

Kubernetes编程/Operator专题精讲—— 理解控制器模式 —— 控制器模式的核心原理与实现逻辑(从原理到实践)
Kubernetes编程/Operator专题精讲—— 理解控制器模式 —— 控制器模式的核心原理与实现逻辑(从原理到实践)
在 Kubernetes(k8s)的生态体系中,控制器模式是实现 声明式 API 的核心基石,也是理解 K8s 自愈能力、自动化运维的关键。
你日常使用的 Deployment、StatefulSet、Service 等资源的自动化管理,本质上都是控制器模式的具体落地。
本文将从控制器模式的核心原理出发,解析 kube-controller-manager 的作用,以 Deployment 为例拆解其创建流程,并深入讲解 Operator 模式的实现逻辑与实践。
一、控制器模式的核心原理
1.1、核心思想:调和循环(Reconciliation Loop)
Kubernetes 的控制器模式本质是实现 实际状态(Actual State)向 期望状态(Desired State)无限逼近的闭环控制系统,核心逻辑可概括为:
观察(Observe)→ 对比(Compare)→ 行动(Act)
-
-
- 观察:通过 k8s API Server 获取资源的实际状态(如 Pod 的运行数量、节点状态);
- 对比:将实际状态与用户通过 YAML 声明的期望状态对比,找出差异;
- 行动:通过调用 k8s API 执行操作(如创建 / 删除 Pod、更新资源标签),消除状态差异。
-
这个循环被称为“调和循环”(Reconciliation Loop),是所有 k8s 控制器的通用骨架,其核心目标是 最终一致性 —— 不保证立即达到期望状态,但会持续尝试直到状态匹配。
1.2、控制器模式的核心组件
一个标准的 k8s 控制器通常包含以下核心模块:
| 模块 | 作用说明 |
| Informer | 监听 API Server 的资源事件(增 / 删 / 改),缓存资源数据,避免频繁请求 API Server |
| WorkQueue | 异步处理资源事件的任务队列,实现 解耦 和 削峰填谷 |
| Sync/Reconcile 函数 | 核心业务逻辑,实现 “观察 - 对比 - 行动” 的核心逻辑 |
| Client | 与 API Server 交互的客户端(如 client-go),用于读写 k8s 资源 |
二、kube-controller-manager:核心控制器的总管家
kube-controller-manager 作为 Kubernetes 控制平面的 核心管控中枢,是实现集群 声明式 API 和 状态自洽 的关键组件。它本身不执行具体管控逻辑,而是通过独立 goroutine 运行多个专业控制器,统一监听 apiserver 的资源状态变化,持续对比 期望状态 与 实际状态,一旦发现偏差立即触发 纠偏操作,最终让集群始终贴合用户定义的状态。
其核心运行逻辑可概括为:监听(apiserver)→ 对比(状态)→ 纠偏(操作)→ 反馈(更新),所有内置控制器均遵循这一通用逻辑,仅针对不同资源的管控细节做差异化实现。下面结合文字解析 + 时序图,详细讲解其整体工作流程和六大核心控制器的具体实现。
2.1、核心架构
kube-controller-manager 的核心运行逻辑,就是 以标准化的监听 - 队列 - 处理框架为基础,通过声明式调和逻辑,让集群的实际状态最终贴合用户定义的期望状态,这也是 Kubernetes 自动化运维的底层核心。
kube-controller-manager 运行在控制平面节点,与 kube-apiserver、kube-scheduler 并称 控制平面三个核心,其核心架构特点:
-
- 与 apiserver 单向交互:所有控制器仅通过 apiserver 读写集群资源,不直接与节点 / 容器交互,保证集群管控的中心化和安全性;
- 控制器独立运行:每个控制器都是一个独立 goroutine,轻量级、无状态,互不阻塞,单个控制器故障不影响其他控制器运行;
- 基于 监听 -> 队列 -> 处理 模型:通过 apiserver 的 List/Watch API 监听资源变化,变化事件存入本地工作队列,控制器从队列中取事件逐一处理,避免并发冲突。
