
采用DrissionPage批量采集抖音视频
参考视频:https://www.bilibili.com/video/BV1nSRPYtEAU/?spm_id_from=333.337.search-card.all.click
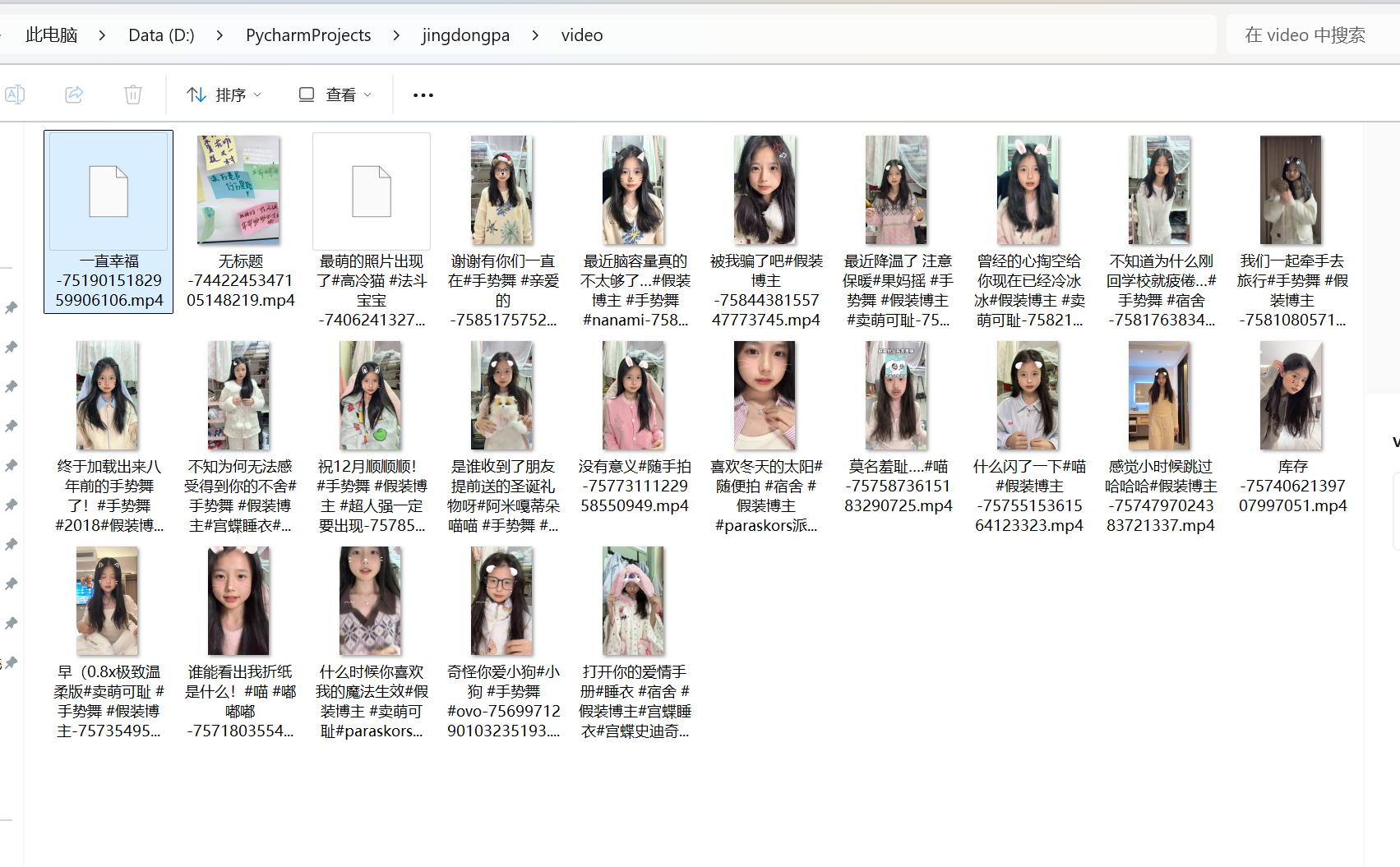
效果展示(只实现了爬取视频,没有爬取图文):
具体代码:
# 导入自动化模块
from DrissionPage import ChromiumPage
import requests
import time
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36',
'referer': 'https://www.douyin.com/user/MS4wLjABAAAAczLgM1eXmTLadiZ_T7_VyrbKP0O79wR-OOMl-meVqgE?from_tab_name=main'
}
# 处理视频数据的函数
def process_videos(video_list):
for index in video_list:
title = index['desc']
video_id = index['aweme_id']
video_url = index['video']['play_addr']['url_list'][0]
# 清理标题中的非法字符
clean_title = ''.join(c for c in title if c not in r'\/:*?"<>|')
if not clean_title or clean_title.isspace():
clean_title = "无标题"
print(f"正在下载: {clean_title[:30]}... (ID: {video_id})")
# 获取视频内容
video_content = requests.get(url=video_url, headers=headers).content
# 保存视频
file_name = f'video/{clean_title}-{video_id}.mp4'
with open(file_name, 'wb') as f:
f.write(video_content)
print(f"✓ 已保存: {file_name}")
# 主程序
dp = ChromiumPage()
dp.listen.start('/aweme/post/')
dp.get('https://www.douyin.com/user/MS4wLjABAAAAczLgM1eXmTLadiZ_T7_VyrbKP0O79wR-OOMl-meVqgE?from_tab_name=main')
# 创建保存视频的目录
os.makedirs('video', exist_ok=True)
# 获取第一页数据
resp = dp.listen.wait()
# 直接使用 resp.response.body,因为它已经是字典格式
json_data = resp.response.body
if 'aweme_list' in json_data:
video_list = json_data['aweme_list']
process_videos(video_list)
# 如果需要更多数据,滚动加载
while json_data.get('has_more', 0) == 1:
# 滚动到页面底部
tab = dp.ele('css:.Rcc71LyU')
dp.scroll.to_see(tab)
time.sleep(2)
# 获取新数据
resp = dp.listen.wait(timeout=5)
if resp:
# 直接使用 body,不需要再解析
json_data = resp.response.body
if 'aweme_list' in json_data:
video_list = json_data['aweme_list']
process_videos(video_list)
print("爬取完成!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号