
mysql1
基础知识
数据:描述事物特征的符号
记录:事物的一系列的典型特征
表:类似excel那样的,是记录的集合的文件
库:文件
数据库管理软件:mysql,db2,oracle等
数据库服务器:运行数据库管理软件的计算机
关系型数据库:需要表结构(会有数据类型等约束)
非关系型约束:单纯的key-value储存
MYSQL环境变量的设置:
找到mysql安装文件夹下面的bin文件夹进行设置
检测是否安装成功:
设置好环境变量之后cmd输入mysqld启动服务端(相当于找到bin目录然后执行mysqld.exe)
设置好环境变量之后cmd输入mysql启动服务端(相当于找到bin目录然后执行mysql.exe)
设置密码
查询当前登录的用户的名字
select user();
修改管理员的密码
mysqladmin -u root -p password 想改的新密码
注意,命令回车后会问你旧密码,输入旧密码之后命令完成,密码修改成功。
-uroot指的是要修改的是管理员的密码
退出当前用户登录
exit
登录
mysql -u用户名 -p密码
忘记了root管理员 的密码怎么办
跳过检验步骤来启动,启动服务器时输入mysql --skip-grant-tables跳过检验步骤
此时可以直接用 mysql -uroot -p 不用密码就能登陆进去管理员账号了
登陆进去管理员账号之后可以输入 update mysql.user set password=password("想改成的密码") where user="root" and host="localhost";
最后再输入flush privileges;
这样就完成了对root管理员的默认修改
查看字符编码
\s
如果上面的语句写错了
可以输入\c或者'\c来中断与上面写的关联,这样再重新写
写配置文件来统一字符编码,需要自己在安装文件夹下面创建my.ini
内容:
client里是给所有的客户端都进行配置(全局配置),[mysqld]按服务器端进行配置
[mysqld]
character-set-server=utf8
collation-server=utf8_general-ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
操作文件夹(库)
创建名为db1的文件夹
create database db1 charset utf8;
查看指定文件夹
show create database db1;
查看所有的数据库
show databases;
改数据库的字符编码方式
alter database db1 charset gbk;
删除数据库
drop database db1;
操作文件(表)
切换文件夹(进入某个文件夹)
use db1;
查看当前的文件所处于的文件夹
select database();
新增表
create table biao1(id int,name char);
查看表
show create table biao1;
desc biao1; #查看表结构
查看所有表
show tables;
修改表,把名字改成六个字符的
alter table biao1 modify name char(6);
alter table biao1 change name NAM char(7); #把name改成char(7)的NAM
删除表
drop table biao1;
操作文件内容(记录)
向biao1增加记录
biao1(id,name)这里的括号里可以修改放数据的顺序,如果不写,默认按定义的顺序放数据
insert biao1(id,name) values(1,'asd'),(2,'qwe'),(3,'zxc');
查看表的指定键值的值
select id,name from db1.biao1;
查看表的所有键值和属性
select * from db1.biao1;
改表里面的全部记录
update db1.biao1 set name='S';
改表里面的指定记录
update db1.biao1 set name='d' where id=2;
删除biao1里面的全部记录
delete from biao1;
删除biao1里面的指定记录
delete from biao1 where id=2;
把整张表删掉,而且将自增长步长等恢复成默认状态
truncate biao;
库的介绍:
系统自带库
information_schema:是虚拟库,不占用磁盘空间,放用户权限等信息
performance_schema:主要用于手机数据库服务器性能参数
mysql:授权库
test:系统自动创建的测试数据库
帮助系统
help 想要查的用法的关键字
存储引擎
存储引擎就是表的类型
1.查看mysql支持的存储引擎,主要学innodb
show engines;
2.指定表类型/存储引擎
create table t1(id int)engine=innodb; 创建完之后有表结构,表数据两个小文件
create table t2(id int)engine=memory; 创建完之后只有表结构 ,这种数据存在内存里,如果重启的话数据就没了
创建表
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
注意在同一张表中,字段名是不能重复的,宽度和约束条件可选,字段名和类型是必须的
查看表
show create table 文件名.表名\G; #查看指定表的内容,可以加上\G来按行显示,这样好看
修改表
1.修改表名
alter table 表名