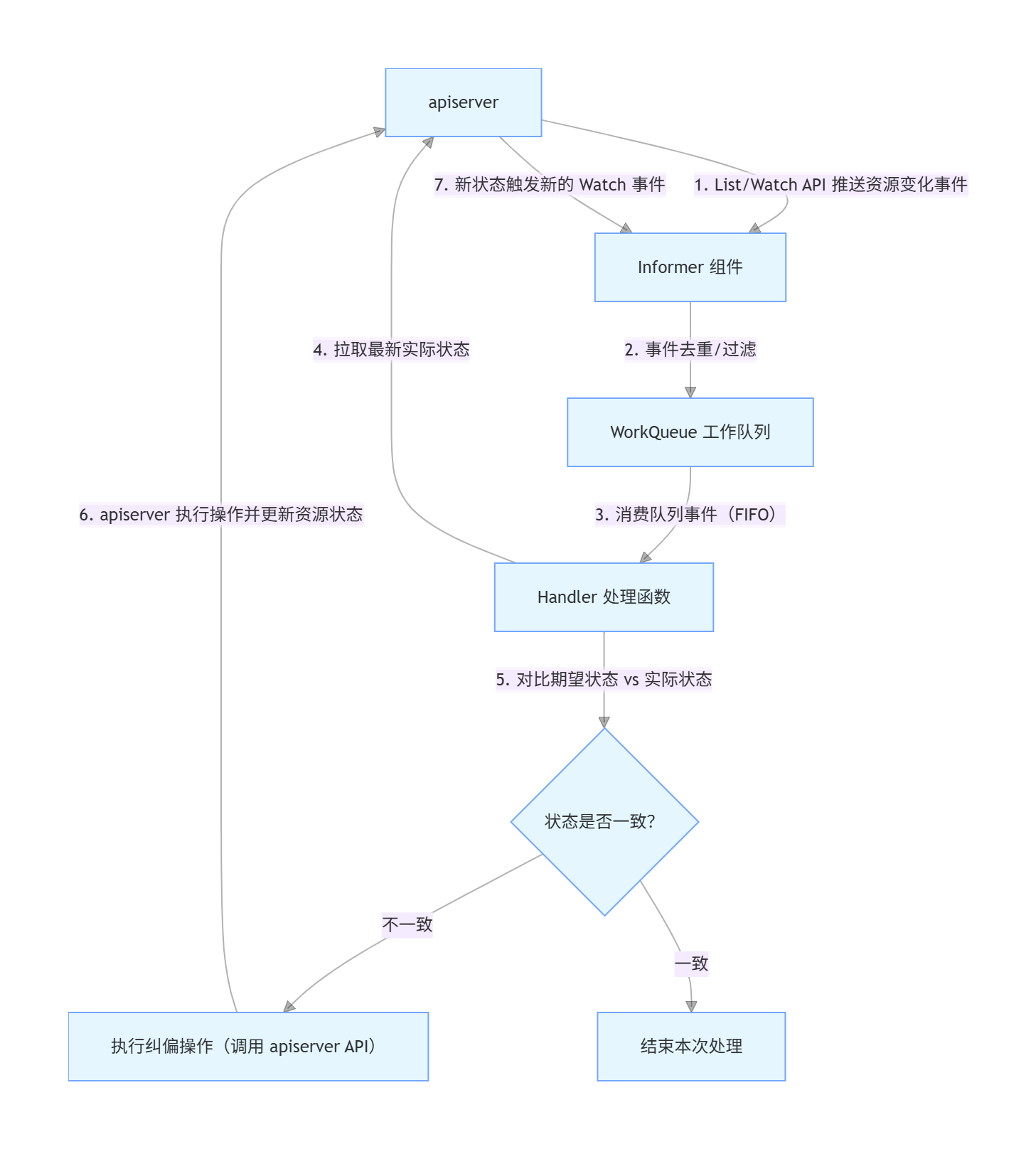
2.2、通用工作时序图(所有控制器的基础执行逻辑)
┌───────────────┐ ┌──────────────────┐ ┌──────────────────────┐ │ 用户/其他组件 │ │ kube-apiserver │ │ kube-controller-manager │ └───────┬───────┘ └─────────┬────────┘ └──────────┬─────────┘ │ │ │ │ 1、定义期望状态(创建/更新资源) │ │ │ ──────────────────────────→ │ │ │ │ │ │ 2、资源状态变更,触发Watch事件 │ │ │ ───────────────────────────→ │ │ │ │ │ │ 3、控制器接收事件,对比 期望状态 与 实际状态 │ │ │ (从apiserver拉取最新实际状态) │ │ ←─────────────────────────── │ │ │ │ │ │ 4、发现状态偏差,执行纠偏操作(调用apiserver API) │ │ ←─────────────────────────── │ │ │ │ │ 5、apiserver执行操作,更新资源实际状态 │ │ │ │ │ │ 6、状态更新完成,反馈给控制器 │ │ │ ───────────────────────────→ │ │ │ │ │ │ 7、控制器确认状态一致,结束本次管控流程 └───────────────┘ └──────────────────┘ └──────────────────────┘
帮助 SRE 理解关键核心点:
-
-
- Watch 机制:基于 HTTP 长连接的 推模式,apiserver 主动向控制器推送资源变化,而非控制器轮询,提升响应效率;
- 工作队列:控制器将 Watch 到的事件存入本地队列,采用 先入先出 模式处理,避免高并发下的事件丢失和重复处理;
- 状态对比:控制器的核心工作是 状态校验,而非直接执行操作,所有实际操作(如创建 Pod、删除节点)均通过调用 apiserver 的 API 完成。
-
2.3、第一层:Informer 组件(监听与事件预处理)
Informer 是 控制器 与 apiserver 之间的桥梁,核心作用是高效监听资源变化,并对事件做预处理,避免控制器直接面对复杂的 Watch 流。
2.3.1、核心能力
-
-
- List + Watch 组合:
- 启动时先执行 List 请求,拉取资源的全量数据,初始化本地缓存(Store);
- 之后通过 Watch 长连接,接收 apiserver 推送的资源增量变化(创建、更新、删除),实时更新本地缓存。
- 事件去重 / 防抖:同一资源短时间内多次变化(如 1 秒内 Pod 状态更新 5 次),Informer 会合并为一次事件,避免控制器重复处理;
- 本地缓存:所有资源状态都缓存在控制器本地(Store),控制器查询状态时优先读缓存,而非每次调用 apiserver,大幅降低 apiserver 压力。
- List + Watch 组合:
-
2.3.2、关键意义
Informer 屏蔽了 apiserver Watch API 的底层细节(如重连、分片、事件乱序),让控制器只需关注 资源变化事件,无需处理网络异常、事件重复等问题。
2.4、第二层:WorkQueue 工作队列(解耦与削峰)
WorkQueue 是控制器的 事件缓冲区,核心作用是解耦 Informer 的事件生产和 Handler 的事件消费,实现削峰填谷。
2.4.1、核心能力
-
-
- FIFO 有序消费:事件按接收顺序入队,控制器按顺序处理,避免并发冲突;
- 重试机制:处理失败的事件会重新入队(可配置重试次数 / 延迟),保证事件不丢失;
- 限速队列(RateLimitingQueue):默认使用限速队列,避免某一资源频繁失败导致队列被占满(如 Pod 创建失败后无限重试);
- 键值存储:队列中仅存储资源的 唯一标识(如 namespace/name),而非完整资源对象,减少内存占用。
-
2.4.2、关键意义
