BUAAOO——第三单元总结
一.总结分析自己实现规格所采取的设计策略
因为这一单元的作业难点在于性能方面,所以在理解了规格的要求后,具体实现时尽量优化方法的性能,首先是容器的使用,基本上使用hashmap实现O(1)查询,而不是arraylist的O(n)查询,然后本单元的方法中有许多统计社交网络中的部分属性的方法,如Network的queryBlockSum方法,Group的getValueSum,getAgeMean,getAgeVar方法,对于这些方法,我将它们的复杂度分摊到了加人和加关系的方法上,这样的设计基本上不会影响addPerson和addRelation性能,还可以大大优化上述方法的性能。
二.结合课程内容,整理基于JML规格来设计测试的方法和策略
本单元和前两个单元最大的区别在于,这一单元代码的架构已经由课程组给出,每个方法需要实现的内容也用JML规格说明了,因为本单元的各个方法都比较简单,测试其正确性只需要理解JML规格描述的内容后,阅读一下自己写的代码,基本上就可以确认方法的正确性,不需要像前两个单元用复杂的测试样例来测试,只需要观察代码就行。
三.总结分析容器选择和使用的经验
本单元的实验中使用了hashmap,hashset和linkedlist三种容器,本单元的person,group和message都有着唯一的id,用hashmap建立id到对象的结构应该是首选方法,并且本单元的方法中有许多查询某个对象是否存在的contains方法,和从容器中取出对应id的对象的get方法,如果使用arraylist的话,这些方法都会变成O(n)的复杂度,而使用hashmap的话就是O(1)复杂度了。hashset是在遍历所有点时用于判断某个点是否被遍历过,也就是使用其contains方法,不用arraylist也是因为arraylist的contains复杂度较高。linkedlist是在person的receivemessages中使用的,因为person接收到信息后会将其插入到接收信息容器的头部,arraylist头插的话需要将原有内容向后移动一个单元,而linkedlist不需要,所以使用性能更优秀的linkedlist。
四.针对本单元容易出现的性能问题,总结分析原因如果自己作业没有出现,分析自己的设计为何可以避免
首先是容器的使用,这在第三部分说明了,然后是各个容易出现性能问题的方法。
对于第一次作业来说,容易出现性能问题的方法只有isCircle方法和queryBlockSum方法,方法的规格如下
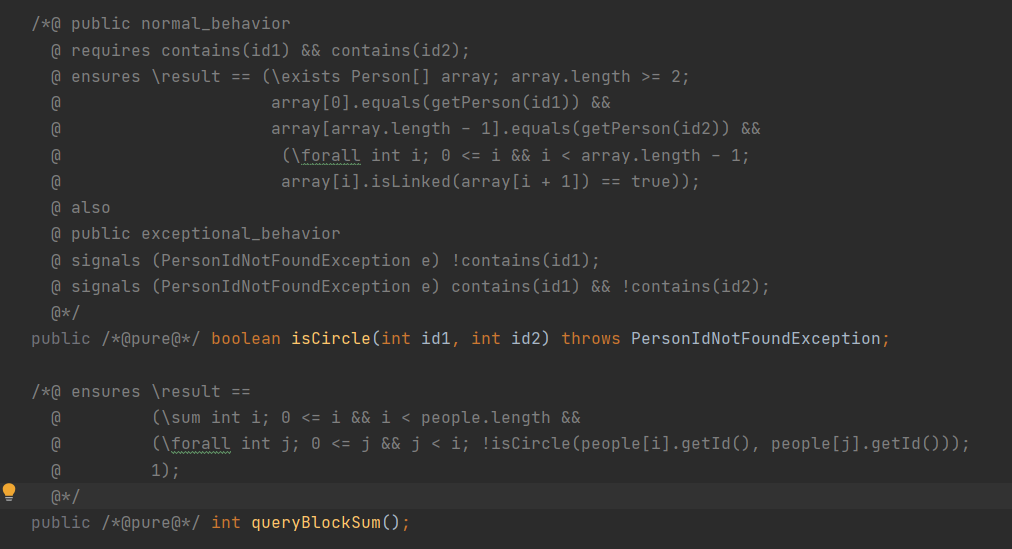
从isCircle的规格中不难看出,它判断的是两个人是否连通,如果以广度优先遍历的方法来实现这个方法,需要特判一下id1和id2相同的情况,但由于第一次作业并没有把人从社交网络中删除的方法存在(实际上,一直到本单元作业做完都没有出现这个方法,使得作业难度降低不少),所以我想到了用并查集来实现这个方法,并查集基本是O(1)的复杂度,比广度优先遍历快不少,而且也不需要特判两个id相同的情况。对于queryBlockSum方法,规格虽然很短,但是理解起来还是有点复杂,最后要求实现的是求出社交网络中连通块的个数,第一次作业不少人都直接按照规格的写法来实现这个方法,这样实现起来很简单,但复杂度也很高,虽然第一单元只有1000条指令,但考虑到之后指令数肯定会增加,为了避免之后修改这个方法,我在Mynetwork类中添加了属性blocksum,在每一次加人和加关系时更新这个属性,在执行queryBlockSum方法时直接返回这个属性。
