爬虫设计方案
1 引言
通过本项目的实施与建设,在以服务科研工作为主导的原则下,基于高性能大数据软硬件设施,构建多样化、专业化、柔性化的科研数据服务应用平台。利用大数据技术,对预报中心数据进行管理统计,形成可视化的坐标,表格,图形等。
2 系统主要功能需求
要构建多样化、专业化、柔性化的科研数据服务应用平台,现有系统很难承担日益增长的数据分析需求。迫切需要一种全新的系统架构来满足日常业务及数据分析。并有效利用数据的价值,提高数据安全性、系统高可用等。需求分析如下:
- 构建新的系统架构,从物理架构、数据架构、业务模型架构及应用架构等几方面满足业务需求,根据数据下载需求对各个地方发布的数据进行抓取和传输、存储、调用。
- 构建新的系统架构,从数据抓取架构、数据存储架构、业务模型架构及应用架构等几方面满足业务需求。
- 定时抓取互联网数据,将数据提取筛选存入数据库,积累数据,进行大数据统计分析,形成可视化的图形坐标等。
- 系统多平台整合,建设统一的底层平台,提高系统安全等保级别,规避系统单点风险。
3 系统架构
根据对项目背景和需求的分析,为了能够更好地在大数据时代下支撑大规模数据的应用,分别从爬虫系统架构,微服务系统架构及数据架构建设大数据平台系统。
3.1整体架构
整体架构主要分三大板块:
爬虫系统架构使用基于TypeScript开发语言为框架,使用RabbitMQ作为消息队列来搭建爬虫分布式系统,实现系统的高可用性,高性能,高扩展性,高容错率。
数据存储分为三大模块:Redis集群:主要用来存储缓存数据,实现快速读写,提高数据的运行效率;Oracle数据库集群:可以实现读写分离,提高数据的读写效率,实现负载均衡,失败转移;文件系统集群:主要用来存储资源文件数据,具有安全性,高扩展性,高传输。
微服务架构使用Netcore webapi来搭建,将模块拆分成一个独立的服务单元通过接口来实现数据的交互,使用Nginx作为负载均衡和反向代理服务器来实现分布式架构;Vue框架调用微服务接口来实现前后端分离的概念,通过接口获取时间展示在前端网页,大屏或移动设备上。
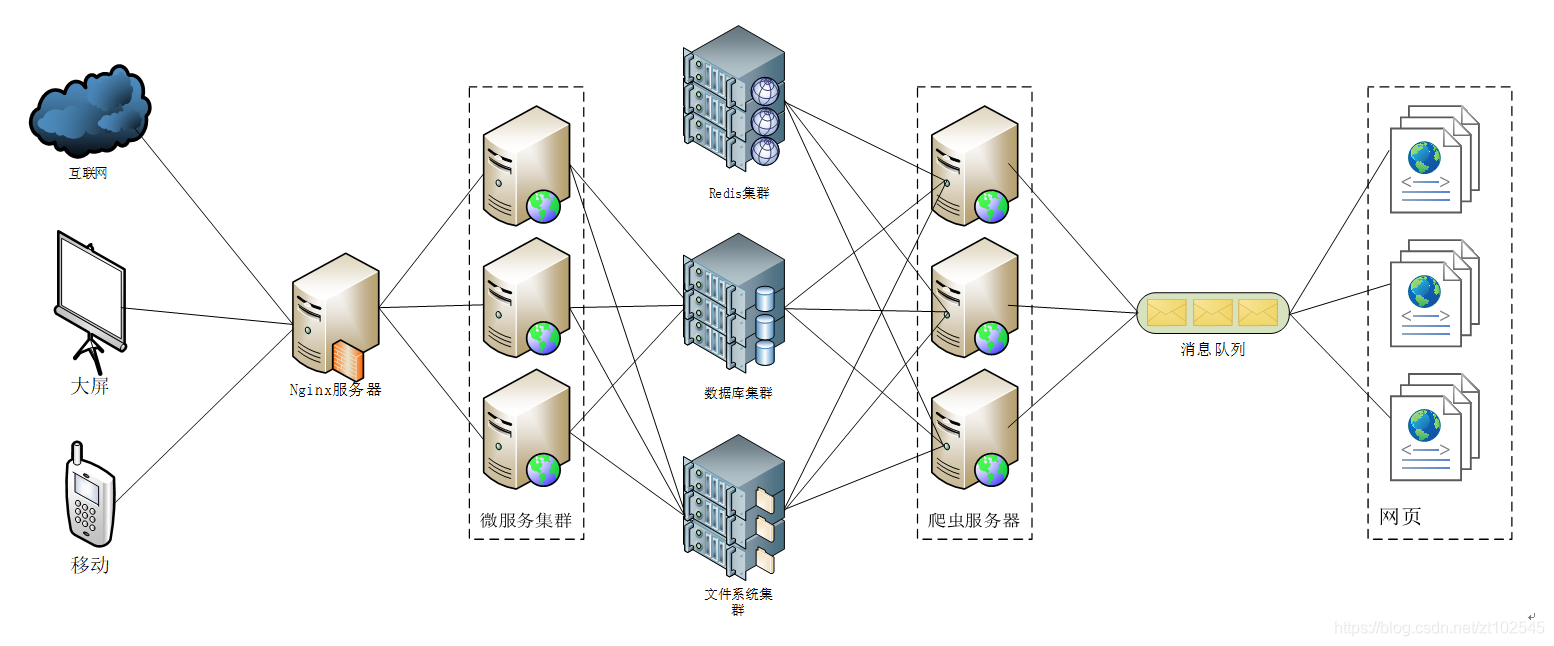
3.2 爬虫架构
爬虫系统架构如图,使用RabbitMQ消息队列作为消息中间件接收网页地址和分发到各个爬虫服务器处理,每个爬虫服务器可以运行多个线程去处理每个网页地址,从而大大提高抓取效率
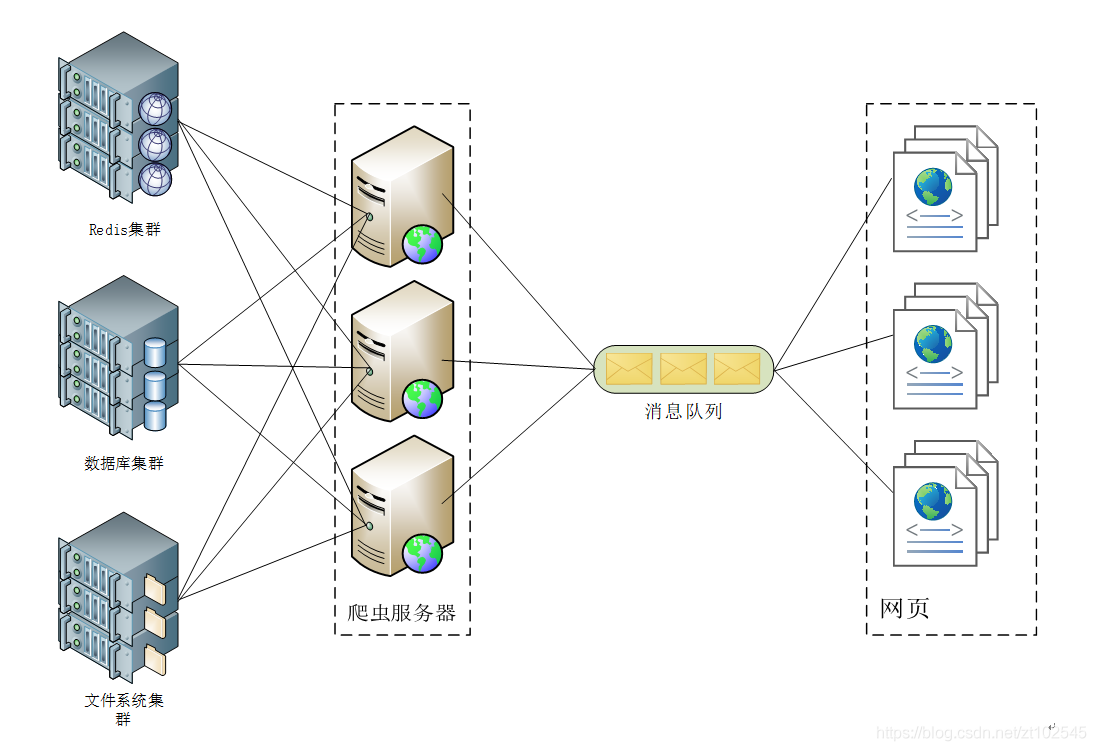
