2. 安装Spark与Python练习
一、安装Spark
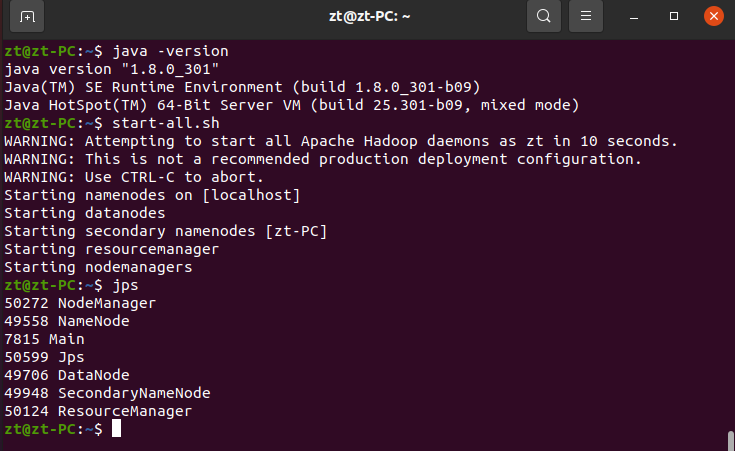
1. 检查基础环境hadoop,jdk
2. 下载spark
3. 解压,文件夹重命名、权限
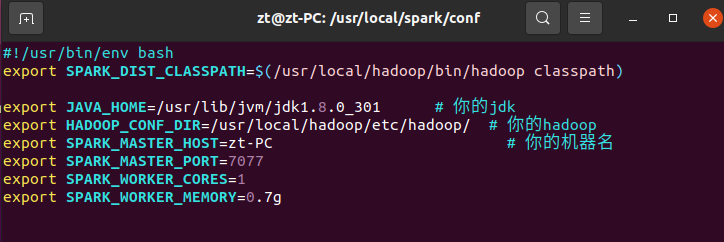
4. 配置文件
编辑该配置文件/usr/local/spark/conf/spark-env.sh,在文件中加上如下一行内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
保存配置文件后,就可以启动、运行Spark了
注:若需要使用HDFS中的文件,则在使用Spark前需要启动Hadoop
5. 环境变量
在~/.bashrc文件中加入
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.2-src.zip:PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$PATH:$SPARK_HOME/bin
注:环境变量中的py4j包必须与/usr/local/spark/python/lib/下的包命名一致

source ~/.bashrc # 环境变量生效
6. 试运行Python代码
启动pyspark,成功后在输出信息的末尾可以看到“>>>”的命令提示符
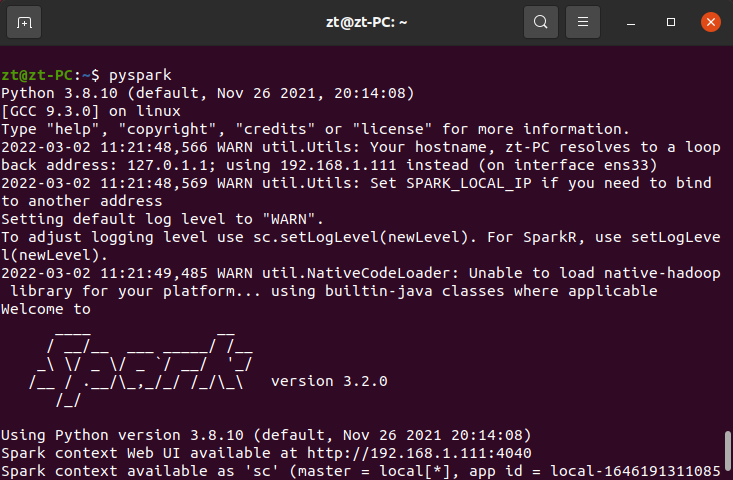
在里面输入python代码进行测试:
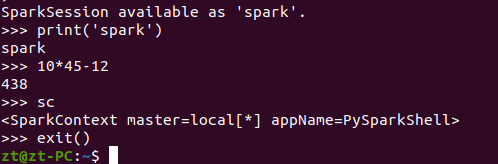
可以用以下命令或者Ctrl+D退出pyspark
exit()
quit()
二、Python编程练习—英文文本的词频统计
具体流程如下:
-
准备英文文本文件

图6 英文文本文件 -
读文件
txt = open("/home/zt/EN/ENText.txt", 'r').read() -
预处理:大小写,标点符号,停用词
txt = txt.lower() # 转为小写字母 for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': txt = txt.replace(ch, ' ') -
分词
words = TestTxt.split() -
统计每个单词出现的次数
for word in words: # 若字典中无当前词语则创建一个键值对,若有则将原有值加1 counts[word] = counts.get(word, 0) + 1 -
按词频大小排序
items = list(counts.items()) # 将无序的字典类型转换为有序的列表类型 items.sort(key=lambda x: x[1], reverse=True) # 按统计值从高到低排序(以第二列排序) -
