


日志分析查看—— cat+grep+awk+uniq+sort+wc+join
有个统计日志信息的需求,下面是使用到的命令
//按 \t 对文件每一行进行切割,正则匹配第二列为32896时,输出第一列;再进行排序并去重,最后统计行数 cat file.log|awk -F '\t' '{if($2~"32896") print $1}'|sort -u|wc -l // 先筛选每一行包含 32896的 包含1925598894的 ;再将筛选后的每一行 按 \t 进行分割 输出每一行的第一列 ;再进行排序去重;最后统计行数 cat file.log |grep 32896|grep 1925598894|awk -F '\t' '{print $1}'|sort -u|wc -l // 先筛选每一行包含 2021-10-17 的 ;按 \t 进行分割,如果第20列正则匹配 7 为 true 输出这一行全部内容;最后将输出的内容 输入到指定的2021-10-17-01.log文件中 cat file.log|grep 2021-10-17|awk -F '\t' '{if($20~"7") print $0}' > 2021-10-17-01.log // gsub(/正则/,'替换的内容',$0) 全局替换 默认整行内容替换 即 $0 cat file.log |awk '{gsub(/-/," ",$0);gsub(/:/," ",$0);print $0}' > result.log
//排除今天和昨天产生的文件,然后删除剩下的文件
time1=`date +%Y-%m-%d`
time2=`date -d -1day +%Y-%m-%d`
ls |grep -v $time1| grep -v $time2 |xargs rm -rf
先了解一下
Shell 输入/输出重定向 : https://www.runoob.com/linux/linux-shell-io-redirections.html
Shell管道 : http://c.biancheng.net/view/3131.html
- 重定向操作符 > 将命令与文件连接起来,用文件来接收命令的输出; 例如: command > file
- 管道符 | 将命令与命令连接起来,用第二个命令来接收第一个命令的输出。 例如: command1 | command2
cat命令
用于连接文件并打印到标准输出设备上。
cat 主要有三大功能:
(1) 一次显示整个文件。$ cat filename
(2) 从键盘创建一个文件。$ cat > filename << 结束符
只能用于创建新文件,不能编辑已有文件。
例如设置结束符为 EOF : $ cat > 1.txt << EOF
编辑文件完后,只需在最后一行键入“EOF”,然后回车即可。
(3) 将几个文件合并为一个文件: $ cat file1 file2 > file
参数:
- -n 或 --number: 由 1 开始对所有输出的行数编号
- -b 或 --number-nonblank :和 -n 相似,只不过对于空白行不编号
- -s 或 --squeeze-blank :当遇到有连续两行以上的空白行,就代换为一行的空白行
- -v 或 --show-nonprinting :使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
例:
(0) 把1.txt和2.txt合并到3.txt
cat 1.txt 2.tx t> 3.txt
(1) 把 1.txt 的内容加上行号后输入 4.txt 这个档案里
cat -n textfile1 > textfile4
(2) 把 1.txt 和 2.txt 的内容加上行号(空白行不加)之后将 内容附加到 textfile3 里。
cat -b 2.txt 1.txt >> textfile3
awk 是一种处理文本文件的语言,是一个强大的文本分析工具。
创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 。
awk依次对每一行进行处理,然后输出。处理庞大文件时不会出现内存溢出或处理缓慢的问题。
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
脚本如果包含多条语句时,可以用分号分隔,处理文本时,若未指定分隔符,则默认将空格、制表符等作为分隔符。print是最常见的指令。
常用参数:
- -F:指定分隔符 相当于内置变量FS
