
一:采集北京市政百姓信件内容(采用WebMagic)
基础链接:https://www.beijing.gov.cn/hudong/hdjl/sindex/hdjl-xjxd.html
视频讲解:【一:采集北京市政百姓信件信息(webMagic)】 https://www.bilibili.com/video/BV1cY8wzeEVP/?share_source=copy_web&vd_source=c40bbd8b0dc6c7ef3e9a75e590c1c1c7
导入依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpmime</artifactId>
<version>4.5.13</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.17.0</version>
</dependency>
原代码:
DetailCrawler.java
package com.example;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class DetailCrawler {
public static void main(String[] args) {
String listUrl = "https://www.beijing.gov.cn/h udong/hdjl/sindex/hdjl-xjxd.html";
String outputFile = "detail_urls.txt"; // 输出文件名
String saveDir = "D:/beijingletters"; // 详情页保存目录
// 创建保存目录
File dir = new File(saveDir);
if (!dir.exists()) {
if (dir.mkdirs()) {
System.out.println("创建目录: " + saveDir);
} else {
System.err.println("无法创建目录: " + saveDir);
return;
}
}
String listHtml = fetchHtml(listUrl);
if (listHtml == null) {
System.err.println("获取列表页面失败");
return;
}
int totalPages = parseTotalPages(listHtml);
if (totalPages <= 0) {
System.err.println("无法解析总页数");
return;
}
System.out.println("总页数: " + totalPages);
// 存储所有详情页URL
List<String> detailUrls = new ArrayList<>();
AtomicInteger totalDownloaded = new AtomicInteger(0);
// 创建线程池(4个线程并行下载)
ExecutorService executor = Executors.newFixedThreadPool(4);
System.out.println("开始下载详情页内容...");
for (int pageNo = 1; pageNo <= totalPages; pageNo++) {
String pageContent;
if (pageNo == 1) {
pageContent = listHtml;
} else {
pageContent = fetchPageByPost(pageNo, 6);
if (pageContent == null) {
System.err.println("第 " + pageNo + " 页获取失败,跳过");
continue;
}
}
// 获取当前页所有详情URL
List<String> pageUrls = parseDetailUrls(pageContent, pageNo == 1);
detailUrls.addAll(pageUrls);
// 为当前页的每个URL创建下载任务
for (String url : pageUrls) {
