你所不知道该如何回答的面试题(一)
JS分为哪两大类型?都有什么各自的特点?你该如何判断正确的类型?
发散思维,举一反三的回答问题,将很多碎片化的知识点进行串联。
JS分为基本数据类型和引用数据类型。
基本数据类型:String、Number、Boolean、Null、Undefined、Bigint、Symbol
引用数据类型:Object
其中 Number 类型 是浮点类型,在使用中会遇到某些bug,比如 0.1 + 0.2 != 0.3。这是由于计算机采用二进制语言,0.1 和 0.2 在由十进制转为二进制时是无限循环的小数,计算机的内存是有限的,会在某个精度点直接舍弃,导致计算机还没开始计算,一个很小的舍入错误就产生了。
对于 Null 类型,虽然 typeof null 会输入 object,但是这只是JS存在的一个悠久的bug,最初版本的 JS 使用的是32位系统,为了性能考虑使用低位存储变量的类型信息,000 开头的是对象类型,然而 null 表示为全零,所以将它错误的判断为 object 。
各自的特点:原始类型存储的是值,存在于栈中;对象类型存储的是指针,存在于堆中(因为保存在栈内存的必须是大小固定的数据)。并且针对原始类型和对象类型,复制拷贝也是不一样的。原始类型的复制是深拷贝,而对象类型的复制,根据复制层级分浅拷贝和深拷贝,这是因为对于对象类型,栈中只存放地址(指针),复制的时候,其实是复制地址,而非具体的内容。
浅拷贝的方式:
- ES6 的 Object.assign()
- ES7 的...解构运算符
- 只拷贝一层
深拷贝的方式:
-
JSON.parse(JSON.stringify(src))
-
采用递归调用
-
借助第三方库
lodash 的cloneDeep(src)jq 的extend(true, result, src1, src2[ ,src3])
深浅拷贝的实现原理 见 原型模式 笔记
对象一般存放在堆空间中,因为堆空间很大,能存很多大的数据,但缺点是分配内存和回收内存会占用一定的时间。所以针对栈和堆的回收是不一样的。
调用栈中的数据回收机制是:当一个函数执行结束之后,JavaScript引擎会通过向下移动ESP来销毁该函数保存在栈中的执行上下文。
堆中的数据回收机制是建立在代际假说的基础之上。
代际假说有两个特点:
- 不死的对象会活的更久
- 大部分对象在内存中存在的时间很短,简单来说就是很多对象一经分配内存,很快就变得不可访问。
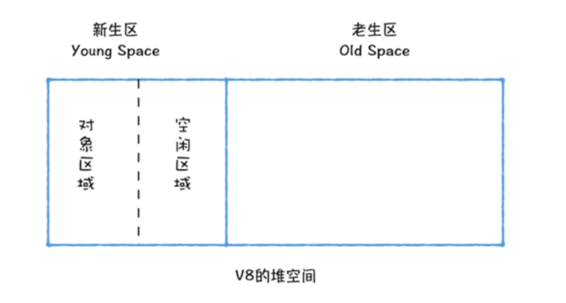
因此V8中会把堆分为新生代和老生代两个区域,新生代中存放生存时间短的对象(1 ~ 8M),老生代中存放生存时间久的对象,采用两种算法进行回收。
新生代中使用Scavenge算法。该算法是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。然后进行循环复制(复制的过程中相当于完成了内存整理)和翻转。并且采取了对象晋升策略,凡是经过两次垃圾回收依然还存活的对象就会被移动到老生区中。
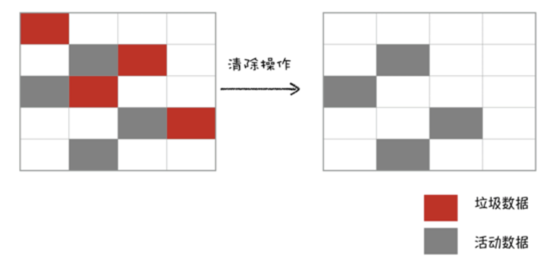
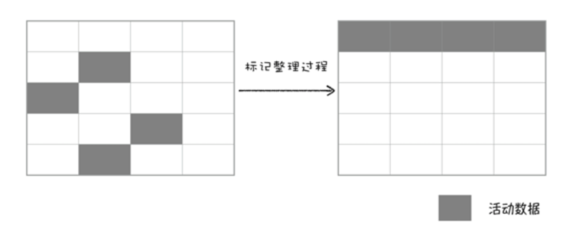
主垃圾回收器回收老生区中的代码,由于老生区中对象占用空间大并且对象存活时间长。所以采用标记-清除的算法进行回收。
针对类型的判断,可以通过 typeof 和 instanceof 来进行判断。
其中 typeof 的缺点是针对Object、Array和Null类型不能区分,他们都返回 Object
而 instanceof 虽然能够区分Array、Object和Function,适合用于判断自定义的类实例对象,但没法判断 Number,Boolean,String 等基本类型。
因此需要视具体情况来使用。
不过Object.prototype.toString.call()可以精准判断数据的各种类型。但写法比较繁琐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号