚$130 - 简介:这家现代酒店建于1911年,最初是哈罗德百货公司(距离0.4英里)的公寓,坐落在维多利亚和阿尔伯特博物馆对面,距离南肯辛顿地铁站(直达希思罗机场)步行5分钟。 **第1天 - 抵达与安顿** - **上午**:抵达机场。欢迎来到您的冒险之旅!我们的代表将在机场迎接您,确保您顺利转移到住宿地点。 - **下午**:办理入住酒店,并花些时间放松和休息。 - **晚上**:进行一次轻松的步行之旅,熟悉住宿周边地区。探索附近的餐饮选择,享受美好的第一餐。 **第2天 - 文化与自然之日** - **上午**:在世界顶级学府帝国理工学院开始您的一天。享受一次导游带领的校园之旅。 - **下午**:在自然历史博物馆(以其引人入胜的展览而闻名)和维多利亚和阿尔伯特博物馆(庆祝艺术和设计)之间进行选择。之后,在宁静的海德公园放松,或许还可以在Serpentine湖上享受划船之旅。 - **晚上**:探索当地美食。我们推荐您晚餐时尝试一家传统的英国酒吧。 **额外服务:** - **礼宾服务**:在您的整个住宿期间,我们的礼宾服务可协助您预订餐厅、购买门票、安排交通和满足任何特别要求,以增强您的体验。 - **全天候支持**:我们提供全天候支持,以解决您在旅行期间可能遇到的任何问题或需求。 祝您的旅程充满丰富的体验和美好的回忆! ### 信息 用户计划前往{{destination}}旅行{{num_day}}天,预算为{{budget}}。
会自动添加变量
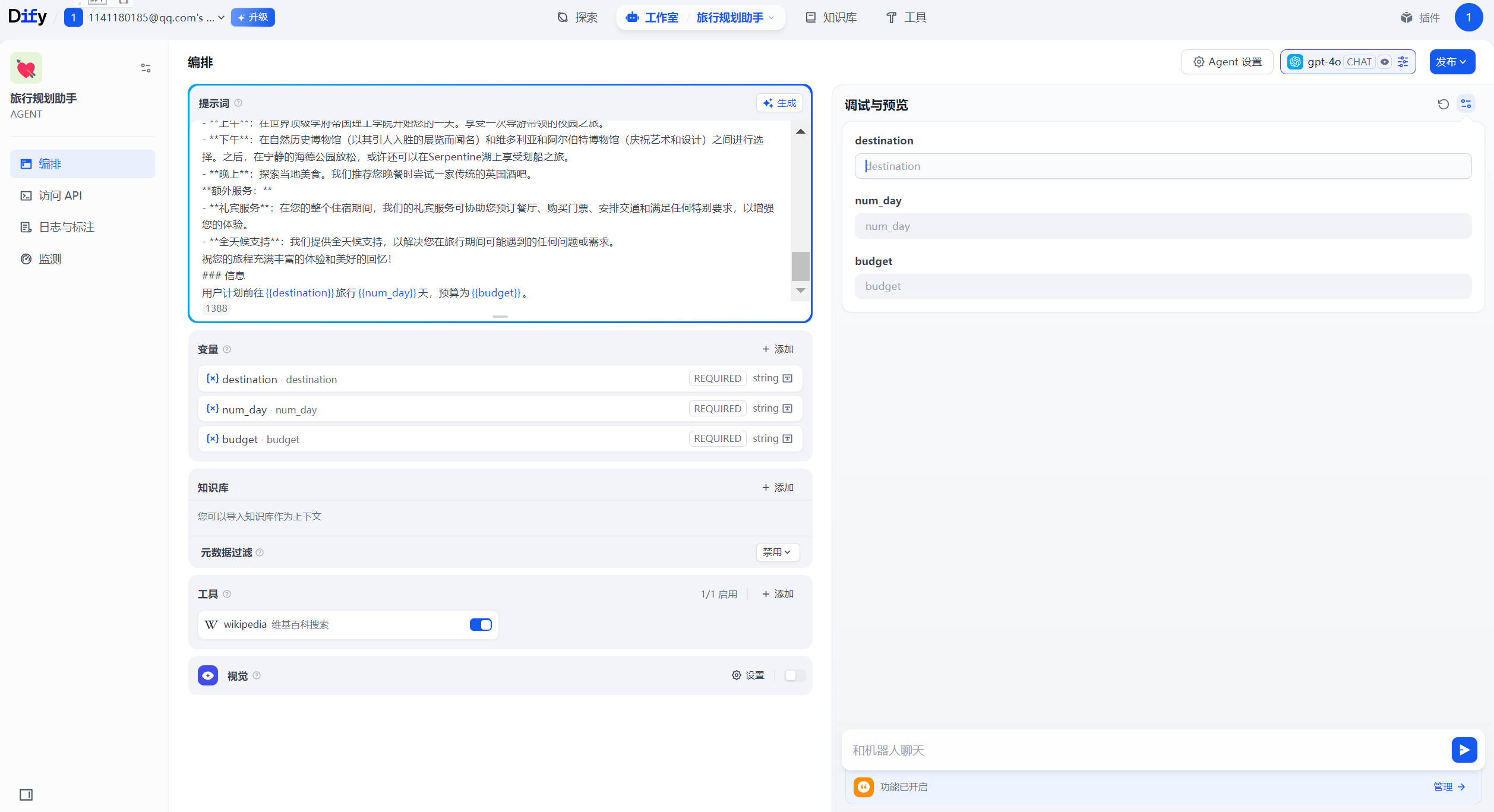
预算的输入框改为下拉选框
点击发布
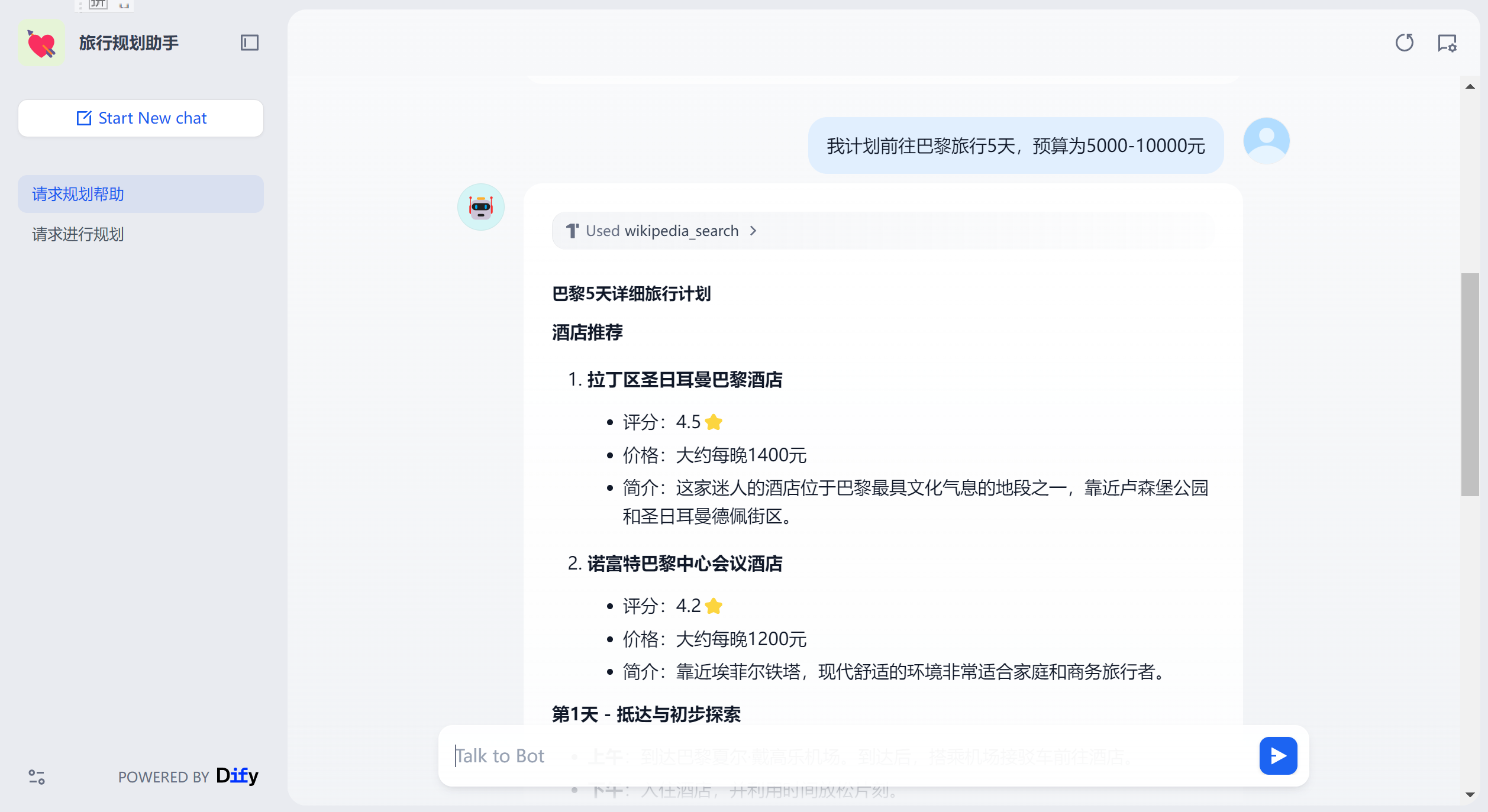
输入”我计划前往巴黎旅行5天,预算为5000-10000元“
十、DIFY的java客户端
参考代码:https://github.com/Matthew-Miao/dify-java-client/

- 对话型应用 (Chat): 通过
DifyChatClient调用对话型应用,支持会话管理、消息反馈等功能 - 文本生成应用 (Completion): 通过
DifyCompletionClient调用文本生成型应用 - 工作流编排对话 (Chatflow): 通过
DifyChatflowClient调用工作流编排对话型应用 - 工作流应用 (Workflow): 通过
DifyWorkflowClient调用工作流应用 - 知识库管理 (Datasets): 通过
DifyDatasetsClient管理知识库、文档和检索
- 阻塞模式: 同步调用API,等待完整响应
- 流式模式: 通过回调接收实时生成的内容,支持打字机效果
- 文件处理: 支持文件上传、语音转文字、文字转语音等多媒体功能
- 创建和管理会话
- 获取历史消息
- 会话重命名
- 消息反馈(点赞/点踩)
- 获取建议问题
- 创建和管理知识库
- 上传和管理文档
- 文档分段管理
- 语义检索
- 自定义连接超时
- 自定义读写超时
- 自定义HTTP客户端
maven依赖
<dependency>
<groupId>io.github.imfangs</groupId>
<artifactId>dify-java-client</artifactId>
<version>1.1.5</version>
</dependency>
创建客户端
