力扣笔记 1 —— 简单 14 最大公共前缀
力扣 简单 14 最大公共前缀
14 最大公共前缀
作者:powcai
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/duo-chong-si-lu-qiu-jie-by-powcai-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题目描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。
提示:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]仅由小写英文字母组成
我的解答
不会
参考答案解析
作者:powcai
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/duo-chong-si-lu-qiu-jie-by-powcai-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
参考答案1
#解答思路1 根据python特性,取每一个单词相同为止的字母,看是否相同
def longestCommonPrefix(strs) :
res = ""
for tmp in zip(*strs): #同时取每个单词的同一位置的字母
tmp_set = set(tmp) # 把同一位置的字母生成一个集合
if len(tmp_set) == 1 : # 如果集合的长度为1,表示是同一个字母
res += tmp[0]
else: #对应的字母不相同,退出循环
break
return res
zip函数的用法
来自菜鸟教程
描述
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 ***** 号操作符,可以将元组解压为列表。
语法
zip 语法:
zip([iterable, ...])
参数说明:
- iterabl -- 一个或多个迭代器;
返回值
返回一个对象。
实例
以下实例展示了 zip 的使用方法:

python 在列表,元组,字典变量前加号。。_l_l_jh的博客-CSDN博客_python 变量前加
可以发现,在列表前加*号,会将列表拆分成一个一个的独立元素,不光是列表、元组、字典,由numpy生成的向量也可以拆分;
zip是将一个或多个可迭代对象进行包装压缩,返回将结果是列表;
通俗的说:zip()压缩可迭代对象,*号解压可迭代对象;
最后需要注意的是:
- 可迭代对象才可以使用*号拆分;
- 带*号变量严格来说并不是一个变量,而更应该称为参数,它是不能赋值给其他变量的,但可以作为参数传递;
#给出一个字符串组成的列表
strsList = ["flower","fa","fba"]
#输出列表 ,查看当前类型
print(strsList)
print(type(strsList))
#看一下将列表strs压缩后的结果以及类型
#逐个输出压缩后的列表里的元素以及类型
print(zip(strsList))
print(type(zip(strsList)))
for tmp in zip(strsList):
print(tmp)
print(type(tmp))
print("\n")
#看一下将列表strs压缩后,再解压的结果
