
Mysql索引原理
1.SQL与Mysql区别
· SQL(Structured Query Language)是一种查询数据库的标准计算机语言,可以查询关系型数据库,包括但不限于Mysql。
· Mysql是关系型数据库,支持SQL语言,但不支持全部的SQL(例如full outer join)
2.Mysql与Oracle使用场景区别
金融场景会使用Oracle
3.RDMS与NoSQL的主要区别
· 强一致性、弱一致性
· 不可水平拓展、可水平拓展
4.什么是NewSQL
可水平扩展的RDMS,代替“中间件+关系型数据库分库分表”,例如TiDB、OceanBase
5.Mysql客户端与服务端通讯方式
三种:1. TCP/IP 2. 命名管道和共享内存【Windows】 3. Unix域套接字文件【Unix系】
6.Mysql的逻辑分层及各层职责
逻辑分层:其中分为server层和存储引擎层
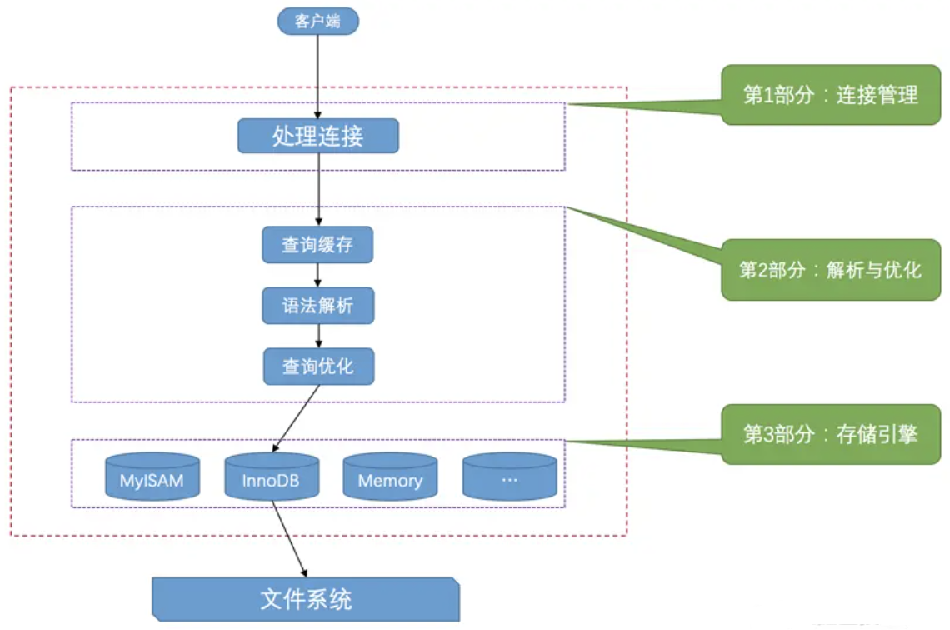
各层职责:
server层:用于连接管理、解析与优化
例如:查询缓存(8.0删除)、语法解析、查询优化(执行计划 EXPLAIN)
存储引擎层:负责数据的存储和提取
例如: InnoDB(常用且默认)
为什么移除查询缓存?
因为表的任何变动都会使查询缓存失效,且前后两次查询的sql语句必须一致
7.什么是索引,索引的优缺点
索引是帮助Mysql高效获取数据的一种数据结构
优点:加快查询速度(若不使用索引,则全表扫描)
缺点:需要额外的存储空间
8.索引的分类
-根据实现的数据结构区分:
B+树索引(InnoDB,MyISAM存储引擎)
Hash索引(Memory存储引擎)
-按照约束(或者创建语句)区分:
普通索引: CREATE INDEX
唯一索引: CREATE UNIQUE INDEX
主键索引: 创建表自带, { PRIMARY KEY (`id`) }
全文索引: CREATE FULLTEXT INDEX【没人用,ES替代】
-按照索引列的数量区分:
单列索引
联合索引(复合索引、组合索引)【最左匹配原则】
-按照存储的内容区分:
聚簇索引:存储了索引列与数据【索引即数据,数据即索引】
非聚簇索引(辅助索引/二级索引):存储了索引列与主键
9.Key(键)与Index(索引)的区别
Index:方便查询
Key:方便查询 + 约束(主键、唯一键、外键)
10.最左匹配原则
以最左边的为起点任何连续的索引都可匹配
11.什么是Mysql的标记删除
