
实验5 编写、调试具有多个段的程序
(1)将所给的程序编译连接,用Debug加载、跟踪,然后回答问题。
因为题一的代码在实验框架中已经给出了,直接进行Debug的相关操作。
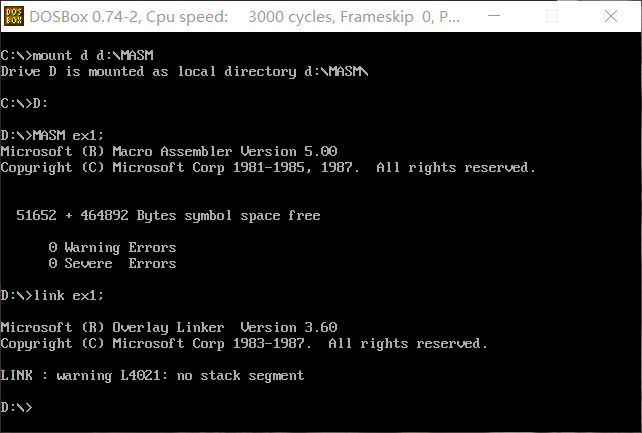
对ex1的asm文件进行编译和连接生成obj和exe文件。
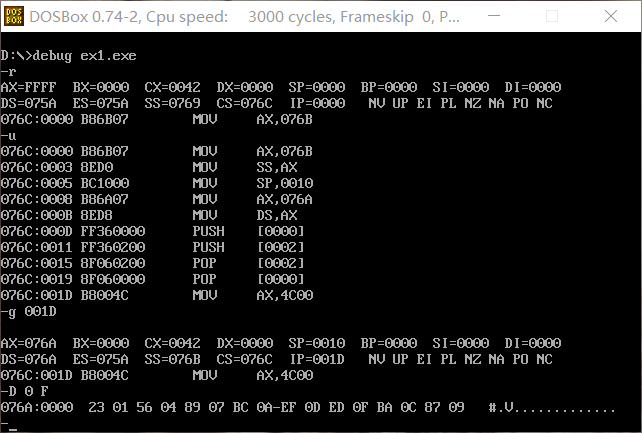
用Debug加载可执行文件ex1并跟踪。先用指令查看内存此时的情况,可以看到cx的值为42即为程序的长度为0042h。因为程序给出了start指令指明了程序的入口,所以直接使用u命令进行反汇编,得到了程序执行的汇编代码及其所对应的内存状况。用g命令使程序执行到返回之前即执行到语句mov ax,4c00h之前,地址为001D,执行后可以看到内存的情况。最后用d命令查看数据段所存放的数据,可以看到就是代码段所输入的8个字数据。
<1>cpu执行程序,程序返回前,data段中的数据是多少?0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h.
<2>cpu执行程序,程序返回前,cs=0042h, ss=076bh, ds=076ah
<3>设程序加载后,code段的地址为X,则data段的地址 X-2,stack段为X-1。
(2)将所给的程序编译连接,用Debug加载、跟踪,然后回答问题。
题二的代码也在程序框架中已经给出,和题一一样对其进行编译、连接,并用Debug加载、跟踪。
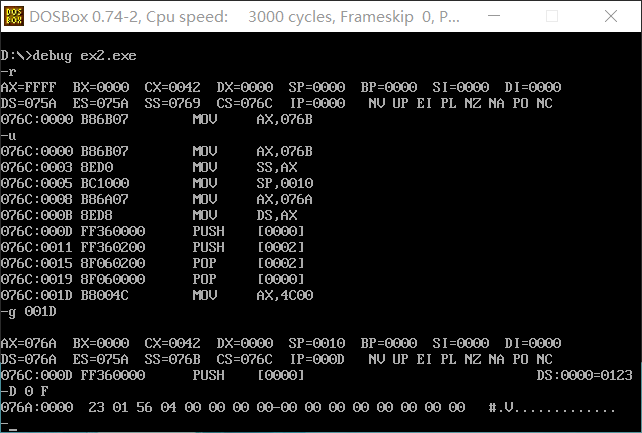
使用r命令查看内存情况后发现虽然这段程序输入的代码段比上个程序少得多可是cx的值还是0042h,其余的操作都和题一相同,不再做阐述。
<1>cpu执行程序,程序返回前,data段中的数据为多少?0123h,0456h.