executor.execute(() -> {
System.out.println("处理: " + url);
String html = fetchDetailHtml(url);
if (html != null) {
saveHtmlToFile(html, saveDir, url);
totalDownloaded.incrementAndGet();
}
});
}
}
// 等待所有任务完成
executor.shutdown();
try {
if (!executor.awaitTermination(10, TimeUnit.MINUTES)) {
System.err.println("部分下载任务未完成");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("详情页下载完成!共下载: " + totalDownloaded.get() + " 个页面");
// 将URL保存到文件
saveUrlsToFile(detailUrls, outputFile);
System.out.println("\n已将所有URL保存到文件: " + outputFile);
}
// 保存HTML到文件
private static void saveHtmlToFile(String html, String saveDir, String url) {
// 从URL提取文件名
String filename = url.substring(url.lastIndexOf('=') + 1) + ".html";
File file = new File(saveDir, filename);
try (BufferedWriter writer = new BufferedWriter(new FileWriter(file))) {
writer.write(html);
System.out.println("保存成功: " + filename);
} catch (IOException e) {
System.err.println("保存文件失败: " + filename + " - " + e.getMessage());
}
}
// 下载详情页HTML内容
private static String fetchDetailHtml(String url) {
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpGet request = new HttpGet(url);
request.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36");
request.setHeader("Referer", "https://www.beijing.gov.cn/hudong/hdjl/sindex/hdjl-xjxd.html");
try (CloseableHttpResponse response = httpClient.execute(request)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != 200) {
System.err.println("详情页请求失败: " + url + " - 状态码: " + statusCode);
return null;
}
HttpEntity entity = response.getEntity();
if (entity != null) {
return EntityUtils.toString(entity, "UTF-8");
}
}
} catch (Exception e) {
System.err.println("详情页请求异常: " + url + " - " + e.getMessage());
}
return null;
}
// 将URL列表保存到文件
private static void saveUrlsToFile(List<String> urls, String filename) {
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filename))) {
