
机器学习1
一,数据
1.数据集:100个西瓜
2.样本:1个西瓜
3.特征向量:甜度,大小,颜色
4.属性:颜色(特征向量中间的一个)
二,学习算法
三,得到模型:
有监督学习,无监督学习
有监督学习的分类:二分类(两个最终解,摘还是不摘),多分类(多个最终解,买哪一种西瓜),回归(预测第二年的价格)
无监督学习:聚类(我们不知道分几类,机器自己分)
进行预测
1.测试
2.测试样本
3.泛化能力,泛化指的是处理没见过的数据的能力
四,归纳模型:
同一个数据集训练出不同的模型,如何选择模型
原则:奥卡姆剃刀(选择最简单的那一个)
第二章 模型评估与选择
一种训练集一种算法
1.经验误差与过拟合:m为样本的数量,假设有1000张图片。每张图片有自己的正确的结果,比如第一张图代表1,第二张图
代表7。使用模型进行预测,统计出错误的个数a。则我们可以通过错误率来衡量模型好坏,错误率E=a/m。精度=1-E
2.模型的评估方法:
训练集:
测试集:
测试集的保留方法:留出法——三七分(前七年训练集,后三年测试集)
k折交叉验证——训练集是整个数据d,将数据d拆分成di块,每次抽出来一块,然后用那一块当成测试集进行测试,最后
