Elasticsearch
1. 理解ES的核心概念
使用场景:
模糊查询(替代mysql的like %全模糊% like %左模糊)
全文检索(替代mysql的全文索引)
基本概念:
Index:索引,含有相同属性的文档的集合,数据管理的顶层单位。(类比mysql的表)
由一个名字来标识(不允许有大写字母,格式: [0-9a-z-_]{1,255} )
在一个集群中,可以定义任意多的索引
Type:类型,虚拟概念,文档的分组。
v5.0:一个Index下允许有多个Type
v6.0:一个Index仅允许有一个Type
v7.0:一个Index仅允许有一个Type,Type被废弃
v8.0:Type被移除
Document:文档,Index内的单条记录。(类比mysql的记录)
数据类型有:text、keyword、数值类型、boolean、date
其他数据类型:geo_point(地理类型,横纵点,即经纬度)、completion(特殊类型,提供自动补全推荐功能)
(题)为什么要废弃Type?
因为Type会被滥用,滥用造成的问题:
1.当程序设计按照Index做为最上层的管理单元时,当不同Type的同名Field的类型不同时,便玩不转。
2.同一索引中存储几乎没有公共字段的不同实体会导致数据稀疏,并干扰Lucene高效压缩文档的能力。(类比mysql:把项目中所有的表的所有字段都平铺在一个表里)
二、ES的映射
映射:mapping,定义了文档的每个字段(Field)的数据类型。
映射策略:
动态映射:根据插入的数据动态生成。
静态映射:预定义【推荐】
推荐静态映射的原因:
1.索引的mapping不支持修改,一旦被自动创建,则无法修改。 例如:日期的字符串映射为text类型,则无法修改回date类型,只能数据迁移。
2.自动映射的规则不一定符合业务的需要。 例如:会自动生成ignore_above设置,超过ignore_above的字符串将不会被索引或者存储,会导致数据的丢失。
3.不合理的映射会造成大量的空间浪费以及性能损耗。
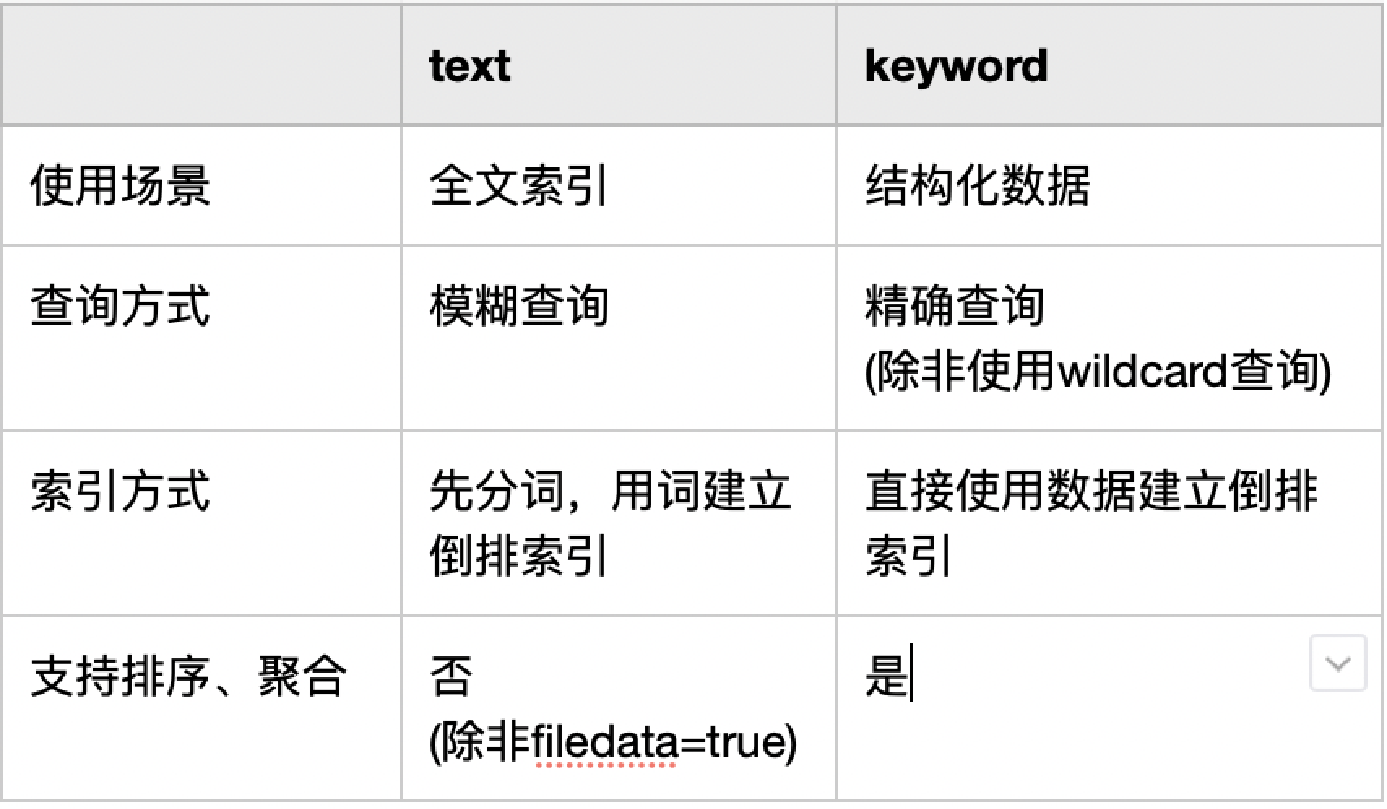
三、keyword与text的区别
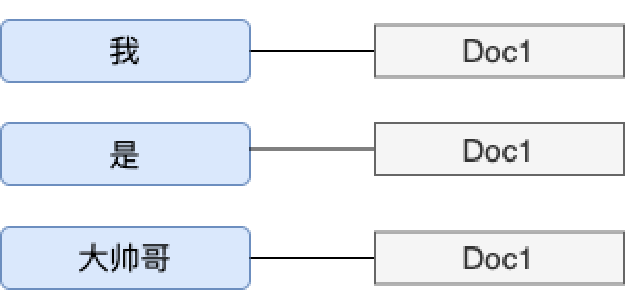
什么是倒排索引?
倒排索引:可以通过关键词找文档,先分词,按照词建立索引。
