
二:编写MapReduce程序清洗信件内容数据
上一节地址:https://www.cnblogs.com/ztn195/p/19000866
视频讲解:【二:编写MapReduce程序清洗信件内容数据】 https://www.bilibili.com/video/BV1dG87zAE6A/?share_source=copy_web&vd_source=c40bbd8b0dc6c7ef3e9a75e590c1c1c7
准备工作:
1.三台搭建了hadoop集群的虚拟机node1(192.168.88.151)node2(192.168.88.152) node3(192.168.88.153)。
2.使用finalShell连接虚拟机。
3.使用start-all.sh 启动hadoop集群服务,用jps查看;stop-all.sh 为关停hadoop集群。
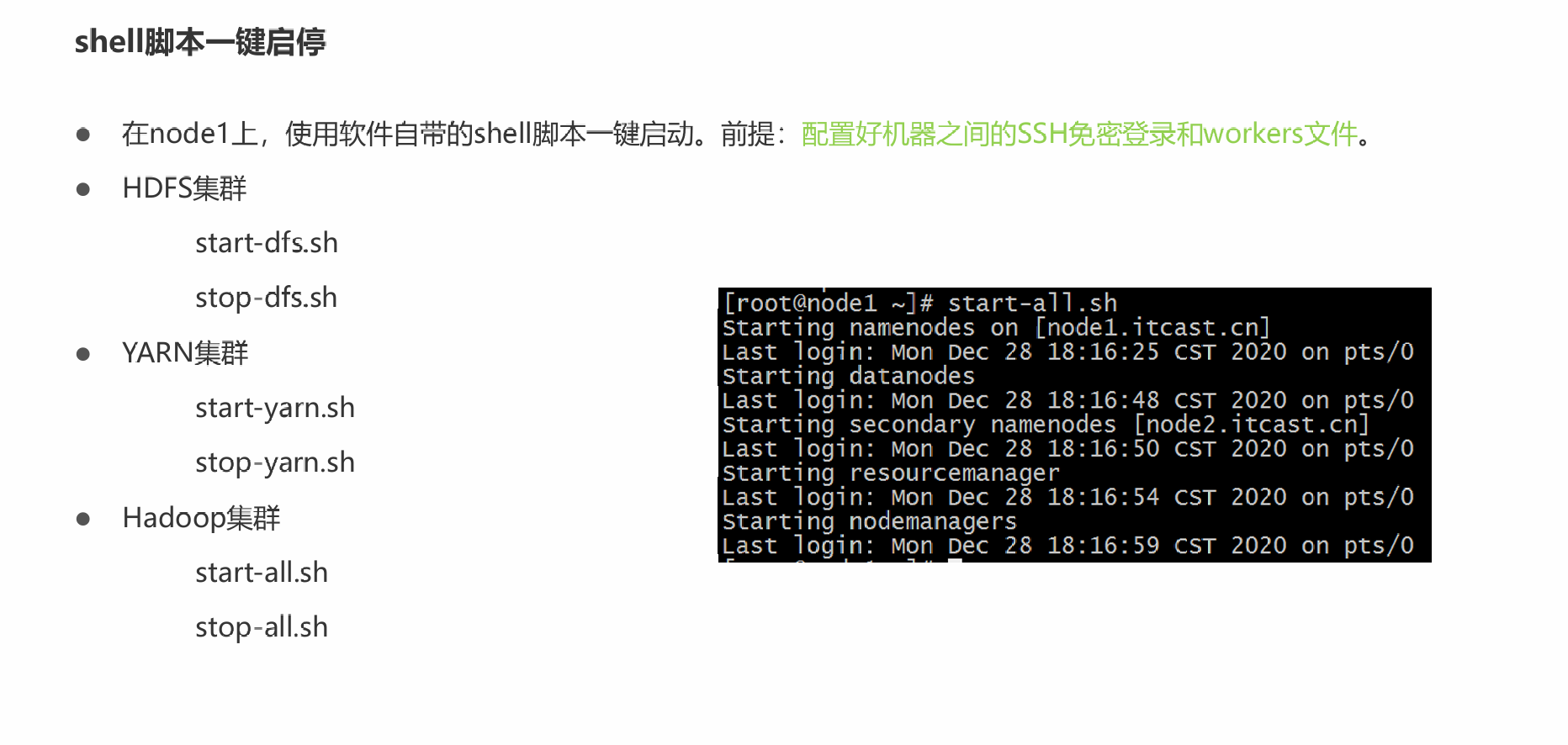
hdfs管理网站:http://node1:9870/ (就是虚拟机名加上9870)
创建输入数据
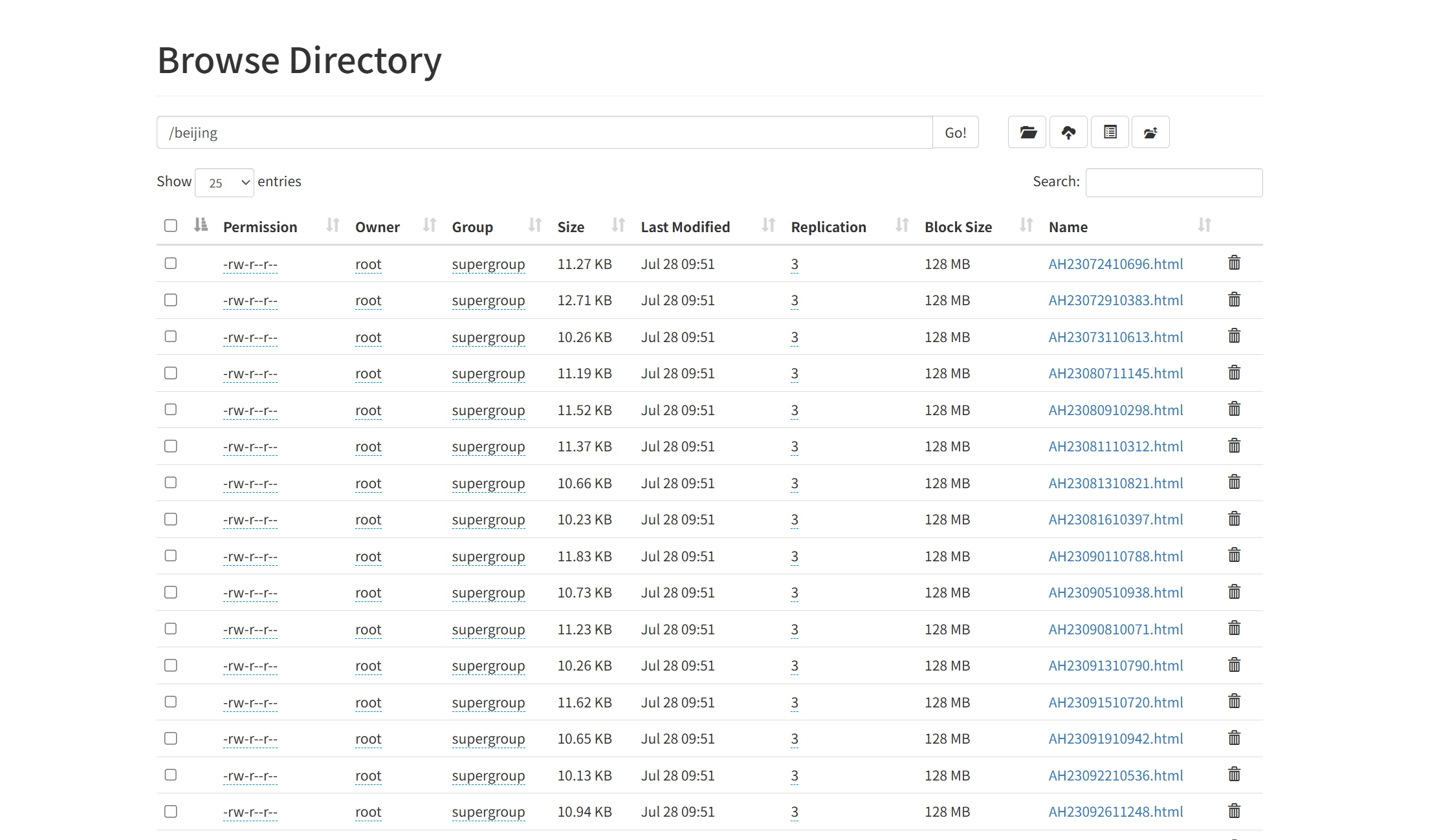
在网站的显示文件系统页面,新建一个文件夹beijing。在beijing中导入上一节在D:/beijingletters中的所有html文件作为程序的输入数据



编写mapreduce程序并打包
MR程序提取出来信人 来信人 来信时间 问题内容 答复单位 答复时间 答复内容字段,map程序分析每一个html。reduce程序将所有结果合并在一个输出文件中。
导入hadoop相关依赖,设置maven打包为jar包,同时由于虚拟机中jdk版本为1.8,调整代码的jdk版本一致。
📁 FileInput.java
作用:自定义输入格式
继承Hadoop的FileInputFormat,定义如何读取输入文件。
将每个整个HTML文件作为一条记录处理(Key:文件名,Value:文件完整内容)。
📁 FileRecordReader.java
作用:自定义记录读取器
实现RecordReader逻辑:
Key = HTML文件名(如12345.html)
Value = HTML文件的完整文本内容
一次性读取整个文件(适用于小文件处理)。
📁 QingxiHtml.java(核心逻辑)
作用:MapReduce作业主程序
Mapper:解析HTML并提取7个关键字段
Reducer:简单合并输出结果
Main:配置并启动MapReduce任务
项目结构:

依赖导入:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.target>1.8</maven.compiler.target> <!-- 修改为8 -->
<maven.compiler.source>1.8</maven.compiler.source> <!-- 修改为8 -->
<junit.version>5.10.0</junit.version>
</properties>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>my.mr.QingxiHtml</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal> <!-- 确保这是小写 "single" -->