3.3 数据存储架构
信息具有海量、异构的特点,且需要进行快速的解算、分析、处理。分布式处理技术技术是目前在军事、商业、医疗等领域广泛应用的高性能计算技术,利用该技术构建的数据服务支撑平台既能够满足对于存储容量和计算能力的需求,同时使平台具备较强可靠性和可扩展性。
(1) 海量存储能力
云平台运行分布式的文件系统,数据库和Redis缓存,能够将数据分块存储在多台计算机组成的存储资源池中,而分块的方法和具体的存储位置对于用户透明,用户如同在访问本地的文件系统。
(2) 高吞吐量
平台在读取分数式文件系统中的数据时,分别从不同计算机读取文件的分块,并将其组装成完整的文件,各块的传输使用独立的物理和逻辑通路,提高了访问的吞吐量。
(3) 高性能计算能力
云平台采用分布式并行计算计数,将一个复杂运算或大规模数据处理任务分解为多个可并行执行的子任务,并将任务分发到不同服务器、CPU、内核中并行执行,从而利用普通的计算机实现高性能计算。
(4) 高可靠性
云平台中的数据均进行冗余备份,文件的多个副本分别存放在不同的计算机中,存储设备的损坏不影响文件的完整性和正确性。
(5) 可扩展性
云平台的体系结构使用户可以通过添加计算机的方式水平扩展平台的存储容量和计算能力,随着硬件集群规模的扩大,其存储容量和数据处理能力将已近似线性的趋势增长。
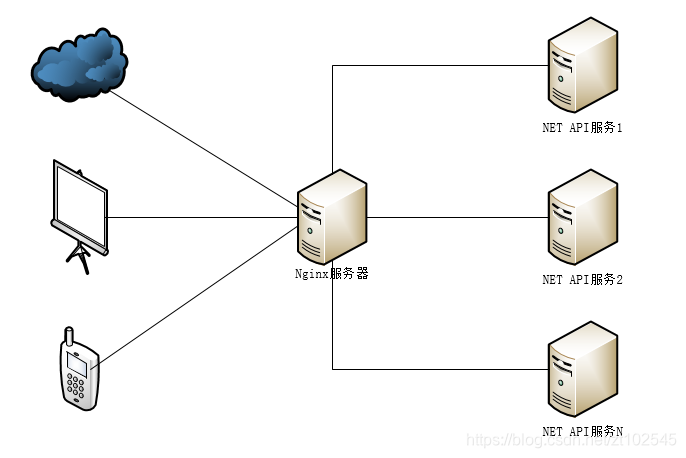
3.4 微服务架构
微服务架构基于NETcore来开发,NETcore是微软提供的一套跨平台技术,可以同时部署在Linux服务器和Window服务器上。在NETcore平台上的Web API 是一个开源的、理想的、构建RES-ful服务的技术,它能够提供轻量级的HTTP服务。WEB API建立在Http协议的,所以可以完美的跨平台,不仅可以用于浏览器的网页,还可以用于移动端设置App(iOS、Android、WP)。Nginx服务器作负载均衡,将请求分发到各个服务器,服务器获取请求,从数据库提取数据,解析成Json格式返回。前端接收Json使用了Vue框架,是其前后端分离,具有高扩展性。
4.技术方案
4.1 爬虫系统
该方案的爬虫系统使用TypeScript作为开发语言,TypeScript是一种由微软开发的自由和开源的编程语言。它是JavaScript的一个超集,而且本质上向这个语言添加了可选的静态类型和基于类的面向对象编程。
4.1.1 爬虫原理