print(*zip(strsList))
print("\n")
# 查看给列表外面加一个*的结果
# 查看 *strs 里面的元素的类型
# for循环逐个查看
print(*strsList)
mylist = [*strsList]
for elm in mylist:
print(type(elm))
print("\n")
# 查看 将*strs 压缩后的结果
# 逐个查看将*strs压缩后的每个元素以及类型
print(zip(*strsList))
for tmp in zip(*strsList):
print(tmp)
print(type(tmp))
print("\n")
# 查看 将zip(*strs)解压后的结果
# 逐个输出将zip(*strs)解压后里每个元素以及类型
print(*zip(*strsList))
mylist = [*zip(*strsList)]
for elm in mylist:
print(elm)
print(type(elm))
结果解析
['flower', 'fa', 'fba']
<class 'list'> # 显然, strsList是一个由字符串组成的列表,其格式为list
<zip object at 0x000001519A63B7C8>
<class 'zip'> #将其压缩后 , 变成一个zip压缩包 , 其格式为zip 类型
('flower',) #在压缩包里每个元素是一个tuple , 由‘字符串’和",“构成
<class 'tuple'>
('fa',)
<class 'tuple'>
('fba',)
<class 'tuple'>
('flower',) ('fa',) ('fba',) #将压缩包解压,就得到了里面的这三个tuple元素
flower fa fba
<class 'str'>
<class 'str'>
<class 'str'> #给列表list外面加一个* ,我们得到了三个字符串元素,相当于是把列表给解压了
<zip object at 0x000001519A63BA48>
('f', 'f', 'f')
<class 'tuple'>
('l', 'a', 'b')
<class 'tuple'> #然后我们在把这三个字符串元素进行压缩 , 得到了两个tuple元素 , 每一个元素的结果都是字符串相同位置的字母 , 这个结果和直接对三个字符串压缩的结果是一样的 ,也就是下列代码的结果是一样的
print(zip('flower','fa','fba'))
for tmp in zip('flower','fa','fba'):
print(tmp)
print(type(tmp))
print("\n")
('f', 'f', 'f') ('l', 'a', 'b')
('f', 'f', 'f')
<class 'tuple'>
('l', 'a', 'b')
<class 'tuple'> #我们将这三个字符串形成的压缩包解压 , 得到了里面的元素 ,元素的类型是tuple ,每一个元素的结果都是字符串相同位置的字母
参考答案2
# 思路2取一个单词 s,和后面单词比较,看 s 与每个单词相同的最长前缀是多少!遍历所有单词。
def longestCommonPrefix( s) :
if not s: #如果字符串列表为空,返回空字符串
return ""
