


Doris(实时数仓)专题精讲【左扬精讲】——Doris 从诞生到应用场景的全方位探索
Doris(实时数仓)专题精讲【左扬精讲】—— Doris 从诞生到应用场景的全方位探索
https://doris.incubator.apache.org/zh-CN/docs/gettingStarted/what-is-apache-doris/
官方原话:
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
一、为何诞生Doris?
https://doris.apache.org/docs/3.0/gettingStarted/what-is-apache-doris#whats-apache-doris
在当今数字化浪潮下,企业的数据量呈爆炸式增长,高效的数据处理能力成为了企业保持竞争力的关键。Doris 的诞生,正是为了应对这种大数据时代的挑战,满足企业在海量数据查询分析场景中的迫切需求。
早期,许多企业在处理海量数据查询分析时,普遍采用传统的关系型数据库,如 MySQL。以百度为例,在其发展过程中,业务规模的迅速扩张带来了日志分析、用户行为分析等海量数据处理任务。当时所使用的 MySQL 的 Sharding 方案在面对大规模数据处理场景时,存在诸多难以克服的问题,无法满足业务需求,其主要痛点如下:
-
- 大规模数据导入效率极低:以某互联网企业为例,在促销活动期间,大量广告投放带来巨量点击数据,企业需将近千万条广告点击数据导入数据库。使用 MySQL Sharding 方案时,导入过程极为缓慢,原本预期数小时完成的任务,最终耗时超过 24 小时。这是因为数据导入时 MySQL 需频繁进行磁盘 I/O 操作,且受 Sharding 机制影响,数据需分散写入多个分片,导致资源竞争激烈,系统整体性能大幅降低,严重拖慢业务数据处理进度。
- 频繁数据导入易引发锁表,导致查询超时:在频繁导入数据的场景下,例如一家互联网广告公司,每天需多次导入新的广告流量数据。由于 MySQL 的行锁和表锁机制,数据导入过程中其他查询操作极易被阻塞。一次该公司在导入新数据时,因锁表导致实时查询广告投放效果的业务请求超时率飙升至 50%,大量业务决策因无法及时获取数据而被迫推迟,严重影响了业务运营效率,无法满足实时数据查询的业务需求。