<2>cpu执行程序,程序返回前,cs=076ch,ss=076bh,ds=076ah.
<3>设程序加载后,code段的短地址为x,则data段的短地址为x-2,stack段的短地址为x-1。
<4>对于如下定义的段:
name segment
…
name ends
如果段中的数据占N个字节,则程序加载后该段实际占有的空间为__([n/16]+1)*16__.
最后一题我不会所以百度了一下,大致弄懂了原理,可是还是有些许的疑惑。
在8086CPU架构上,段是以paragraph(16-byte)对齐的。程序默认以16字节为边界对齐,所以不足16字节的部分数据也要填够16字节。“对齐”是alignment,这种填充叫做padding。16字节成一小段,称为节。
一、这首先要从8086处理器寻址原理说起。
8086这种处理器有二十根地址线(20个用于寻址的管脚),可以使用的外部存储器空间可达1MB(00000H~FFFFFH)。 但是,8086内部的寄存器都是16位的,用任何一个寄存器(比如BX或SI),都无法直接寻址8086所支持的1M地址空间,因为16位寄存器只能表示640KB的空间范围(0000~FFFFH)。
所以,Intel想了一个方法,设计出了CS/DS/ES/SS这几个段地址寄存器,用段地址寄存器与普通寄存器组合,来寻址1MB的地址范围,即:对于CPU取指来说,用CS:IP组合来寻址下一个要执行的指令(也在存储器中);对于堆栈操作PUSH/POP来说,用SS:SP组合来表示当前栈指针(栈也在存储器中);对于数据操作指令来说,用默认的DS/ES或指定的段地址(段前缀指令)与偏移量寄存器组合寻址。
组合后的实际地址=段寄存器内容×16+偏移量寄存器内容
从这个公式可以看到,每一个段的地址都对齐在16的倍数上。比如DS=1234H,则这个段就从 1234H×16+0000H=12340H开始,最大到1234H×16+0FFFFH=2233FH为止。
二、对同一个内存地址,有不同的段:偏移量组合方法,比如2233FH这个地址,既可以表示为1234H:0FFFFH(在1234H段中),也可以表示为2233H:0000FH(在2233H段中)。
那么,如果汇编程序中有下面两个连续的段定义,汇编编译程序会怎么做呢?
name1 segment
d1 db 0
name1 ends
name2 segment
d2 db 0
name2 ends
编译程序可以将name1和name2编译成一个段,d1和d2在内存中连续存放,这样可以节省内存空间。比如编译程序以name1为基准,将name1作为一个段的起始,程序加载后会被放在xxxx0H的地方,那么d1就放在该段偏移地址为0字节的位置,d2就放在该段偏移为1字节的位置。
这样的处理方式虽然可能会节省一点内存空间,但是对于编译器的智能化要求太高了,它必须将源程序中所有引用到name2和d2的地方,全部调整为以name1段为基准,这实在是太难了,而且也节省不了几个字节的空间,编译器是不会干这种吃力不讨好的事的。编译器实际的处理方式是将name1中的所有内容放在一个段的起始地址处,name2里的所有内容放在后续一个段的起始地址处(这也是汇编指令segment的本义:将不同数据分段)。这样,即使name1中只包含一个字节,也要占一个段(16个字节),所以,一个段实际占用的空间=(段中字节数+15)/ 16。
所以,8086处理器的内部寻址原理和汇编程序编译器共同决定了segment定义的段必须放在按16的倍数对准的段地址边界上,占用的空间也是16的倍数。
从上面的说明可以知道,8086处理器中所定义的段占用的空间一定是16的倍数,即使不满16个字节,也要占一整个段即16个字节,所以题一和题二的cx的值都为0042h。对于公式的疑惑在于如果所需空间正好是16的倍数,那公式所求的占用空间为所需空间多16个字节,为什么不直接分配刚刚好所需的空间而要多一个段空间呢。
(3)将所给的程序编译连接,用Debug加载、跟踪,然后回答问题。
题三的代码也已经在程序框架中给出,和前两题一样对其进行编译、连接,并用Debug加载、跟踪。
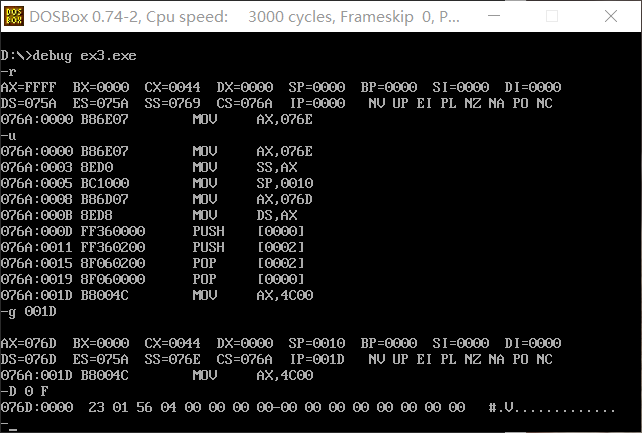
相关的操作和前两题类似,不再做阐述。
<1>CPU执行程序,程序返回前,data段中的数据为多少?