即使 apiserver 短时间推送大量事件(如集群扩容时 1000 个 Pod 同时创建),WorkQueue 也能缓存这些事件,控制器按自身处理能力逐步消费,避免控制器过载崩溃。
2.5、第三层:Handler 处理函数(核心逻辑执行)
Handler 是控制器的 大脑,核心作用是实现 状态对比 - 纠偏 的核心逻辑,也是不同控制器差异化的核心所在。执行流程(所有控制器通用):
-
-
- 从队列取事件:每次从 WorkQueue 取出一个资源标识(如 default/nginx-rc);
- 读本地缓存 + 校验:从 Informer 本地缓存读取该资源的最新状态,若资源已被删除(如 RC 已被删),则直接跳过;
- 拉取实际状态:针对需要管控的关联资源(如 RC 对应的 Pod),调用 apiserver 拉取 实际状态(如当前运行的 Pod 数量);
- 状态对比:对比 期望状态(如 RC 中定义的 replicas: 3)和 实际状态(如当前只有 2 个 Pod);
- 执行纠偏操作:若状态不一致,调用 apiserver API 执行纠偏(如创建 1 个新 Pod);
- 确认结果:操作完成后,再次检查状态,确保纠偏生效。
-
三、六大控制器详解
kube-controller-manager 内置的六大核心控制器各司其职,覆盖节点、Pod、Service、命名空间等核心资源的全生命周期管控,下面逐一讲解其 核心作用、工作机制、时序图 和 实际应用场景。
3.3.1、节点控制器(Node Controller)—— 集群节点的健康哨兵
3.3.1.1、核心作用
监控集群所有节点的健康状态,自动识别节点故障,触发节点标记和 Pod 驱逐,保证集群节点的可用性和业务连续性。
-
-
-
- 节点心跳检查间隔:5s
- 节点失联标记阈值(Unknown):40s(node-monitor-grace-period)
- 故障节点 Pod 驱逐阈值:5min(pod-eviction-timeout)
-
-
3.3.1.2、工作时序图
┌──────────────┐ ┌──────────────────┐ ┌──────────────────────┐
│ kubelet │ │ kube-apiserver │ │ Node Controller │
└───────┬──────┘ └─────────┬────────┘ └──────────┬─────────┘
│ │ │
│ 1、正常向apiserver上报节点状态(心跳+资源使用) │
│ ──────────────────────────> │
│ │ │
│ 2、节点故障(宕机/网络中断),停止上报心跳 │
│ │ │
│ │ 3、控制器Watch到节点状态无更新,开始计时
│ │ ───────────────────────────>
│ │ │
│ │ │ 4、达到40s阈值,将节点标记为Unknown状态(调用apiserver)
│ │ <───────────────────────────
│ │ │
│ │ 5、继续计时,等待5min驱逐阈值 │
│ │ │
│ │ │ 6、阈值到达,检查节点上Pod的控制器归属(是否属于Deployment/RS)
│ │ <───────────────────────────
│ │ │
│ │ │ 7、对有控制器的Pod,触发驱逐(通知apiserver删除故障节点上的Pod)
│ │ <───────────────────────────
│ │ │
│ │ 8、apiserver更新Pod状态,触发kube-scheduler重新调度
│ │ │
│ │ │ 9、新Pod在健康节点创建,控制器确认节点故障处理完成
└──────────────┘ └──────────────────┘ └──────────────────────┘
3.3.1.3、核心工作机制
-
-
-
- 心跳监控:通过 apiserver 监听 kubelet 上报的节点状态,持续获取节点的存活状态、资源使用情况;
- 故障识别:节点超过阈值无心跳,立即标记为 Unknown,避免新的 Pod 被调度到故障节点;
- Pod 驱逐:故障节点达到驱逐阈值后,仅驱逐有控制器管理的 Pod(无控制器的静态 Pod 不会被驱逐);