- 数据量达千万级别时性能急剧下降:某社交平台拥有海量用户,其用户行为分析涉及的数据量高达数千万条。使用 MySQL Sharding 方案进行数据分析时,复杂查询的响应时间变得难以忍受。如分析用户在特定广告活动期间的行为路径这一复杂查询,原本在数据量较小时能在数秒内返回结果,但当数据量突破千万级别后,查询时间延长至数分钟,且随着数据量的持续增长,查询性能进一步恶化。该平台不得不从产品层面限制用户端的查询时间,以避免系统长时间无响应,这极大地影响了用户体验和业务分析的全面性,无法支撑深度数据分析的业务需求。
- 多分片关联查询时数据一致性难以保证:当企业需要对多个分片上的数据进行关联查询时,由于各分片的数据更新可能存在延迟,MySQL Sharding 方案难以保证查询结果的实时一致性。例如一家跨区域运营的互联网企业,在分析各地区广告投放效果与销售业绩的关联关系时,因该方案的数据一致性问题,导致分析结果出现偏差,误导了后续的市场策略制定,无法满足业务对数据准确性和一致性的要求。
随着数据量的急剧增加,查询速度变得极为缓慢,复杂查询往往需要耗费数分钟甚至更长时间才能返回结果,这对于需要实时获取数据洞察以调整业务策略的企业来说,是难以接受的。而且,MySQL Sharding 方案在系统扩展性方面也表现不佳,当业务量进一步增长时,增加服务器节点并不能有效地提升整体性能,反而可能导致系统架构变得更加复杂和难以维护。
为了突破这些困境,满足高并发、低延迟的查询需求,百度的工程师们凭借深厚的技术积累,开启了自主研发之路。经过多年不懈的努力和实践打磨,一款全新的、专用于高效处理大规模数据的 OLAP 数据库应运而生。这款数据库在设计上采用了创新的分布式架构,摒弃了传统的主从架构模式,采用无主节点的分布式设计,每个节点都能独立处理查询请求,避免了单点瓶颈问题。同时,其向量化执行引擎充分利用现代 CPU 的 SIMD 指令集,大大提升了数据处理的效率,在查询性能上实现了质的飞跃。
在百度内部,这款自研数据库迅速得到了广泛应用。在百度搜索业务中,它能够快速处理用户搜索日志数据,为搜索算法的优化提供及时准确的数据支持,助力提升搜索结果的相关性和用户体验。在百度地图业务里,通过对大量位置信息和用户行为数据的高效分析,实现了智能路线规划、实时交通状况预测等功能的优化。随着技术的不断成熟和完善,这款数据库在百度内部稳定运行,有力地支撑了众多核心业务的数据查询分析工作。
与 MySQL Sharding 方案相比,Doris 在聚合模型、物化视图、批量读写方面有显著改进,具体如下:
为了回馈开源社区,促进全球技术的交流与共同进步,百度于 2017 年毅然将这款凝聚了无数心血的数据库开源,并命名为 Doris( Doris 发展历程:https://doris.apache.org/zh-CN/docs/3.0/gettingStarted/what-is-apache-doris#%E5%8F%91%E5%B1%95%E5%8E%86%E7%A8%8B)。自此,Doris 开启了新的征程,在开源社区的滋养下,不断吸收来自全球开发者的智慧和贡献,持续迭代升级,为更多企业解决数据处理难题,推动大数据技术的广泛应用和发展(Doris 应用现状:https://doris.apache.org/zh-CN/docs/3.0/gettingStarted/what-is-apache-doris#%E5%BA%94%E7%94%A8%E7%8E%B0%E7%8A%B6)。
二、Doris 架构
Frontend 是 Doris 的前端节点,承担着多种重要角色。它负责接收用户的查询请求,并对请求进行解析、优化和生成执行计划。同时,Frontend 还负责元数据的管理,包括数据库表的结构、分区信息、集群节点信息等。此外,Frontend 还承担着集群管理的职责,如节点的加入与退出、负载均衡等。
Backend 是 Doris 的后端节点,主要负责数据的存储和计算。它接收 Frontend 生成的执行计划,并按照计划对数据进行处理和计算,最后将结果返回给 Frontend。Backend 采用了列式存储的方式,能够有效减少数据的 I/O 操作,提高查询效率。同时,Backend 还支持数据的副本存储,保证了数据的可靠性和高可用性。
这种架构设计使得 Doris 具有良好的扩展性和灵活性。用户可以根据业务需求,灵活地增加 Frontend 或 Backend 节点,以应对不断增长的数据量和查询压力。以下是其架构详情介绍:
2.1、聊聊 Frontend(FE)
Frontend(FE)是 Doris 的核心管控节点,相当于整个集群的 “大脑”,其核心功能可细分为以下几个关键模块:
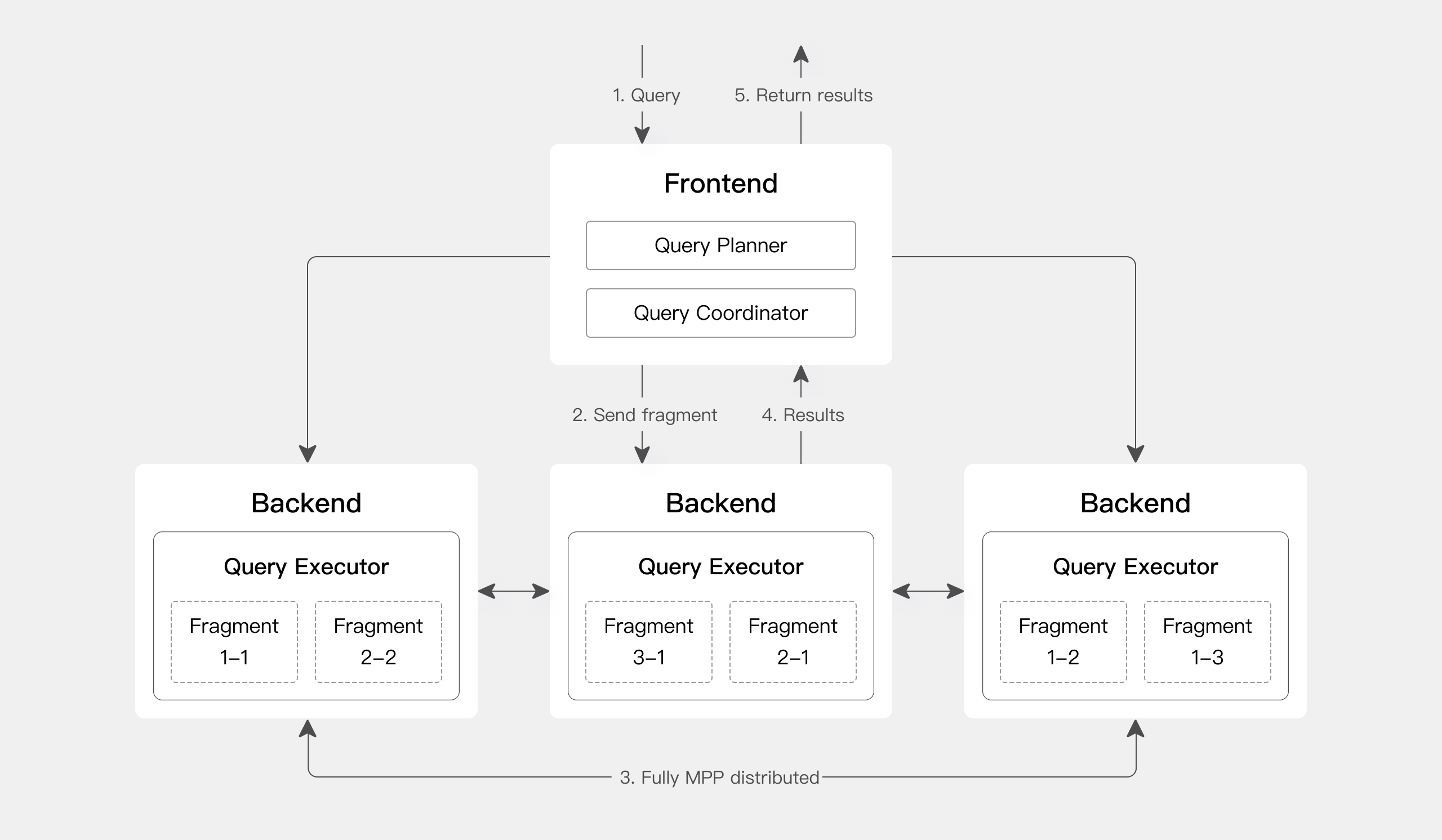
2.1.1、查询引擎模块
-
- 接收用户通过 MySQL 客户端、JDBC/ODBC 等方式提交的 SQL 查询请求,首先进行语法解析和语义校验,确保 SQL 语句符合语法规则且操作权限合法。
- 基于元数据信息(如表结构、分区分布、数据统计信息等)进行查询优化,例如通过代价估算选择最优的执行路径(如选择全表扫描还是索引扫描、调整 Join 顺序等),最终生成分布式执行计划。