- -v:赋值一个用户定义的变量,-v 变量名=value ,变量名区分字符大小写。
- -f:调用脚本文件
内置变量:
$n : 指定分隔的第n个字段,如$1、$3分别表示第1列、第3列
$0 :当前读入的整行文本内容
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
- BEGIN{ 这里面放的是执行前的语句 } 只执行一次
- END {这里面放的是处理完所有的行后要执行的语句 } 只执行一次
- {这里面放的是处理每一行时要执行的语句} 一行执行一次
- 所有命令都要写在{}里
awk -F '分割符' 'BEGIN{脚本语句} {脚本语句} END{脚本语句}'
使用内置变量
awk -v FS='指定输入分隔符' -v OFS='指定输出分隔符' '{}'
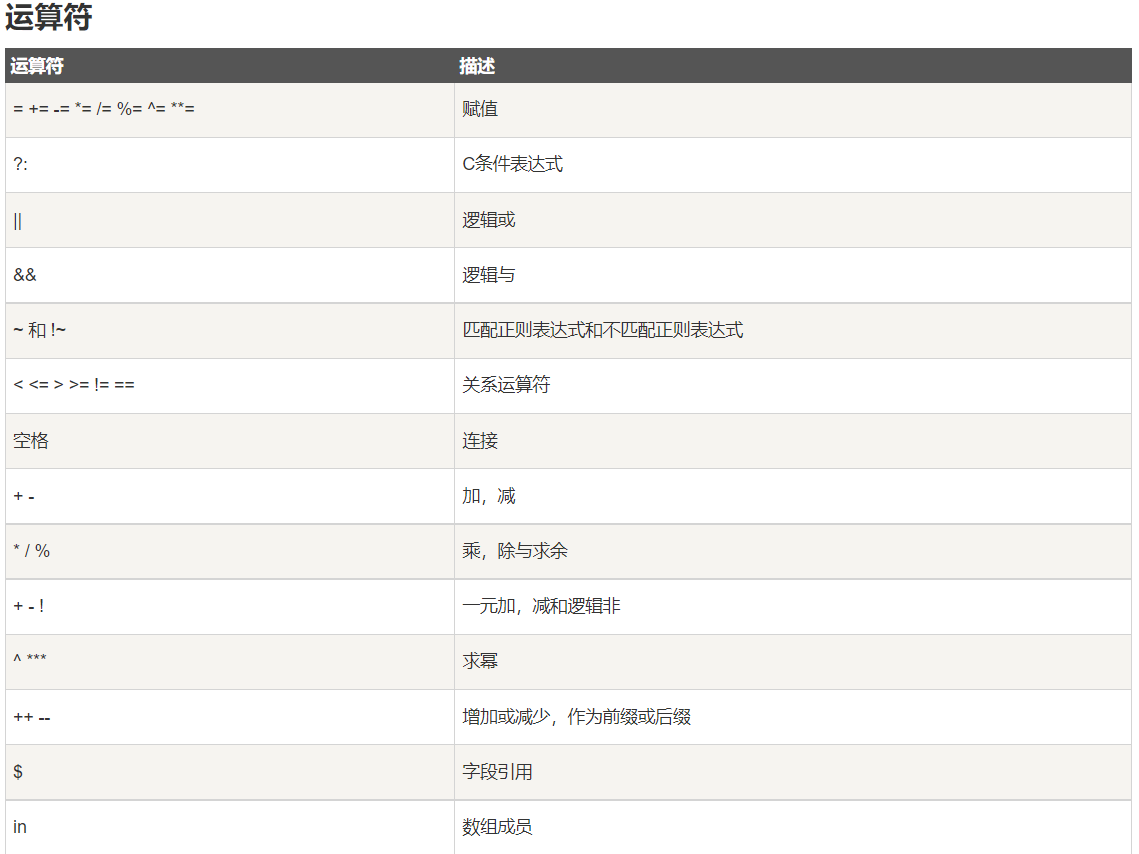
awk内置函数: https://www.runoob.com/w3cnote/awk-built-in-functions.html
详细教程请参考:https://www.runoob.com/linux/linux-comm-awk.html
awk -F '\t' 'length($1) == 32 {print $1}' > file
Linux sort 命令用于将文本文件内容加以排序。sort 可针对文本文件的内容,以行为单位来排序。
sort file //该命令将以默认的方式将文本文件的第一列以 ASCII 码的次序排列,并将结果输出到标准输出。默认升序
参数说明:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
- [-k field1[,field2]] 按指定的列进行排序。
uniq 命令
Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。
当重复的行并不相邻时,uniq 命令是不起作用的。先使用sort进行排序,再使用uniq命令
sort file | uniq
- -c或--count 在行首显示该行重复出现的次数
- -d或--repeated 仅显示重复出现的行列。
- -f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
- -s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
- -u或--unique 仅显示出一次的行列。
- -w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
grep 命令
用于查找文件里符合条件的字符串
- -a 或 --text : 不要忽略二进制的数据。
- -c 或 --count : 计算符合样式的列数。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
grep -F -x -f fileA fileB
-F表示按固定字符串而非正则表达式进行匹配。-x表示只匹配整行。-f fileA表示匹配文件A中的文本。fileB是目标文件。
这个命令将会输出文件B中存在于文件A中的所有行。
wc 命令
wc命令用于计算字数。利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 显示行数。
- -w或--words 只显示字数。
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。
$ wc testfile # testfile文件的统计信息 3 92 598 testfile # testfile文件的行数为3、单词数92、字节数598
$ wc testfile testfile_1 testfile_2 #统计三个文件的信息 3 92 598 testfile #第一个文件行数为3、单词数92、字节数598 9 18 78 testfile_1 #第二个文件的行数为9、单词数18、字节数78 3 6 32 testfile_2 #第三个文件的行数为3、单词数6、字节数32 15 116 708 总用量 #三个文件总共的行数为15、单词数116、字节数708
comm 命令
Linux comm 命令用于比较两个已排过序的文件。
这项指令会一列列地比较两个已排序文件的差异,并将其结果显示出来,如果没有指定任何参数,则会把结果分成 3 列显示:第 1 列仅是在第 1 个文件中出现过的列,第 2 列是仅在第 2 个文件中出现过的列,第 3 列则是在第 1 与第 2 个文件里都出现过的列