rename 新表名;
2.增加字段
alter table 表名
add 字段名 数据类型[完整的约束条件]
3.增加字段到第一个
alter table 表名
add 字段名 数据类型[完整的约束条件] first;
4.增加字段到指定字段的后面
alter table 表名
add 字段名 数据类型[完整的约束条件] after 字段名;
5.删除字段
alter table 表名
drop 字段名;
4.修改字段
alter table 表名
modify 字段名 数据类型[完整的约束条件];
alter table 表名
change 旧的字段名 新的字段名 旧的数据类型[完整的约束条件];
alter table 表名
change 旧的字段名 新的字段名 新的数据类型[完整的约束条件];
复制表
将整个表给复制掉
create table 表名 select host,user from mysql.user; #select host,user from mysql.user是要进行复制的select出来的内容
只复制表的结构
create table 表名 like mysql.user;
数值类型
1.整数类型
超过范围将会显示范围边界数
加上unsigned会是无限制变成全正数(无符号)
tinyint (-128,127) 无符号(0,255)
smallint (-32768,32767) 无符号(0,65535)
mediumint (-8388608,8388607) 无符号(0,16777215)
int 的长度够用了,不够用bigint
2.浮点型
整数部分占用的位数=数字总共占几位-小数类型的占几位
float[(数字总共占几位,小数类型的占几位)][unsigned][zerofill] m最大255,d最大30(精确度到7位左右,后面不准)
double[(数字总共占几位,小数类型的占几位)][unsigned][zerofill] m最大255,d最大30(精确度到14位左右,后面不准)
decimal[(数字总共占几位,小数类型的占几位)][unsigned][zerofill] m最大65,d最大30(精确度完全准确)
日期类型
create table student( id int, name char(6), born_year year, birth_date date, class_time time, reg_time datetime ); insert into student values (1,'abcd',now(),now(),now(),now());
select * from student;

字符类型
设置mysql不要自己取数的时候自动删除空格 SET sql_mode='PAD_CHAR_TO_FULL_LENGTH';
char: 定长
varchar: 变长
create table tchar1(name char(5)); create table tchar2(name varchar(5)); insert into tchar1 values('zqh'); insert into tchar2 values('zqh'); select char_length(name) from tchar1; #查看里面存的数据的长度 select char_length(name) from tchar2; #查看里面存的数据的长度

char是存储的很快 varchar存的慢,因为varchar要先读头部份
枚举类型和集合类型
传某些位置参数的时候,限制只能传某些固定的参数
如果传的不在枚举类型和集合类型里面,就会显示空,传不进去
create table consumer( id int, name char(16), sex enum('male','female','other'), level enum('vip1','vip2','vip3'), hobbies set('play','music') ); insert into consumer values (1,'abcd','male','vip2','music');
约束条件
1.完整性
null代表空值
create table txp( id int, name char(6), sex enum('male','female') not null default 'male' ); insert into txp(id,name) values(1,'dsad'); select * from txp;
2.重复性
添加unique来限制重复的问题
create table department( id int, name char(10) unique );
或者这样写
create table department( id int, name char(10), unique(id), unique(name) );
上面是单个唯一,现在来弄联合唯一,两个部分都一样才不行
create table ipport( id int, ip char(15), port int, unique(ip,port) );
主键primary key
主键:not null unique 不为空且为1
一张表之中必须有一个主键
不设定主键,mysql会自己找一个当主键
1.单列主键
create table t01( id int primary key, name char(16) );
2.复合主键
create table t01( id char(15), port int, primary key(ip,port) );