<2>CPU执行程序,程序返回前,cs=076ah,ss=076eh,ds=076dh.
<3>设程序加载后,code段的短地址为x,则data段的短地址为__x+3__,stack段的短地址为__x+4__。
(4)如果将(1),(2),(3)题中的最后一条伪指令end start改为end(也就是说,不指明程序的入口个),则哪个程序仍然可以正确执行?请说明原因。
第三个程序仍然可以正确执行,因为当不指明程序的入口时,cs:code segment的默认ip为0,第三个程序在ip为0时正好对应的是程序开始的地方即代码段,而前两个ip为0的地方存的是数据,解析为汇编指令时是错误的。所以只有第三个程序仍然可以正确执行。
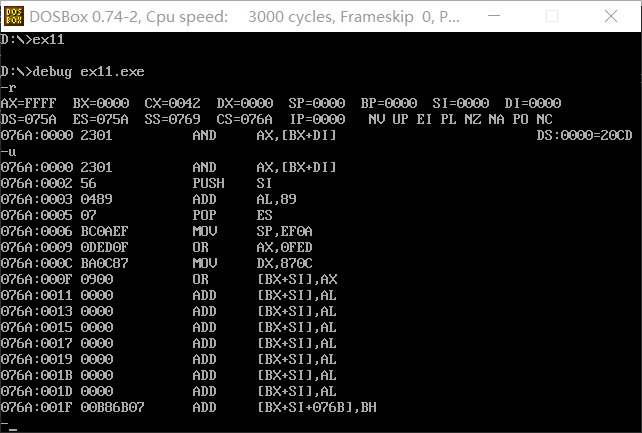
可执行文件ex11.exe即为题一的代码去除最后的start经过编译、连接所得。在上图可以看出在对程序反汇编后内存中的2301h,56h,0489h等数据即为数据段中的数据,所以解析为汇编指令时出错,无法正确执行,题二也是如此。
(5)程序如下,编写code段中的代码,将a段和b段中的数据依次相加,将结果存放到c段中。
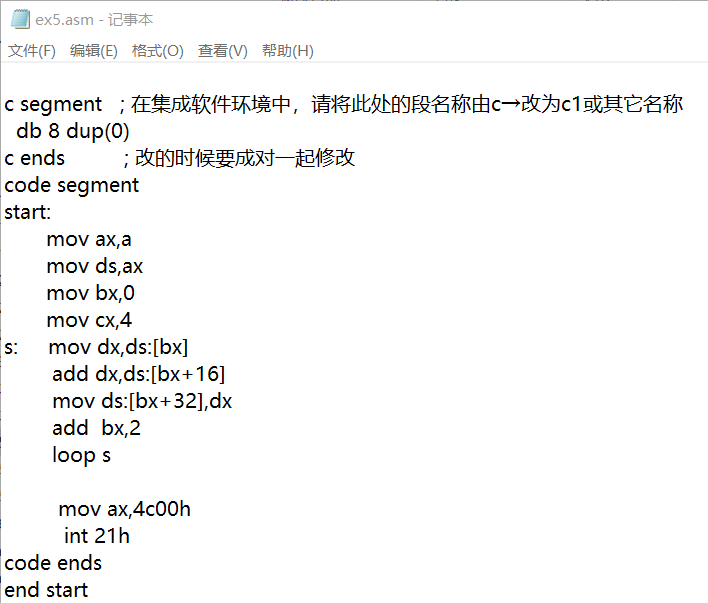
所编写的代码如图所示,先将数据段段地址指向a,bx赋值为0作为偏移地址,令循环次数cx为4,并用循环s实现将a段和b段中的数据依次相加,将结果存放到c段中。
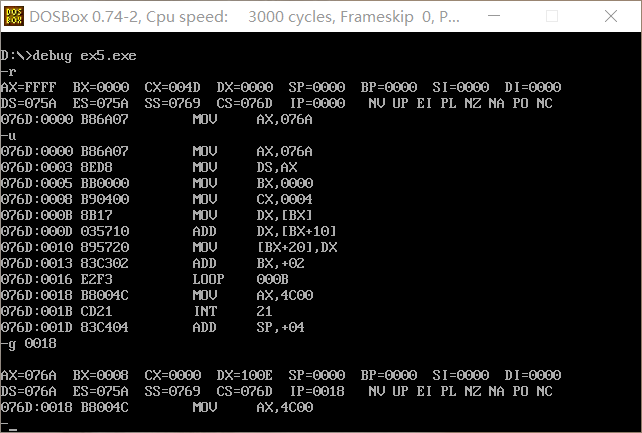