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
源代码:
FileInput.java
点击查看代码
package my.mr;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class FileInput extends FileInputFormat<Text, Text> {
@Override
public RecordReader<Text, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
return new FileRecordReader();
}
}
FileRecordReader.java
点击查看代码
package my.mr;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class FileRecordReader extends RecordReader<Text, Text> {
private FileSplit fileSplit;
private JobContext jobContext;
private Text currentKey = new Text();
private Text currentValue = new Text();
private boolean processed = false;
@Override
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
this.fileSplit = (FileSplit) split;
this.jobContext = context;
currentKey.set(fileSplit.getPath().getName());
}
@Override
public boolean nextKeyValue() throws IOException {
if (!processed) {
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(jobContext.getConfiguration());
try (FSDataInputStream in = fs.open(file);
BufferedReader br = new BufferedReader(new InputStreamReader(in, "UTF-8"))) {
StringBuilder content = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
content.append(line).append("\n"); // 保留换行符确保JSoup正确解析
}
currentValue.set(content.toString());
}
processed = true;
return true;
}
return false;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return currentKey;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return currentValue;
}
@Override
public float getProgress() throws IOException {
return processed ? 1.0f : 0.0f;
}
@Override
public void close() throws IOException {
// 资源已在try-with-resources中自动关闭
}
}
QingxiHtml.java
点击查看代码
package my.mr;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class QingxiHtml {
public static class HtmlMapper extends Mapper<Text, Text, Text, Text> {
private String cleanField(String field) {
if (field == null) return "";
// 替换制表符、换行符和回车符
return field.replace("\t", " ").replace("\n", " ").replace("\r", " ").trim();
}
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
try {
String html = value.toString();
Document doc = Jsoup.parse(html);
// 1. 标题提取(移除网站后缀)
String title = cleanField(doc.select("title").text()
.replace("_首都之窗_北京市人民政府门户网站", ""));
// 2. 来信人提取(更健壮的选择器)
String sender = "";
Elements senderElements = doc.select("div.text-muted:contains(来信人)");
if (!senderElements.isEmpty()) {
sender = cleanField(senderElements.first().text()
.replace("来信人:", ""));
}
// 3. 来信时间提取
String sendTime = "";
Elements timeElements = doc.select("div.text-muted:contains(时间)");
if (!timeElements.isEmpty()) {
sendTime = cleanField(timeElements.first().text()
.replace("时间:", ""));
}
// 4. 问题内容提取
String questionContent = "";
Elements questionSections = doc.select("div.row.clearfix.my-5.o-border.p-2");
if (!questionSections.isEmpty()) {
