
MySQL索引(二)索引优化方案有哪些
在上一篇文章中,我们介绍了MySQL中常见的索引类型以及每种索引的各自特点,那么这篇文章带你来与我一起看一下聚集索引与二级索引的关系,最后在附上常见的索引优化方案。首先我们还是看一下聚集索引和二级索引的区别
聚集索引和二级索引区别
首先,每个Innodb引擎的表都有一个聚集索引,用于存储行数据,通常情况下,聚集索引也叫做主键索引。
-
如果一个表定义了主键,
Innodb就使用它作为聚集索引。因此我们要尽可能的为表添加一个主键,如果实在没有一个列是非空且唯一的可以作为主键列,建议添加一个自动递增的列作为主键列 -
如果表没有主键,
Innodb会选择第一个非空且唯一的列作为聚集索引 -
如果表既没有主键,也没有非空且唯一的索引,则
Innodb生成一个隐藏的聚集索引,GEN_CLUST_INDEX包含rowid值的列,数据行根据rowid排序,rowid是一个6字节的字段,随着数据插入而单调递增,也就是说,数据行根据rowid排序也就是根据插入顺序排序的
在上面,我们知道了主键索引也就是聚集索引,而且我们的日常工作中,查询如果根据主键查询都是很快的,那么聚集索引是如何提升查询效率的呢?
聚集索引如何提升查询效率
通过聚集索引访问一条数据是很快的,这是因为所有的行数据和索引保存在同一个页上。如果表数据特别大,相较于数据和索引保存在不同的页上的存储结构相比,Innodb大大节省了磁盘IO操作
现在我们知道了聚集索引之所以查询的快是因为要查询的行数据和索引都保存在同一个页上,也就减少了去磁盘查找数据的过程,那么二级索引呢,二级索引是如何与聚集索引关联的呢?
二级索引如何与聚集索引关联
聚集索引之外的其它索引全部被称为二级索引。在Innodb中,二级索引中的每条记录都包含主键列以及本身二级索引指定的索引列,在聚集索引中,Innodb使用此主键值查询该行的数据
如果主键较长的话,那么我们二级索引保存主键列时就会占用更多的空间,所以主键尽可能的短是有利的
读到这,我们应该已经知道了,聚集索引中所有记录与索引都保存在同一个页中,所以这也是聚集索引查询快的原因。二级索引没有保存当前记录的数据,只保存了主键列,所以在使用二级索引的时候会涉及到两步操作,即根据二级索引先定位主键列,然后根据主键列在聚集索引中查询数据返回。现在我们也知道了,通过二级索引查找会涉及到多一次交互的问题,那么这个点也是我们后文将要讨论的一个点,也就是所谓的回表。目前我们常用的索引优化方式有覆盖索引、最左前缀、索引下推,现在我们一起来详细看下索引的优化方式是怎么工作的
常用的索引优化方式
覆盖索引
首先我们还是新建一张表t,在k列建立索引,建表语句如下
create table t( id int primary key, k int not null default 0, s varchar(16) not null default '', index k(k) )engine=Innodb; # 加入测试数据 insert into t values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
在上文中,我们已经知道了聚集索引与二级索引的区别,所以在执行完上面的插入语句之后,数据的存储结构为两棵索引树,一棵主键索引树包含数据,一棵二级索引k的索引树
此处借鉴一下极客时间丁奇老师的索引结构图,此处放个不同数据结构存储图,这个网站不错,可以模拟数据结构的存储过程,给大家推荐一下,这块网站模拟的和丁奇老师的还是不一样,这块原因还不了解,对这块还不是很熟悉,有了解的可以评论区说一下,互相学习一下。本文还是以丁奇老师讲解的图为主
Arts and Sciences - Computer Science | myUSF![]() https://www.cs.usfca.edu/
https://www.cs.usfca.edu/
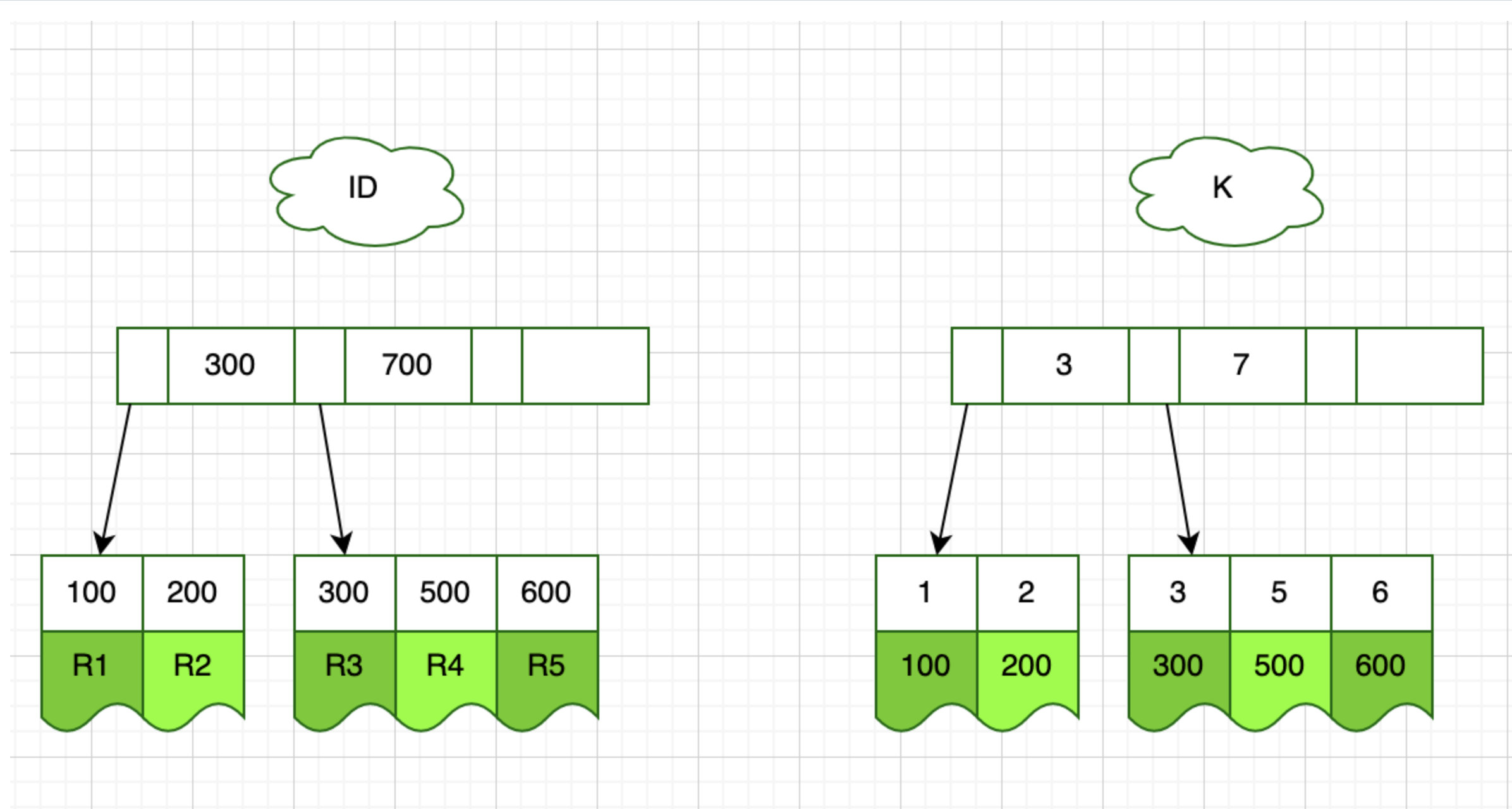
首先我们执行一条查询语句
select * from t where k between 3 and 5;
执行过程是这样的,首先到k索引树取到值为3的到主键索引树获取主键等于300的R3记录返回,然后取k索引树下一值5的主键500到主键索引树取500的记录R5,然后取k索引树下一个值6的主键600到主键树查询,发现6不符合条件,不再去主键树查询,返回结果
通过上面的分析,那么什么是覆盖索引呢,很简单,我们看下面两条sql语句
1、explain select * from t where k between 3 and 5; 2、explain select id from t where k between 3 and 5;
两条语句的执行分析结果如下

