
强化学习
基本的流程图
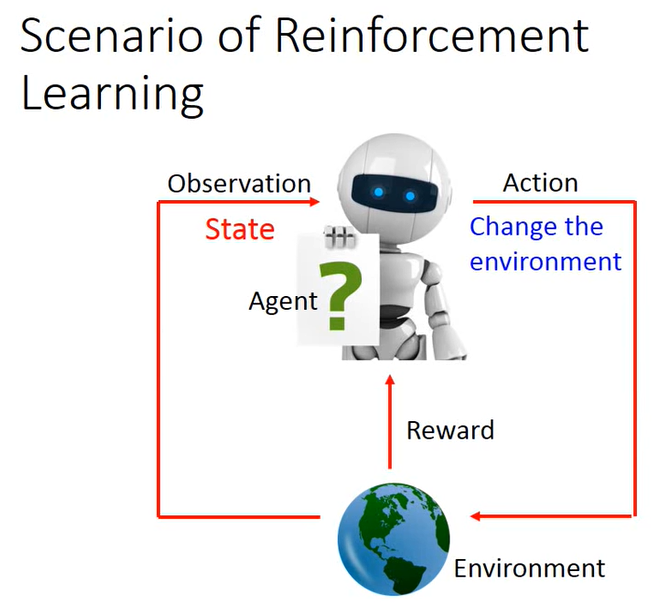
机器通过观测环境的状态来进行考虑做出哪一些相应的action,然后做出的action又会相应的影响环境的状态,影响环境的状态之后环境又会反馈给机器,使其得知当前的影响是正向的还是负向的。
强化学习相对于监督学习的优势。强化学习主要是用于在环境很少能给出reward的情况下(我们人很难知道围棋下哪一步是正确的,也就是很难给数据打标签)
