驾校理论考试系统之数据提取三(2)

DocToDataXml.zip 1
目的:将各个word(选择,判断,多选)中的数据填入data.xml
项目:微软开源CodePlex, PowerTools for Open XML
PowerTools for Open XML
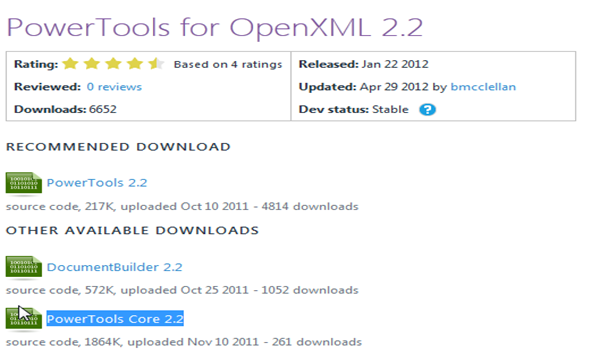
下载PowerTools Core 2.2
解压缩 ,然后打开
,然后打开  ,然后设置未启动项目
,然后设置未启动项目
OpenXmlPowerTools.zip 1 OpenXmlPowerTools.sln
然后分析代码,我们可以看到在ExampleHtmlConverter03Images项目内有一个Test.docx文档,这是用来测试的文档。运行看看能不能正常运行。
可以看到在项目ExampleHtmlConverter03Images中生成了test.html文档。
在这里我们要补一补,html语法和open xml的用法。
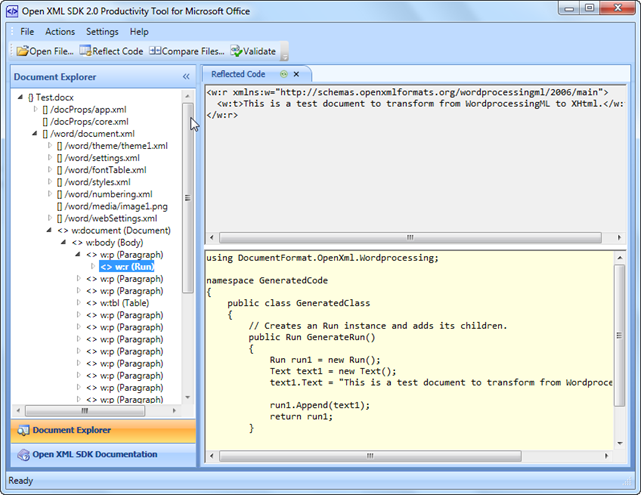
首先要安装Open xml SDK,有106.4 MB大小,其中安装目录中有一个工具叫做OpenXmlSdkTool,可以查看Word文档,docx,我们用来查看一下Test.docx。
点击Open File找到Test.docx,然后将树状节点图展开到下图形式
reflect code,就会出现出现代码,这些都是自动生成的,我们会发现,原来我们经常用到的docx居然是这样的,各一个XML文档没有太大区别。
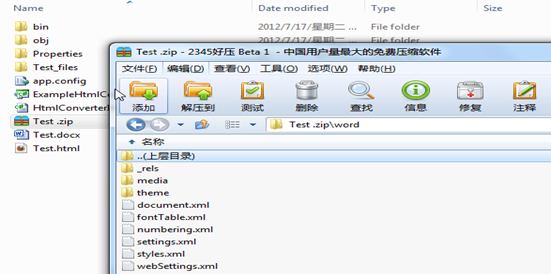
其实,还有你不知道的,那就是word文档其实是一个zip,压缩文件。
我们将Test.docx转换成Test.zip,然后打开压缩文件如图:
打开其中的document.xml,发现
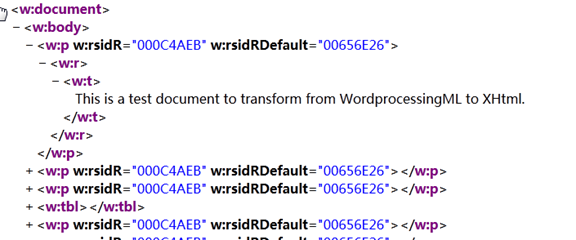
第一个W:p中w:t中的那句话对应,word文档中的第一句话。我们猜测,W:p,p指的是Paragraph一段,而W:t,t则是Text文本。正如前面那个工具展示的那个图。
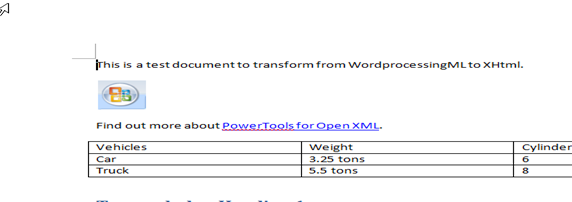
再来看看已经转换好的html文档,