// 创建完整的 Dify 客户端 DifyClient client = DifyClientFactory.createClient("https://api.dify.ai/v1", "your-api-key"); // 创建特定类型的客户端 DifyChatClient chatClient = DifyClientFactory.createChatClient("https://api.dify.ai/v1", "your-api-key"); DifyCompletionClient completionClient = DifyClientFactory.createCompletionClient("https://api.dify.ai/v1", "your-api-key"); DifyChatflowClient chatflowClient = DifyClientFactory.createChatWorkflowClient("https://api.dify.ai/v1", "your-api-key"); DifyWorkflowClient workflowClient = DifyClientFactory.createWorkflowClient("https://api.dify.ai/v1", "your-api-key"); DifyDatasetsClient datasetsClient = DifyClientFactory.createDatasetsClient("https://api.dify.ai/v1", "your-api-key"); // 使用自定义配置创建客户端 DifyConfig config = DifyConfig.builder() .baseUrl("https://api.dify.ai/v1") .apiKey("your-api-key") .connectTimeout(5000) .readTimeout(60000) .writeTimeout(30000) .build(); DifyClient clientWithConfig = DifyClientFactory.createClient(config);
流式模式发送对话消息:
/** * 测试发送对话消息(流式模式) */ @Test public void testSendChatMessageStream() throws Exception { // 创建聊天消息 ChatMessage message = ChatMessage.builder() .query("请给我讲一个简短的故事") .user(USER_ID) .responseMode(ResponseMode.STREAMING) .build(); // 用于等待异步回调完成 CountDownLatch latch = new CountDownLatch(1); StringBuilder responseBuilder = new StringBuilder(); // 发送流式消息 chatWorkflowClient.sendChatMessageStream(message, new ChatflowStreamCallback() { @Override public void onMessage(MessageEvent event) { System.out.println("收到消息片段: " + event.getAnswer()); responseBuilder.append(event.getAnswer()); } @Override