两条sql唯一的区别就是第一条sql会获取所有的字段,而第二条sql只获取id这个字段,而k索引树上已经保存了id的值,所以此时也就不用回表查询了,这种方式就是覆盖索引。因为覆盖索引可以大大减少搜索树的次数,所以使用覆盖索引是常用的优化手段
下面我们在看另一个使用覆盖索引的例子首先还是创建一张用户表,建表语句如下
CREATE TABLE `tuser` ( `id` int(11) NOT NULL, `id_card` varchar(32) DEFAULT NULL, `name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, `ismale` tinyint(1) DEFAULT NULL, PRIMARY KEY (`id`), KEY `id_card` (`id_card`), KEY `name_age` (`name`,`age`) ) ENGINE=InnoDB # 加入数据 insert into tuser values(1,'123456789012345678','test1','18',1),(2,'123456879012345677','test2','19',1),(3,'123456987012345676','test3','20',1),(4,'123456986012345675','user1','21',0),(5,'123456985012345674','user2','22',1),(6,'123456787012345673','user3','23',1),(7,'123456788012345672','admin1','24',0);
现在我们在表上建立了两个索引,身份证上一个索引,姓名和年龄一个索引。如果我们根据身份证获取用户信息,那么一个身份证索引就可以满足了,但是要是有一个高频的请求,根据身份证获取用户姓名,那么我们可以再创建一个身份证和姓名的联合索引,这样这些所有的根据身份证获取用户名的请求都可以在身份证姓名的联合索引上使用覆盖索引,那么这个索引也就是有意义的。
explain select * from tuser where id_card = '123456789012345678';
下面是根据身份证索引查询信息的执行结果