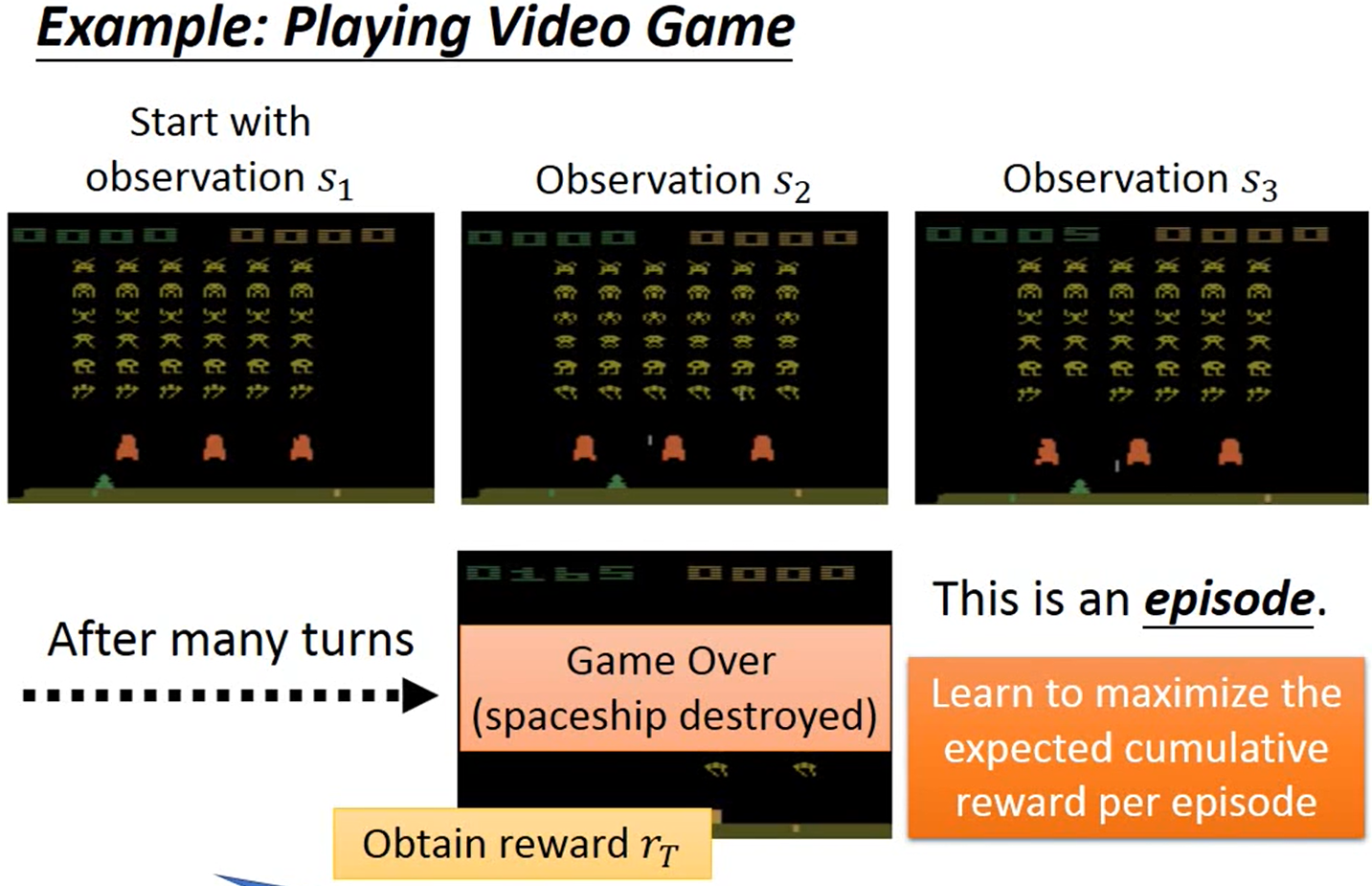
一次训练的过程成为一次episode,目标是在一次episode内尽可能多的最大化reward
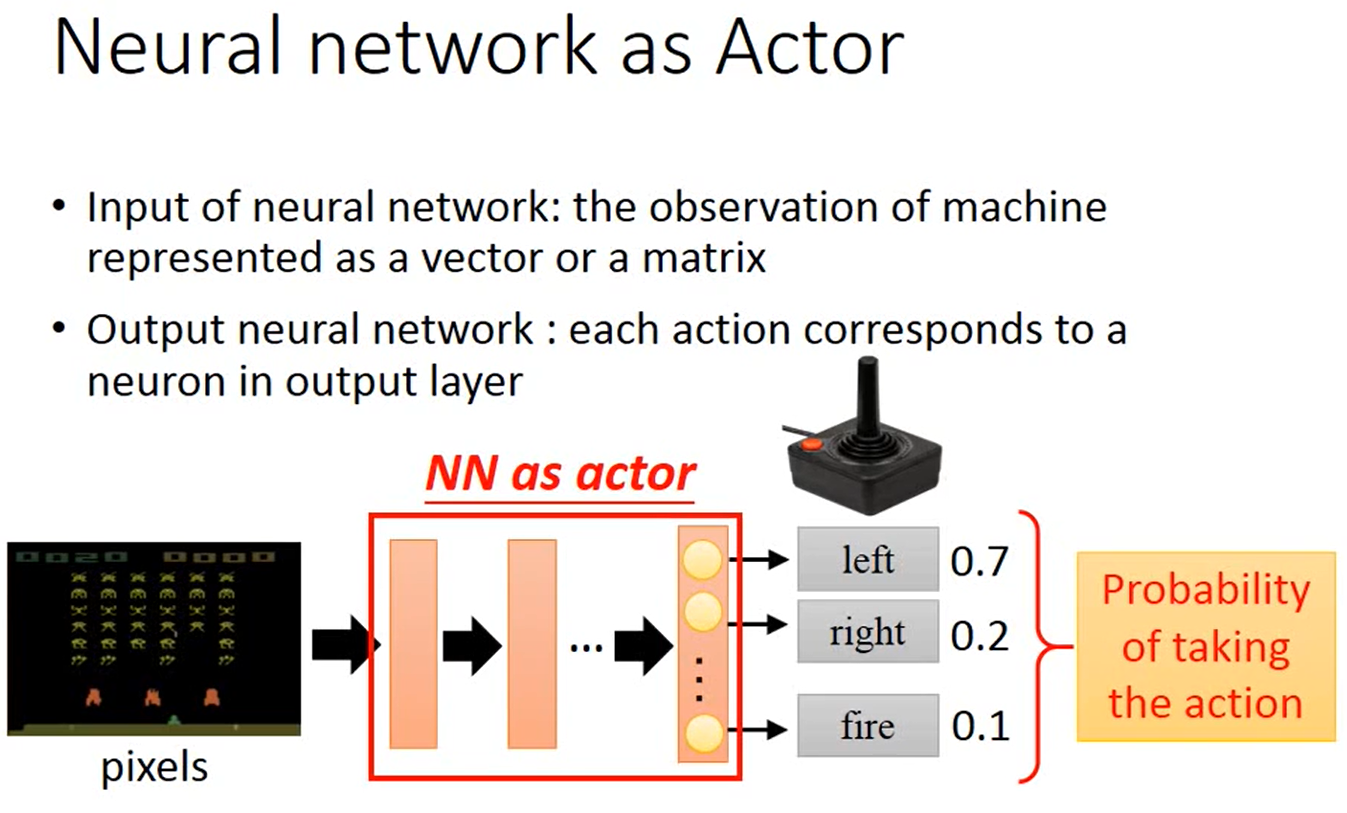
用神经网络来做反应器,训练好神经网络来给出下一步做的每种动作的相应的概率
整体的过程
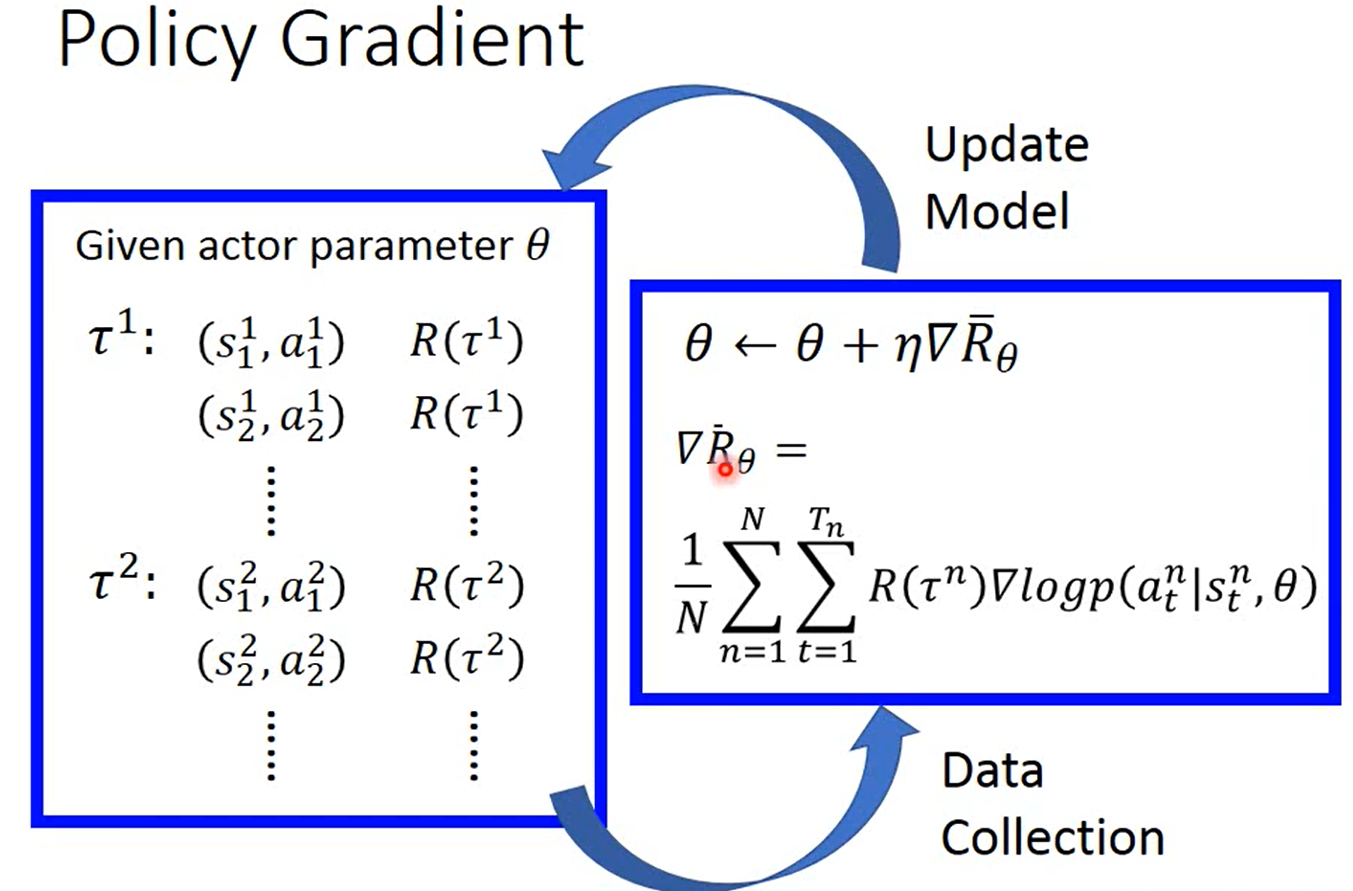