将i个测试结果进行平均
验证集:
为了调参,常常会加上一个数据集,验证集。训练集训练,验证集看结果,调参,再看验证集结果。参数调完,最后再上测试集看结果
性能度量公式:

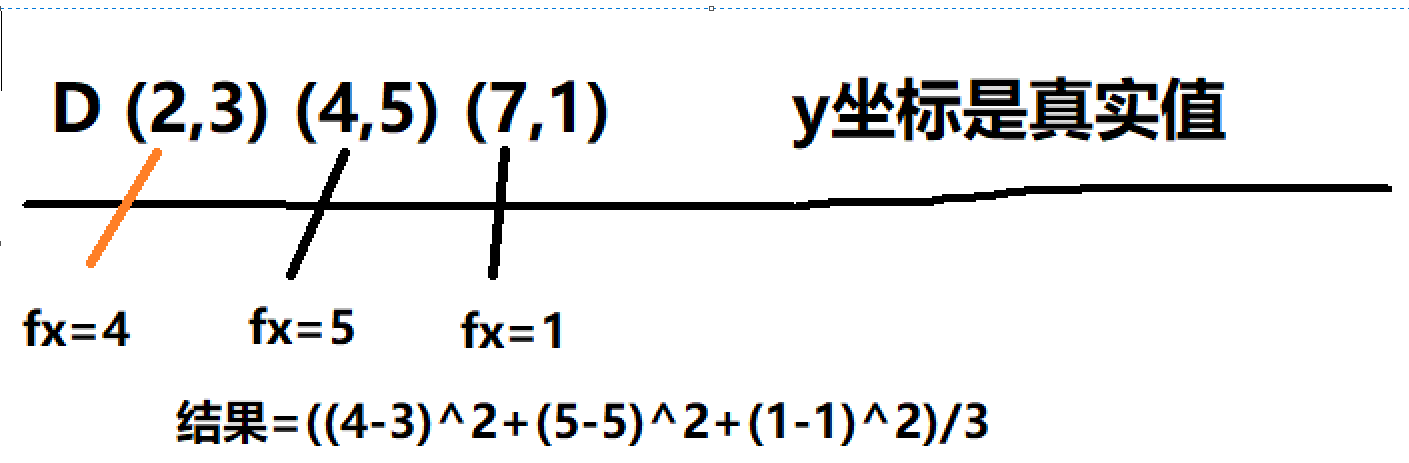
错误率:
算出来的fx和原来坐标的y值进行比较,相同为1,不同为0。将所有数据进行判断然后再除以总个数
查准率:
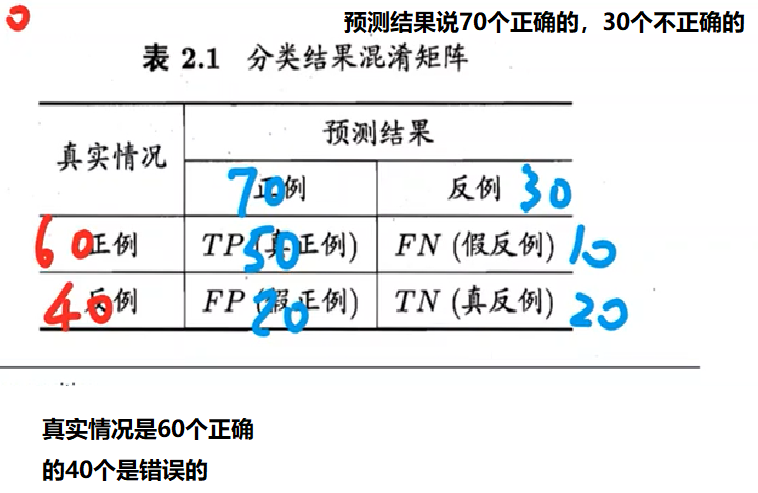
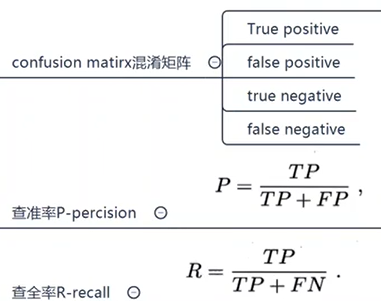
PR反向变动
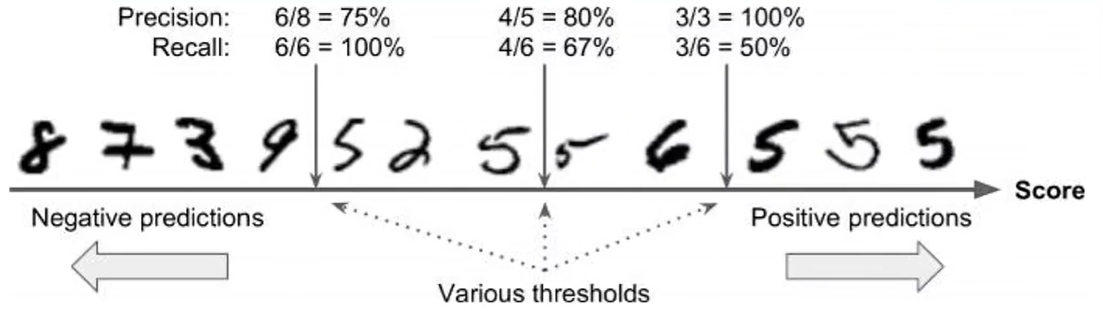
threashold意思是分界线,分界线右边的判为是,分界线左边的判别成不是
precision是查准率,就拿最中间的那个分界线来说,查准率是右边有56555五个数字,分界线右边查到了4个,因此查准率为4/5
recall是查全率,就拿最中间的那个分界线来说,查全率是不看分界线总共有6个五,然后分界线右边查到了4个,因此为4/6
查全率与查准率呈现反向关系