借助name,age的联合索引我们来分析一下最左前缀和索引下推
最左前缀
在上面的测试数据中,如果我们有以下查询语句
1、explain select * from tuser where name like 'test%'; 2、explain select * from tuser where name = 'test1';
第一条语句会在查询时获取name,age索引树上test开头的数据,是可以用到name_age的联合索引的(possible_keys),但是在这次查询中优化器没有选择使用索引(key是null)
第二条语句也是可以走name,age索引树的,而且选择走name_age的联合索引(possible_keys和key都是name_age)

通过上面两条sql语句,我们可以知道,不只是索引的全部定义,只要满足索引的最左前缀也是可以加速访问的。这个最左前缀可以是字符串索引的前n个字节,也可以是联合索引的 最左n个字段。
索引下推
开启关闭索引下推功能,默认情况下是开启的
SET optimizer_switch = 'index_condition_pushdown=off'; SET optimizer_switch = 'index_condition_pushdown=on';
那么什么是索引下推呢,还是上SQL语句
SET optimizer_switch = 'index_condition_pushdown=off'; explain select * from tuser where name like 'test%' and age = '18'; SET optimizer_switch = 'index_condition_pushdown=on'; explain select * from tuser where age = '18' and name like 'test%';
那么怎么看是否使用了索引下推呢,引用下官网 的一句话,Extra列显示Using index condition即使用了索引下推
-
EXPLAIN output shows
Using index conditionin theExtracolumn when Index Condition Pushdown is used. It does not showUsing indexbecause that does not apply when full table rows must be read.

所以,到底什么是索引下推呢,来看我分析
-
关闭索引下推优化时
首先或者所有name是test开头的数据,然后回表,判断age等于18的数据,然后返回数据
-
开启索引下推优化时
获取name是test开头的数据,并判断age等于18 的数据,然后剩余的数据拿到主键索引树回表查询返回
两者的区别就是回表的次数明显变少,在索引下推优化关闭时,会拿所有的主键去主键树获取数据,而开启之后,提前做判断,减少回表次数,这就是索引下推,也是工作中常用到的优化方式
_rowid 查看示例
非空,唯一,主键

create table test(a int primary key,b varchar(5)); insert into test values(1,'a'),(2,'b'),(3,'c'),(4,'c'),(5,'d'); select _rowid from test;
原文链接
参考链接
MySQL :: MySQL 8.0 Reference Manual :: 15.6.2.1 Clustered and Secondary Indexes
有不同索引类型之间的描述
MySQL :: MySQL 8.0 Reference Manual :: 13.1.15 CREATE INDEX Statement
b树索引与hash索引的对比
MySQL :: MySQL 8.0 Reference Manual :: 8.3.9 Comparison of B-Tree and Hash Indexes
index
MySQL :: MySQL 8.0 Reference Manual :: MySQL Glossary
geek

 浙公网安备 33010602011771号
浙公网安备 33010602011771号