当执行delete语句删除数据,并不会把这条数据完全删除,而是保存页中的"垃圾链表"中,并标记标志位为删除,表示该数据已删除,并空出该条数据的空间。
12.记录的页内插入
当插入新数据时,就会先从"垃圾链表"中找到已经标志为删除的记录地址,如果没有,再去未分配的空间中找到未使用的空间最小地址。插入策略分为:物理有序和逻辑有序
13.记录的页内查找
页中有一个"Slot区",它的作用就是加快查找速度,如果没有"Slot区",则通过next_record(类似指针)来查找数据,时间复杂度为O(N),如下图,查找一个id=3的数据
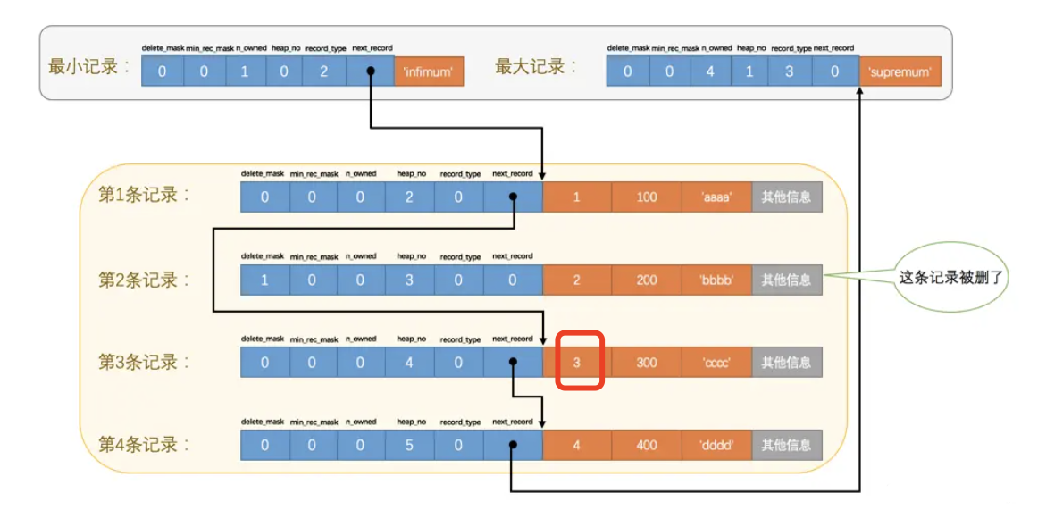
Slot区,也称Page Directory区,页目录区,它记录页中的某些记录的相应位置,这个过程:先由Slot(槽),对页内记录(包括最大最小记录,不包括已删除的记录)进行分组,每个组的最后一条记录(也就是组内最大的记录)的地址偏移量即为槽,查找过程中,先用二分查找确定该记录所在的槽,因为组是单向链表,无法逆序查找,所以要找到该组的最小记录通过next_record遍历该槽所在组中的各个记录,直到遍历到要查找的那条数据,时间复杂度为O(log2N)。
14.Mysql无主键怎么办
当创建的表没有主键,并且也没有NOT NULL的UK(唯一键),则系统会默认分配一个row_id来充当主键
15.什么是页分裂
假设一个页只能存储3条数据,此时要插入一个id=4的记录,如下图
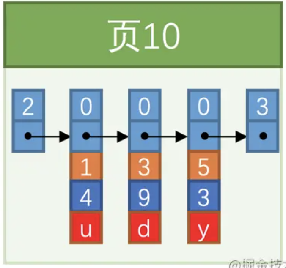

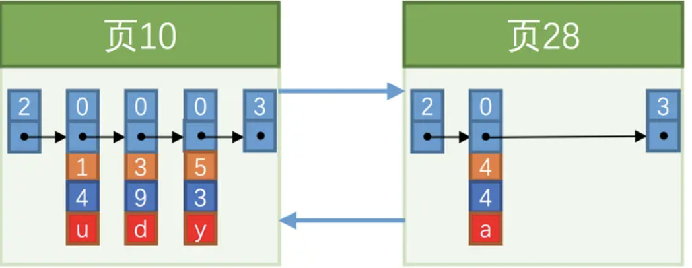
因为下一个页中的用户记录的主键值必须大于上一个页中用户记录的主键值,(所以Mysql主键不建议使用UUID,容易页分裂,影响插入效率和页的利用率)这时发生如下图情况,
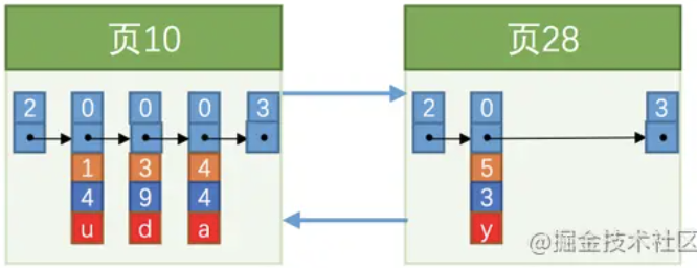
即当我们对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作,这个过程我们称为页分裂。
16.什么是行溢出
当记录中的数据太多,当前页放不下的时候,会把多余的数据存储到其他页中的现象
17.Hash索引和B+树索引
Hash索引:存储的时候先做一次hash运算,根据 hash 的值就可以快速的定位数据的磁盘指针,查询效率都非常的快;缺点:如果遇到类似select * from t where clo2 > 6这种查找范围的sql语句,就不会走Hash索引,包括排序也没有办法使用Hash索引。