for (String url : urls) {
writer.write(url);
writer.newLine();
}
System.out.println("成功保存 " + urls.size() + " 个URL到文件");
} catch (IOException e) {
System.err.println("保存文件时出错: " + e.getMessage());
}
}
// 解析详情页URL - 支持HTML和JSON两种格式
private static List<String> parseDetailUrls(String content, boolean isFirstPage) {
List<String> urls = new ArrayList<>();
// 第一页是HTML,其他页是JSON
if (isFirstPage) {
urls.addAll(parseDetailUrlsFromHtml(content));
} else {
urls.addAll(parseDetailUrlsFromJson(content));
}
return urls;
}
// 从HTML解析详情页URL
private static List<String> parseDetailUrlsFromHtml(String html) {
List<String> urls = new ArrayList<>();
Document doc = Jsoup.parse(html);
// 更通用的选择器
Elements letterItems = doc.select("div.row.clearfix");
for (Element item : letterItems) {
Element link = item.selectFirst("a[onclick]");
if (link == null) continue;
String onclick = link.attr("onclick");
// 更灵活的正则表达式,允许空格变化
Matcher matcher = Pattern.compile("letterdetail\\s*\\(\\s*'(\\d+)'\\s*,\\s*'([^']+)'\\s*\\)").matcher(onclick);
if (matcher.find()) {
String letterType = matcher.group(1);
String originalId = matcher.group(2);
String detailUrl = buildDetailUrl(letterType, originalId);
if (detailUrl != null) {
urls.add(detailUrl);
}
}
}
return urls;
}
// 从JSON解析详情页URL
private static List<String> parseDetailUrlsFromJson(String json) {
List<String> urls = new ArrayList<>();
// 使用正则表达式提取JSON中的信件数据
Pattern pattern = Pattern.compile("\\{originalId:'([^']+)',\\s*letterType:'([^']+)'");
Matcher matcher = pattern.matcher(json);
while (matcher.find()) {
String originalId = matcher.group(1);
String letterType = matcher.group(2);
String detailUrl = buildDetailUrl(letterType, originalId);
if (detailUrl != null) {
urls.add(detailUrl);
}
}
return urls;
}
// 构建详情页URL
private static String buildDetailUrl(String letterType, String originalId) {