- 节点恢复:若故障节点恢复并重新上报心跳,控制器会将其标记为 Ready,重新纳入集群调度。
-
-
3.3.1.4、常见场景
集群某节点因硬件故障宕机,Node Controller 会在 5 分 40 秒 后自动将该节点上的业务 Pod 驱逐,kube-scheduler 会将这些 Pod 重新调度到其他健康节点,保证业务不中断。
3.3.2、副本控制器(Replication Controller,RC)—— 保障期望的 Pod 副本数量
3.3.2.1、核心作用
保证指定数量的 Pod 副本始终运行,是 Deployment、ReplicaSet 的底层实现基础(ReplicaSet 是 RC 的升级版,支持更丰富的标签选择器,逻辑与 RC 完全一致)。
3.3.2.2、工作时序图
┌───────────────┐ ┌──────────────────┐ ┌──────────────────────┐ │ 用户定义RC │ │ kube-apiserver │ │ Replication Controller │ └───────┬───────┘ └─────────┬────────┘ └──────────┬─────────┘ │ │ │ │ 1、创建RC,指定replicas:3 + Pod模板 + 标签选择器 │ │ ──────────────────────────> │ │ │ │ │ │ 2、Watch到RC创建事件,推送给控制器 │ │ ───────────────────────────> │ │ │ │ │ │ 3、控制器通过标签选择器查询实际运行的Pod数(初始为0) │ │ <─────────────────────────── │ │ │ │ │ │ 4、发现实际数(0) < 期望数(3),触发创建Pod操作(调用apiserver,基于Pod模板创建3个Pod) │ │ <─────────────────────────── │ │ │ │ │ 5、apiserver创建Pod,触发kube-scheduler调度 │ │ │ │ │ 6、Pod调度到节点并运行,kubelet上报Pod状态为Running │ │ <─────────────────────────── │ │ │ │ │ 7、控制器Watch到Pod状态更新,重新查询实际Pod数(3) │ │ ───────────────────────────> │ │ │ │ │ │ 8、实际数=期望数,状态一致,结束本次处理 │ │ │ │ │ │ 9、若某Pod异常退出(实际数变为2),控制器立即补建1个Pod,恢复副本数为3 │ │ <─────────────────────────── └───────────────┘ └──────────────────┘ └──────────────────────┘
3.3.2.3、核心工作机制
-
-
-
- 标签匹配:通过 标签选择器 筛选归属于当前 RC 的 Pod,仅对匹配的 Pod 进行副本数管控;
- Pod 模板:当需要补建 Pod 时,直接基于 RC 中定义的 Pod 模板创建,保证新 Pod 与原有 Pod 配置一致;
- 实时监控:Pod 发生异常退出、被手动删除、节点故障等情况,控制器会立即感知并补建,无需人工干预。
-
-
3.3.2.4、常见场景
用户创建 RC 部署 3 个 Nginx Pod,其中 1 个 Pod 因容器崩溃退出,RC 会在几秒内自动新建 1 个 Nginx Pod,始终保持 3 个副本运行。
3.3.3、端点控制器(Endpoint Controller)—— Service <——> Pod
3.3.3.1、核心作用
-
-
-
- 维护 Endpoints 资源(Service 与 Pod 的映射关系表,存储匹配的 Pod IP:Port),是 Service 能实现 负载均衡 和 Pod 访问 的核心,也是 kube-proxy 配置转发规则的依据。
- 标签匹配 + 映射更新:监听 Service 和 Pod 的变化,自动将匹配 Service 标签的 Pod 地址加入 Endpoints,将不匹配 / 已删除的 Pod 地址从 Endpoints 中移除。
-
-
3.3.3.2、工作时序图