res = s[0] #取字符串列表中第一个字符串
i = 1
while i < len(s): #遍历字符串列表中每个字符串
while s[i].find(res) != 0:
#在每个字符串s[i]中寻找第一个字符串res ,
# 其中 find函数返回下标,不包含返回-1 当返回值为0表示是从位置0开始找到了字符串res,也就是我们要找的前缀
# 由于我们是从完整的字符不断向前缩短的,也就是当前的最大前缀
res = res[0:len(res)-1] #如果没有找到,我们缩短第一个字符串res,继续寻找
i += 1
return res
find函数
版权声明:本文为CSDN博主「交小通」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_46291589/article/details/105876080
1、find
函数功能:find函数用于检测字符串中是否包括子字符串,如果指定检测的开始和结束范围,则在该范围内进行检测,默认在整个字符串内部检测。
返回值:如果包括子字符串,则返回其下标;如果不包含则返回-1(需要注意并不返回错误类型)。
函数语法:str.find(sub[,start[.end]])
sub:指定检索的字符串
start:开始索引的位置,默认是0
end:结束索引的位置,默认是字符串的长度
2、index
函数功能:index函数用于检测字符串中是否包含子字符串,如果指定检测的开始和结束范围,则在该范围内进行检测,默认在整个字符串内部检测。
返回值:如果包括子字符串,则返回其下标;如果不包含钻返回valueerror。(这里是和find函数不同之处)
函数语法:str.index(sub[,start[.end]])
sub:指定检索的字符串
start:开始索引的位置,默认是0
end:结束索引的位置,默认是字符串的长度
3、count
函数功能:count函数用于统计字符串中子字符串出现的次数,如果指定检测的开始和结束范围,则在该范围内进行检测,默认在整个字符串内部检测。
返回值:该函数返回子字符串在字符串中出现的次数。
函数语法:str.count(sub[,start[.end]])
sub:指定检索的字符串
start:开始索引的位置,默认是0
end:结束索引的位置,默认是字符串的长度
参考答案三
#思路三 按字典排序数组,比较第一个,和最后一个单词,有多少前缀相同。
def longestCommonPrefix(strs):
if not strs:
return ""
strs.sort() #先将字符串进行排序,排序结果为按着字典顺序升序
starts = strs[0] # 字符串列表第一个元素,第一个字符串
ends = strs[len(strs)-1]# 字符串列表最后一个元素,最后一个字符串
'''经过字典顺序排序后,最后一个与第一个在第i个字母必然不一致'''
res = ""
for i in range(len(starts)):
if starts[i] == ends [i]:
res += starts[i]
else:
break
return res
sort函数
Python3 list 排序字符串排序_俊晗的博客-CSDN博客_python列表字符串排序
我觉得使用python给出的这个三个答案都很巧妙,很好得使用了Python的特性
又看了一个java写的代码
