
大数据应用期末总评
本作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
1.将爬虫大作业产生的csv文件上传到HDFS
将爬虫大作业中爬取到的数据文件csv导入到/usr/local/bigdatacase/dataset目录下

2.对CSV文件进行预处理生成无标题文本文件
利用bash ./douban.deal.sh douban.csv douban.db.table.txt对文本进行预处理,字符分割、输出
douban.deal.sh脚步如下:

因为本人爬取的数据文件中,评论数据是长评论,所以我就把该列去除了。
查看/usr/local:
利用start-all.sh命令,启动HDFS
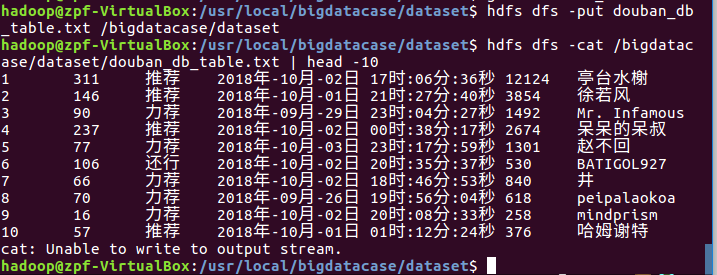
在HDFD上建立/bigdatacase/dataset文件夹

把douban_db_table.txt上传到HDFS中
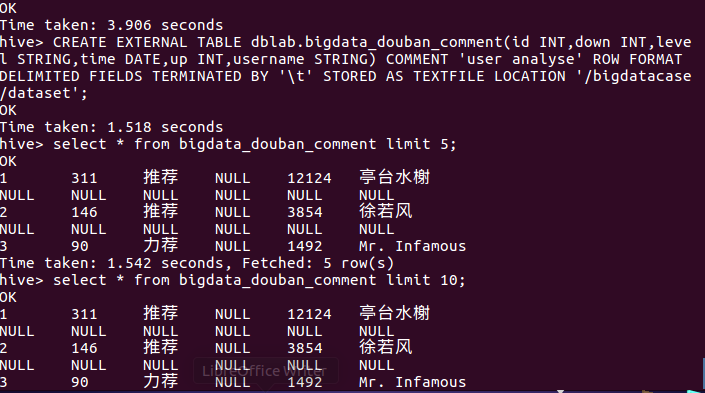
3.把hdfs中的文本文件最终导入到数据仓库Hive中
4.在Hive中查看并分析数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
①统计数据总条数