- 将执行计划拆解为可并行执行的子任务,分配给对应的 Backend(BE)节点,并协调各节点的执行进度,汇总计算结果后返回给用户。
2.1.2、元数据管理模块
-
- 维护全集群的元数据信息,包括数据库、表、分区、索引、用户权限、集群节点状态等,这些信息以 Raft 协议同步到多个 FE 节点(通过主从复制机制保证高可用)。
- 支持动态元数据变更,例如用户创建表、修改分区策略时,FE 会实时更新元数据并同步至全集群,确保各节点对数据结构的认知一致。
2.1.3、集群管理模块
-
- 负责 BE 节点的生命周期管理,包括节点的加入、下线、健康状态监控(通过心跳机制检测节点存活)。若某 BE 节点故障,FE 会自动将其数据分片迁移至其他健康节点,保障数据可用性。
- 实现负载均衡,根据各 BE 节点的 CPU、内存、磁盘使用率及当前查询压力,动态调整数据分片的分布和查询任务的分配,避免单节点过载。
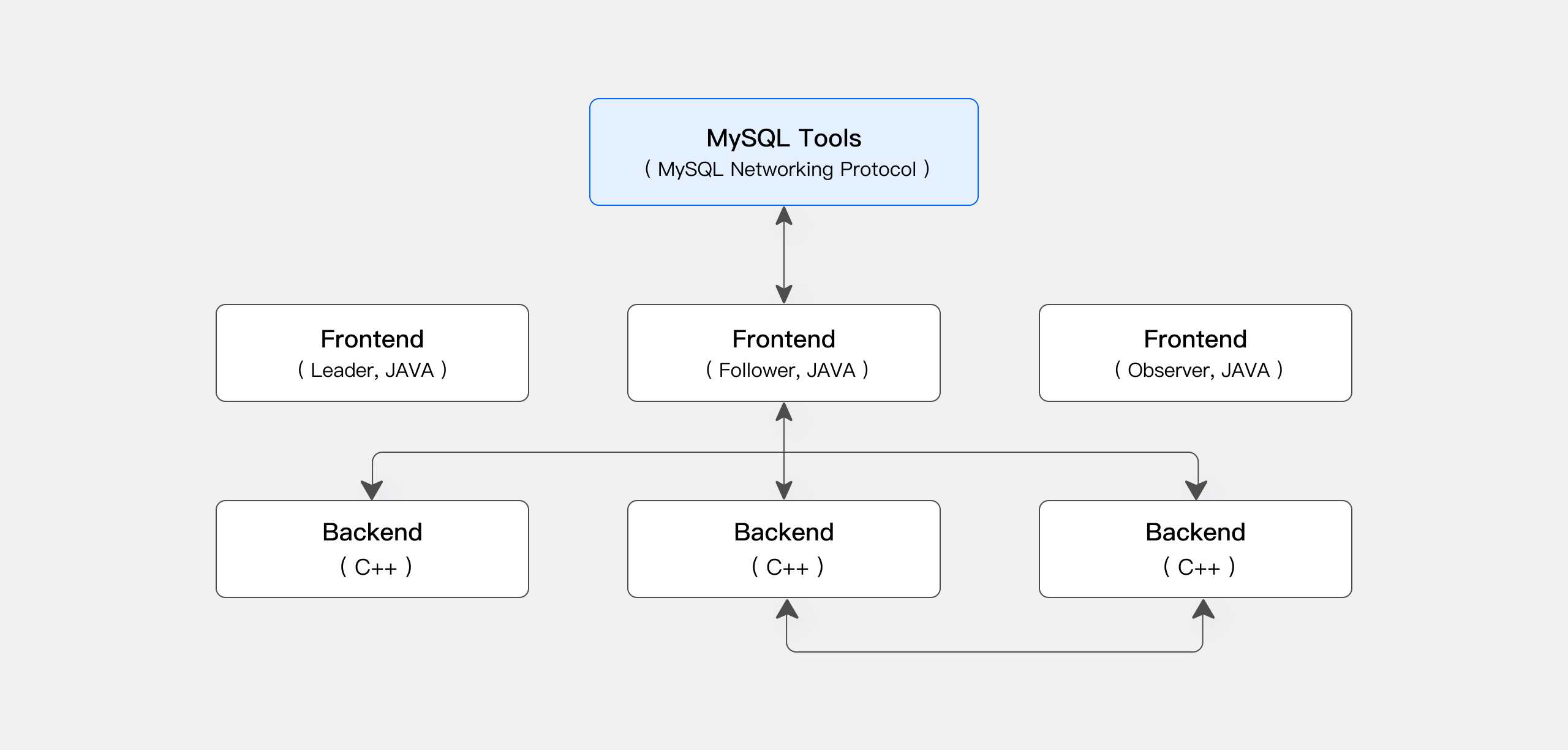
- 支持 FE 节点的主从架构(1 个 Leader 节点 + 多个 Follower/Observer 节点),Leader 负责元数据写入和集群决策,Follower 提供读服务并参与 Leader 选举,Observer 仅提供读服务(可扩展查询能力)。
2.2、聊聊 Backend(BE)
Backend(BE)是 Doris 的 “数据存储与计算单元”,直接处理数据的读写和计算任务,核心功能如下:
2.2.1、数据存储模块
数据存储兼顾高效与可靠,采用多种策略优化存储与查询。
-
- 采用列式存储格式,将表中不同列的数据分开存储。例如一张用户行为表,“用户 ID”“访问时间”“点击商品” 等列各自连续存储,查询时只需读取所需列,大幅减少磁盘 I/O 量(尤其适合 OLAP 场景中 “宽表查少数列” 的需求)。
- 支持数据分区和分桶:用户可按时间(如按天分区)或业务维度(如按地区分桶)对表进行划分,BE 节点仅需处理目标分区 / 分桶的数据,进一步提升查询效率。
- 运用多副本机制(默认 3 副本),确保数据可靠性与服务连续性。同一份数据存储在不同 BE 节点,某节点故障时,可从其他副本读取数据,保障数据安全与业务稳定运行。
2.2.2、计算执行模块
计算执行以并行与优化为核心,高效处理各类任务。
-
-
接收 FE 下发的子任务,依托本地数据并行运算,提升处理效率。FE 将查询任务拆解为子任务(如扫描某分区数据、执行聚合函数、Join 操作等)下发给 BE,BE 利用本地存储的数据进行并行计算,加速任务完成。
