
pytorch——全连接层,模型好坏的衡量,过拟合欠拟合及解决方法,动量,卷积开头
全连接层
import torch #构建全连接层的写法 class zqh_layer(torch.nn.Module): #定义一个自己想的类,继承于torch.nn.Module def __init__(self): #以下两行固定写法 super(zqh_layer, self).__init__() #以下为设计三个层级的写法(从下往上,总共的是10,784) self.model=torch.nn.Sequential( torch.nn.Linear(784,200), torch.nn.ReLU(inplace=True), torch.nn.Linear(200, 200), torch.nn.ReLU(inplace=True), torch.nn.Linear(200, 10), torch.nn.ReLU(inplace=True), ) #重写forward,x是输入,输入进来直接走全连接层 def forward(self,x): x=self.model(x) return x net=zqh_layer() #net是继承于上面写的那个类名 optimizer=torch.optim.SGD(net.parameters(),lr=0.001) #由于类里面已经写了连接层 #所以可以直接写net.parameters()。权重和偏置不需要我们自己管的,包含在连接层内部
leaky relu
将relu的x<0且接近0的时候,并不完全等于0,使其有梯度
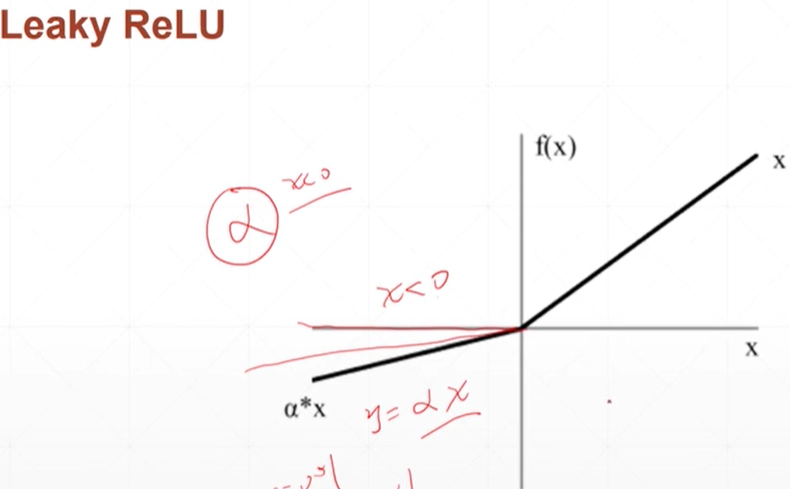
更加光滑的relu
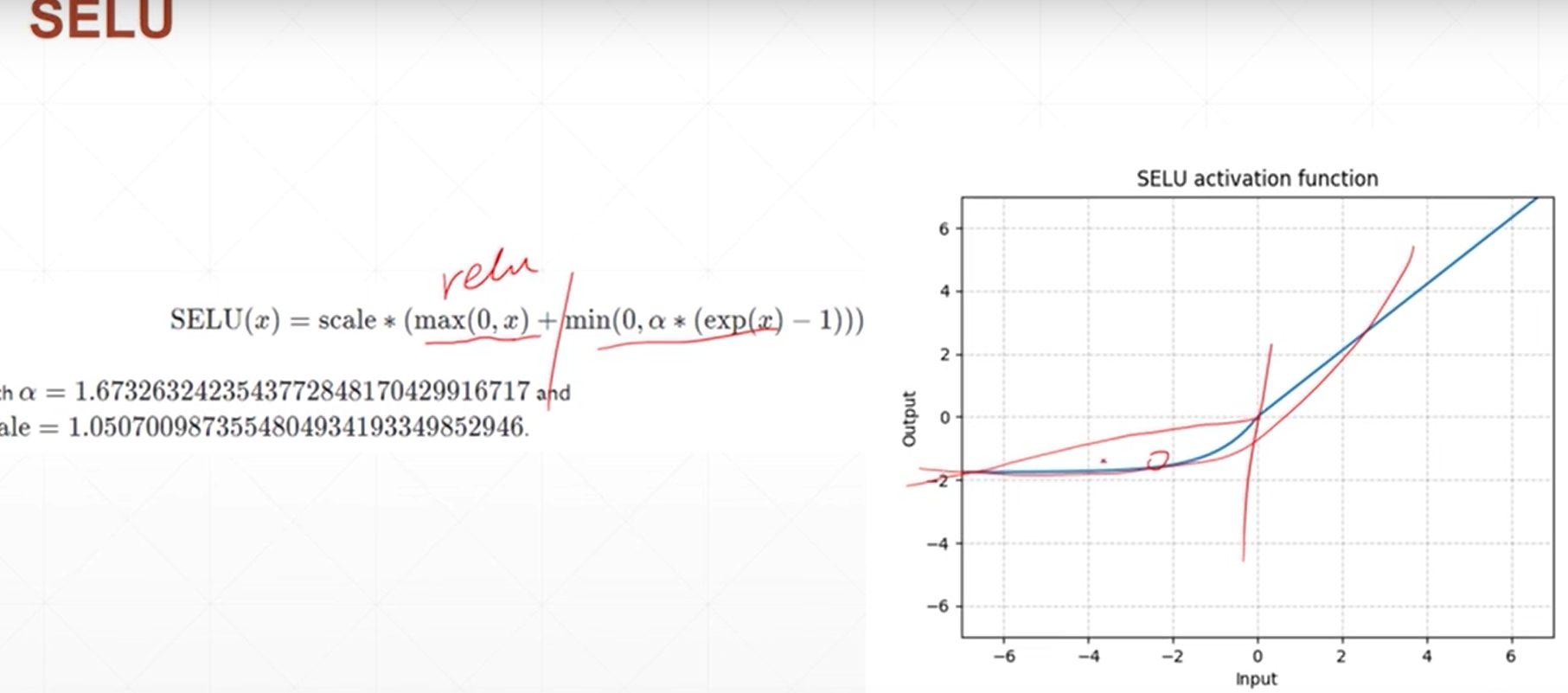
