
Tensorflow 学习笔记(一)TensorFlow入门
一、计算模型----计算图
1.1 计算图的概念:TensorFlow就是通过图的形式绘制出张量节点的计算过程,例如下图执行了一个a+b的操作。
1.2 计算图的使用
TensorFlow程序一般分为两个阶段。第一个阶段定义计算图中的所有计算,第二个阶段执行计算(执行会话)。
阶段一
>>> import tensorflow as tf >>> a = tf.constant([1,2],name = 'a') >>> b = tf.constant([2,4],name = 'b') >>> result = a + b
阶段二
>>> ses = tf.Session() 2018-06-06 20:16:14.770712: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 >>> ses.run(result) array([3, 6]) >>>
在TF中,系统会自动维护一个默认的计算图,通过tf.get_default_graph函数可以获取当前默认的计算图。
a.graph可以查看当前张量所属的计算图。没有特殊指定的情况下,一般为默认计算图。
>>> tf.get_default_graph() <tensorflow.python.framework.ops.Graph object at 0x0000020774910828> >>> a.graph <tensorflow.python.framework.ops.Graph object at 0x0000020774910828>
#(两个对象的内存地址相同)
TF可以通过tf.Graph函数来生成一个新的计算图。不同计算图上的张量不会共享。
import tensorflow as tf #创建新的计算图,并且在计算图的上下文管理器中定义变量v,初始化为0 g1 = tf.Graph() with g1.as_default(): v = tf.get_variable("v",initializer=tf.zeros_initializer(),shape = [1,]) g2 = tf.Graph() with g2.as_default(): v = tf.get_variable("v",initializer=tf.ones_initializer(),shape=[1]) #在计算图g1中读取变量V的取值 with tf.Session(graph=g1) as sess: tf.global_variables_initializer().run() with tf.variable_scope("",reuse=True): print(sess.run(tf.get_variable("v"))) #在计算图g2中读取变量V的取值 with tf.Session(graph=g2) as sess: tf.global_variables_initializer().run() with tf.variable_scope("",reuse=True): print(sess.run(tf.get_variable("v")))
可以通过tf.Graph.device()指定运行计算的设备,例如GPU。
g = tf.Graph()
with g.device("gpu/0") :
result = a + b
二、数据模型------张量
2.1张量的概念
从功能的角度,张量可以被理解成一个N维数组。零阶张量表示标量,一阶张量表示向量,也就是一个以为数组,第n阶张量为矩阵,也就是一个n维数组。
但张量在tf中并不是采用数组的形式,只是对TF的运算结果的引用。
import tensorflow as tf #tf.constant是一个计算,这个计算的结果为一个张量,保存在变量a中 a = tf.constant([1,2],name="a") b = tf.constant([1,3],name="b") result = tf.add(a,b,name="add") print(result) #输出结果 Tensor("add:0", shape=(2,), dtype=int32)
TF的计算结果是一个张量结构。一个张量包含三个属性:名字name ,维度shape,类型 dtype。
name :张量的唯一标识。命名规范:“node:src_input” 。node 表示图的节点的名称,src_input 表示张量来自节点的第几个输入(从0开始)
shape:描述张量的维度信息。
dtype;每一个张量有一个唯一的类型。不同类型计算会报错。
import tensorflow as tf #tf.constant是一个计算,这个计算的结果为一个张量,保存在变量a中 a = tf.constant([1,2],name="a") b = tf.constant([1.0,3.0],name="b") result = tf.add(a,b,name="adds") print(result) TypeError: Input 'y' of 'Add' Op has type float32 that does not match type int32 of argument 'x'.