String baseUrl = "https://www.beijing.gov.cn/hudong/hdjl/";
switch (letterType) {
case "1":
return baseUrl + "com.web.consult.consultDetail.flow?originalId=" + originalId;
case "2":
return baseUrl + "com.web.suggest.suggesDetail.flow?originalId=" + originalId;
case "3":
return baseUrl + "com.web.complain.complainDetail.flow?originalId=" + originalId;
default:
System.err.println("未知信件类型: " + letterType);
return null;
}
}
// 解析总页数
private static int parseTotalPages(String html) {
Document doc = Jsoup.parse(html);
// 通过隐藏域获取
Element totalPagesElement = doc.selectFirst("input[name=page.totalPages]");
if (totalPagesElement != null) {
try {
return Integer.parseInt(totalPagesElement.attr("value"));
} catch (NumberFormatException e) {
System.err.println("隐藏域解析总页数失败");
}
}
return 0;
}
// 分页POST请求 - 静默处理
private static String fetchPageByPost(int pageNo, int pageSize) {
String url = "https://www.beijing.gov.cn/hudong/hdjl/sindex/bjah-index-hdjl!letterListJson.action";
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpPost request = new HttpPost(url);
request.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36");
request.setHeader("Accept", "application/json, text/javascript, */*; q=0.01");
request.setHeader("Content-Type", "application/x-www-form-urlencoded");
request.setHeader("Referer", "https://www.beijing.gov.cn/hudong/hdjl/sindex/hdjl-xjxd.html");
request.setHeader("X-Requested-With", "XMLHttpRequest");
// 构建POST参数
List<NameValuePair> params = new ArrayList<>();
params.add(new BasicNameValuePair("keyword", ""));
params.add(new BasicNameValuePair("letterType", "0"));
params.add(new BasicNameValuePair("page.pageNo", String.valueOf(pageNo)));
params.add(new BasicNameValuePair("page.pageSize", String.valueOf(pageSize)));
params.add(new BasicNameValuePair("orgtitleLength", "26"));
request.setEntity(new UrlEncodedFormEntity(params, StandardCharsets.UTF_8));