参考答案四
思路
标签:链表
当字符串数组长度为 0 时则公共前缀为空,直接返回
令最长公共前缀 ans 的值为第一个字符串,进行初始化
遍历后面的字符串,依次将其与 ans 进行比较,两两找出公共前缀,最终结果即为最长公共前缀
如果查找过程中出现了 ans 为空的情况,则公共前缀不存在直接返回
时间复杂度:O(s),s 为所有字符串的长度之和
代码
class Solution {
public String longestCommonPrefix(String[] strs) {
if(strs.length == 0) //当数组为空,直接返回空字符串
return "";
String ans = strs[0]; //将第一个字符串元素赋值给ans
for(int i =1;i<strs.length;i++) { //遍历字符串列表中的每一个元素
int j=0; //j表示相同前缀的下标,
//找到后面每个字符串与第一个字符串的公共前缀
for(;j<ans.length() && j < strs[i].length();j++) { //下标j要小于第一个字符串元素的长度和当前字符串的长度
if(ans.charAt(j) != strs[i].charAt(j)) //当不在相等的时候,我们跳出循环
break;
}
ans = ans.substring(0, j); //把最后一个截取掉
if(ans.equals(""))
return ans;
}
return ans;
}
}
画解
作者:guanpengchn
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/hua-jie-suan-fa-14-zui-chang-gong-gong-qian-zhui-b/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
官方解答
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
📖 文字题解
方法一:横向扫描

基于该结论,可以得到一种查找字符串数组中的最长公共前缀的简单方法。依次遍历字符串数组中的每个字符串,对于每个遍历到的字符串,更新最长公共前缀,当遍历完所有的字符串以后,即可得到字符串数组中的最长公共前缀。
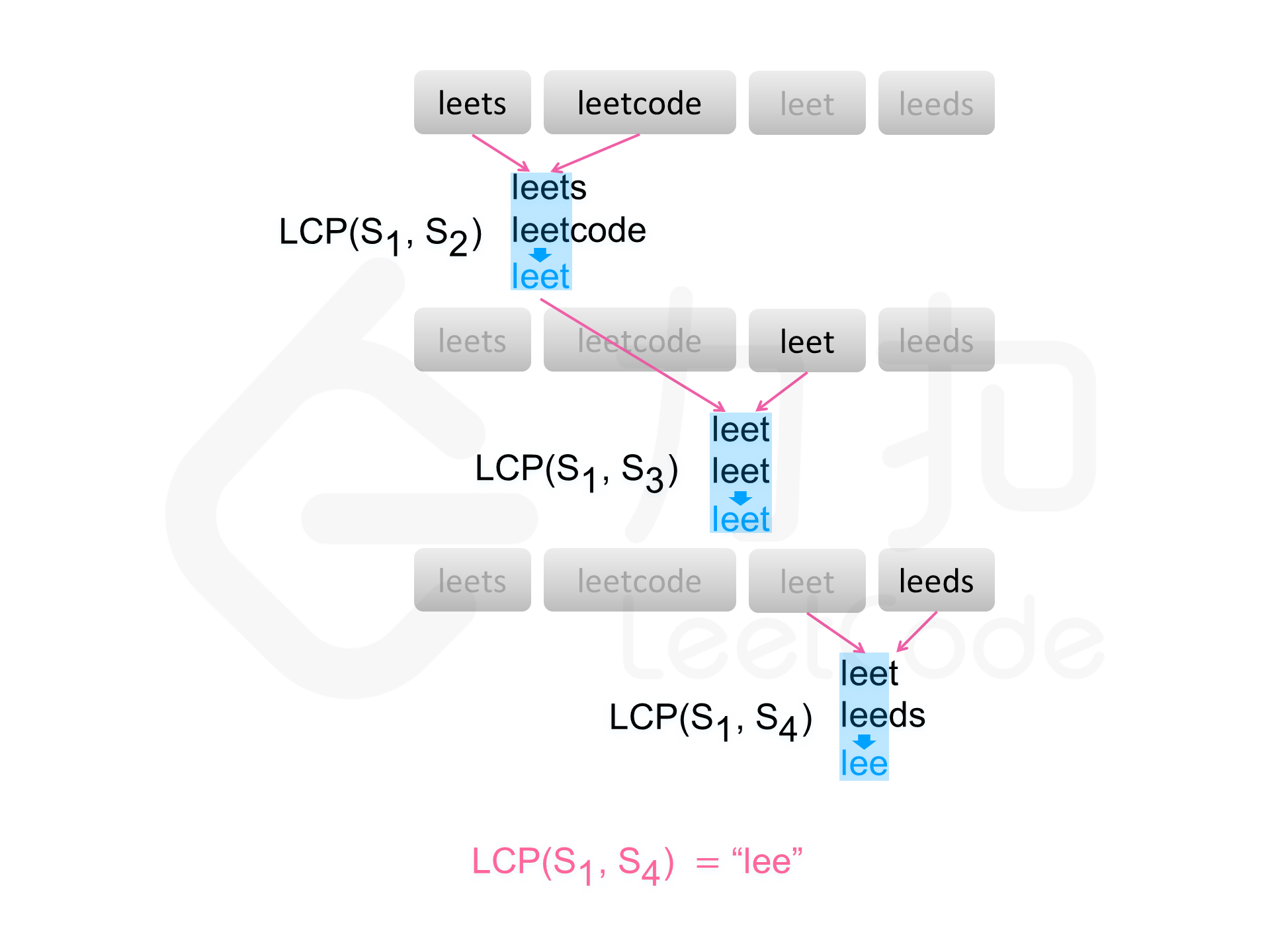
如果在尚未遍历完所有的字符串时,最长公共前缀已经是空串,则最长公共前缀一定是空串,因此不需要继续遍历剩下的字符串,直接返回空串即可。
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
string prefix = strs[0];
int count = strs.size();
for (int i = 1; i < count; ++i) {
prefix = longestCommonPrefix(prefix, strs[i]);
if (!prefix.size()) {
break;
}
}
return prefix;
}
string longestCommonPrefix(const string& str1, const string& str2) {
int length = min(str1.size(), str2.size());