第二单元新增了Group类和Message类,对于Message类相关的方法基本都是照着规格实现,不会有什么性能问题,Group类中下列3个方法可以优化。
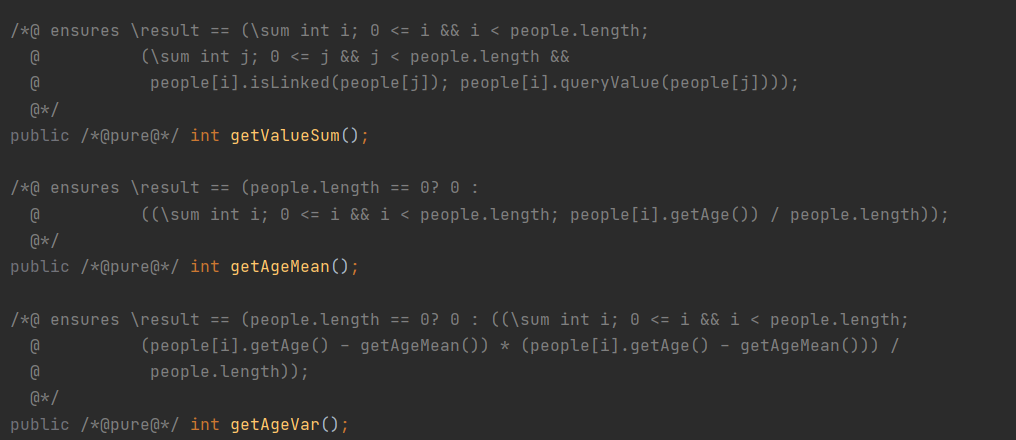
getAgeMean和getAgeVar如果普通的按照规格来实现的话是O(n)复杂度,但是我们可以定义两个属性,一个是组内所有人的总年龄,一个是组内所有人年龄平方的和,在向group中添加或删除人时更新这两个属性,在执行上述两个方法时,根据这两个属性可以实现O(1)的复杂度,相当于把原来O(n)的复杂度O(1)平摊到了addperson和delperson方法上,使得这两个属性O(1)维护,O(1)应答。而getValueSum方法根据规格是一个O(n^2)的方法,这个复杂度极可能导致超时,所以我采用相同的策略,定义了一个valuesum的属性,在增删人时更新这个属性,把这个O(n^2)复杂度O(n)的平摊到了addperson和delperson的方法上,使得这个属性O(n)维护,O(1)应答,valuesum这个属性还有一个坑点,就是在network中增加关系时,也要判断一下这个组的valuesum是否会增加。
对于第三次作业,最容易出现性能问题的肯定是sendindirectMessage方法了,它主要是求两个人之间的最短路径距离,如果用普通的dijkstra算法的话是O(n^2)的复杂度,这容易造成超时问题,所以我采用堆优化的dijkstra算法,把复杂度降低到O(nlog(n)),这样基本不会有性能问题。
五.梳理自己的作业架构设计,特别是图模型构建与维护策略
本单元的作业架构已经由课程组给出,总体架构和JML规格中描述的相同,图中的点就相当于是一个person对象,在addperson时新建一个person对象来维护,图的边相当于person类中的value属性,它存储那些和他连通的人之间的距离,在addrelation时更新这个属性,有点像是邻接表形式的构造图模型。在第三次作业时,我认为数组更好写dijkstra算法,所以新建了一个graph类,给每一个person一个数组下标,在addperson时给新加入的人下标维护,用两个hashmap维护图的边属性,在addrelation时更新,相当于复制了一个network里的图关系到graph中,这个类因为是第三次作业才加上去,前两次作业虽然也有很多可以用它实现的东西,但是我没有去修改那些代码,所以它唯一的优点是我可以用数组来写dijkstra。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号