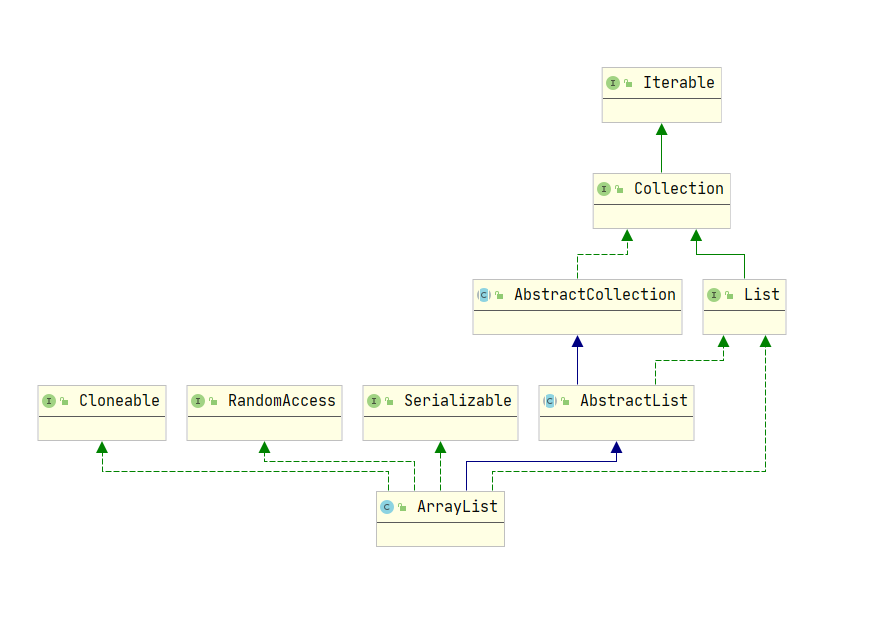
JAVA集合框架 - List
List集合
接口说明:(整理自有道云翻译jdk11)
有序集合(也称为序列)。此接口的用户可以精确控制每个元素在列表中的插入位置。用户可以通过其整数索引(在列表中的位置)访问元素,并在列表中搜索。
List与Set不同,列表通常允许重复元素。更正式地说,列表通常允许el和e2元素相同,即el.equals(e2),如果允许空元素,则通常允许多个空元素。
通过在用户试图插入相同数据时抛出运行时异常,可以实现禁止重复元素的列表,但是并不推荐这样做。
List接口在迭代器、add、remove、equals和hashCode方法的注释上放置了超出集合接口中指定的其他规定。为了方便起见,这里还包括了其他继承方法的声明。
List接口提供了四种方法,用于对List元素进行位置(索引)访问。注意,这些操作的执行时间可能与某些实现(例如LinkedList类)的索引值成比例。因此,如果调用方不知道具体的实现,迭代列表中的元素通常比通过它建立索引更可取。
List接口提供了一个特殊的迭代器,称为ListIterator,除了迭代器接口提供的正常操作之外,它还允许插入和替换元素以及双向访问。还提供了一种方法来获取从列表中指定位置开始的列表迭代器。
List接口提供了两个方法来搜索指定的对象。从性能的角度来看,这些方法应该谨慎使用。在许多实现中,它们将执行代价高昂的线性搜索。
List接口提供了两种方法来有效地在List中的任意点插入和删除多个元素。
注意:虽然允许列表将自己包含为元素,但还是要特别注意:equals和hashCode方法不再在这样的列表中定义得很好。有些列表实现对其可能包含的元素有限制。
例如,有些实现禁止空元素,有些实现对元素的类型有限制。试图添加不符合条件的元素会引发未检查异常,通常是NullPointerException或ClassCastException。试图查询不符合条件的元素的存在可能会引发异常,或者只返回false:一些实现将显示前一种行为,而另一些实现将显示后一种行为。更一般地说,尝试对一个不可访问的元素执行操作,该元素的完成不会导致将一个不符合条件的元素插入到列表中,这可能会引发异常,也可能会成功,这取决于实现的选择。在此接口的规范中,此类异常被标记为“optional”。
List集合常用子类:
ArrayList- 底层数据结构是数组。线程不安全LinkedList- 底层数据结构是链表。线程不安全Vector- 底层数据结构是数组。线程安全
System.arraycopy
ArrayList中大多数操作数组的方法都是通过System.arraycopy来实现的.