- 内置向量化执行引擎,批量处理数据以利用 CPU 缓存及 SIMD 指令集。通过批量处理数据(而非逐行处理),充分利用 CPU 缓存和 SIMD 指令集,提升计算效率。例如对 “求和”“计数” 等聚合操作,可一次性处理数千行数据,降低函数调用开销。
- 支持中间结果本地聚合,减少节点间数据传输量。如跨 BE 节点的 Join 操作,BE 节点先在本地预处理数据,仅传输过滤后的结果,降低网络带宽压力。
-
2.2.3、数据导入模块
数据导入灵活且严谨,保障数据准确高效写入。
-
- 支持多种导入方式,适配各类外部数据源,实现高效写入。提供 Broker Load、Stream Load、Routine Load 等多种导入方式,可接收 HDFS、Kafka、本地文件等外部数据源的数据,按 FE 定义的表结构和分区规则写入本地存储。
-
导入过程严格校验数据并进行预聚合,提升数据质量与查询效率。导入时进行数据校验(如类型匹配、约束检查),针对聚合模型表进行预聚合,减少无效数据存储,为后续查询优化数据基础。
- 支持多种导入方式,适配各类外部数据源,实现高效写入。提供 Broker Load、Stream Load、Routine Load 等多种导入方式,可接收 HDFS、Kafka、本地文件等外部数据源的数据,按 FE 定义的表结构和分区规则写入本地存储。
三、Doris3 架构
https://doris.apache.org/blog/release-note-3.0.0/
https://doris.apache.org/zh-CN/docs/releasenotes/v3.0/release-3.0.2/
https://www.selectdb.com/blog/1058
Doris 3 带来了一系列重大变革,对整体架构、性能、功能等多方面进行了深度优化与拓展。
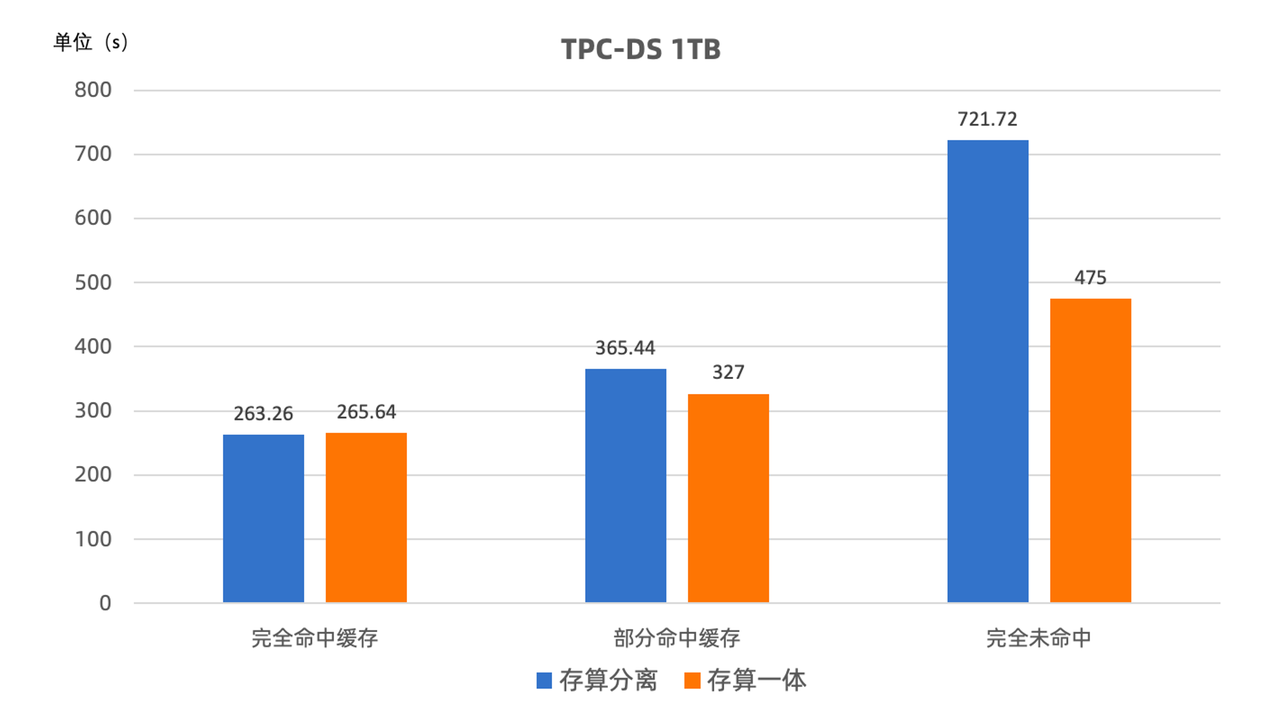
3.1、架构革新:存算分离架构
3.2、性能优化:多维度提升奠定高效基石

- 执行模型的持续升级:Doris 3 延续并深化了 2.0 版本引入的 Pipeline 执行模型。该模型将执行计划按照阻塞逻辑巧妙拆解为 Pipeline Task,然后分时调度到线程池中,成功实现阻塞操作的异步化。这一改进有效解决了旧版火山模型中 Instance 长期独占单一线程,导致线程池被占满,进而引发查询引擎假死的问题。通过采用差异化的调度策略,能够更加合理地分配 CPU 资源,充分满足不同规模查询以及不同租户的多样化需求。数据池化技术的应用,彻底解除了分桶数对 Instance 数量的限制,充分挖掘多核系统的计算潜力,显著提升系统的并发性能与稳定性,让系统在高负载下也能游刃有余地运行。