我们发现,与document.xml显示的类似,第一句话也被包含在<p></p>中,而且代码简洁了不知道多少。
由此可知,要把Docx转化为html无非是把图片和段中的文字提取出来,然后显示在html的<p></p>和<img/>中。
既然这样,那我们为什么只要找到项目ExampleHtmlConverter03Images,提取段文字和图片的地方,然后将其填入data.xml中就达到了我们的目的了。
我们现在来断点调试吧!
值得注意的是,你可能要补一下LINQ,语言集成查询(Language INtegrated Query)方面的知识!!
在main方法出设置一个断点,按F11会达到这个地方,如图,我们发现=>这个图标看不懂,其实这是linq中的语法,表示的是将imageInfo
这个参数传到=>后面的语句进行循环处理,就是有多少个imageInfo就处理多少次。随后我们发现关键词,png,jpeg,这提示我们下面的语句是在保存图片,到html文件中的<img/>中。
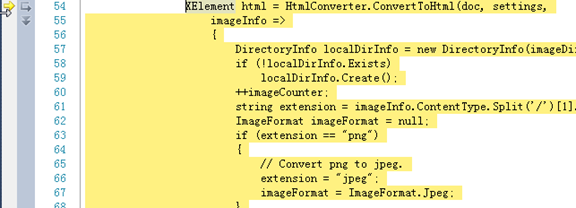
看到黄色区域最后部分,我们发现的确是这样子的,兴奋了吧!!哈哈

再来看看是如何保存<p></P>段文字的,继续调试
既然是htmlConverter,所以我们首先在 HtmlConverter.cs中查看,发现

这里这段话,Transform every paragraph,猜测应该是这吧,设个断点试试,不断F11
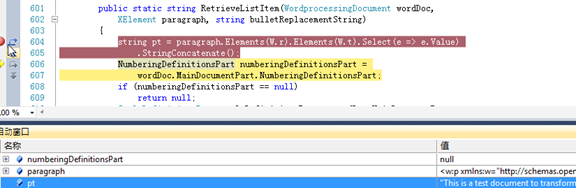
这是我们惊喜的发现,居然有一个变量pt与文档中的第一句话是一样的,这是我们要找的段落文字找到了!
现在我们该考虑怎么将这些图片和文字保存到data.xml中了!!!
我们新建一个C#控制台应用程序,DocToDataXml。
将先前项目ExampleHtmlConverter03Images中需要的HtmlConverterImages.cs文件和OpenXmlPowerTools项目中的所有cs文件添加到项目DocToDataXml。并且添加缺少的dll引用和文件Test.dll.并且删除program.cs,以避免有两个入口点。
调试是否成功运行。调试成功后!
再来分析一下试题,例如一个单选文档中有很多道题目,如果要处理这些数据,我们需要一道题一道题的处理,那么必须有一个标志,来识别是否一道题已经处理完了,观察题目可以清楚的发现,每道题前面都有1.,2.,3.。。。。。等等,那么就这个标志,不知道在openxml是怎么区分了,我们用openxml tool来看看!!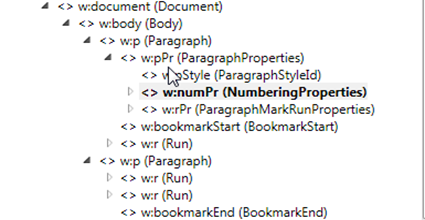
为了对比有1.,和没有的区别,新建一个docx,一个带编号,一个不带
- 呵呵
呵呵
用openxml tool查看:发现带编号的段落,多段属性,属性中又有编号属性,由此可区分!!
现在我们来正式处理试题文档,复制所有试题到项目bin/debug目录下进行处理!!修改HtmlConverterImages.cs源文件中修改
string sourceDocumentFileName = @"驾校考试试题\安全行车常识\安全避让\单选.docx";
,运行成功后,打开单选.html,发现出现乱码,说明需要修改最后保存html文件的格式,所以修改HtmlConverterImages.cs源文件最后这段代码,添加Encoding.UTF8
File.WriteAllText(fileInfo.Directory.FullName + "/" + fileInfo.Name.Substring(0,
fileInfo.Name.Length - fileInfo.Extension.Length) + ".html",
html.ToStringNewLineOnAttributes(),Encoding.UTF8);
修改后得到预期中的html文件
接下来,定义保存一道题目的变量在
在Program类中定义静态变量数组str和静态变量图片文件名
public static ArrayList str = new ArrayList();
public static string imageFileName;
在先前找到的保存<p></p>的地方ListItemRetriever.cs类,方法RetrieveListItem
中添加如下代码,用来保存题目和选项。
if (pt != " " && pt != "" && pt != " " && pt != " " && pt != " ")
{
Console.WriteLine(pt);
Program.str.Add(pt);
}
去掉main方法中 string imageFileName = imageDirectoryName + "/image" +
imageCounter.ToString() + "." + extension;
前面的string因为我们已经在此类中定义了,相同的静态变量!以此来保存
图片文件地址!!
提示:由于代码行比较多,可以定义书签,按两下ctrl –k,
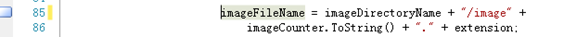
左边出现方形框,提示此处为书签,在此文件任意位置,按F2即可跳到此处!!
在HtmlConverter.cs类,方法ConvertToHtmlTransform添加如下代码用来判断一道题是终结
//控制序号属性值,令其换行
if (element.Name == W.p)
{
if (element.Elements(W.pPr).Elements(W.numPr).FirstOrDefault() != null)
{
string numId = element.Elements(W.pPr).Elements(W.numPr).Elements(W.numId)
.First().FirstAttribute.Value;
if (numId == "1")
{
Console.Write("\n\n");
//如果str中已经插入了题目和选项,则调用InsertSomeNode写入data.xml,并将str和imageFileName清零
if (Program.str.Count > 1)
{
Console.WriteLine(Program.strFileName);
Program.str.Add(Program.imageFileName);
Program.InsertSomeNode(Program.str, Program.strFileName, Program.i++);
Program.imageFileName = null;
Program.str.Clear();
}
}
}
}
可以看到我们判断这道题是否结束是通过查找W.p -> w.pPr->numId == '1'来判断是否结束的!!
然后利用此方法
public static void InsertSomeNode(ArrayList str, string locateFullName, int NumId)
插入题目和选项及图片地址到data.xml!!
其中有些地方需要小幅改动,具体请查看源代码!
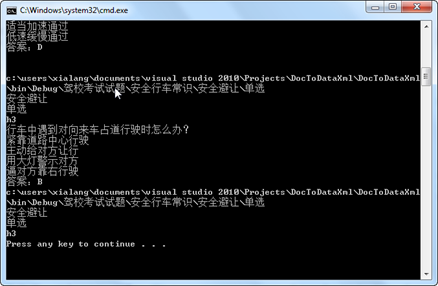
运行结果如下:

接下来,我们要做的是将所有文档一次都插入到data.xml!
那首先得检索到所有文档,我们使用此方法
//检索文档中特定格式的文档pattenr="*.docx"
public static void GetFiles(DirectoryInfo directory, string pattern)
{
if (directory.Exists || pattern.Trim() != string.Empty)
{
foreach (FileInfo info in directory.GetFiles(pattern))
{
//对单个文档的操作
//Console.WriteLine(info.FullName);
//Console.WriteLine(info.FullName.TrimEnd(".docx".ToCharArray())+".html");
DocToHtml(info.FullName);
//SpliteHtml(info.FullName.TrimEnd(".docx".ToCharArray()) + ".html");
}
foreach (DirectoryInfo info in directory.GetDirectories())
{
GetFiles(info, pattern);
}
}
}
至于docTOhtml,是将先前处理单个文档的过程全部放到一个方法中,
static void Main(string[] args)
{
string strPath ="驾校考试试题";
DirectoryInfo doc = new DirectoryInfo(strPath);
Program.GetFiles(doc, "*.docx");
}
Main方法中如上显示的,点击运行,彻底结束这个蛋疼的过程了!!
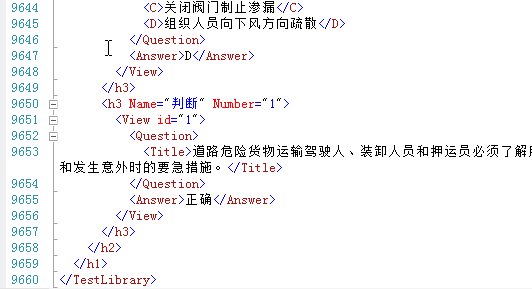
将近一万行的data.xml
不过我们注意到,好像还有动画文件名没有插入文档,下面在来看看吧!!

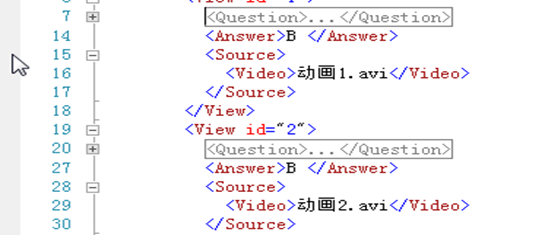
我们可以看到动画在<Title></Title>之间,我们要做的就是找到带有动画的节点Title
XmlNodeList Xlist = doc.SelectNodes("//Title");
用c#中的正则表达式提取动画名
foundMatch = Regex.Match(str, "动画[0-9]{1,}");
然后在把动画*.AVI插入到data.xml的source->Video中
XmlElement elem1 = doc.CreateElement("Video");
elem1.InnerText = foundMatch.Value + ".avi";//@"D:\驾校考试题库\AVI文件\" +
elem.AppendChild(elem1);
具体代码参看源文件!!
点击执行!
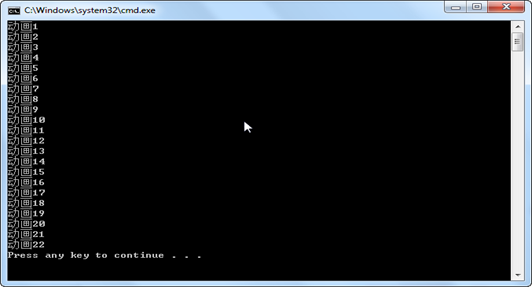
找到22个动画

 浙公网安备 33010602011771号
浙公网安备 33010602011771号