┌───────────────┐ ┌──────────────────┐ ┌──────────────────────┐ │ Service/Pod │ │ kube-apiserver │ │ Endpoint Controller │ └───────┬───────┘ └─────────┬────────┘ └──────────┬─────────┘ │ │ │ │ 1、创建Service,指定标签选择器app:nginx │ │ ──────────────────────────> │ │ │ │ │ 2、创建3个带app:nginx标签的Pod并运行 │ │ ──────────────────────────> │ │ │ │ │ │ 3、Watch到Service和Pod创建事件,推送给控制器 │ │ ───────────────────────────> │ │ │ │ │ │ 4、控制器通过Service的标签选择器,筛选出匹配的3个Pod │ │ <─────────────────────────── │ │ │ │ │ │ 5、创建/更新Endpoints资源,写入3个Pod的IP:Port │ │ <─────────────────────────── │ │ │ │ │ 6、kube-proxy Watch到Endpoints变化,更新节点iptables/IPVS规则 │ │ ───────────────────────────> │ │ │ │ │ │ 7、若1个Pod异常删除,控制器立即从Endpoints中移除其IP:Port │ │ <─────────────────────────── │ │ │ │ │ 8、kube-proxy同步更新转发规则,避免访问到已删除的Pod └───────────────┘ └──────────────────┘ └──────────────────────┘
3.3.3.3、核心工作机制
-
-
-
- 双向监听:同时监听 Service 和 Pod 资源的创建、更新、删除事件,任何一方变化都会触发映射检查;
- Endpoints 与 Service 强绑定:一个 Service 对应一个同名的 Endpoints 资源,存储在同一命名空间;
- 无状态更新:仅维护地址映射,不参与实际的流量转发,流量转发由节点上的 kube-proxy 完成。
-
-
3.3.3.4、常见场景
用户访问 Service 的 ClusterIP 时,请求会通过 kube-proxy 的转发规则,转发到 Endpoints 中的任意一个 Pod IP,实现 Service 对 Pod 的透明访问和负载均衡。
3.3.4、命名空间控制器(Namespace Controller)—— 命名空间的生命周期管家
3.3.4.1、核心作用
-
-
-
- 管理命名空间的全生命周期,包括创建、更新、删除,核心是处理命名空间的删除逻辑,保证命名空间删除时,其下的所有资源被递归清理。
- 命名空间删除为异步操作,不会立即删除,而是先标记为 Terminating 状态,直到所有子资源清理完成后,才最终删除命名空间。
-
-
3.3.4.2、工作时序图
┌───────────────┐ ┌──────────────────┐ ┌──────────────────────┐
│ 用户操作NS │ │ kube-apiserver │ │ Namespace Controller │
└───────┬───────┘ └─────────┬────────┘ └──────────┬─────────┘
│ │ │
│ 1、执行kubectl delete ns test │
│ ──────────────────────────> │
│ │ │
│ │ 2、将ns/test标记为Terminating状态,推送给控制器 │
│ │ ───────────────────────────>
│ │ │
│ │ │ 3、控制器查询ns/test下的所有资源(Pod/Service/RC等)
│ │ <───────────────────────────
│ │ │
│ │ │ 4、递归删除所有子资源(按依赖顺序:先删除RC,再删除Pod,最后删除Service/ConfigMap等)