②查询前十条数据

③查询level为力荐的总数
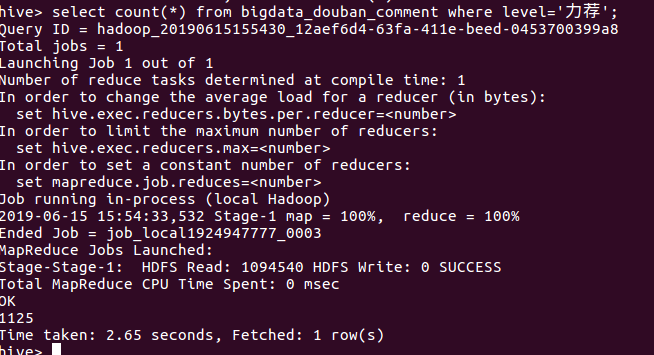
④查询level为推荐的总数
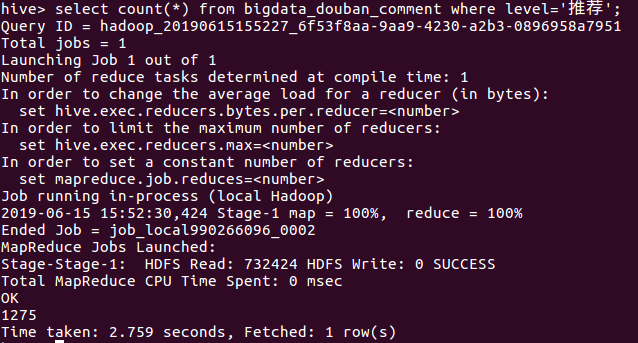
⑤统计level=“力荐”的点赞数
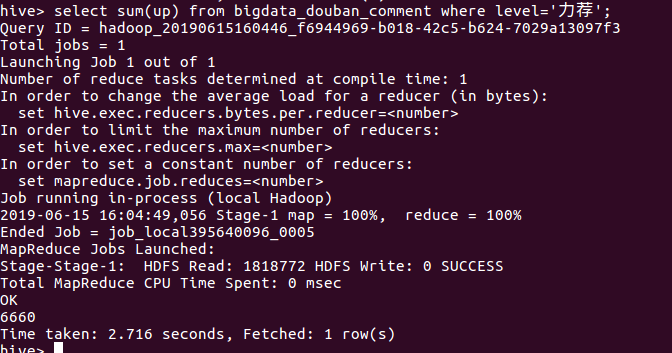
⑥统计level=“力荐”的反对数
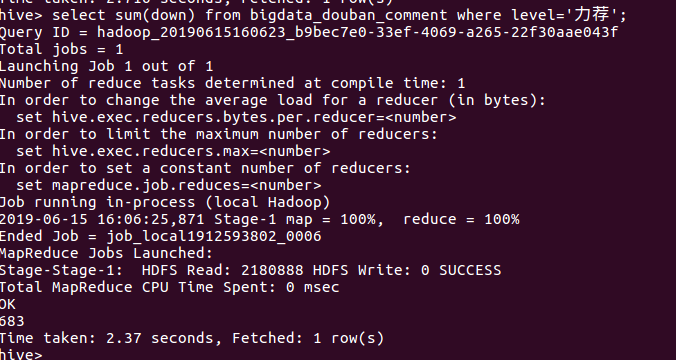
⑦统计level=“推荐”的点赞数
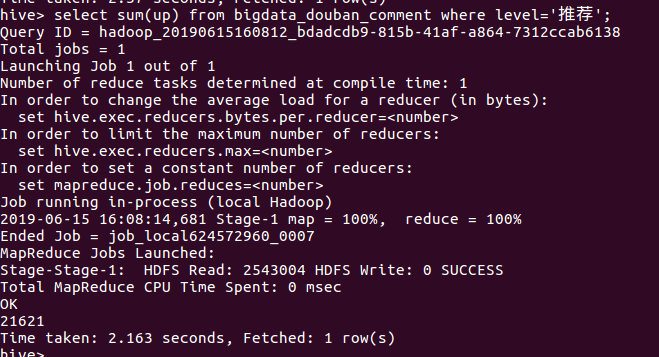
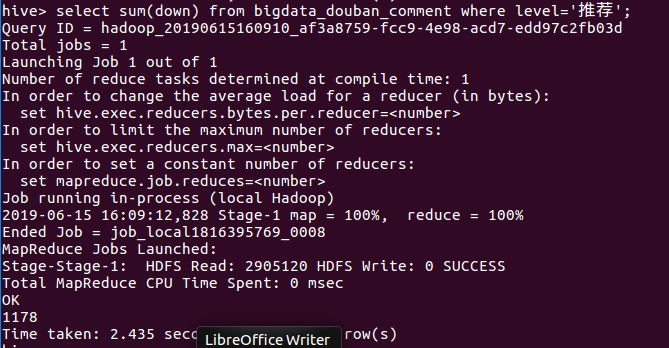
⑧统计level=“推荐”的反对数
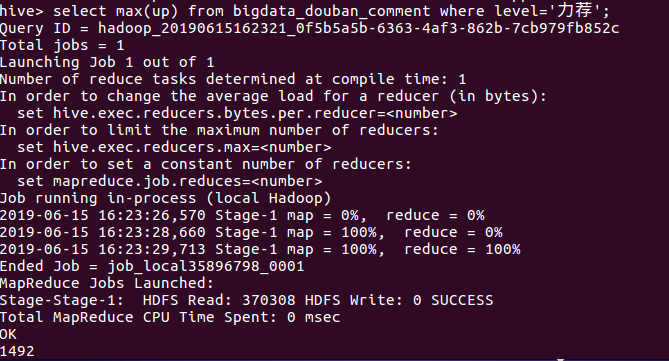
⑨先查询出level=“力荐”的最高点赞数,然后再根据最高点赞数查询出该用户

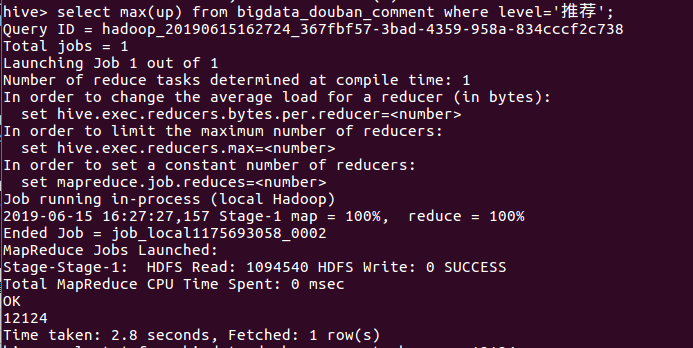
④先查询出level=“推荐”的最高点赞数,然后再根据最高点赞数查询出该用户

总结:
通过hive数据库查询统计,在爬取的数据中,《无双》影片在绝大部分人认为是一部很不错的片子,评分星级中的力荐和推荐数占比例80%以上,并且力荐和推荐的评论的点赞数也是远远高于反对数的,hive数据库统计中,因为评论过长,所以我没有导进去,把评论内容这列删除了,但是查询出来的力荐和推荐的最高点赞评论,就可以去观察这两条评论。
问题:在文本预处理中,已经处理好的数据,导入到hive数据库中,建表的字段也和文本字段对应,但却出现有些数据为null的现象,对于这个问题,我也有回头认真检查是否我的文本预处理没有处理好,但是检查结果是文本已经处理好了,就是都进去有些数据不能对应。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号