模型好坏的衡量,如何计算精度
#精度的计算方法 import torch import torch.nn.functional as F logits=torch.rand(4,10) print(logits) pred=F.softmax(logits,dim=1) print('将logits改成概率的形式',pred) pred_label=pred.argmax(dim=1) print('四行里面每一行的最大值是第几位',pred_label) #假设原来的label是torch.tensor([9,8,9,8]) orin_label=torch.tensor([9,8,9,8]) print('原来的(正确的)label',orin_label) correct=torch.eq(orin_label,pred_label) print(correct) print(correct.sum().float().item()/4) #预测对的除以总的预测的
过拟合和欠拟合
所使用的模型的复杂度<实际真实的模型的复杂度——欠拟合(ax+b<a(bx+c)+d)
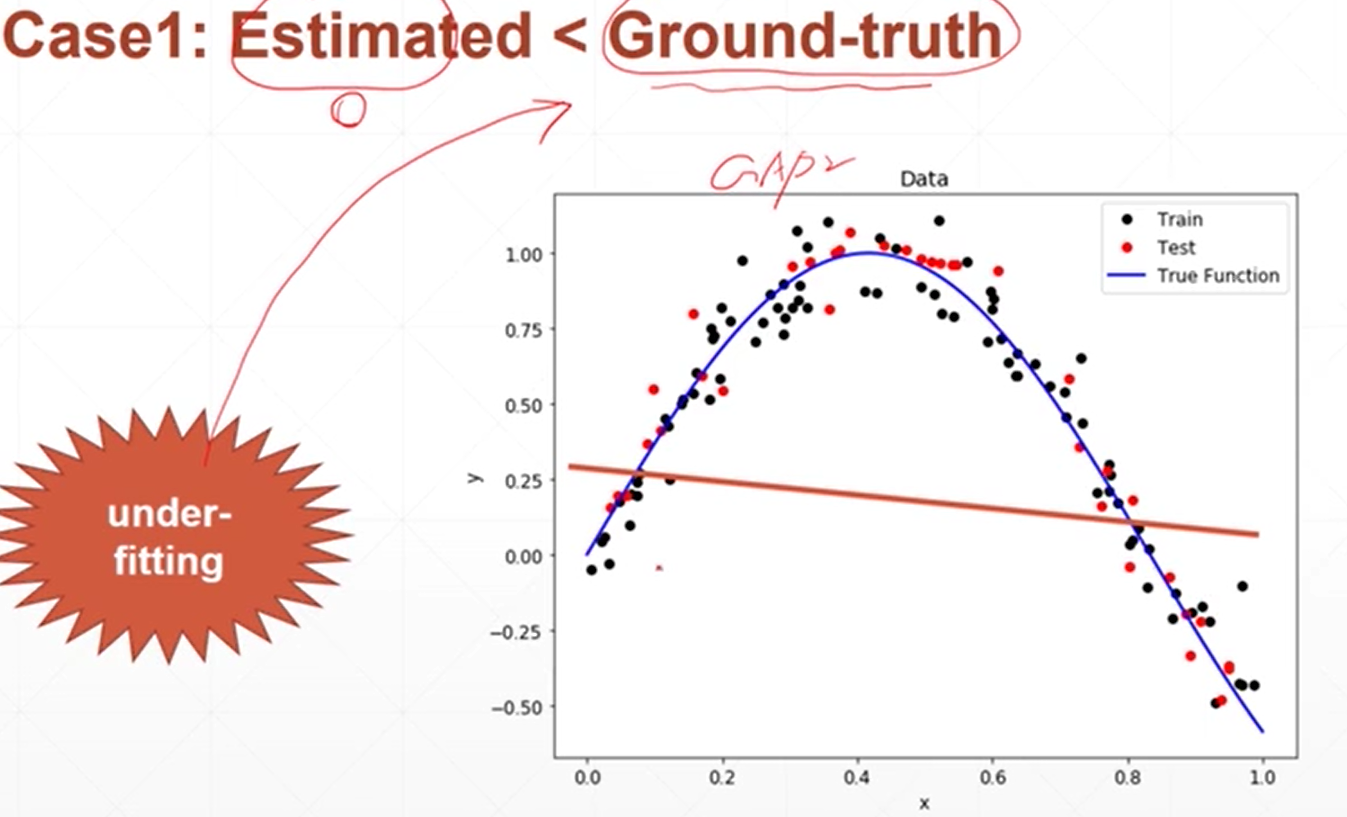
实际真实的模型的复杂度<所使用的模型的复杂度——过拟合
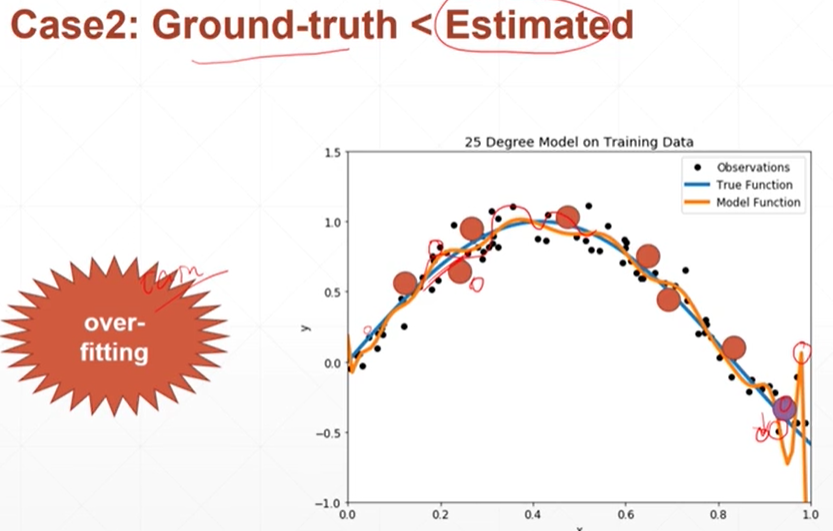
如何检测出到底是过拟合还是欠拟合:做测试的原因,检测是否有欠拟合或者过拟合找合适的神经网络模型的参数
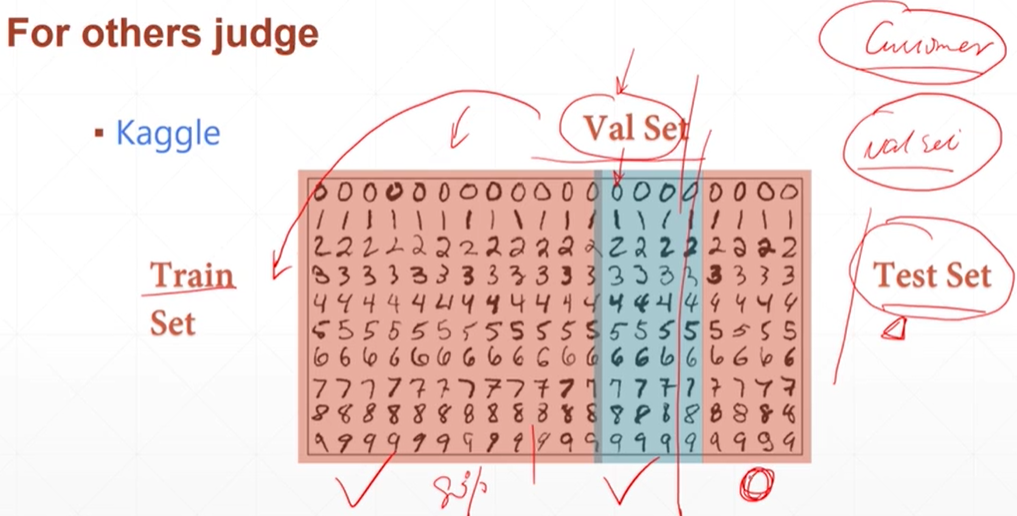
k值法,把训练集分成k份,每次取ki份当验证集,ki-1份当数据集
如何解决过拟合

更多的数据,减少模型的复杂度
使用回归方法在运行过程中智能减少模型的复杂度