Element questionSection = questionSections.first();
Elements textFormat = questionSection.select("div.text-format");
if (!textFormat.isEmpty()) {
questionContent = cleanField(textFormat.first().text());
}
}
// 5. 答复信息提取
String replyOrg = "";
String replyTime = "";
String replyContent = "";
if (questionSections.size() > 1) {
Element replySection = questionSections.get(1);
// 答复机构(支持两种选择器)
Elements orgElements = replySection.select("div.o-font4 strong, div.o-font4 > strong");
if (!orgElements.isEmpty()) {
replyOrg = cleanField(orgElements.first().text());
}
// 答复时间提取(关键修改) - 使用正则确保只获取日期
Elements timeContainer = replySection.select("div.col-xs-12.col-sm-3.col-md-3.my-2");
if (!timeContainer.isEmpty()) {
String timeText = timeContainer.first().text();
// 使用正则提取YYYY-MM-DD格式的日期
Pattern pattern = Pattern.compile("\\d{4}-\\d{2}-\\d{2}");
Matcher matcher = pattern.matcher(timeText);
if (matcher.find()) {
replyTime = matcher.group(0);
}
}
// 答复内容(处理多段内容)
Elements replyTexts = replySection.select("div.text-format");
if (!replyTexts.isEmpty()) {
StringBuilder contentBuilder = new StringBuilder();
for (Element el : replyTexts) {
contentBuilder.append(cleanField(el.text())).append(" ");
}
replyContent = contentBuilder.toString().trim();
}
}
// 构建TSV行
String output = String.join("\t",
title.isEmpty() ? "N/A" : title,
sender.isEmpty() ? "N/A" : sender,
sendTime.isEmpty() ? "N/A" : sendTime,
questionContent.isEmpty() ? "N/A" : questionContent,