- 查询优化器的增强:查询优化器在生成执行计划时,具备了更为精准的代价估算能力。它能够全面综合数据分布、硬件资源等多方面因素,精心生成更优的分布式物理执行计划。通过巧妙减少数据移动,显著提升本地 Scan 比例,从而大幅提升查询效率。以复杂 Join 操作为例,优化器能够依据表数据量和关联列特性,智能灵活地选择 Broadcast Join、Shuffle Join 或 Bucket shuffle join 等不同策略,最大程度地降低网络开销与内存占用,确保查询在复杂场景下也能高效运行。
3.3、功能拓展:丰富数据处理能力满足多元需求

- 数据存储功能的扩充:在存算分离架构的支持下,Doris 3 能够适配更多类型的共享存储后端。与各类云厂商的对象存储服务实现深度集成,用户可以根据自身的成本预算、性能要求等灵活挑选合适的存储方案,实现资源的最优配置。针对存储的数据,引入了更为丰富的数据生命周期管理策略,能够对冷、热数据进行差异化存储与处理。将冷数据存储到低成本存储介质中,而热点数据则存储在高速存储设备中,在降低存储成本的同时,确保热点数据能够被快速访问,提升整体数据处理效率。
- 数据导入方式的完善:Doris 3 在保留原有的 Broker Load、Stream Load、Routine Load 等导入方式的基础上,对数据导入性能和稳定性进行了全方位优化。在面对高并发、大规模数据导入场景时,能够更加高效地处理数据,大幅缩短导入时间。在导入过程中,数据校验和预聚合功能变得更加智能,可根据表结构和数据特点自动灵活调整校验规则和聚合策略,从源头提升数据质量,为后续查询提供可靠的数据基础,提升查询效率。
- 实时数据分析能力的提升:Doris 3 显著增强了对实时数据的处理能力。在流数据处理场景中,能够以更快的速度摄取、分析数据。结合其卓越的查询性能,能够完美满足如实时监控、实时报表生成等对数据时效性要求极高的业务场景。企业能够依据实时分析结果迅速做出决策,把握市场先机,提升自身竞争力 。
四、Doris 引擎升级
随着业务的不断发展和数据量的爆炸式增长,Doris 的引擎也在不断升级迭代,以提供更高效、更稳定的性能。
-