│ │ <───────────────────────────
│ │ │
│ │ 5、逐个删除资源,持续检查子资源剩余数量
│ │ <───────────────────────────
│ │ │
│ │ │ 6、确认ns/test下无任何子资源
│ │ <───────────────────────────
│ │ │
│ │ │ 7、最终删除ns/test资源,解除Terminating状态
│ │ <───────────────────────────
│ │ │
│ │ 8、命名空间删除完成,事件推送给apiserver
└───────────────┘ └──────────────────┘ └──────────────────────┘
3.3.4.3、核心工作机制
-
-
-
- 状态标记:命名空间删除的第一步是标记为 Terminating,防止新资源被创建到该命名空间;
- 递归清理:按 资源依赖顺序 清理子资源,避免因资源依赖导致删除失败;
- 卡点处理:若某子资源删除失败(如 Pod 一直处于 Terminating 状态),命名空间会卡在 Terminating 状态,需手动排查并清理卡点资源。
-
-
3.3.4.4、常见场景
用户删除测试命名空间 test,Namespace Controller 会自动清理该命名空间下的所有测试 Pod、Service、RC 等资源,无需人工逐个删除,避免集群资源残留。
3.3.5、服务账号控制器(ServiceAccount Controller)—— 集群的身份凭证管理员
3.3.5.1、核心作用
-
-
- 管理集群中的 ServiceAccount(服务账号)和对应的 Secret 令牌,为 Pod 提供访问 kube-apiserver 的身份认证凭证,实现 Pod 与 apiserver 的安全交互。
- 默认创建 + 凭证自动挂载:为每个命名空间自动创建 default 服务账号,为每个 ServiceAccount 自动创建对应的 Secret 令牌,Pod 若未指定 ServiceAccount,会自动挂载 default 账号的令牌。
-
3.3.5.2、工作时序图
┌───────────────┐ ┌──────────────────┐ ┌──────────────────────┐
│ 命名空间/Pod │ │ kube-apiserver │ │ ServiceAccount Controller │
└───────┬───────┘ └─────────┬────────┘ └──────────┬─────────┘
│ │ │
│ 1、创建新命名空间 ns/test │
│ ──────────────────────────> │
│ │ │
│ │ 2、Watch到NS创建事件,推送给控制器
│ │ ───────────────────────────>
│ │ │
│ │ │ 3、为ns/test自动创建default ServiceAccount
│ │ <───────────────────────────
│ │ │
│ │ │ 4、为default ServiceAccount自动创建Secret令牌(包含JWT认证信息)
│ │ <───────────────────────────
│ │ │
│ │ 5、在ns/test中创建Pod,未指定ServiceAccount
│ │ <───────────────────────────
│ │ │
│ │ │ 6、控制器自动将default ServiceAccount的Secret令牌挂载到Pod的/var/run/secrets/kubernetes.io/serviceaccount目录
│ │ <───────────────────────────
│ │ │
│ │ 7、Pod内应用通过挂载的令牌,向apiserver发起认证并请求API
│ │ <───────────────────────────
│ │ │
│ │ 8、若删除ServiceAccount,控制器自动删除对应的Secret令牌
│ │ <───────────────────────────