需要注意的点:
System.arraycopy是JVM 提供的数组拷贝实现.- 复制策略为浅复制, 如果原数组中指定的元素是除
String之外的引用类型, 且发生了变化, 目标数组中也会收到影响. - 该操作线程不安全.
- 因为是直接操作内存,所以相较于其它复制操作, 效率很高.
将 src 中从下标 scrPos 开始, 复制 length 个元素到从 下标为destPos开始的 desc 数组中.
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
ArrayList
ArrayList本质上是对数组的封装.
arrayList中的属性
private static final long serialVersionUID = 8683452581122892189L;
// 默认初始容量为10
private static final int DEFAULT_CAPACITY = 10;
// 当用户指定空数组时返回的空数组实例
private static final Object[] EMPTY_ELEMENTDATA = {};
// 用户不进行具体参数指定时, 默认返回的空数组实例
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 保存添加到ArrayList中的元素, 实际为空的数组第一次添加时会扩容.
// non-private to simplify nested class access
transient Object[] elementData;
// ArrayList的大小(它包含的元素的数量)
private int size;
构造方法
ArrayList的构造方法比较简单,就是根据传入参数的情况建立一个初始数组.传0或者不传值就是默认的空数组.
传入集合的话就根据原来的数组拷贝出来的一个数组.
// 构造一个指定初始长度的数组
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//实际上底层结构就是个数组..
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 默认的空数组, 会在第一次添加数据时进行扩容
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 这里源码说的是:构造一个初始容量为10的空列表。
// 实际上还是整个空数组, 会在第一次添加数据的时候进行扩容, 扩容成长度为10的数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 构造一个列表,其中包含指定集合的元素,按集合的迭代器返回元素的顺序排列
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// defend against c.toArray (incorrectly) not returning Object[]
// (see e.g. https://bugs.openjdk.java.net/browse/JDK-6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
add方法
ArrayList中提供了四种add方法, 分别是:
- 将指定的元素追加到末尾的
public boolean add(E e) - 在指定位置插入数据的
public void add(int index, E element). - 末尾添加整个集合
public boolean addAll(Collection<? extends E> c) - 指定位置添加整个集合
public boolean addAll(int index, Collection<? extends E> c)
add(E e)
// 这是我们写代码时调用的方法
public boolean add(E e) {
// 增加操作次数
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
// 比较数组当前已放入元素数量(成员变量size)和数组长度
// 如果已经没有空间放元素就进行扩容.
// 如果创建的是默认的空数组的话, 第一次必然会触发扩容
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
// Arrays.copyOf 底层实现是调用的System.arraycopy()本地方法
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
// 数组扩容策略(如何计算扩容后的大小)
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 默认扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 验证是否扩容成功
if (newCapacity - minCapacity <= 0) {
// 空数组第一次扩容
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// 默认返回10, 如果是addAll()方法的参数长度超过10, 就返回参数长度
return Math.max(DEFAULT_CAPACITY, minCapacity);
// 请求的数组大小超过VM限制
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
// 尽可能的限制不超过最大数组限制. 最多不能超过 Integer.MAX_VALUE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE)
? Integer.MAX_VALUE
: MAX_ARRAY_SIZE;
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
add(int index, E element)
由以下源码可以看出, 在指定位置插入数据必然会引发数组的复制. 会随着数据量的增加而占用更多的资源进行内存操作.
所以如果对在非末尾插入/删除数据的情况很多的场景下,不建议用ArrayList.