参数:
- -1 不显示只在第 1 个文件里出现过的列。
- -2 不显示只在第 2 个文件里出现过的列。
- -3 不显示只在第 1 和第 2 个文件里出现过的列。
join命令
Linux join命令用于将两个文件中,指定栏位内容相同的行连接起来。
找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。
参数:
- -a<1或2> 除了显示原来的输出内容之外,还显示指令文件中没有相同栏位的行。
- -e<字符串> 若[文件1]与[文件2]中找不到指定的栏位,则在输出中填入选项中的字符串。
- -i或--igore-case 比较栏位内容时,忽略大小写的差异。
- -o<格式> 按照指定的格式来显示结果。
- -t<字符> 使用栏位的分隔字符。默认文件字段的分隔符是空白字符(空格),可以指定分隔符 -t, 或者 -t "," 或者-t',' 表示使用 逗号进行分割 输出时也是以指定的分割符进行分隔。 以四个空格进行分割 : -t " "
- -v<1或2> 跟-a相同,但是只显示文件中没有相同栏位的行。
- -1<栏位> 连接[文件1]指定的栏位。
- -2<栏位> 连接[文件2]指定的栏位。
join [参数] 文件1 文件2 //文件1 和文件2 的内容必须是经过排序后的,否则会报 is not sorted
-a1表示 显示第一个文件中不匹配的行,类似于sql里的left join
-a2 表示 显示第二个文件中不匹配的行,类似于sql里的 right join
-o 1.1 2.1 1.1表示输出第一个文件的第一列;2.1表示输出第二个文件的第一列
-1 1 -2 1 表示第一个文件的第一列和第二个文件的第一列关联 类似于sql 的 from a inner join b on a.第一列字段名 = b.第一列字段名
xargs 命令:
xargs 可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据
ls
- -a 显示所有文件及目录 (. 开头的隐藏文件也会列出)
- -d 只列出目录(不递归列出目录内的文件)。
- -l 以长格式显示文件和目录信息,包括权限、所有者、大小、创建时间等。
- -r 倒序显示文件和目录。
- -t 将按照修改时间排序,最新的文件在最前面。
- -A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)
- -F 在列出的文件名称后加一符号;例如可执行档则加 "*", 目录则加 "/"
- -R 递归显示目录中的所有文件和子目录。
find命令
https://www.runoob.com/linux/linux-comm-find.html
find [path] [expression]
-name pattern:按文件名查找,支持使用通配符*和?。 -iname 不区分大小写-type type:按文件类型查找,可以是f(普通文件)、d(目录)、l(符号链接)等。-size [+-]size[cwbkMG]:按文件大小查找,支持使用+或-表示大于或小于指定大小,单位可以是c(字节)、w(字数)、b(块数)、k(KB)、M(MB)或G(GB)。-mtime days:按修改时间查找,支持使用+或-表示在指定天数前或后,days 是一个整数表示天数。-user username:按文件所有者查找。-group groupname:按文件所属组查找。
find 命令中用于时间的参数如下:
-amin n:查找在 n 分钟内被访问过的文件。-atime n:查找在 n*24 小时内被访问过的文件。-cmin n:查找在 n 分钟内状态发生变化的文件(例如权限)。-ctime n:查找在 n*24 小时内状态发生变化的文件(例如权限)。-mmin n:查找在 n 分钟内被修改过的文件。-mtime n:查找在 n*24 小时内被修改过的文件。
- -a:and逻辑与
- -o:or逻辑或
- -not:not逻辑非
在这些参数中,n 可以是一个正数、负数或零。正数表示在指定的时间内修改或访问过的文件,负数表示在指定的时间之前修改或访问过的文件,零表示在当前时间点上修改或访问过的文件。
-exec选项 -exec 命令{} \; "{}"代表 find 命令的査找结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号