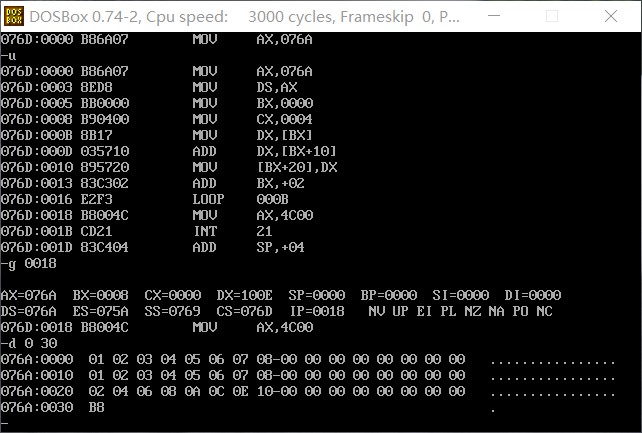
此前的编译、连接、用debug加载、跟踪都和前面的实验大致相同,不做具体的阐述。在程序执行到返回前后,用d命令查看内存中的前48个字节,因为在题三中得知无论有没有满16个字节,段都要占用16个字节的段空间,所以是查看前48个字节。可以看到前16个字节存放着a中的数据,第16个字节到第32个字节存放着b中的数据,在最后16个字节中存放着cx的数据,已经实现了将a、b段的数据依次相加并将结果存入c段中。
(6)编写code段中的代码,用push指令将a段中的前8个字型数据,逆序存储到b段中。

将数据段寄存器指向a,栈段寄存器指向b,因为栈段分配ss:0到ss:F空间,而在栈空时栈指针sp应该指向栈底的下一个单元即为ss:10h,所以赋值sp为10h。令循环次数cx为8,执行循环s,实现用push指令将a段中的前8个字型数据,逆序存储到b段中。
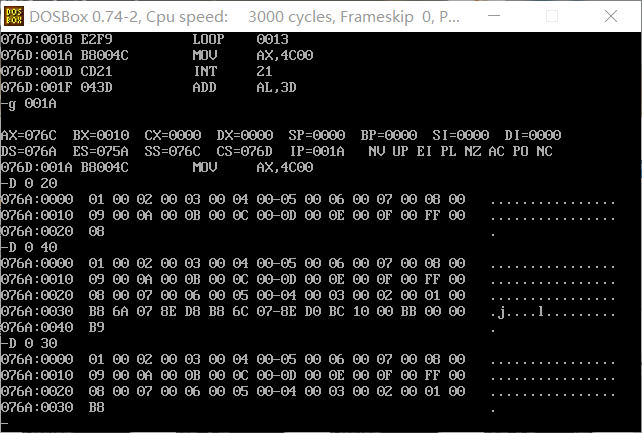
运行后用d命令可以看出,076A:0000和076A:0010所对应的32个字节空间所存放的为a中的数据,0076A:0030所在行的数据即为a的前8个字型数据逆序存储到b段中。
总结:通过本次实验,在实践中掌握了相关的知识,知道了段实际占用空间的规则以及程序入口在什么样的程序中必须存在什么样的程序中可以没有。对汇编的内部结构有了更加鲜明的认识,但是在实验的过程中仍然有许多的疑问,日后慢慢去一个个攻破。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号