// 这是我们写代码时调用的方法
// 在指定位置插入数据
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
// 判断数组是否已满, 满的话去扩容
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
// 进行数组复制.
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}
// 检查传入参数是否正确
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
addAll(Collection<? extends E> c)
addAll方法在ArrayList中的实现还是通过System.arraycopy()来处理数组.
System.arraycopy()在数组长度较小时的性能很强悍.但是随着数组的增长不可避免的会造成更多的资源浪费.
public boolean addAll(Collection<? extends E> c) {
// 转换成数组
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
// 判断是否需要扩容
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
// 实际上还是调用System.arraycopy()进行数组复制
System.arraycopy(a, 0, elementData, s, numNew);
size = s + numNew;
return true;
}
public Object[] toArray() {
// 校验数组的操作次数
checkForComodification();
// 这里跟到最底层还是调用System.arraycopy()进行数组操作
return Arrays.copyOfRange(root.elementData, offset, offset + size);
}
addAll(int index, Collection<? extends E> c)
这方法在本质上与addAll(Collection<? extends E> c)相同,还是利用System.arraycopy()对数组进行操作.
public boolean addAll(int index, Collection<? extends E> c) {
// 判断下标是否合法
rangeCheckForAdd(index);
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
// 计算是否需要扩容, 扩容的话默认扩容为整体长度的1.5倍
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
// 计算是否需要先移动数组, 腾出来需要的位置
int numMoved = s - index;
if (numMoved > 0)
System.arraycopy(elementData, index,
elementData, index + numNew,
numMoved);
// 最终进行数组复制
System.arraycopy(a, 0, elementData, index, numNew);
size = s + numNew;
return true;
}
get/set 方法
get/set方法都是根据数组
get方法
get方法就很简单, 直接根据下标从数组中读取对应位置的元素.
public E get(int index) {
// 判断想获取的下标是否越界了
Objects.checkIndex(index, size);
return elementData(index);
}
// 位置访问操作
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
set方法
set方法跟get相同, 直接根据下标操作数组.然后返回被替换的元素.
public E set(int index, E element) {
// 判断下标是否越界
Objects.checkIndex(index, size);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
// 位置访问操作
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
remove 方法
remove方法分为单个删除和批量删除.
单个元素删除也是检查下标之后,计算要移动的个数, 再移动数组, 如果要删除的是最后一个, 就跳过复制直接置为null.
批量删除简单来说就是循环后对数组的元素进行移动排序后,删除掉多余的元素.但是本身算法的设计很值得看看.
单个元素删除:
// 按标志位删除
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
// 按元素删除
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
// 非空的时候, 如果不是基本类型的话
// 注意需要依赖元素本身的.equals()方法重写.
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
批量删除
// 批量删除
public boolean removeAll(Collection<?> c) {
return batchRemove(c, false, 0, size);
}
/**
* 批量删除方法
* @param c 要比对的内容
* @param complement 所进行运算是否为补集
* @param from 起始位置
* @param end 结束位置
* @return
*/
boolean batchRemove(Collection<?> c, boolean complement,
final int from, final int end) {
Objects.requireNonNull(c);
final Object[] es = elementData;
int r;
// Optimize for initial run of survivors
// 循环遍历本身数组
for (r = from;; r++) {
if (r == end)
return false;
// 找出原集中的匹配运算规则的起始位置
if (c.contains(es[r]) != complement)
break;
}
int w = r++;
try {
// 循环所有起始位置之后的元素
// 把所有符合条件的元素按顺序排到起始位置之后
for (Object e; r < end; r++)
if (c.contains(e = es[r]) == complement)
es[w++] = e;
} catch (Throwable ex) {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
System.arraycopy(es, r, es, w, end - r);
w += end - r;
throw ex;
} finally {
modCount += end - w;
// 删除所有多余的元素
shiftTailOverGap(es, w, end);
}
return true;
}
private void shiftTailOverGap(Object[] es, int lo, int hi) {
System.arraycopy(es, hi, es, lo, size - hi);
// 移动数组后, 挨个置为null
for (int to = size, i = (size -= hi - lo); i < to; i++)
es[i] = null;
}
删除中运用的contains()方法:
一路跟下去发现就是遍历...