keyword与text建立倒排索引的区别:
keyword
![]()
text
四、查询API
用Query DSL(增删改查的Restful API),格式:
POST <index>/<type>/_search
查询结果组成部分:
最条数:total
最大分数:max_score
命中数据:hits [数组内对象含score]
分:score,标示了文档的匹配程度
查询请求组成部分:
查询:query,计算分值的查询条件
过滤:filter,不计算分值的查询条件 (尽可能使用filter,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存,性能很高)
排序:sort,按照什么列正序/倒序排列。
分页:from,size,偏移量、位移量
挑选:_source 返回哪些数据
聚合:aggregations,基于查询结果的加工。
查询的逻辑分类:类比为sql语句 where xx and xx or xx
简单查询:单条件查询
match查询:对查询的入参做分词后,再进行查询。
term查询:对查询的入参不做分词,直接用于进行查询。
复合查询:多条件逻辑查询(与、或、非)
通配符(wildcard)查询:影响性能,慎用“避免以*或?开头的模式”
高亮(highlight)查询:分词器分的词会自动添加高亮
模糊(fuzzy)查询:基于相似度的针对词查询拼写错误的自动修正
五、ES的分析器
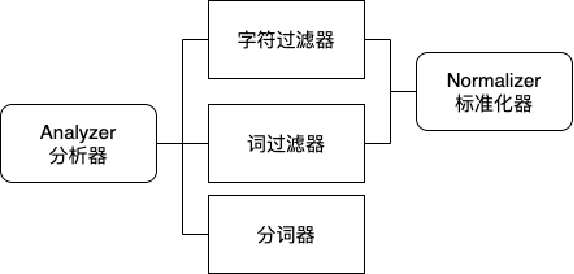
分析器(Analyzer):
Character filters:字符过滤器,文本预处理。
Tokenizers:分词器,文本分词。
Token filters:词过滤器,对词进行加工,转换(大小写),去除(停用词),增加(同义词)[此工作也可以在分词器完成]

分析器与分词器的关系:分析器包含分词器。
Normalizer:标准化器,类似于分析器,由字符过滤器与词过滤器组成,仅对单个词有用,用于keywrod数据类型。
六、ES的分词器
分词器职责:
1.分“词”(为了搜索)
2.记录每个词的位置信息(为了近似查询)
3.记录每个词的起始与结束的偏移量(为了高亮)
中文分词的难点:
1.词的边界难以确定
英文的书写单位是词,中文的书写单位是字