θ是模型(决定该哪些动作)的参数
T1是第一次训练,在这一次训练中,它会在state(1)-state(t)的情况下相应的根据概率来选择来做出action(1)-action(t),相应的reward也会被计算出来。在收集完这n次训练后,会根据公式来对这n次reward的值进行计算然后进行梯度下降,然后更新模型的参数。更新梯度的公式在下面。
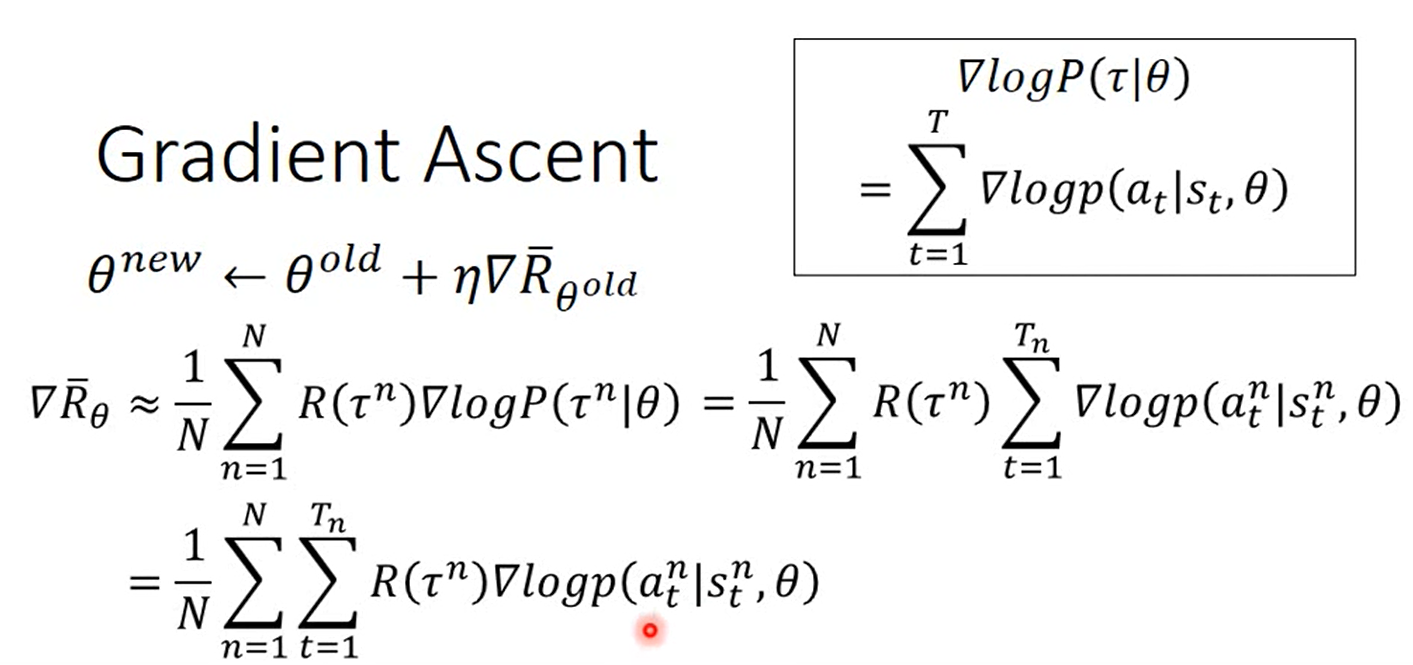