replyOrg.isEmpty() ? "N/A" : replyOrg,
replyTime.isEmpty() ? "N/A" : replyTime,
replyContent.isEmpty() ? "N/A" : replyContent
);
context.write(new Text("output"), new Text(output));
} catch (Exception e) {
String errorMsg = "ERROR:" + key.toString() + " | " + e.getClass().getSimpleName();
if (e.getMessage() != null) {
errorMsg += ": " + e.getMessage();
}
context.write(new Text("ERROR"), new Text(cleanField(errorMsg)));
}
}
}
public static class HtmlReducer extends Reducer<Text, Text, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value, NullWritable.get()); // 直接输出数据行
}
}
}
public static void main(String[] args) throws Exception {
Job job = Job.getInstance();
job.setJarByClass(QingxiHtml.class);
job.setJobName("GovLetterCleaner");
job.setInputFormatClass(FileInput.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(HtmlMapper.class);
job.setReducerClass(HtmlReducer.class);
job.setNumReduceTasks(1); // 关键:只使用一个Reducer
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path("/beijing"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
打包:

将jar包在虚拟机上运行
将jar包拖入虚拟机一个目录下(我这里是/export/server),然后cd到该目录下,执行命令运行
cd /export/server
hadoop jar pachong-1.0-SNAPSHOT-jar-with-dependencies.jar my.mr.QingxiHtml /beijing /output
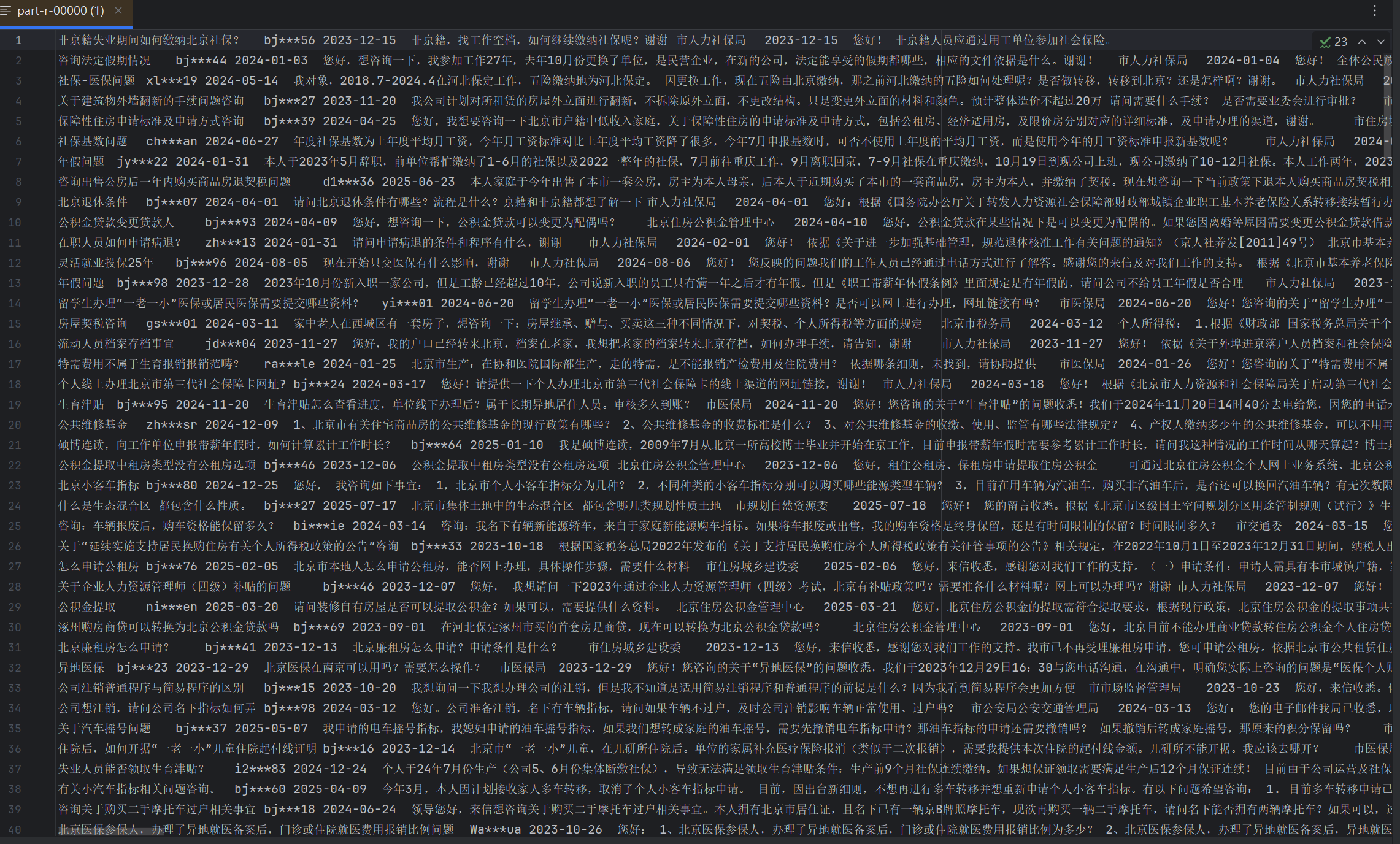
由于数据量有点少才284个所以执行MR程序较慢。执行完毕后在hdfs的文件系统页面会多一个output文件夹,
一个标识文件代表运行成功还是失败。另一个是输出结果,下载后用idea打开可以查看结果,一共284行数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号