

zookeeper kafka
一、Zookeeper
是开源的分布式应用程序协调服务
用来保证数据在集群间的事务一致性(比如访问集群中的一台机器,刷新访问另一台时数据一致)
(一)应用场景
1. 集群分布式锁
2. 集群统一命名服务
3. 分布式协调服务
(二)角色
1. Leader 接受所有Follower的提案请求并统一协调发提案的投票,负责与所有的Follower进行内部数据交换
2. Follower 直接为客户端服务并参与提案的投票,同时与Leader进行数据交换
3. Observer 直接为客户端服务但不参与提案的投票同时也与Leader进行数据交换
角色的选举 服务器在启动的时候是没有角色的 会在启动的机器中自动选取一台当做Leader其他的作为Follower
选举Leader的原则 过半的投票,如果Leader宕机 那么会重新选举,但是重新选举也是会在算在所有机器比如,刚开始有八台机器,损坏一台选举的时候还是需要投五票,宕机的数量是四台那么整个集群就会宕机
(三)zookeeper的原理
Client访问服务器发送写请求,服务器把写请求发给Leader向所有的机器发送信息 在所有的机器中投票,Leader收集所有机器的投票结果,分析是否执该操作,当判定是什么操作之后就发送给所有的节点机器,节点机器再发给Client
如果增加Follwer节点,那么则是增加了投票的压力,必须投票过半才能执行下步操作,有的节点性能不好饿那话那么会影响集群的运行速,所以有了OBsrever 不参与投票和Leader交互 和其他服务器在Leader收集到投票结构后一起得到投票的结果
Observer 提供广域网的性能可以在本地创建集群在其他地区创建Observe机器
(四)安装zookper
1.安装 javaopenjkd
2.修改host文件
(五)配置文件
文件名应该是zoo.cfg 如果没有就把zoo_sample.cfg文件改为zoo.cfg

在配置文件最后一行中添加上图中的这几行
1,2,3,4 为ID范围(1-255) 在相应的主机中必须配置这个id
后缀有角色的就是不参与选举
配置一个之后传给其他的节点,创建数据目录,在数据目录中必须有一个文件myid对应上图中的id
(六)启动服务


要把所有节点都启动不然 会报错
需要查每台机器的状态 需要登录到机器上 把上图中的 start 换成 status,这样的话比较麻烦,在zookeeper的管理员手册中 可以通过api 进行操作
网址: https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html

交互查询 第二个参数 是指元数据 - 是指本地的数据

通过上图中的四字命令查询

查询 zookeeper 状态 恢复imok 说明正常
解释shell
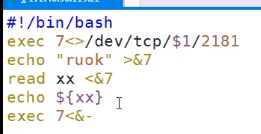
exec 打开一个文件描述符
7 因为0 1 2 标准输入输出错误都被占用 所用 0 1 2 除外随便一个都行
$1 表示 主机名
<>读写方式 <读 >写
echo ‘ruok’ > &7 把命令传给 描述符7
&- 关闭描述符
#!/bin/bash function getzkstat(){ exec 2>/dev/null exec 8<>/dev/tcp/$1/2181 echo stat >&8 Msg=$(cat <&8 |grep -P "^Mode:") echo -e "$1\t${Msg:-Mode: \x1b[31mNULL\x1b[0m}" exec 8<&- } if (( $# == 0 ));then echo "${0##*/} zk1 zk2 zk3 ... ..." else for i in $@;do getzkstat ${i} done fi
上面的代码可以查询 zookeeper集群哪个是 Leader 哪些是Follwer

二、kafka
是分布式消息系统
是一种消息的中间件
(一)优点
- 解耦、冗余、提高扩展性、缓冲
- 保证顺序、灵活、削峰填谷
- 异步通信
(二)kafka的角色
(1)preducer:生产者,负责发布消息
(2)consumer:消费者负责读取处理消息
(3)topic:消息的类别
(4)parition:每个topic包含一个或多个parition
(5)beoker:kafka集群包含一个或者多个服务器
kafka通过zookeeper管理集群配置选举Leader
(三)结构图
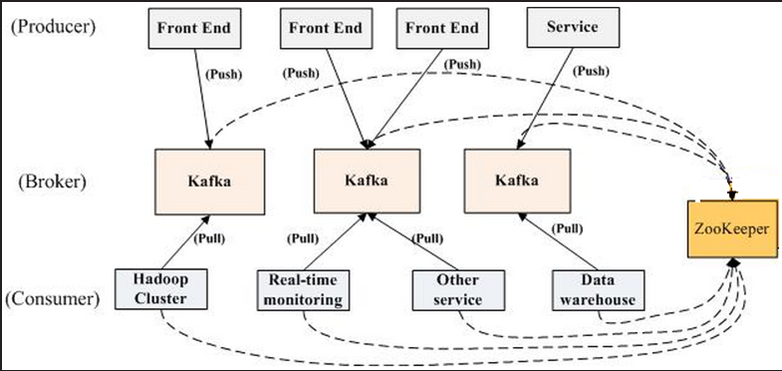
数据库优化 读缓存写队列
(四)安装kafka流程
(1)kafka集群的安装依赖zookeeper 搭建kafka集群之前 请先创建好一个可用的zookeeper集群
(2)安装openjdk
(3)同步kafka拷贝到所有集群主机
(4)修改配置文件
(5)启动验证
(五)安装
配置文件

配置两个参数
(1)broker.id 每台服务器都不能一样(1-255随便选)
(2)zookeeper.connect (zookeeper的地址可以写多个 逗号隔开)
修改完这两个参数拷贝到所有kafka节点 修改broker.id这行的参数
(六)启动

启动时要加上 -daemon 在上server.properties的绝对路径
所有的kafka主机都要输入这个命令
(七)验证集群

创建了消息之后 在第二台机上输入信息 在第三台机上能够看得到那么就证明 集群创建成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号