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
迭代器:
ArrayList中提供了迭代器, 里面用到了fail-fast机制来尽可能保证遍历的是没有被操作过的数组(遍历过程中被操作就报错),同时提供了下标校验和删除操作.
比自己for循环要安全很多.也能规避一些奇怪的异常.效率方面试了一下循环打印100w条uuid,慢了大概7%左右. 所以如果数据量不太大的话,最好还是用ArrayList提供的Iterator来遍历.
for循环 --- 所用时间(ms) --- 9326
Iterator循环 --- 所用时间(ms) --- 10079
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
// prevent creating a synthetic constructor
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
public void forEachRemaining(Consumer<? super E> action) {
......
......
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
序列化
ArrayList中, 存储数据的数组被transient修饰, 意味着该结构不能序列化.
所以ArrayList自己实现了序列化的方法.
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioral compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// like clone(), allocate array based upon size not capacity
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
// Read in all elements in the proper order.
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}
ArrayList 总结:
- ArrayList是基于动态数组实现的, 本质上存储结构是个数组.
- ArrayList需要连续的内存空间来存储.
- ArrayList默认创建空数组, 默认的初始化容量是10,每次扩容时候增加原先容量的一半(扩容后不超过
Integer.MAX_VALUE - 8), 最大不能超过Integer.MAX_VALUE最大值. - ArrayList除了在末尾增删单个元素外,其它对元素的操作都需要利用
System.arraycopy()进行数组复制。 - ArrayList线程不安全, 如果需要线程安全的场景.相对于
Vector, 更建议使用Collections.synchronizedList(List<T> list)来进行代理操作. - 删除元素时不会减少容量, 只会把元素放到末尾再置为null,若希望减少容量需要调用