在末尾加上 入和θ的范数的累加。这样再求loss梯度更新参数的时候,θ的范数在更新的过程中也会逐渐的减小

加上weight_decay就加上了后面的1/2lambda二范数,0.01设置的是lambda的值
#加l2-regularization的方法 optimizer=torch.optim.SGD(net.parameters(),lr=0.001,weight_decay=0.01)
#加l1_regularization方法 regularization_loss=0 for param in model.parameters(): #循环网络里面的所有的参数 regularization_loss+=torch.sum(torch.abs(param)) #计算一范数的和 class_loss=criteon(logits,target) #计算loss loss=class_loss +0.01*regularization_loss #loss+lambda*一范数的和
要寻找全局最小解,可以增加动量momentum
原来的更新方式
![]()
加上动量后的更新方式
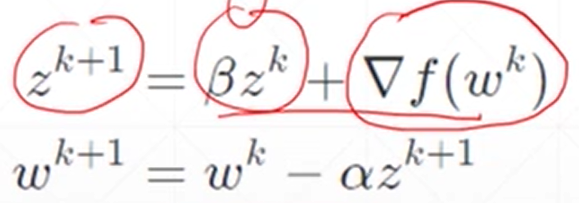
更新时不仅仅只考虑梯度方向,还考虑了历史方向
#要使用动量moment,直接在sgd中加入momentum,值是公式中的β optimizer=torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.078)
早期停止
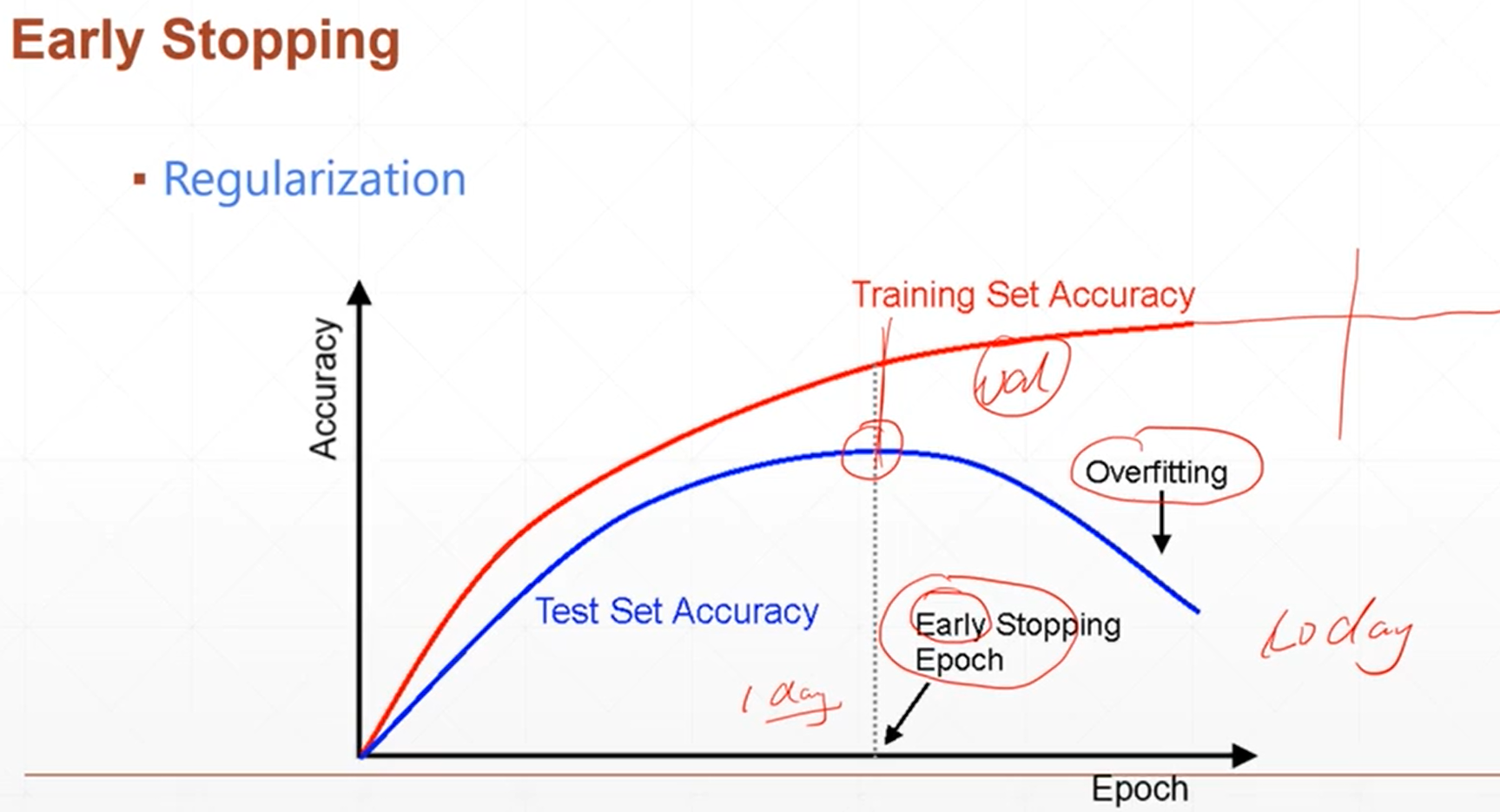
在训练集的准确度上升的时候,验证集的精准度也会先上升再下降,就要找到那中间的一个最高点,选择的参数设置就是中间那个最高点的
可是由于后面的不需要,我们为了节省时间可以在最高点处设置出停止