tf有14中数值类型
2.2张量的使用。
张量的使用分为两大类:
第一类,对中间计算结果的引用。提高代码的可读性。
import tensorflow as tf #使用张量记录计算结果 a = tf.constant([1.0,2.0],name="a") b = tf.constant([1.0,3.0],name="b") result = a+b #直接计算向量的和,可读性很差 result = tf.constant([1.0,2.0],name="a") + tf.constant([1.0,2.0],name="b")
第二类情况,当计算图构造完成后,张量可以用来获取计算结果,得到真实的数字。(利用Session)
三、TF运行模型----会话
会话用来执行定义好的计算。会话可以调用和管理TF的所有资源。会话用完后需要关闭释放资源。
会话的模式有两种:
第一种、显式调用会话生成函数和关闭会话函数。
#创建一个会话 sess = tf.Session() #运行会话得到计算结果 sess.run(result) #关闭会话,释放资源 sess.close()
第二种,运用上下文管理器来使用会话
with tf.Session() as session:
session.run(result)
设置默认会话
TF可以手动指定默认的会话,当默认的会话被指定之后可以通过tf.Tensor.eval函数来计算一个张量的取值。
以下两种代码均可以完成这种功能。
import tensorflow as tf a = tf.constant([1.0,2.0],name="a") b = tf.constant([1.0,3.0],name="b") result = a+b #方法一 sess = tf.Session() with sess.as_default(): print(result.eval()) #方法二 sess = tf.Session() print(sess.run(result)) print(result.eval(session=sess))
设置交互式默认会话
在交互环境下,通过设置默认会话的方式来获取张量的取值更方便。TF提供了在交互环境下直接构建默认会话的函数。这个函数就是tf.InteractiveSession。可以省略将会话注册为默认会话的过程
sess = tf.InteractiveSession() print(result.eval()) sess.close()
通过ConfigProto Protocol Buffer 来配置需要生成的会话。
config = tf.ConfigProto(allow_soft_placement = True,log_device_placement = True) sess1 = tf.Session(config=config) sess2 = tf.InteractiveSession(config=config)
ConfigProto的功能:配置类似并行的线程数、GPU分配策略、运行超时时间参数等。
第一个常用的参数allow_soft_placement。为True的时候,在某些条件成立时下,GPU运算可以放在CPU上进行;
第二个常用参数log_device_placement。当为True的时候,日志会记录每个节点被安排在哪个节点上以方便调试。生产环境中设为False,以减少日志量。
四、TF实现神经网络
4.1神经网络简介
使用神经网络解决分类问题主要有以下四个步骤:
1、提取问题中实体的特征向量作为神经网络的输入。
2.定义神经网络的结构,并定义如何从神经网络的输入得到输出。这就是神经网络的前向传播算法。
3.通过训练数据来调整神经网络中参数的取值,这就是训练神经网络的过程。主要利用反向传播算法。
4.使用训练好的神经网络来预测未知的数据。
4.2 前向传播算法简介以及TF实现前向传播算法。
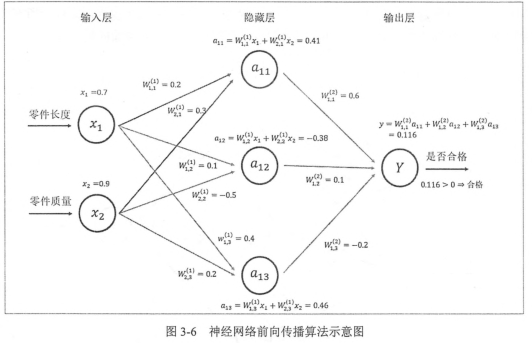
将输入x1和x2组织成一个1X2的矩阵x = [x1,x2],而w1组织成一个2X3的矩阵:

TF实现前向传播
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
其中malmul函数实现了矩阵乘法的功能。
4.3 神经网络参数与TensorFlow变量
TF声明一个2X3矩阵变量的方法:
weights = tf.Variable(tf.random_normal([2,3],stddev =2))
其中tf.random_normal([2,3],stddev =2会产生一个2X3的矩阵,矩阵中元素均值为0,标准差为2的随机数。
TF支持的随机数生成器

TF也支持通过常数来初始化变量。

bias(偏置项)通常会使用常数来初始化。
baises = tf.Variable(tf.zeros([3]))
TF还支持通过其他其他变量的初始值来初始化新的变量
w2 = Variable(weights.initiialized_values() )
w3 = Variable(weights.initiialized_values() *2.0 )
一个前向传播算法的样例:
import tensorflow as tf #声明w1,w2 两个变量,通过seed设定随机种子 w1 = tf.Variable(tf.random_normal([2,3],stddev=1.0 ,seed =1 )) w2 = tf.Variable(tf.random_normal([3,1],stddev=1.0 ,seed =1 )) #暂时将输入的誊正向量定义为一个常量,这里的X是一个【1,2】矩阵 x = tf.constant([[0.7,0.9]]) #通过前向传播算法得到输出y hd = tf.matmul(x,w1) y = tf.matmul(hd,w2) sess = tf.Session() #初始化w1和w2 sess.run(w1.initializer) sess.run(w2.initializer) print(sess.run(y)) sess.close()