int index = 0;
while (index < length && str1[index] == str2[index]) {
++index;
}
return str1.substr(0, index);
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复杂度分析
时间复杂度:O(mn),其中 m 是字符串数组中的字符串的平均长度,n 是字符串的数量。最坏情况下,字符串数组中的每个字符串的每个字符都会被比较一次。
空间复杂度:O(1)。使用的额外空间复杂度为常数。
方法二:纵向扫描
方法一是横向扫描,依次遍历每个字符串,更新最长公共前缀。另一种方法是纵向扫描。纵向扫描时,从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀,当前列之前的部分为最长公共前缀。
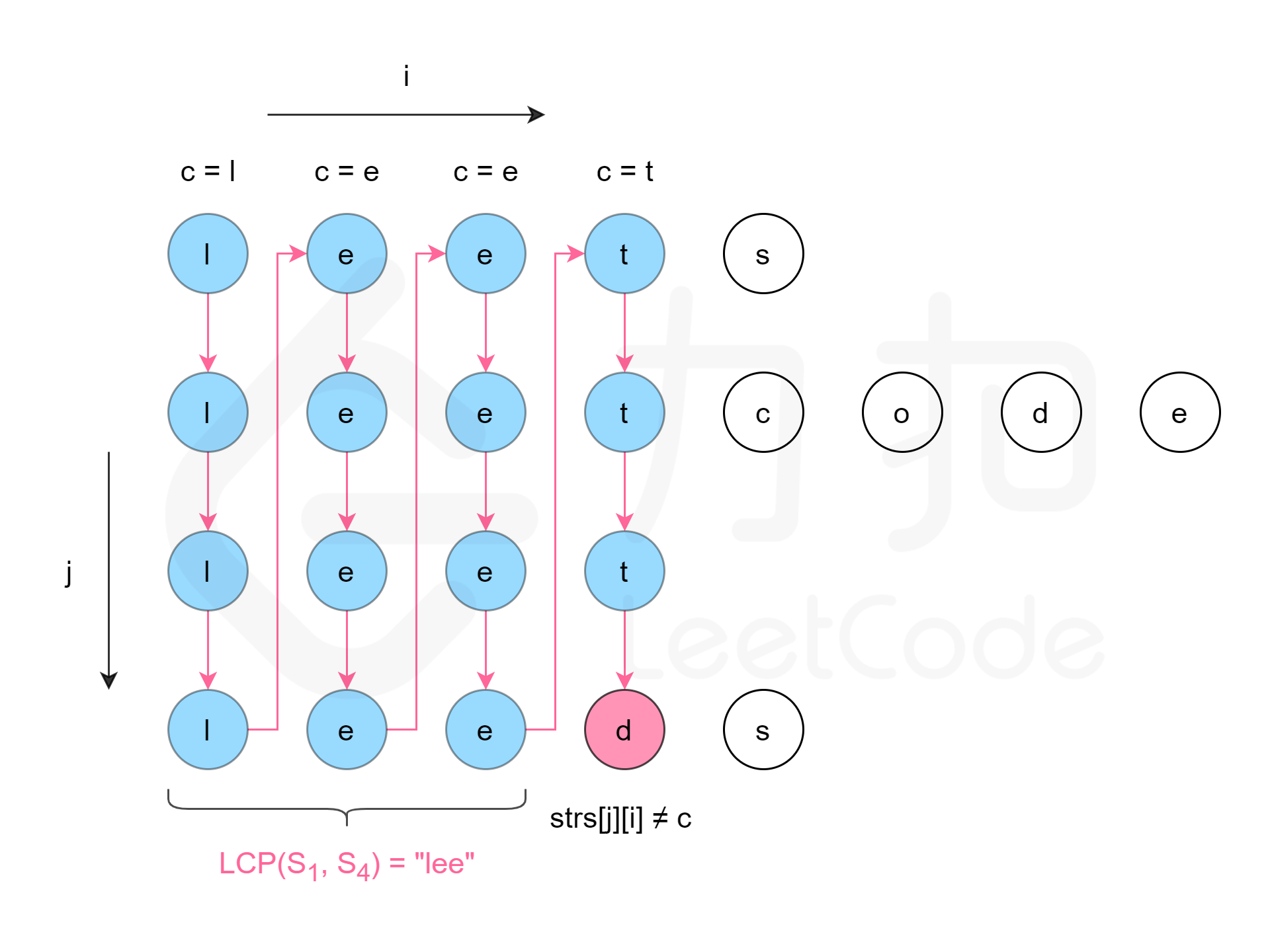
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
int length = strs[0].size();
int count = strs.size();
for (int i = 0; i < length; ++i) {
char c = strs[0][i];
for (int j = 1; j < count; ++j) {
if (i == strs[j].size() || strs[j][i] != c) {
return strs[0].substr(0, i);
}
}
}
return strs[0];
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复杂度分析
时间复杂度:O(mn),其中 m是字符串数组中的字符串的平均长度,nn 是字符串的数量。最坏情况下,字符串数组中的每个字符串的每个字符都会被比较一次。
空间复杂度:O(1)。使用的额外空间复杂度为常数。
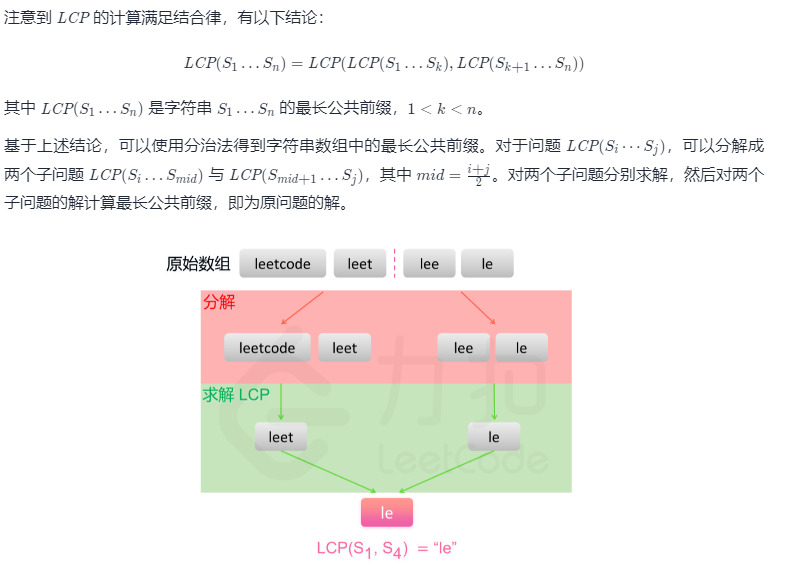
方法三:分治
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
else {
return longestCommonPrefix(strs, 0, strs.size() - 1);
}
}
string longestCommonPrefix(const vector<string>& strs, int start, int end) {
if (start == end) {
return strs[start];
}
else {
int mid = (start + end) / 2;
string lcpLeft = longestCommonPrefix(strs, start, mid);
string lcpRight = longestCommonPrefix(strs, mid + 1, end);
return commonPrefix(lcpLeft, lcpRight);
}
}
string commonPrefix(const string& lcpLeft, const string& lcpRight) {