网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的 URL会得到一些新的 URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
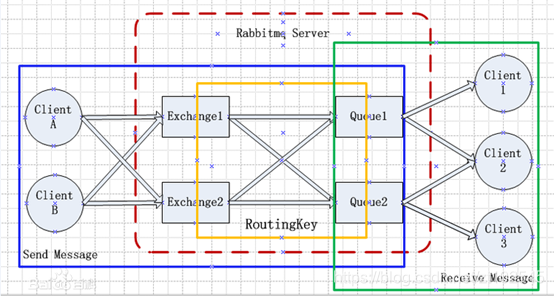
4.1.2 消息队列
消息队列技术是分布式应用间交换信息的一种技术,可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行–它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。该方案采用的是RabbitMQ消息队里,它的主要作用是接受和转发消息,并不处理消息。
4.1.3 数据解析
对于爬虫获取的到信息需要解析转换为项目能识别的格式,目前有以下三种方式来实施数据解析:
- 对于Html形式的文本,使用Jsoup等工具包解析
- 对于json格式的文本,使用Gson等工具包解析
- 对于没有固定格式,无法用特定工具解析的文本,使用正则表达式工具获取目标数据
4.1.4 数据存储
该方案对于数据存储主要分为三个模块:
- 对于资源文件,下载存储到文件服务器,路径存储到数据库。
- 对于数据去重,需要将数据存储到Redis缓存里,提取数据时作比对。
- 对于数据存储,数据库设计好相应字段,数据解析成数据库结构存储到数据库。
4.1.5 定时任务
根据需求,项目需要定时的去给定的URL网址抓取数据,所以在定时任务这块项目采用Quartz,它是一个完全由java编写的开源作业调度框架。其优势主要有:
- 配置方便,支持多任务
- 业务-定时可控,灵活配置,随时更改
- 支持分布式集群
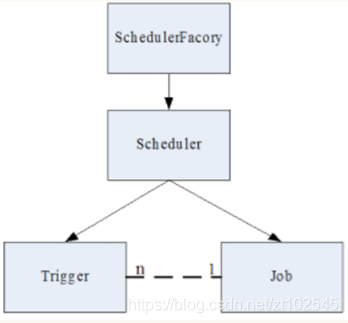
其主要组成部分如图: - scheduler(调度器):将job和trigger绑定在一起
- job(任务):配置具体哪个类实现定时任务
- trigger(触发器):配置定时器参数,如:多久执行一次,执行多上次等
4.2 分布式数据库
分布式数据库用于管理实时采集的爬虫数据,及质量数据分析和挖掘的中间结果。
分布式数据库同样由一个管理节点和多个数据节点构成,底层利用分布式文件系统存储数据;利用分布式计算框架处理其中的海量数据,完成查询、筛选操作。
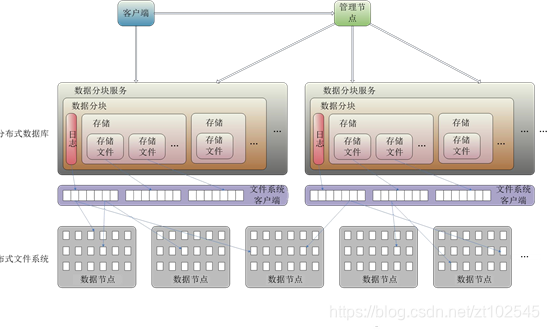