这里调用变量的初始化过程比较麻烦,TF提供了一种便捷的方法:initialize_all_variables()
init_op = tf.initialize_all_variables()
sess.run(init_op)
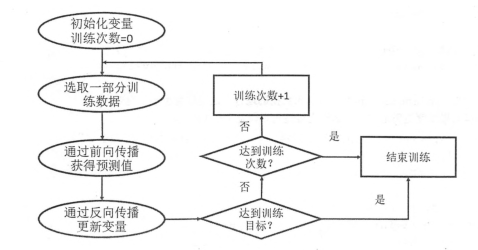
4.4 通过TensorFlow训练神经网络模型
网络训练的流程图
为了避免大量的存放输入的常量,可以用placeholder
import tensorflow as tf #声明w1,w2 两个变量,通过seed设定随机种子 w1 = tf.Variable(tf.random_normal([2,3],stddev=1.0 ,seed =1 )) w2 = tf.Variable(tf.random_normal([3,1],stddev=1.0 ,seed =1 )) #用placeholder定义存放输入数据的地方,维度可以不用定义,但维度确定,可减少出错率 x = tf.placeholder(tf.float32,shape=(1,2),name= 'input') #通过前向传播算法得到输出y hd = tf.matmul(x,w1) y = tf.matmul(hd,w2) sess = tf.Session() #初始化w1和w2 init_op = tf.global_variables_initializer() sess.run(init_op) #计算过程,需要feed_dict来制定x的值 print(sess.run(y,feed_dict={x:[[0.7,0.9]]})) sess.close()
定义反向传播算法
#定义损失函数来刻画预测值和真实值的差距 cross_entropy = tf.reduce_mean(y* tf.log(tf.clip_by_value(y,1e-10,1.0))) #定义学习率 learning_rate = 0.001 #定义反向传播算法来优化神经网络中的参数 train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) sess.run(train_step)
4.5跑一个完整的NN的样例
在模拟数据集上训练神经网络,实现一个二分类的问题
import tensorflow as tf from numpy import random as rd #定义batch的大小 batch_size = 8 #定义神经网络的参数 w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) # shape的一个维度用None方便使用不大的batch。在训练时需要把数据分成较少的batch,测试时可以一次性使用全部数据 x = tf.placeholder(tf.float32,shape=(None,2),name='x_input') y_ = tf.placeholder(tf.float32,shape=(None,1),name='y_input') #学习率 lr = 0.001 #定义前向传播过程 a = tf.matmul(x,w1) y = tf.matmul(a,w2) # 定义loss和bp cross_entropy = -tf.reduce_mean(y_* tf.log(tf.clip_by_value(y,1e-10,1))) train_step = tf.train.AdamOptimizer(lr).minimize(cross_entropy) #生成模拟数据集 rdm = rd.RandomState(1) dataset_size = 128 X = rdm.rand(dataset_size,2) Y = [[int(x1+x2 < 1)] for( x1,x2) in X ] print(X,Y) #创建会话来运行TF with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) print(sess.run(w1)) print(sess.run(w2)) #设定训练次数 epho = 5000 for i in range(epho): #每次选取batch个样本进行训练 start = i*batch_size % dataset_size end = min(start + batch_size,dataset_size) #用样本训练神经网络,更新参数 sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]}) if i %1000 ==0: #每隔一段时间计算在所有数据上的交叉熵斌输出 total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y}) print("After %s epho ,total_cross_entropy is %s"%(i,total_cross_entropy)) print(sess.run(w1)) print(sess.run(w2))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号