结果输出并写文件
for i in range(len(items)): word, count = items[i] print("{0:<10}{1:>5}".format(word, count)) # 格式化输出词频统计结果 open('output.txt', 'a').write(word+"\t\t\t"+str(count)+"\n") # 写入output.txt中
点击查看完整代码
# 首先定义一个函数,用于提取文档并处理噪音
def getText():
txt = open("/home/zt/EN/ENText.txt", 'r').read()
txt = txt.lower() # 转为小写字母
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, ' ') # 将文本中的特殊字符替换为空格
return txt
TestTxt = getText()
words = TestTxt.split() # 获得分割完成的单词列表
counts = {} # 创建空字典,存放词频统计信息
for word in words:
# 若字典中无当前词语则创建一个键值对,若有则将原有值加1
counts[word] = counts.get(word, 0) + 1
items = list(counts.items()) # 将无序的字典类型转换为有序的列表类型
items.sort(key=lambda x: x[1], reverse=True) # 按统计值从高到低排序(以第二列排序)
for i in range(len(items)):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count)) # 格式化输出词频统计结果
open('output.txt', 'a').write(word+"\t\t\t"+str(count)+"\n") # 写入output.txt中
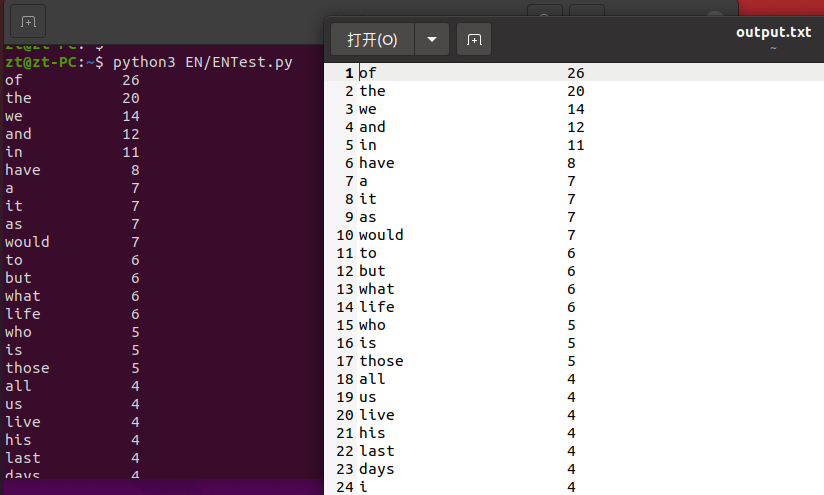
运行结果如下:
三、搭建编程环境
可选择的开发环境有两种:Jupyter Notebook和PyCharm
可以根据自己的编程习惯进行对应搭建,参考资料如下
- 使用Jupyter Notebook调试PySpark程序:http://dblab.xmu.edu.cn/blog/2575-2/
- 使用PyCharm参考:Ubuntu 16.04 + PyCharm + spark 运行环境配置:https://blog.csdn.net/zhurui_idea/article/details/72982598