数据库中每一个记录由键、时间、值组成,而值根据其所属的列簇划分为多个列。数据库采用面向列的存储方式,相同列簇的数据被连续存储,列簇中同一列的数据被连续存储。
4.2.1 高可用
分布式数据库通过安全组内冗余机制来保证集群的高可用特性:
- 每个安全组可提供1个或2个副本数据冗余;
- 安全组 内数据副本自动同步;
- 复制引擎自动管理数据同步;
- 采用扁平架构,每一个节点都可以充当主控节点。避免一个服务器宕机产生的整个集群不可用。
4.2.2 高性能
数据加载功能作为分布式数据库的一部分而存在,目的是将用户从其他数据源得到的原始数据文件,按照某种加载规则分发至集群节点,集群各节点接收数据入库保存到本地磁盘。
分布式数据库支持数据高效并行加载,数据加载速度随节点的扩展而呈现线性增加。集群加载采用B/S架构,包括数据分发服务器和数据分发客户端两个应用程序。
数据分发服务器接收到客户端的数据加载请求后,服务器端负责原始数据文件切分和数据文件的下发;各节点调用本地的集群加载服务接收数据入库并保存到本地磁盘。
4.3 微服务系统
该方案使用的是NETcore Web API来做请求接口,基于HTTP协议,将数据传输给前端,前端采用VUE轻量级的渐进式框架来展示数据。
4.3.1 Nginx
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器;同时也是一个IMAP、POP3、SMTP代理服务器;nginx可以作为一个HTTP服务器进行网站的发布处理,另外nginx可以作为反向代理进行负载均衡的实现。
4.3.2 负载均衡
负载均衡建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。
4.3.3 反向代理
在计算机网络中,反向代理是代理服务器的一种。服务器根据客户端的请求,从其关系的一组或多组后端服务器(如Web服务器)上获取资源,然后再将这些资源返回给客户端,客户端只会得知反向代理的IP地址,而不知道在代理服务器后面的服务器簇的存在。
4.3.4 Netcore Web API
.NET Core 是一个开源的、跨平台的 .NET 实现。而Web API是网络应用程序接口,通过接口可以对接各种客户端(浏览器,移动设备),构建http服务的框架。
4.3.5 Vue