trimToSize() - ArrayList的读取速度很快, 因为获取到下标后直接从数组中读取下标的内容就可以.
LinkedList
LinkedList本质上是记录头尾节点的双向链表.
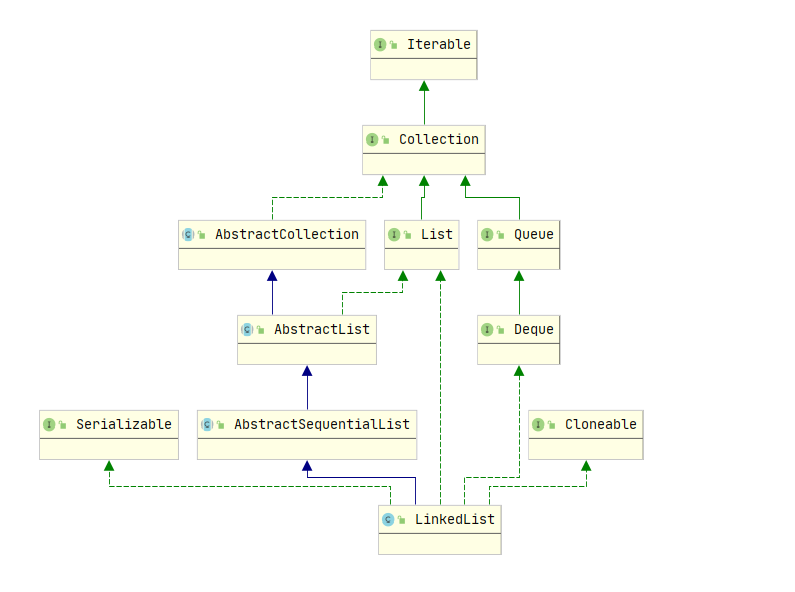
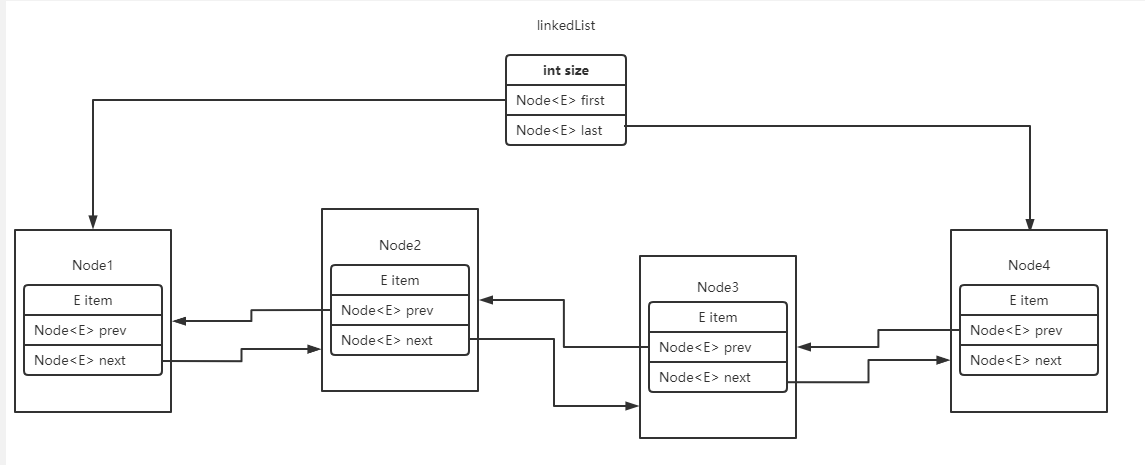
linkedList 中的属性
linkedList中的属性很简单,除了继承过来的属性外,只有链表长度和指向第一个 / 最后一个节点的指针.
比较重要的概念是LinkedList中节点的概念, 节点(Node<E>)是一个内部类.结构就是本身元素, 加上上一个/下一个节点的指针.
不知道其他人有没有我最开始学习时的一个很傻的困惑,我第一次看这个结构的时候,总觉得这是个嵌套结构, 会一层套一层跟套娃似的把每个节点的数据一层层包裹起来.但是实际上, LinkedList和Node<E>中的节点对象, 存储的都是一个内存地址, 而不是实际的内存. 可以理解为链式结构中的箭头.
// 链表长度
transient int size = 0;
/**
* 指向第一个节点的指针
*/
transient Node<E> first;
/**
* 指向最后一个节点的指针
*/
transient Node<E> last;
// LinkedList中的内部类 - 节点
private static class Node<E> {
// 该节点的元素
E item;
// 指向下一个节点的指针
Node<E> next;
// 指向上一个节点的指针
Node<E> prev;
// 构造方法
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
linkedList 中主要方法
linkedList中的方法大多都是对几个公共方法的简单封装,看懂了这些公共方法,基本上对于LinkedList的数据结构和特点以及操作时的时间复杂度就都有一个明确的认识了.
/**
* 将元素e连接为头结点
*/
private void linkFirst(E e) {
final Node<E> f = first;
// 创建新的Node对象, 将现在的头节点作为Node对象中的next.
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
// 如果没有节点, 那尾结点也是newNode
if (f == null)
last = newNode;
else
// 否则给原头结点中的prev赋值, 指向新的头结点
f.prev = newNode;
// 增加连接数量
size++;
// 增加操作数
modCount++;
}
// 将元素e链接为尾结点, 和链接到头节点逻辑相同
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 将元素e链接在元素succ之前(在元素succ之前插入e)
// 这里就体现出LinkedList插入节点的操作为什么很快,因为在知道具体节点的情况下,
// 只需要修改一下对应节点的引用就可以了.