英文的词之间有空格,中文的词之间没有明显的区分标记
2.词的定义难以规范
3.歧义词难以切分:爱国情感、保证金融安全
4.新词频出:蓝瘦香菇、奥力给
研究方法:
1.基于词典的分词算法:应用最广泛、分词速度最快的算法 【常用】
2.基于统计的分词算法:NLP机器学习方向。
常见的开源的中文分词器:分词准确率与学习成本:从上到下,依次递增
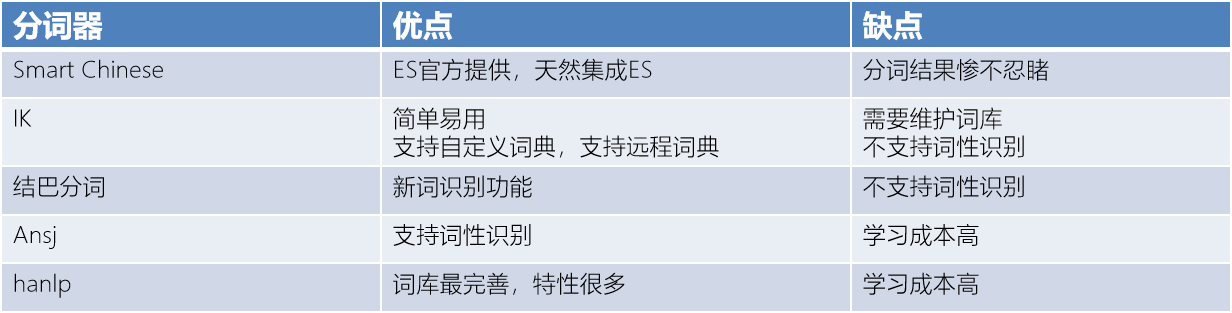
(面试题)为什么使用IK分词器,不使用其他的分词器?
从场景分析,有通用搜索(例如百度、谷歌)和垂直搜索(例如淘宝、链家),根据匹配度分析,IK可以支持自定义词库,符合垂直搜索领域需求,且学习成本低,成熟度高。
IK词典的两大规则:
智能模式 :ik_smart 属于最粗粒度的拆分(对于特定领域的搜索,我们一般选用ik_smart )
细粒度模式 :ik_max_word 穷举所有可能词,属于最细粒度的拆分
例子:南京市长江大桥
智能模式:南京市、长江大桥
细粒度模式:南京市、南京、南、市、市长、长江大桥、大桥
ik的词典热更新原理:
热更新频率:ES启动10s后加载,之后60s
原理:
1.定时线程:60s HEAD轮询一次远程接口
请求头:If-Modified-Since=上次返回的Last-Modified、If-None-Match=上次返回的ETag)
2.更新判断(Dictionary#initial):响应头的Last-Modified或者ETag与上一次是否不同
3.触发更新(Monitor#runUnprivileged): GET访问远程接口
HTTP Response Header:
Last-Modified:资源的最新修改时间
ETag:资源的标记(主要解决内容不变但Last-Modified的问题)
HTTP Request Header:
If-Modified-Since:通过最后修改时间,判断当前请求资源是否改变,若改变,应返回200,否则返回304
If-None-Match:通过资源标记,判断当前请求资源是否改变,若改变,应返回200,否则返回304
HTTP Response Code: 304: Not Modified,未修改

 浙公网安备 33010602011771号
浙公网安备 33010602011771号