τ是一次训练的流程,τn就是训练了n次。
公式是将这训练了n次得到的reward结果乘以log(这次训练出现的概率值)进行求期望 = 将这训练了n次得到的reward结果乘以log(这次训练中所有的在situation(t)下做出action(t)的概率的和)进行求期望

如果这次训练得出的reword是积极的,应该增加这次训练里面在situation下的action的几率,反之亦然
Critic判决准则,判决评价现在是多好还是多坏
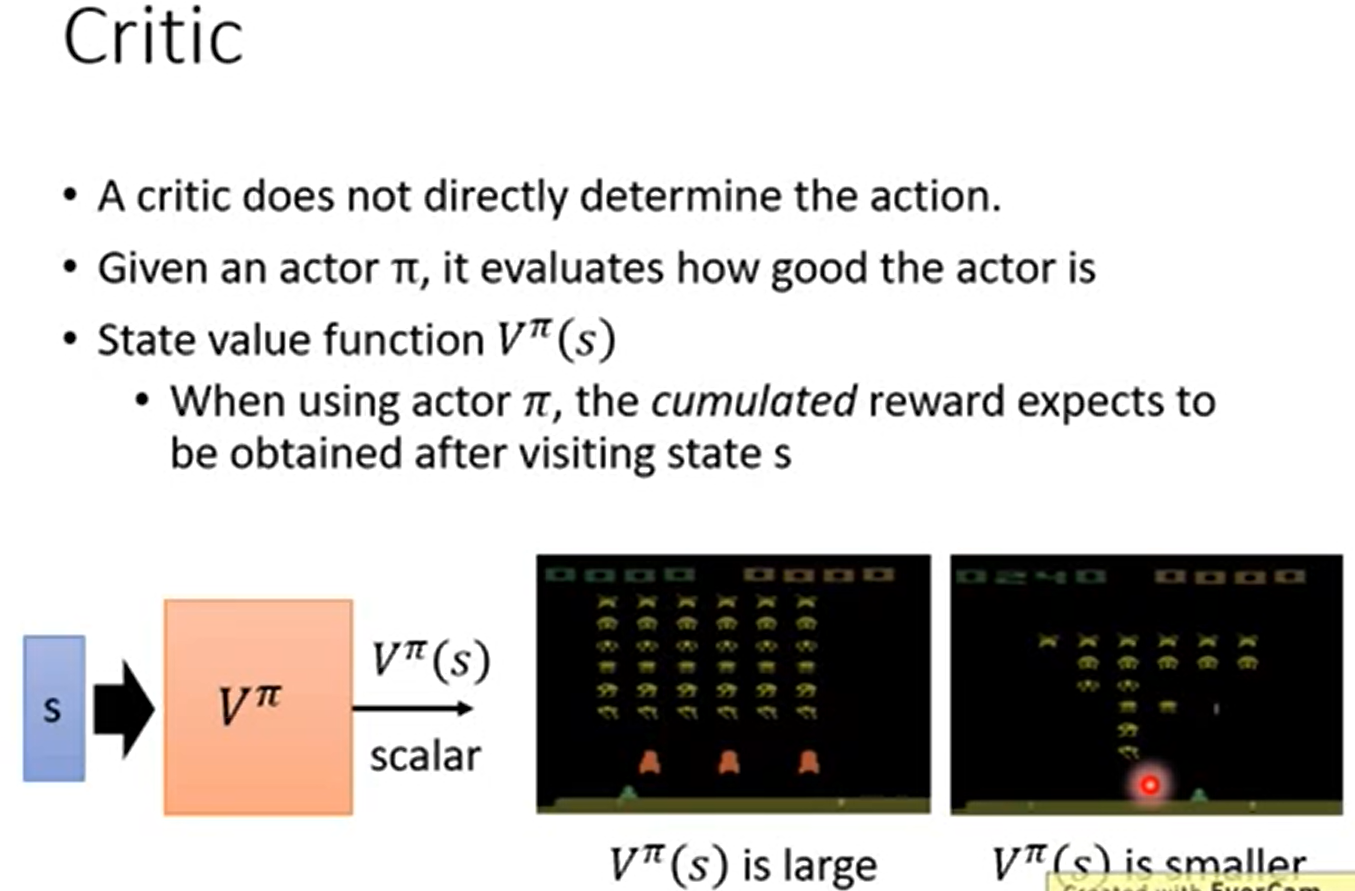
判决准则不是单独存在的(它需要与一个假设的actor动作器进行绑定),环境输入为s。Vπ(s)的意思是,在输入为s的情况下假设使用π作为当前环境而做出的下一步的动作器而最终产生的判决值。Vπ(s)就是计算出来的判决值。比如在左边的那一副游戏的途中,飞机有护罩而且还能打好多的敌人,所以判决的值是很大的很好