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
// 从linkedList中断开包括f在内,所有在f之前的节点
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
// 头结点指向到f的下一个节点
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
// 从linkedList中断开包括f在内,所有在f之后的节点
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
// 从链表中断开节点x
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
// 检验下标是否是存在的节点
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
// 检验传入的下标是否是可以插入的位置
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
// 构建错误信息
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
// 检查是否为已存在的节点
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 检查是否为可插入的节点
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 返回指定位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
// 怎么样都逃不了需要循环节点.所以链表结构,对于操作中间的节点,查询的时间复杂度为O(n)
// 如果可以,尽量避免让链表的长度过长...
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 转换为数组
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
LinkedList 中的构造方法
linkedList的默认构造方法没什么新意,就是默认一个空链表.
带集合参数的构造,跟到最后是一个循环插入节点方法.
// 默认创建一个空链表
public LinkedList() {
}
/**
* 构造一个包含指定集合的链表集合(LinkedList)
*
* @param c 进行浅复制的集合
* @throws NullPointerException 如果指定集合为空会抛出空指针异常
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 检查下标是否可插入
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
// 如果链表为空
if (index == size) {
succ = null;
pred = last;
} else {
// 找到节点
succ = node(index);
pred = succ.prev;
}
// 循环插入
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
// 判断是否为头结点
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
add / get / set / remove
public boolean add(E e) {
linkLast(e);
return true;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
序列化/反序列化
同ArrayList一样, LinkedList也在很多属性上加上了transient关键字拒绝序列化, 也同样提供了序列化和反序列化的方法.
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}
线程安全
LinkedList当然是线程不安全的.在官方注释中, 建议的线程安全方式为利用Collections工具类提供的方法进行代理(设计模式 - 代理模式):
List list = Collections.synchronizedList(new LinkedList(...));
里面对常见的增删改查等方法进行了synchronized关键字修饰.还可以指定锁住的对象.
但是要注意, 如果要进行迭代/函数式编程(Stream)的话, 必须手动实现锁.
部分源码如下:
/**
* @serial include
*/
static class SynchronizedCollection<E> implements Collection<E>, Serializable {
private static final long serialVersionUID = 3053995032091335093L;
final Collection<E> c; // Backing Collection
final Object mutex; // Object on which to synchronize
SynchronizedCollection(Collection<E> c) {
this.c = Objects.requireNonNull(c);
mutex = this;
}
SynchronizedCollection(Collection<E> c, Object mutex) {
this.c = Objects.requireNonNull(c);
this.mutex = Objects.requireNonNull(mutex);
}
public int size() {
synchronized (mutex) {return c.size();}
}
......
public Iterator<E> iterator() {
return c.iterator(); // Must be manually synched by user!
}
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}
public boolean remove(Object o) {
synchronized (mutex) {return c.remove(o);}
}
......
// Override default methods in Collection
@Override
public void forEach(Consumer<? super E> consumer) {
synchronized (mutex) {c.forEach(consumer);}
}
@Override
public Stream<E> stream() {
// 写的明明白白让你自己去实现!
return c.stream(); // Must be manually synched by user!
}
.....
}
总结:
- LinkedList自己实现了序列化和反序列化,因为它实现了writeObject和readObject方法。
- LinkedList是一个以双向链表实现的List。
- LinkedList还是一个双端队列,具有队列、双端队列、栈的特性。
- LinkedList在首部和尾部添加、删除元素效率高效,在中间添加、删除元素效率较低, 但是相对于ArrayList, 还是更好一些, 至少在节点贼多的时候不用去移动大量的内存.
- LinkedList虽然实现了随机访问,但是效率低效,不建议使用。
- LinkedList是线程不安全的。
- LinkedList也是有快速失败机制.
Vector
官方注释:
从Java 2 platform v1.2开始,这个类经过了改进以实现List接口,使其成为Java集合框架的成员。与新的集合实现不同,Vector是同步的。如果不需要线程安全的实现,建议使用ArrayList代替Vector。
内部代码基本上就是ArrayList粗暴的加上synchronized关键字.不建议使用. 如果需要保证ArrayList线程安全的话,建议使用或者参考Collections.synchronizedList()来对ArrayList进行代理.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号