└───────────────┘ └──────────────────┘ └──────────────────────┘
3.3.5.3、核心工作机制
-
-
- 默认初始化:集群中每个命名空间都有且仅有一个 default 服务账号,由控制器保证其存在;
- 凭证自动生成:ServiceAccount 与 Secret 令牌一一对应,令牌为 JWT 格式,包含认证所需的所有信息;
- 无感知挂载:Pod 无需任何额外配置,即可自动挂载 default 账号的令牌,实现与 apiserver 的无缝认证。
-
3.3.5.4、常见场景
Pod 内的监控应用(如 Prometheus)需要查询集群的 Pod 列表和节点状态,应用会通过挂载的令牌向 apiserver 认证,通过后即可调用 k8s API 获取所需信息。
3.3.6、垃圾回收控制器(Garbage Collector)—— 集群的资源垃圾回收
3.3.6.1、核心作用
-
-
- 清理集群中的孤儿资源(无所有者、无被引用的资源),基于所有者引用(OwnerReference) 机制工作,避免集群资源泄露。
- 所有者引用:资源之间的父子依赖关系,如 Deployment → ReplicaSet → Pod,子资源的 OwnerReference 会指向父资源,标记其归属。
-
3.3.6.2、工作时序图
┌───────────────┐ ┌──────────────────┐ ┌──────────────────────┐
│ 父资源/子资源 │ │ kube-apiserver │ │ Garbage Collector │
└───────┬───────┘ └─────────┬────────┘ └──────────┬─────────┘
│ │ │
│ 1、创建Deployment,自动创建RS,RS自动创建Pod(均设置OwnerReference)
│ ──────────────────────────> │
│ │ │
│ 2、执行kubectl delete deploy test(默认cascade=true)
│ ──────────────────────────> │
│ │ │
│ │ 3、Watch到Deployment删除事件,推送给控制器
│ │ ───────────────────────────>
│ │ │
│ │ │ 4、控制器通过OwnerReference,查询到Deployment的子资源RS
│ │ <───────────────────────────
│ │ │
│ │ │ 5、先删除子资源RS
│ │ <───────────────────────────
│ │ │
│ │ │ 6、再通过OwnerReference查询到RS的子资源Pod,删除所有Pod
│ │ <───────────────────────────
│ │ │
│ │ │ 7、检查是否有孤儿资源(无OwnerReference的资源),发现1个手动创建的无归属Pod
│ │ <───────────────────────────
│ │ │
│ │ │ 8、自动删除该孤儿Pod,释放节点资源
│ │ <───────────────────────────
│ │ │
│ │ 9、所有依赖资源和孤儿资源清理完成
└───────────────┘ └──────────────────┘ └──────────────────────┘
3.3.6.3、核心机制
-
-
- 级联删除:删除父资源时,默认会递归删除其所有子资源(cascade=true),若设置 cascade=false,则仅删除父资源,子资源变为孤儿资源;
- 孤儿资源检测:定期扫描集群资源,识别无 OwnerReference 且长期未被使用的资源,自动清理;
- 引用计数:对于被多个资源引用的资源(如 ConfigMap 被多个 Pod 引用),仅当引用数为 0 时,才会被清理。
-
3.3.6.4、常见场景
用户手动创建了一个 Pod 用于测试,测试完成后忘记删除,该 Pod 异常退出后成为孤儿资源,垃圾回收控制器会在一定时间后自动清理该 Pod,释放节点的 CPU / 内存资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号