的,再看右边的图,飞机的护盾消失,处于劣势,所以判决的值不好很小
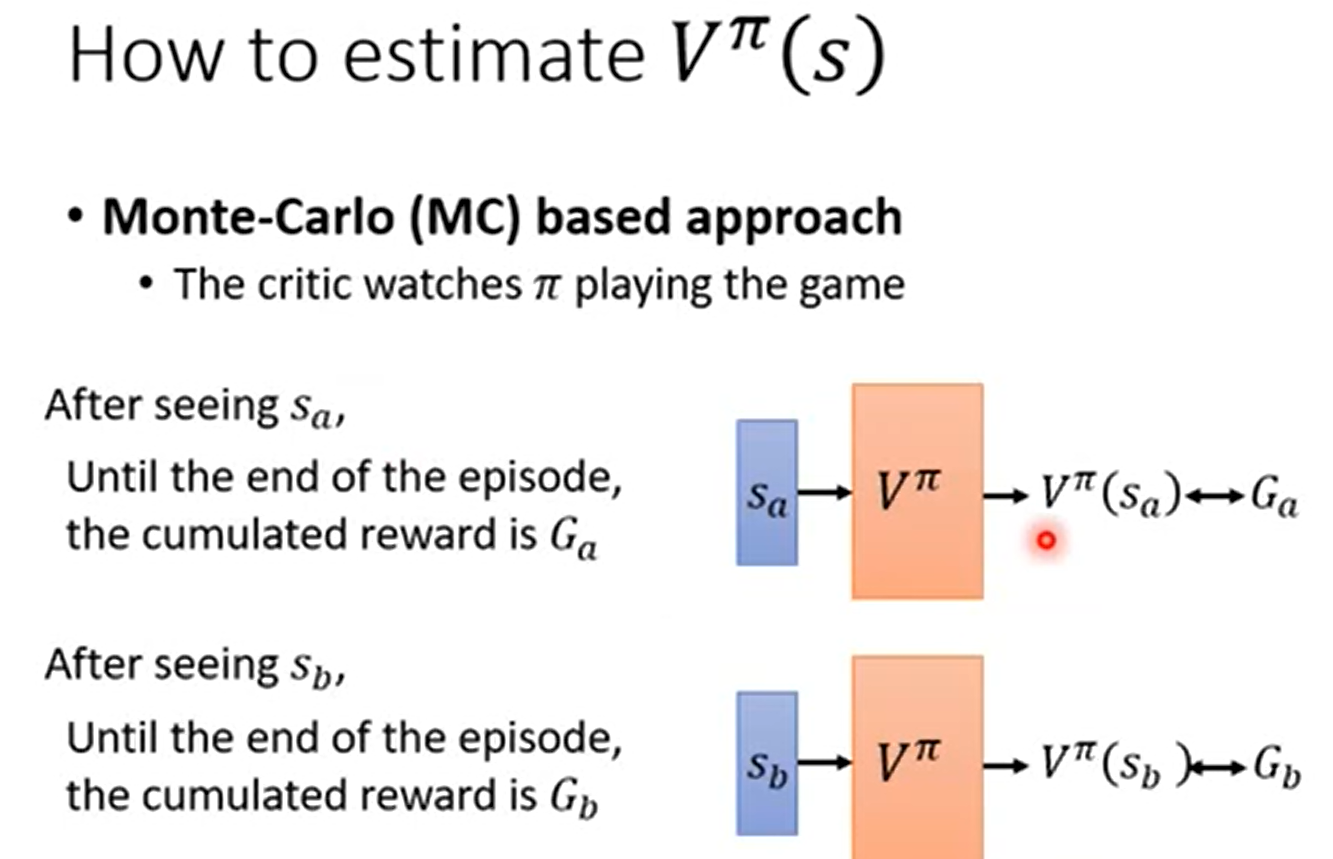
第一种估计Vπ(s)的方法MC,监督学习,回归,输入sa的时候输出应当为Ga,输入sb的时候输出应当是Gb
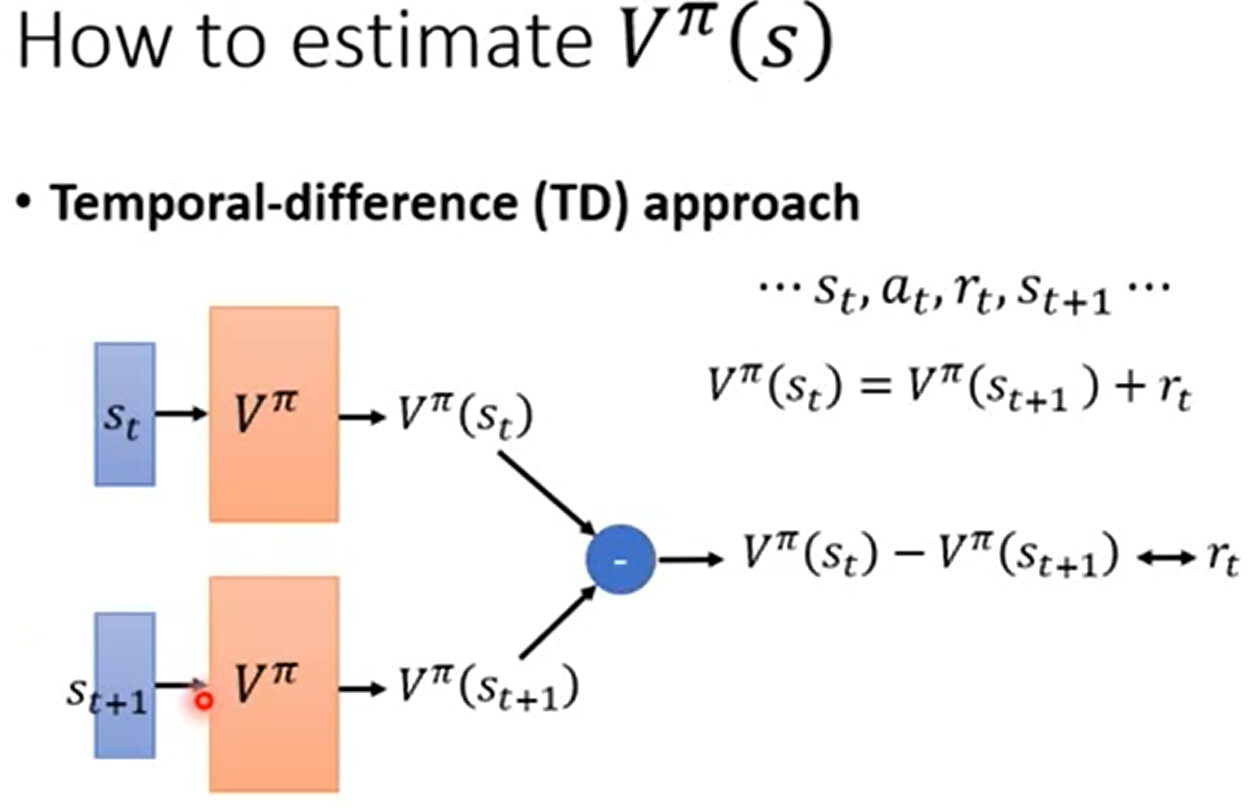
第二种估计Vπ(s)的MC方法,st是在t时刻下的环境状态,at是在t时刻采用的动作器,