dropout(用于减少过拟合)
就是所有的w权值的路线,都设置一个probility,每一次这条路线都是概率连通
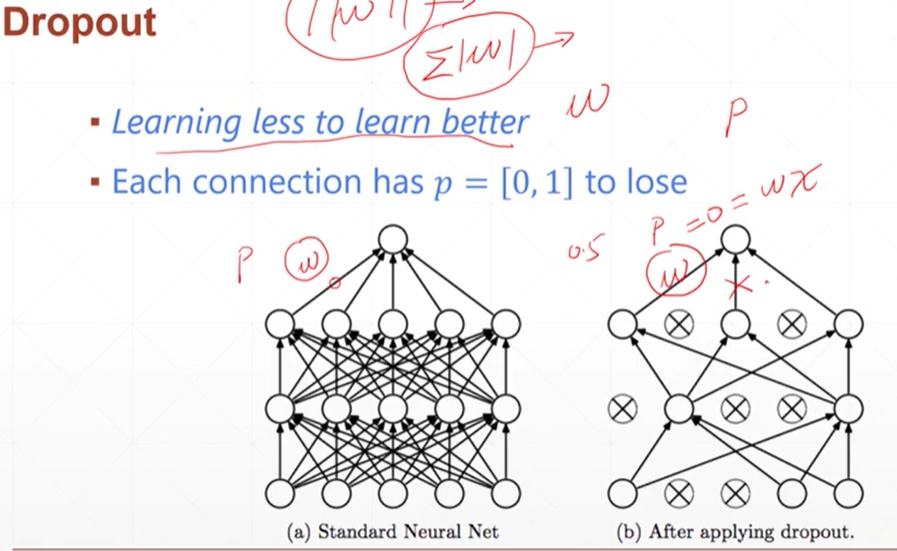
只需要在层之间加入torch.nn.Dropout(概率),即可
self.model=torch.nn.Sequential( torch.nn.Linear(784,200), torch.nn.Dropout(0.5), torch.nn.ReLU(inplace=True), torch.nn.Linear(200, 200), torch.nn.ReLU(inplace=True), torch.nn.Linear(200, 10), torch.nn.ReLU(inplace=True), )
验证集验证的时候,需要关掉这个概率的,可以加入net_dropped.eval()
图片


