
Spark SQL学习以及实验5 Spark SQL编程初级实践



// ==================== 实验1:JSON数据处理 ====================
:paste
import org.apache.spark.sql.SparkSession
// 创建SparkSession
val spark = SparkSession.builder()
.appName("JSONDataFrameExample")
.getOrCreate()
import spark.implicits._
// 1. 读取employee.json文件
val jsonDF = spark.read.json("file:///export/data/employee.json")
println("=== 原始数据 ===")
jsonDF.show()
// (1) 查询所有数据
println("\n(1) 查询所有数据:")
jsonDF.show()
// (2) 查询所有数据,并去除重复的数据
println("\n(2) 查询所有数据,并去除重复的数据:")
jsonDF.distinct().show()
// (3) 查询所有数据,打印时去除id字段
println("\n(3) 查询所有数据,打印时去除id字段:")
jsonDF.drop("id").show()
// (4) 筛选出age>30的记录
println("\n(4) 筛选出age>30的记录:")
jsonDF.filter("age > 30").show()
// (5) 将数据按age分组
println("\n(5) 将数据按age分组:")
jsonDF.groupBy("age").count().orderBy("age").show()
// (6) 将数据按name升序排列
println("\n(6) 将数据按name升序排列:")
jsonDF.orderBy("name").show()
// (7) 取出前3行数据
println("\n(7) 取出前3行数据:")
jsonDF.head(3).foreach(println)
// (8) 查询所有记录的name列,并为其取别名为username
println("\n(8) 查询所有记录的name列,并为其取别名为username:")
jsonDF.select($"name".as("username")).show()
// (9) 查询年龄age的平均值
println("\n(9) 查询年龄age的平均值:")
jsonDF.select(avg("age")).show()
// (10) 查询年龄age的最小值
println("\n(10) 查询年龄age的最小值:")
jsonDF.select(min("age")).show()
println("\n=== 实验1完成 ===")
// Ctrl+D结束粘贴 
// ==================== 实验2:RDD转换为DataFrame ====================
:paste
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
// 1. 读取文本文件创建RDD
val rdd = spark.sparkContext.textFile("file:///export/data/employee.txt")
// 2. 定义Schema
val schema = StructType(Array(
StructField("id", IntegerType, nullable = false),
StructField("name", StringType, nullable = false),
StructField("age", IntegerType, nullable = false)
))
// 3. 将RDD转换为Row RDD
val rowRDD = rdd.map(_.split(","))
.filter(_.length == 3)
.map(attributes => Row(attributes(0).trim.toInt, attributes(1).trim, attributes(2).trim.toInt))
// 4. 创建DataFrame
val employeeDF = spark.createDataFrame(rowRDD, schema)
// 5. 显示DataFrame
println("=== 从RDD转换得到的DataFrame ===")
employeeDF.show()
// 6. 按指定格式打印数据
println("\n按格式打印数据:")
employeeDF.collect().foreach { row =>