最优阈值(分界线的确定):pr的最优秀分界点:
1.P=R查准率等于查全率的点
2.用调和平均数求f1
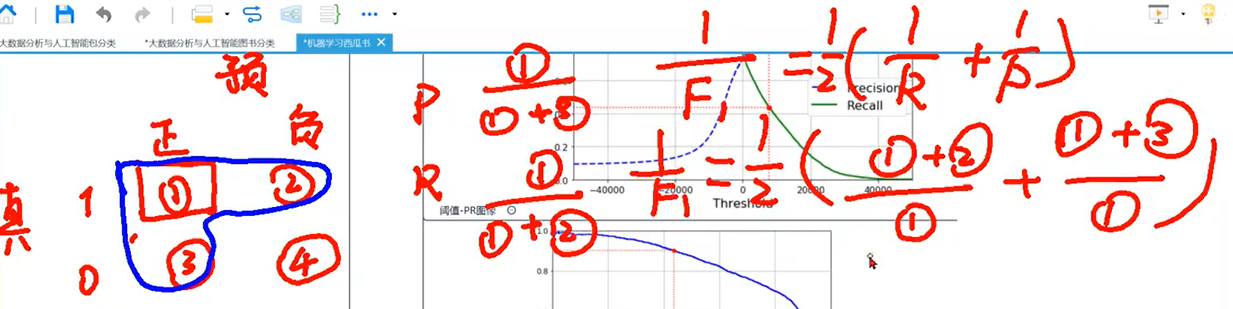

3.fbata


以上是二分类的问题,只有一个二分类的问题。如果是多分类问题,就会有多个PR图
解决方法1:
将把所有的p平均成杠p,将把所有的R平均成杠R,再进行后面的计算
解决方法2:
将把所有的TP,FP,TN,FN平均出来,再进行后面的计算
利用PR图对模型好坏进行评估
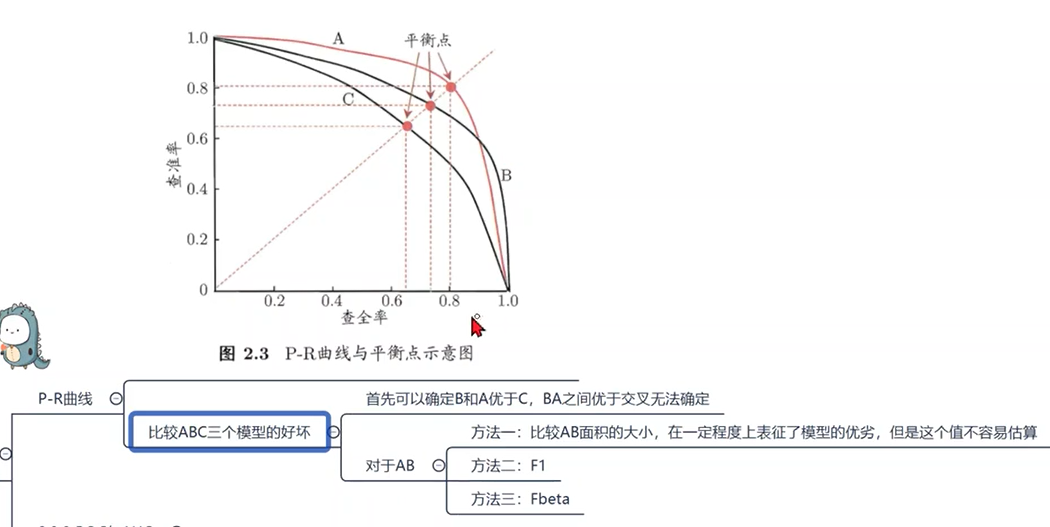
A和B肯定是优于C,因为相同的查全率的情况下C的查准率必定最低。但是A和B的比较就需要判断
可以用f1或者fbeta求出分界点,然后再进行相应的比较查全率下的查准率
一种训练集多种算法
ROC
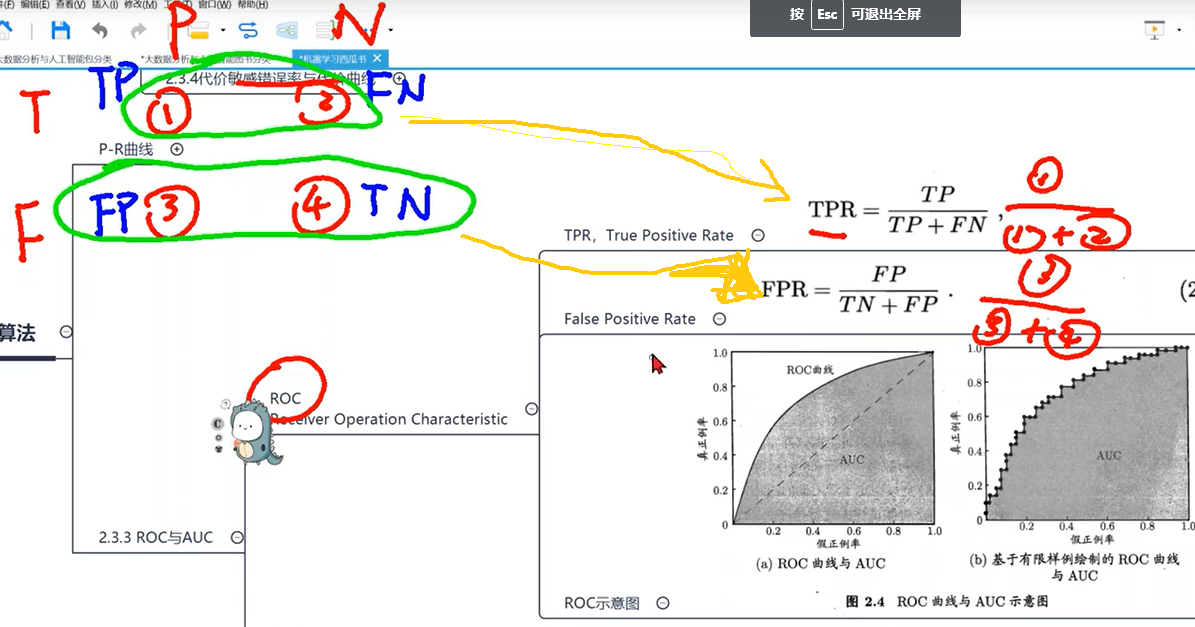

D+指的是猜对的个数 D-指的是猜错的个数 m+代表正确的5的个数 m-代表不是5的个数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号