try (CloseableHttpResponse response = httpClient.execute(request)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode != 200) {
return null;
}
HttpEntity entity = response.getEntity();
if (entity != null) {
return EntityUtils.toString(entity, "UTF-8");
}
}
} catch (Exception e) {
System.err.println("第 " + pageNo + " 页请求异常: " + e.getMessage());
}
return null;
}
// 获取HTML内容 (使用Jsoup替代HttpClient)
private static String fetchHtml(String url) {
try {
// 使用Jsoup连接并设置超时时间和User-Agent
Document doc = Jsoup.connect(url)
.timeout(30000) // 30秒超时
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
.get();
return doc.html(); // 返回整个HTML文档字符串
} catch (IOException e) {
System.err.println("Jsoup获取页面异常: " + e.getMessage());
return null;
}
}
}
需求分析:我们要将一个48页284个信件详情页的数据爬取到本地,首先我们要爬取到全部详情页的url,然后下载url(对应的页面源代码)
以下是代码实现的逻辑和相关解释
1.分析网页源码结构
首先我们发现第一页有6个信件,在其中一个信件上右键检查,可以发现6个信件的共同点就是位于div下calss为“row clearfix my-2 list-group o-border-bottom2 p-3”

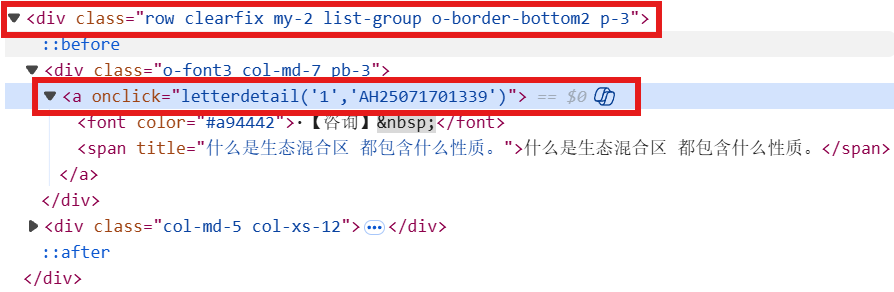
其中有一个a标签,对应的onclick为letterdetail('1','AH25071701339')
当点击其中一个信件中会跳转到所对应的信件详情页(例如:https://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=AH25071701339)
通过对不同类别不同信件的网址进行分析,得出规律:网址中consult.consultDetail代码信件为咨询类型,originalId是信件的编号,网址其他部分一致。
得到这一规律后,可以利用正则对列表页的网页源码进行匹配,从而得到信件的详细页网址。
这样我们即可得出第一页的六个信件内容。
2.构建post请求
在得到第一页的6个信件后,我们还要获取其他页面的内容,首先在第一页按F12。点击下面页数2,可以发现它发送了一条post请求
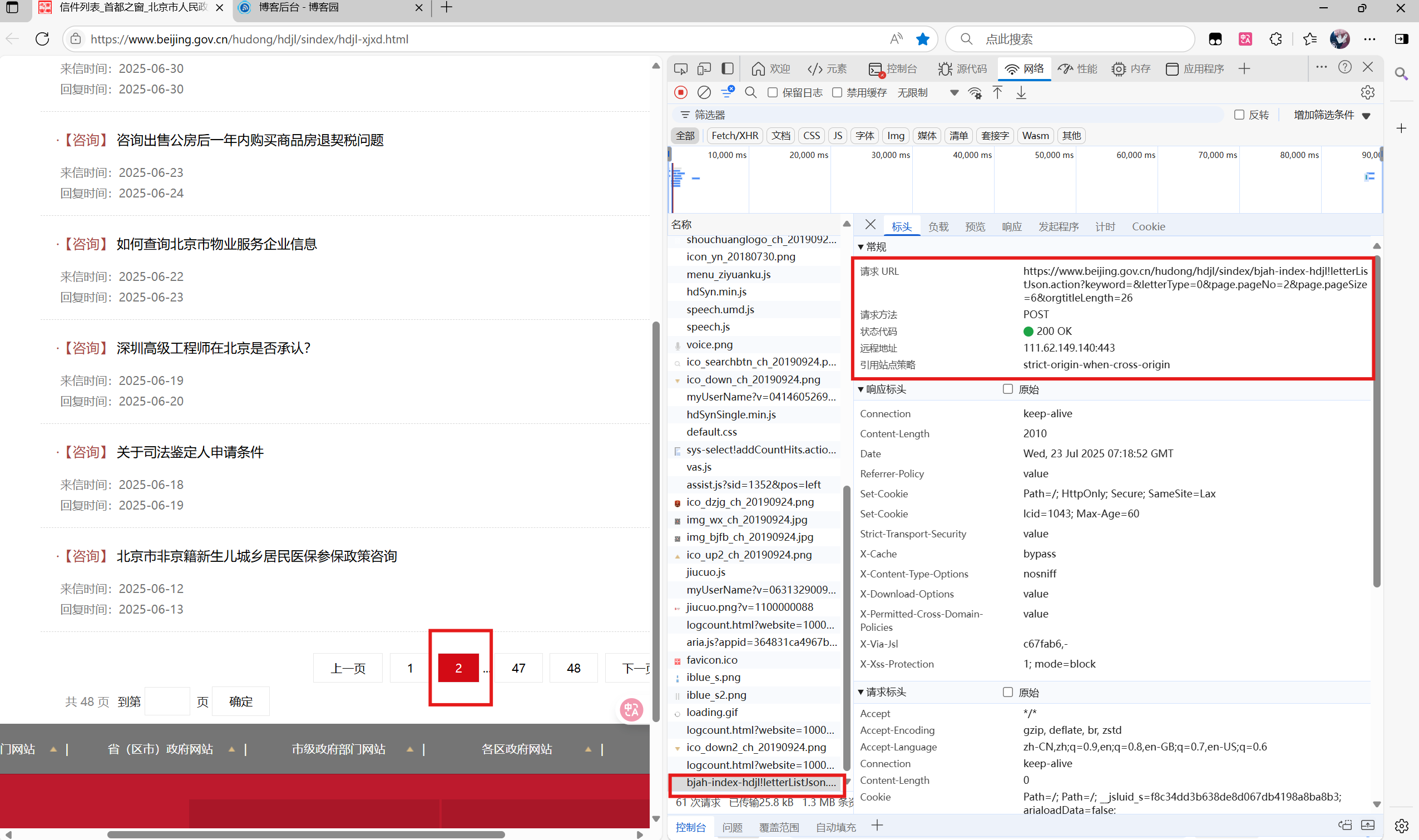
我们代码中按照此格式构建post请求。
接下来我们看这个请求返回的数据,点击预览或响应,可以看到其中的内容有一部分乱码了
但是有一些是正常的如(pageNo表示的是当前页面,originalId表示信件编号,letterType表示信件类型)。注意响应的数据格式为gson
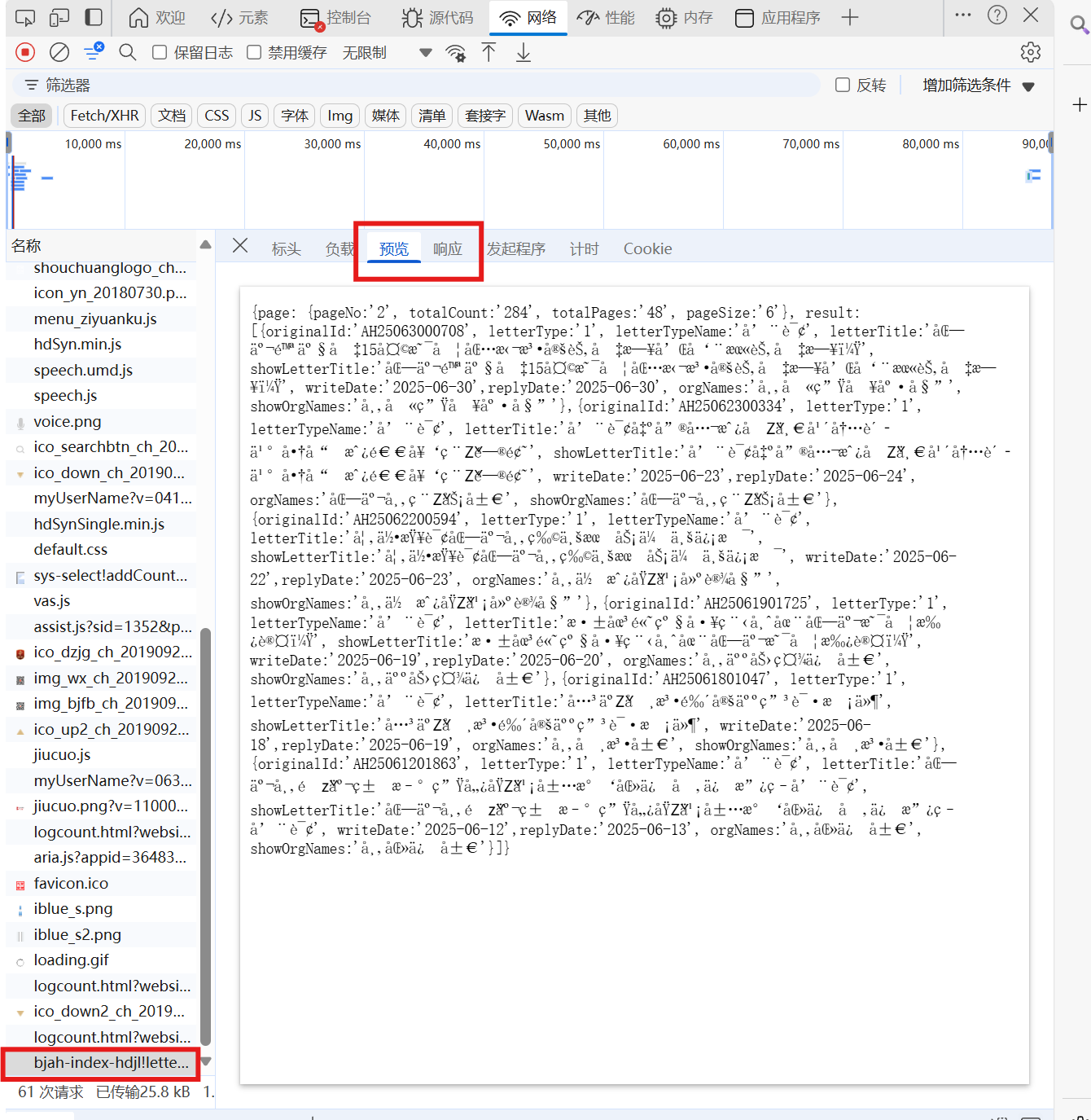
这样我们就可以通过构建post请求获取到全部详情页的url,并下载。
3.创建线程池(4个线程并行下载)
我们发现单线程下载总时间要5,6分钟。太慢了,于是采用多线程,这也是java爬虫对比python爬虫的优势所在,不到一分钟运行完毕。
最终将所有的详情页url保存在根目录的detail_urls.txt文件中

而全部的页面保存在D:/beijingletters中


 浙公网安备 33010602011771号
浙公网安备 33010602011771号