自增长auto_increment
none了自增长之后就可以不用管primarykey了,让他自增长,传后面的数据就行了
create table t11( id int primary key auto_increment, name char(16) ); insert into t11(name) values ('sb1'), ('sb2'); #也可以强行自己传 insert into t11(id,name) values(7,'sdad');
auto_increment_increment步长默认为1
设置当前连接步长为5 set session auto_increment_increment=5;
设置全局每次步长为5 set global auto_increment_increment=5;
auto_increment_offset起始偏移量默认为1
设置当前连接起始偏移量为5 set session auto_increment_offset=5;
设置全局每次起始偏移量为5 set global auto_increment_offset=5;
注意起始偏移量必须<=步长
两个表之间建立联系foreign key
#先建立被关联的表,再建立发起建立的表。并且需要保证被关联的字段唯一
create table dep( id int primary key, name char(10), comment char(16) ); create table emp( id int primary key, name char(10), sex enum('male','female'), dep_id int, foreign key(dep_id) references dep(id) #dep_id 关联另一个表的id
on delete cascade #删除同步,如果关联的表删了某个,另一个被关联的也会同步删除这个
on update cascade ); #先往被关联表插入记录 insert into dep values (1,'it','dsssweq'), (2,'xiaoshou','1231543'); insert into emp values (1,'asd','male',1), (2,'qwe','female',2), (3,'zxc','female',1);
如果删除 dep里面的id是1的
delete from dep where id=1;
表之间的关系
1.多对一
左边很多本书可以被右边的同一个出版社出版
2.多对多
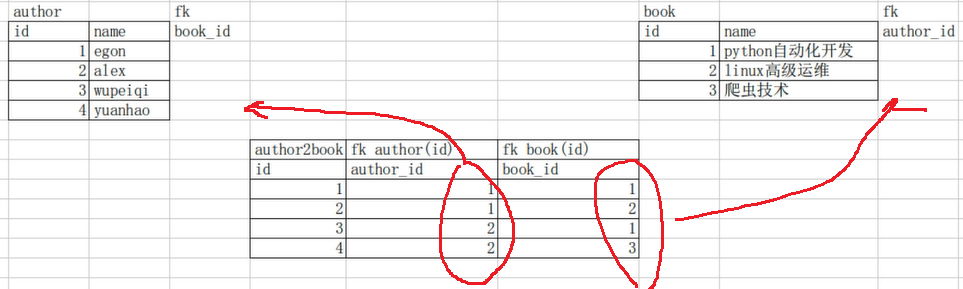
3.一对多
单表查询和多表查询
select 字段1,字段2 from 库.表
where条件
group by 分组条件
having过滤
order by排序字段
limit限制段
1.可以在取数时对数据进行简单的四则运算
select name,salary*12 as annual_salary from biao1;
2.用于拼接字符串concat
concat('姓名:',name,'性别:',sex) as info是一块,concat('薪资:',salary*12) as annual_salary是一块
select concat('姓名:',name,'性别:',sex) as info,concat('薪资:',salary*12) as annual_salary from biao1;
3.去重distinct
select distinct name from user;
where语句
1.比较运算:
< > = !=
2.用between
select * from employee where salary between 20000 and 30000;
3.可以用and和or连接
select * from employee where post='techer' and salary>8000;
4.用in
select * from employee where age in (73,81,22);
5.判断是否空
select * from employee where post is Null; select * from employee where post is not Null;
6.like匹配,后面有没有都行
select * from employee where post like 'jin%';
7.like匹配,后面只能有下划线个任意字符
select * from employee where post like 'jin_';
group by分组
按照相同的字段进行分组
设置分组时按照严格分组模式,就不会出现分组后每个组只显示一个一条数据
set global sql_mode="ONLY_FULL_GROUP_BY"; #只能取分组的字段或者聚合 select post from employee group by post;
聚合函数max,min,avg,sum,count(计算出现的次数)
下面用聚合函数
select post,count(id) from employee group by post;
如果没有分组的话整体是一组
group_concat在分组之后可以将某个组里面的数据给显示出来
select post,group_concat(name) from employee group by post;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号