- 早期的 Doris 引擎在处理复杂查询和大规模数据时,性能存在一定的瓶颈。为了突破这些瓶颈,研发团队对引擎进行了一系列的优化和升级。例如,引入了更先进的查询优化器,能够根据查询语句和数据分布情况,自动选择最优的执行计划,提高查询效率。
- 同时,Doris 引擎还在存储格式上进行了改进,采用了更高效的压缩算法和编码方式,减少了数据的存储空间,同时也提高了数据的读写速度。此外,引擎还支持向量化执行,能够将多条记录的处理合并为一个批量操作,大大提高了 CPU 的利用率和处理效率。
通过不断的引擎升级,Doris 的性能得到了显著提升,能够轻松应对各种复杂的查询场景和大规模的数据处理需求。
五、Doris 应用场景
https://doris.apache.org/docs/3.0/gettingStarted/what-is-apache-doris#usage-scenarios
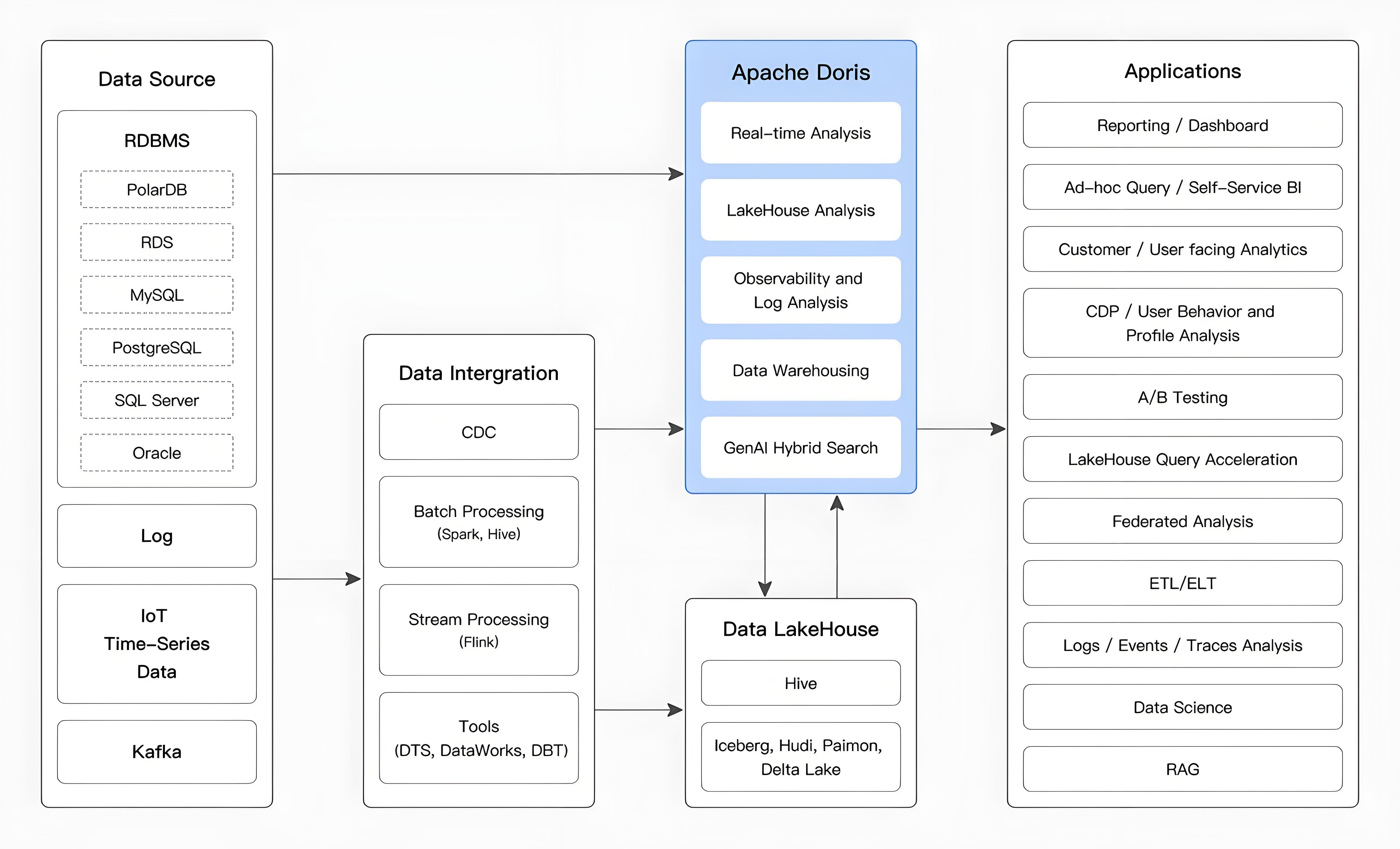
Apache Doris 在以下场景中被广泛使用:
Real-time Data Analysis: 实时数据分析:
- Real-time Reporting and Decision-making: Doris provides real-time updated reports and dashboards for both internal and external enterprise use, supporting real-time decision-making in automated processes.(实时报告和决策:Doris 为内外部企业提供实时更新的报告和仪表盘,支持自动化流程中的实时决策。)
- Ad Hoc Analysis: Doris offers multidimensional data analysis capabilities, enabling rapid business intelligence analysis and ad hoc queries to help users quickly uncover insights from complex data.(临时分析:Doris 具备多维数据分析能力,能够支持快速的商业智能分析和临时查询,帮助用户从复杂数据中迅速挖掘洞见。)