rt是在t时刻下得到的reward,TD就是要先分别将st带入Vπ(s)和st+1带入Vπ(s)的值分别求出来,然后再将他们相减,使他们相减的值趋近于rt
常用的是MC
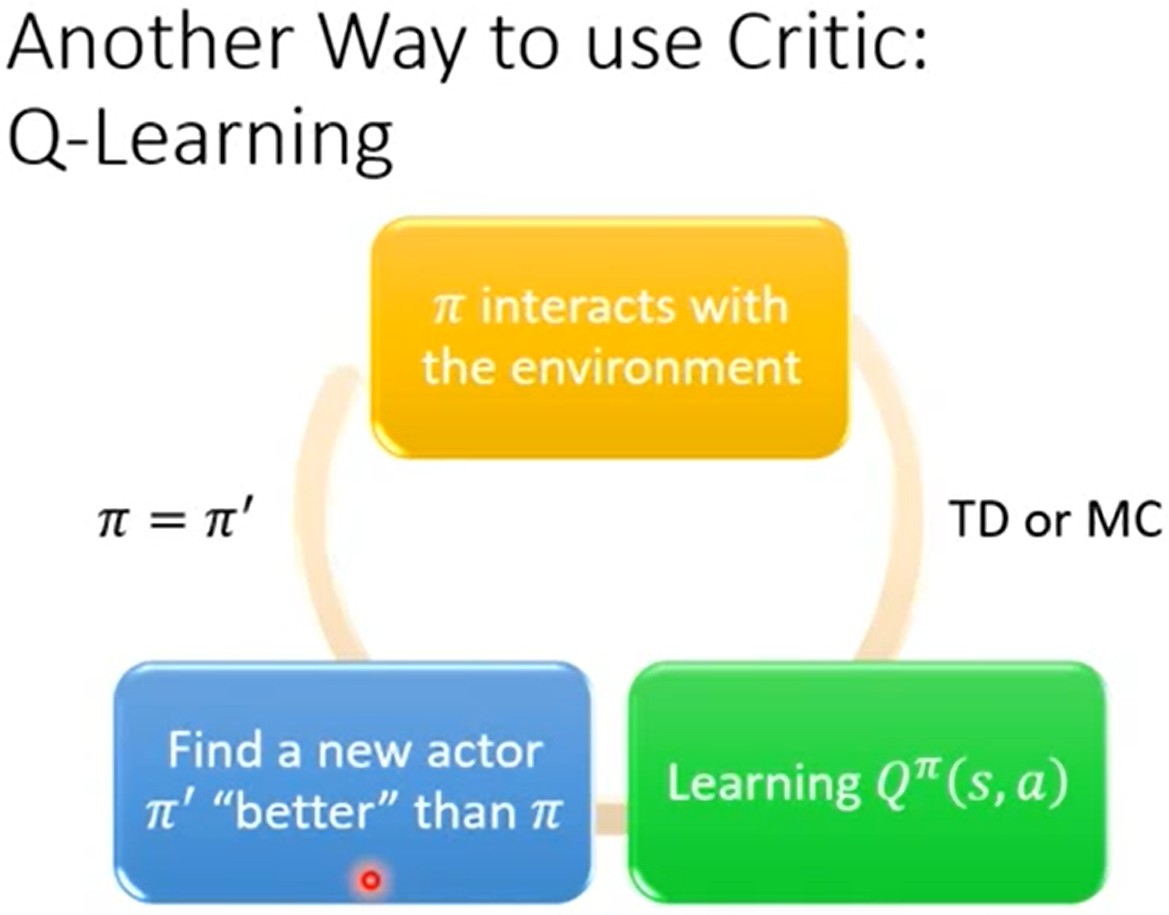
原先有一个动作器actor,使用它去在s情况下做出action动作a,然后得出Qπ(s,a),用Qπ(s,a)来衡量动作器的好坏,然后进行更新动作器,得到一个新的动作器π'