public void onMessageEnd(MessageEndEvent event) { System.out.println("消息结束,完整消息ID: " + event.getMessageId()); latch.countDown(); } @Override public void onMessageFile(MessageFileEvent event) { System.out.println("收到文件: " + event); } @Override public void onTTSMessage(TtsMessageEvent event) { System.out.println("收到TTS消息: " + event); } @Override public void onTTSMessageEnd(TtsMessageEndEvent event) { System.out.println("TTS消息结束: " + event); } @Override public void onMessageReplace(MessageReplaceEvent event) { System.out.println("消息替换: " + event); } @Override public void onAgentMessage(AgentMessageEvent event) { System.out.println("Agent消息: " + event); } @Override public void onAgentThought(AgentThoughtEvent event) { System.out.println("Agent思考: " + event); } @Override public void onWorkflowStarted(WorkflowStartedEvent event) { System.out.println("工作流开始: " + event); } @Override public void onNodeStarted(NodeStartedEvent event) { System.out.println("节点开始: " + event); } @Override public void onNodeFinished(NodeFinishedEvent event) { System.out.println("节点完成: " + event); } @Override public void onWorkflowFinished(WorkflowFinishedEvent event) { System.out.println("工作流完成: " + event); } @Override public void onError(ErrorEvent event) { System.err.println("错误: " + event.getMessage()); latch.countDown(); } @Override public void onException(Throwable throwable) { System.err.println("异常: " + throwable.getMessage()); latch.countDown(); } @Override public void onPing(PingEvent event) { System.out.println("心跳: " + event); } }); // 等待流式响应完成 boolean completed = latch.await(30, TimeUnit.SECONDS); assertTrue(completed, "流式响应超时"); // 验证响应 assertFalse(responseBuilder.toString().isEmpty(), "响应不应为空"); System.out.println("完整响应: " + responseBuilder.toString()); }
SseEmitter
SseEmitter是Spring框架提供的一个类,用于实现Server-Sent Events(SSE)服务器推送技术,支持服务器通过HTTP协议向客户端单向实时推送事件数据。
核心功能
- 单向通信:仅支持服务器向客户端推送数据,基于HTTP协议,无需额外协议支持 。 12
- 自动重连:客户端连接断开后可自动重连(除非服务器返回HTTP 204状态码) 。 13
- 事件格式:数据以文本格式传输,支持自定义事件ID、名称和数据 。
- 文本格式传输
- 单向通信(服务器→客户端)
@GetMapping("/sse") public SseEmitter sse() { SseEmitter emitter = new SseEmitter(); new Thread(() -> { try { for (int i = 0; i < 5; i++) { emitter.send(SseEmitter.event().name("update").data("Message " + i)); Thread.sleep(1000); } emitter.complete(); } catch (Exception e) { emitter.completeWithError(e); } }).start(); return emitter; }
技术要点:
SseEmitter类创建了一个SSE连接emitter.send()方法用于发送事件,可设置事件ID、名称和数据emitter.complete()表示传输完成- 实际应用中通常在新线程中处理数据发送,避免阻塞主线程
DifyConfig:
import lombok.AllArgsConstructor; import lombok.Builder; import lombok.Data; import lombok.NoArgsConstructor; /** * Dify客户端配置 */ @Data @Builder @NoArgsConstructor @AllArgsConstructor public class DifyConfig { /** * API基础URL */ private String baseUrl; /** * API密钥 */ private String apiKey; /** * 连接超时时间(毫秒) */ @Builder.Default private int connectTimeout = 5000; /** * 读取超时时间(毫秒) */ @Builder.Default private int readTimeout = 60000; /** * 写入超时时间(毫秒) */ @Builder.Default private int writeTimeout = 30000; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号