这里用PyCharm进行开发环境的搭建:
-
下载pycharm: http://www.jetbrains.com/pycharm/, 安装Community社区版即可
-
在下载文件夹中解压(也可自定解压路径)
tar -zxvf pycharm-community-2021.3.2.tar.gz -C 目标路径 -
打开终端,进入
pycharm-2021.3.2/bincd pycharm-2021.3.2/bin -
执行pycharm.sh命令文件,开始安装;
sh ./pycharm.sh -
弹出PyCharm License Activation框,即PyCharm许可证激活。
a. 选择Activation Code激活方式,
c. 直接用浏览器打开地址 http://idea.imsxm.com ,点击该页面中的“获得注册码”,
d. 复制该注册码,然后切换回Activation Code界面,输入注册码
e. 然后点击“Activate”即可完成激活。
-
配置pycharm
新建一个新项目
在Run/Debug Configurations中找到自己的python运行环境路径
which python3 # 查看python路径注:一般情况下会在
/usr/bin/python3下 -
安装Py4j
Py4j库:通过Py4J,Python程序能够动态访问Java虚拟机中的Java对象,Java程序也能够回调 Python对象。
sudo pip install py4j注:没有pip的会报错,可以先自行下载pip
sudo apt update sudo apt install python3-pip验证安装过程,检查 pip 版本:
pip3 --version -
在pycharm中运行pyspark的程序
开启hadoop
start-all.sh测试代码如下:
from pyspark import SparkContext sc = SparkContext() logData = sc.textFile("test.txt").cache() # 这里的文件是HDFS中的文件 numAs = logData.filter(lambda s: 'a' in s).count() numBs = logData.filter(lambda s: 'b' in s).count() print("Lines with a: %i, lines with b: %i" % (numAs, numBs))运行结果如下:
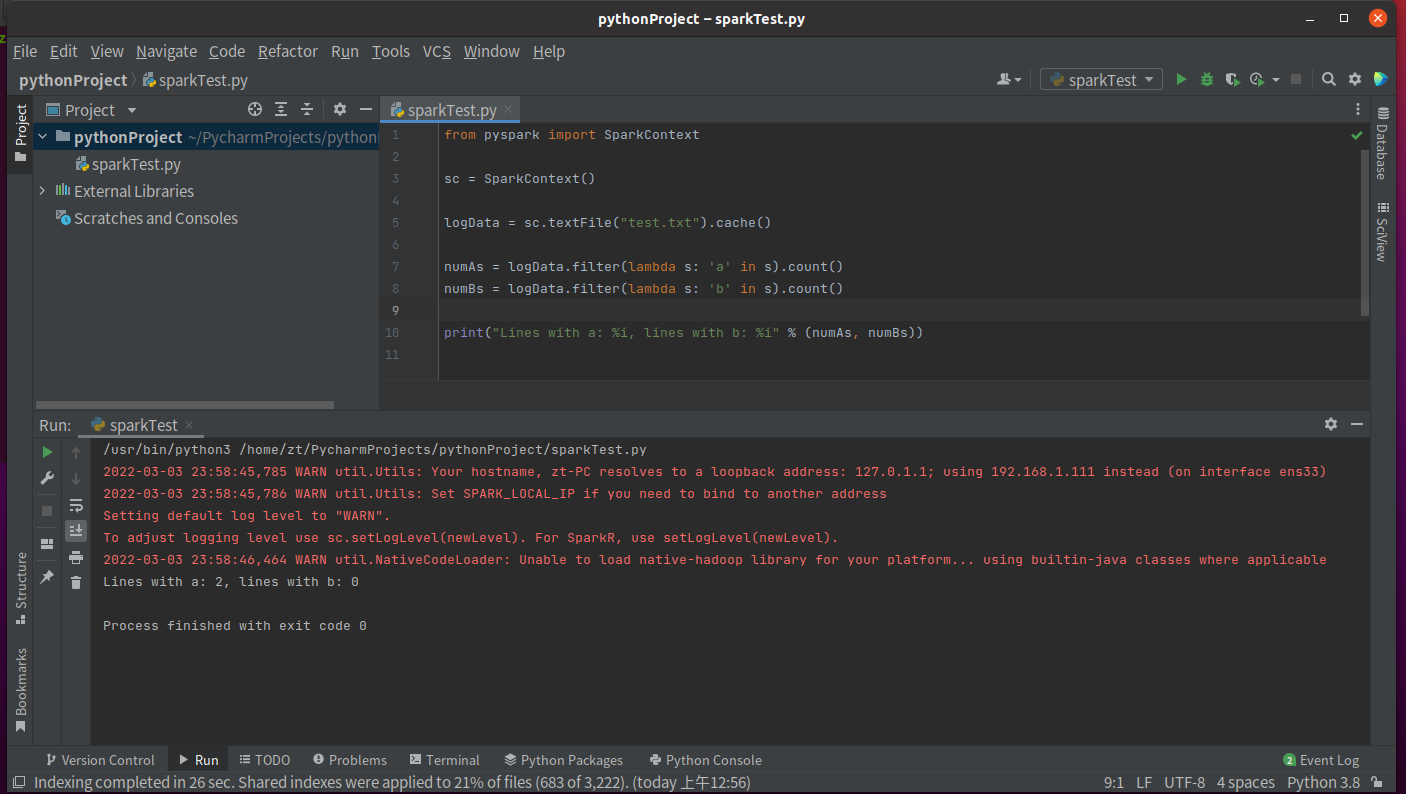
图8 测试结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号