val id = row.getAs[Int]("id")
val name = row.getAs[String]("name")
val age = row.getAs[Int]("age")
println(s"id:$id,name:$name,age:$age")
}
println("\n=== 实验2完成 ===")
// Ctrl+D结束粘贴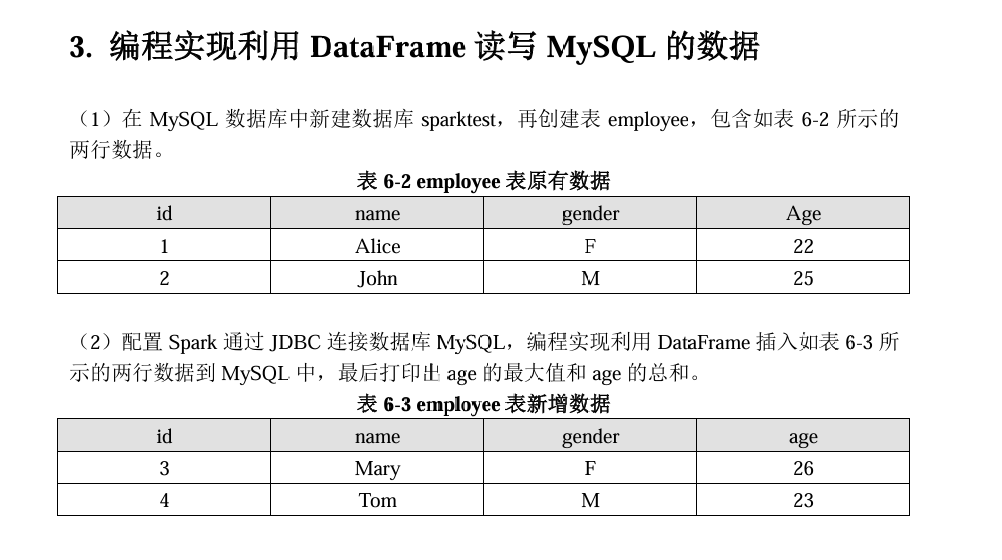
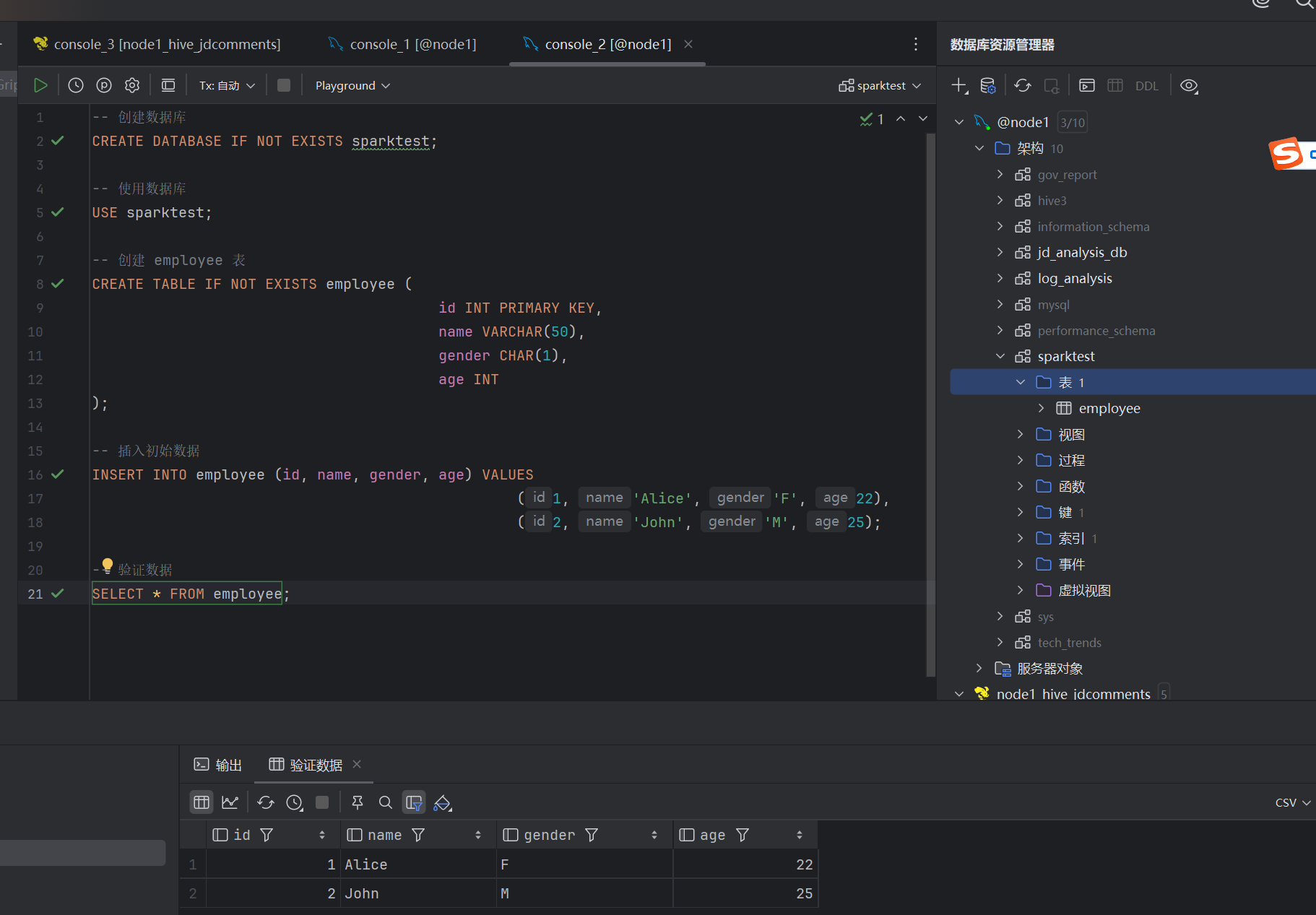
-- 创建数据库
CREATE DATABASE IF NOT EXISTS sparktest;
-- 使用数据库
USE sparktest;
-- 创建 employee 表
CREATE TABLE IF NOT EXISTS employee (
id INT PRIMARY KEY,
name VARCHAR(50),
gender CHAR(1),
age INT
);
-- 插入初始数据
INSERT INTO employee (id, name, gender, age) VALUES
(1, 'Alice', 'F', 22),
(2, 'John', 'M', 25);
-- 验证数据
SELECT * FROM employee;注意在运行以下代码前一定要将mysql-jdbc驱动放在/export/server/spark-3.4.0-bin-without-hadoop/jars下
// ==================== 实验3:更简单的版本 ====================
:paste
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.functions._
val spark = SparkSession.builder().appName("MySQLTest").getOrCreate()
import spark.implicits._
println("=== 开始MySQL实验 ===")
val jdbcUrl = "jdbc:mysql://node1:3306/sparktest"
try {
// 读取数据
println("1. 读取原始数据:")
val df = spark.read
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", "employee")
.option("user", "root")
.option("password", "hadoop")
.load()
df.show()
// 插入新数据
println("2. 插入新数据:")
val newData = Seq(
(3, "Mary", "F", 26),
(4, "Tom", "M", 23)
).toDF("id", "name", "gender", "age")
newData.write
.mode(SaveMode.Append)
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", "employee")
.option("user", "root")
.option("password", "hadoop")
.save()
println("3. 重新读取数据:")
val updatedDF = spark.read
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", "employee")
.option("user", "root")
.option("password", "hadoop")
.load()
updatedDF.show()
println("4. 计算结果:")
val maxAge = updatedDF.selectExpr("max(age)").first().getInt(0)
val totalAge = updatedDF.selectExpr("sum(age)").first().getLong(0)
println(s"age的最大值: $maxAge")
println(s"age的总和: $totalAge")
} catch {
case e: Exception =>
println(s"错误: ${e.getMessage}")
println("请检查:")
println("1. MySQL服务是否运行: service mysql status")
println("2. 数据库和表是否存在")
println("3. 用户名和密码是否正确")
}
// Ctrl+D结束粘贴

 浙公网安备 33010602011771号
浙公网安备 33010602011771号