int minLength = min(lcpLeft.size(), lcpRight.size());
for (int i = 0; i < minLength; ++i) {
if (lcpLeft[i] != lcpRight[i]) {
return lcpLeft.substr(0, i);
}
}
return lcpLeft.substr(0, minLength);
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复杂度分析

方法四:二分查找

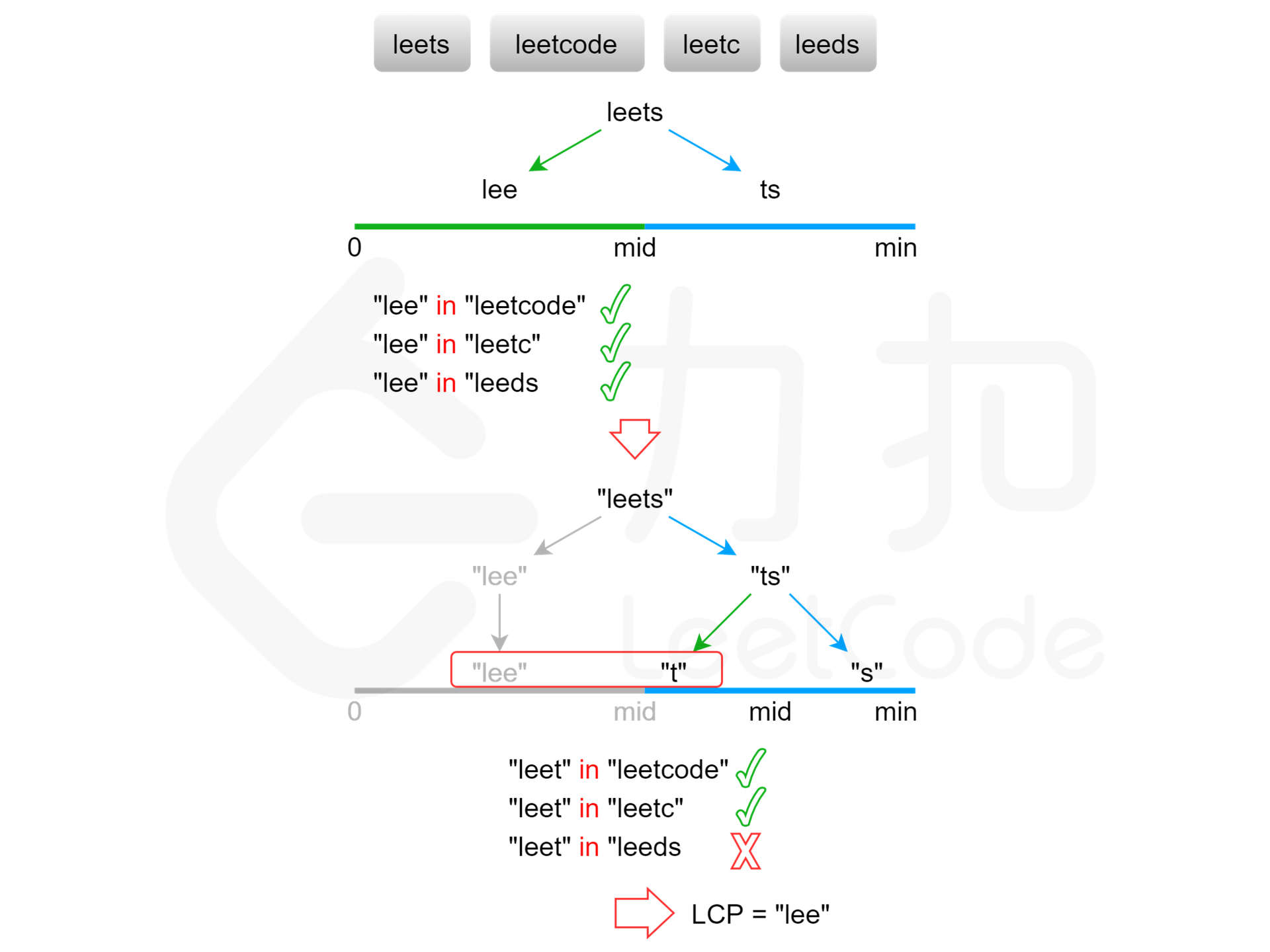
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
int minLength = min_element(strs.begin(), strs.end(), [](const string& s, const string& t) {return s.size() < t.size();})->size();
int low = 0, high = minLength;
while (low < high) {
int mid = (high - low + 1) / 2 + low;
if (isCommonPrefix(strs, mid)) {
low = mid;
}
else {
high = mid - 1;
}
}
return strs[0].substr(0, low);
}
bool isCommonPrefix(const vector<string>& strs, int length) {
string str0 = strs[0].substr(0, length);
int count = strs.size();
for (int i = 1; i < count; ++i) {
string str = strs[i];
for (int j = 0; j < length; ++j) {
if (str0[j] != str[j]) {
return false;
}
}
}
return true;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/longest-common-prefix/solution/zui-chang-gong-gong-qian-zhui-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复杂度分析
时间复杂度:O(mn \log m)O(mnlogm),其中 mm 是字符串数组中的字符串的最小长度,nn 是字符串的数量。二分查找的迭代执行次数是 O(\log m)O(logm),每次迭代最多需要比较 mnmn 个字符,因此总时间复杂度是 O(mn \log m)O(mnlogm)。
空间复杂度:O(1)O(1)。使用的额外空间复杂度为常数。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本文来自博客园,作者:{珇逖},转载请注明原文链接:https://www.cnblogs.com/zuti666/p/15771090.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号