- User Profiling and Behavior Analysis: Doris can analyze user behaviors such as participation, retention, and conversion, while also supporting scenarios like population insights and crowd selection for behavior analysis.(用户画像与行为分析:Doris能够分析用户的参与度、留存率、转化率等行为,同时支持人群洞察、人群圈选等行为分析场景。)
Lakehouse Analytics: 湖仓一体分析
-
-
- Lakehouse Query Acceleration: Doris accelerates lakehouse data queries with its efficient query engine.(实时数据处理:Doris 融合了实时数据流与批量数据处理能力,能够满足高并发、低延迟的复杂业务需求。)
- Federated Analytics: Doris supports federated queries across multiple data sources, simplifying architecture and eliminating data silos.(联邦分析:Doris 支持跨多数据源的联邦查询,可简化架构设计并消除数据孤岛问题。)
- Real-time Data Processing: Doris combines real-time data streams and batch data processing capabilities to meet the needs of high concurrency and low-latency complex business requirements.(湖仓查询加速:Doris 凭借高效的查询引擎,实现了湖仓数据查询的加速。)
-
SQL-based Observability: 基于 SQL 的可观测性:
-
-
- Log and Event Analysis: Doris enables real-time or batch analysis of logs and events in distributed systems, helping to identify issues and optimize performance. (日志与事件分析:Doris 能够对分布式系统中的日志和事件进行实时或批量分析,助力问题定位与性能优化。)
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号