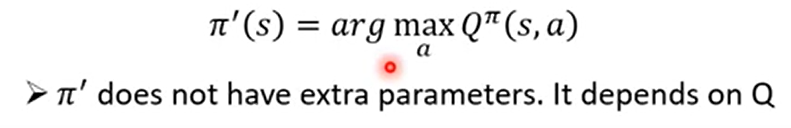
实际上π'就是由Qπ(s,a)导出的,就是要找Qπ(s,a)的最大值
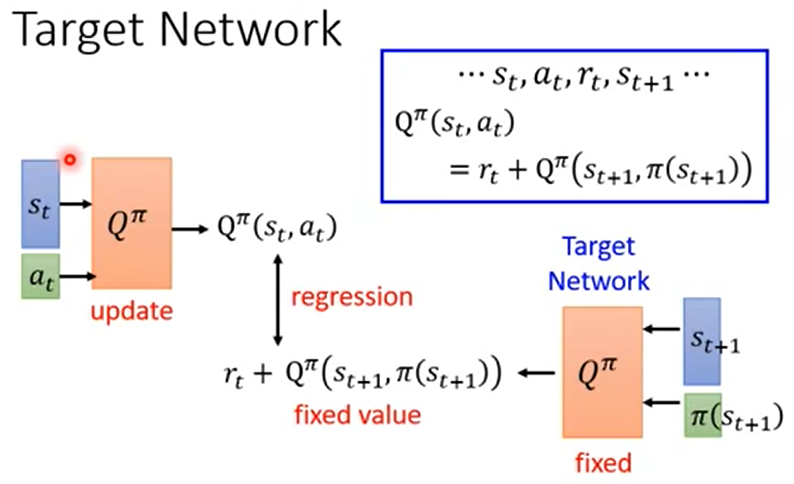
平常在train的过程中,右边的那个Qπ是参数是被固定住的,只调节左边的Qπ的参数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号