B+树索引:非叶子节点不存储数据,只存储索引,这样可以放更多的索引;叶子节点存储数据,同时叶子节点使用指针连接,提高了区间访问的性能,并且从左到右是依次递增,提高查询效率。
18.二叉树到B+树的演进过程
二叉树索引的特点是左边的子元素小于父元素,右边的子元素大于父元素,当有极端情况,例如单边递增的二叉树,即所有数据都在右节点,这样就和全表扫描一样,效率低下
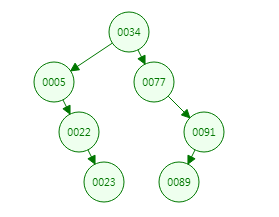
二叉树优化之后,变成红黑树索引,它的特点是当单边的节点大于3时候,就会自动调整,这样可以解决二叉树的弊端;红黑树也叫平衡二叉树,缺点是当数据量特别大,红黑树的高度就非常高,若我们要查找的数据刚好是叶子节点,就要从根节点查找到叶子节点,树有几层高,就要进行几次磁盘I/O操作,降低性能。
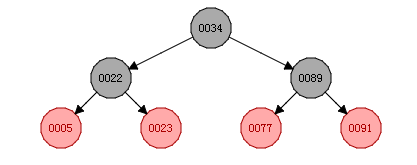
红黑树优化之后,变成B-树,它的特点是叶子节点具有相同的深度,叶节点的指针为空;所有索引元素不重复;一个节点可以存储多个元素,节点中的数据索引从左到右递增排列,缺点是若一个节点申请的空间大小为16KB,当存储的数据越大,则每个节点可以存储的数据就越小,后果就是树的高度变高(比红黑树高度小)。
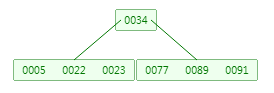
最后优化成B+树索引,与B-树相比,B+树只有叶子节点存储数据,非叶子节点存储索引,这样可以存储更多的索引;叶子节点之间是双向链表,对于范围查找更快,查找49的记录,如下图
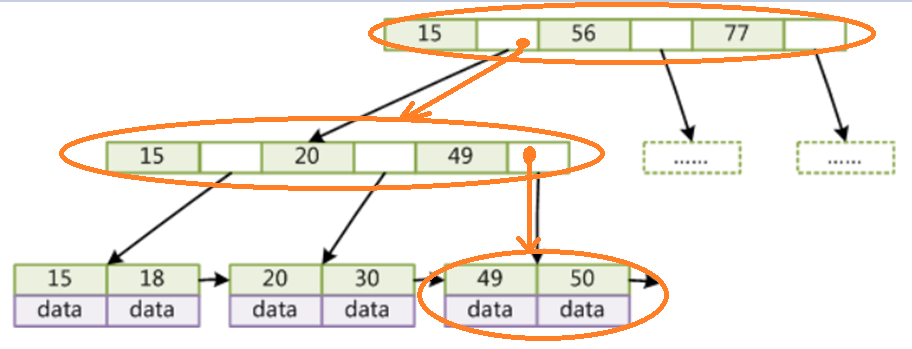
19.什么是索引覆盖
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表。例如 select id ,col1 from tableA where col=1,其中col1是索引
20.为什么不建议使用select *
会出现回表的情况
21.什么是回表
通过辅助索引查询到的数据,不包含用户查询的全量数据,即 select * from tableA where col1 = 1,就需要用主键去聚簇索引再次查询的过程就是回表,(随机I/O,影响效率和性能)
22.为什么要索引下推
从5.6+,可以有效减少回表次数,从而提高效率
使用索引下推,当存在索引的列做为判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号