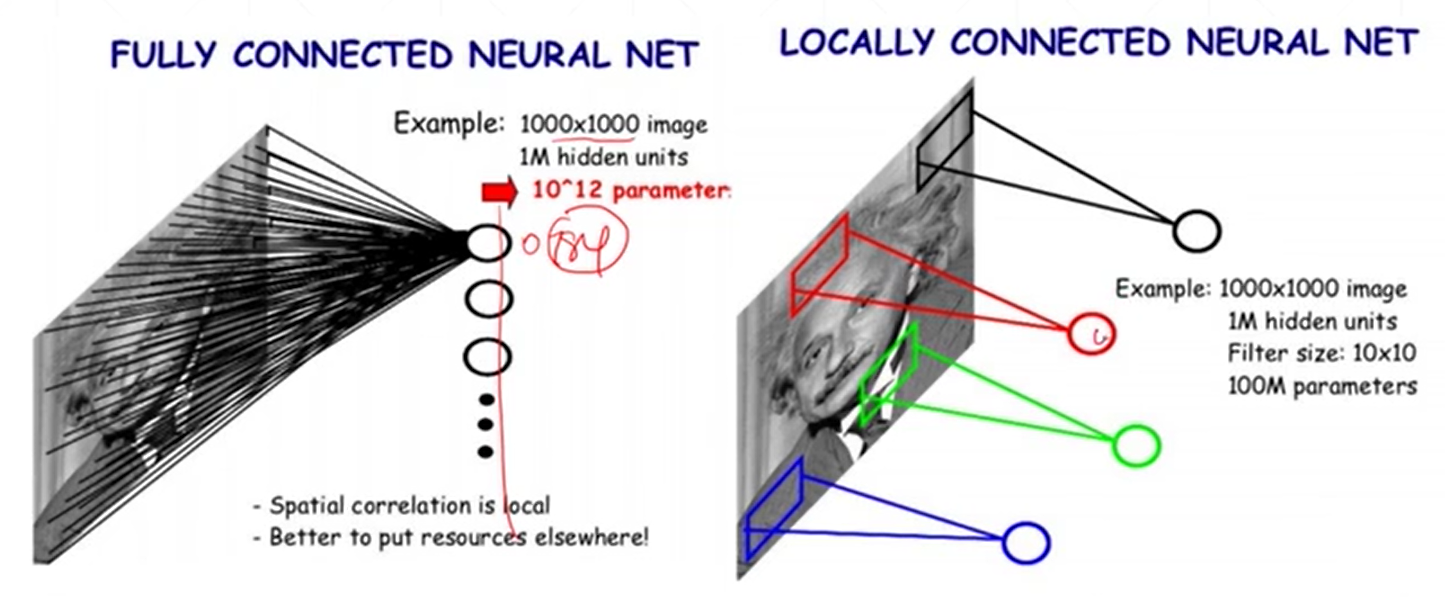
局部视野,局部相关性
由于神经网络中的点一多,线就会特别多,引起硬件需求变高。此时提出了局部相关性(卷积),只使用上一部分的某几个通过权值到达下一层的一个节点,减少线
卷积
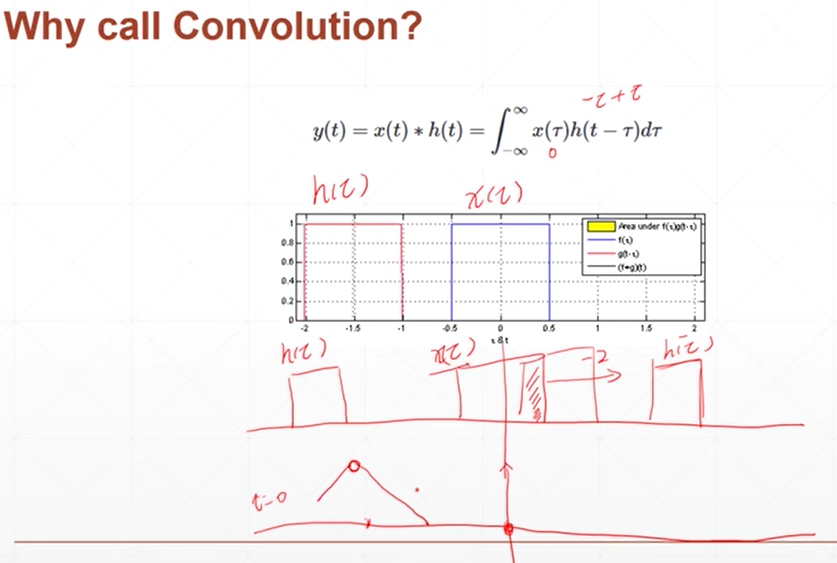
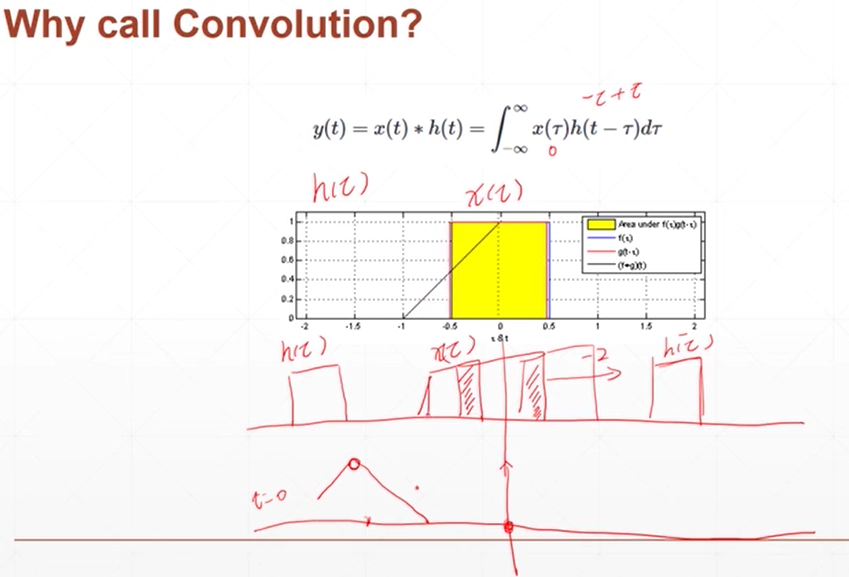
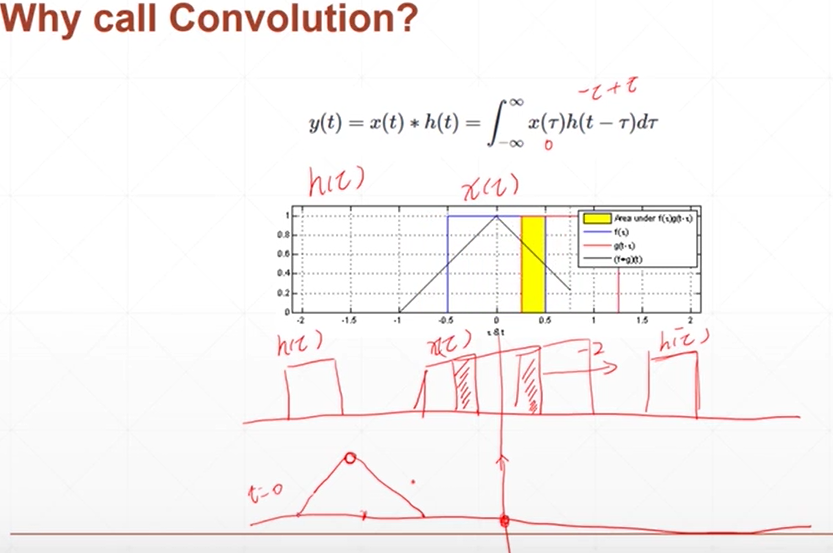
红色的是h(t),蓝色的是x(t),卷积代表的是在h(t)移动的过程中与x(t)的重合量,重合的多重叠时达到最大。
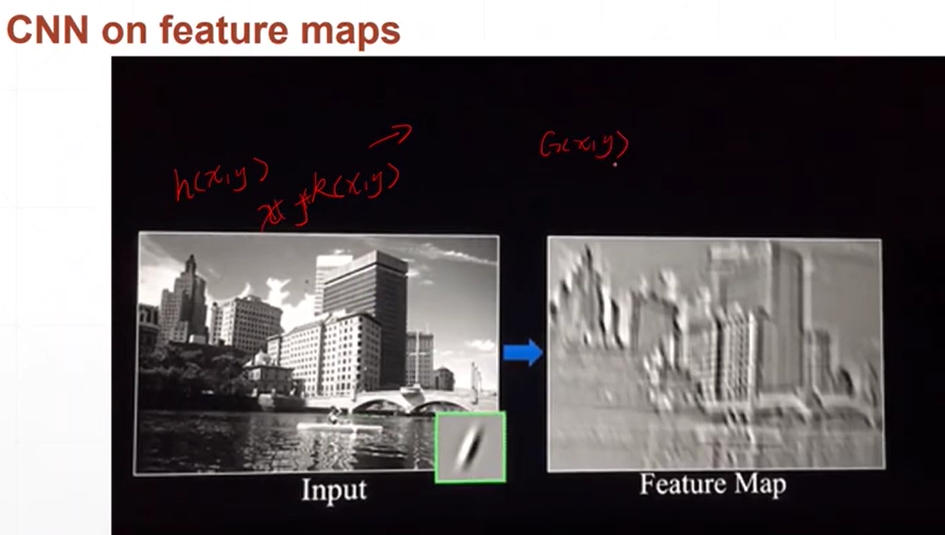

 浙公网安备 33010602011771号
浙公网安备 33010602011771号