Vue.js是一个构建数据驱动的 web 界面的渐进式框架。Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件。
4.3.6 前后端分离
核心思想是前端HTML页面通过AJAX调用后端的RESTFUL API接口并使用JSON数据进行交互。
4.4 数据展示
4.4.1 功能介绍
数据采集后Vue框架通过调用微服务接口来获取数据展示到前端,前端会是一个预报中心下载平台,该平台具备用户登录,用户管理,用户级别,基础数据管理,历史数据查询,统计分析报表,百度地图API等功能。同时也具备可扩展性。
4.4.2 用户管理
可以为各级用户分配不同的权限,保证数据及系统的安全性。用户分为三类:
- 管理员
- 企业用户
- 普通用户
其中管理员为系统运行和管理人员,具有系统的所有权限。企业用户只能管理本企业的数据,对本企业的数据具有所有管理权限;普通用户只能对自己拥有的数据进行管理,包括实时监控、诊断等功能,普通用户只能使用该系统,不具备删除、停用等高级权限。
4.4.3 基础数据管理
该平台具备对预报中心数据的数据进行查询,修改,删除等功能。
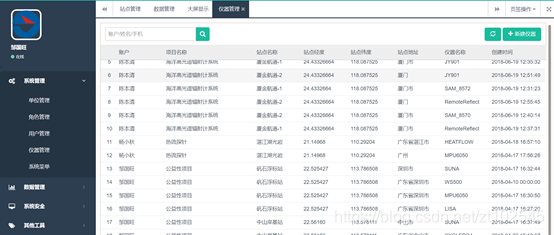
4.4.4 历史数据查询
该平台可提供历史数据查询功能
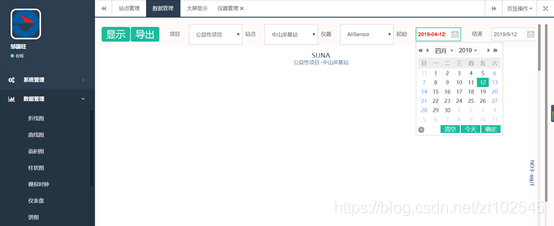
4.4.5 统计分析报表
该平台可以对查询出来的数据进行大数据统计分析,形成条形图,饼状图,曲线图等。
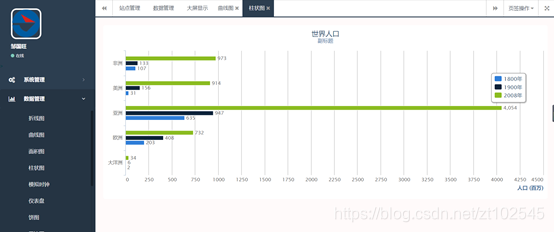
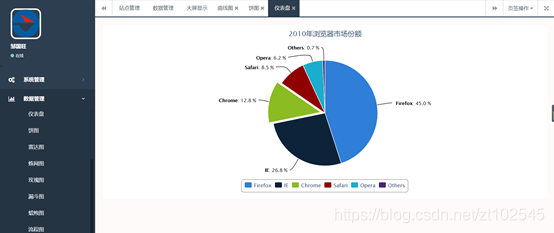
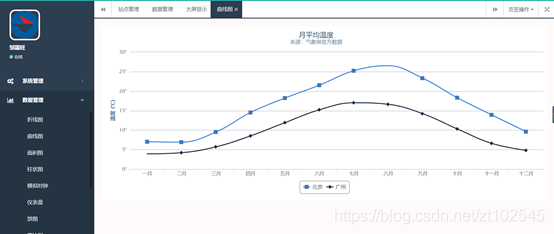
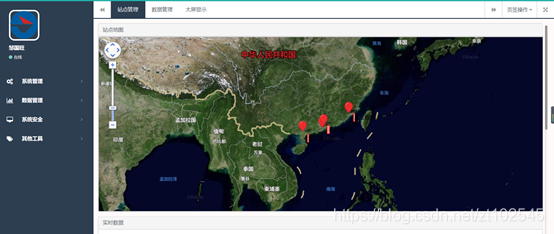
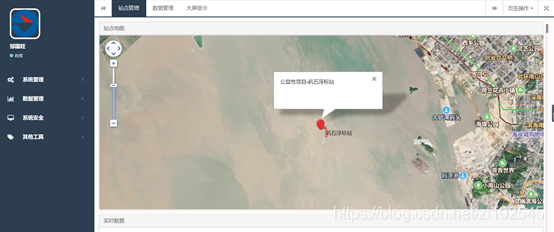
4.4.6 百度地图api
百度地图API是一套为开发者提供的基于百度地图的应用程序接口,包括JavaScript、iOS、Andriod、静态地图、Web服务等多种版本,提供基本地图、位置搜索、周边搜索、公交驾车导航、定位服务、地理编码及逆地理编码等丰富功能。

4.4.7 大屏展示
网页上的大屏预览功能,同时也可以直接投到大屏幕上展示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号