redis数据结构编码优化(1)
redis数据结构内部编码优化(1)
Redis可以通过内部编码规则来节省空间。Redis为每种数据类型提供了两种内部编码方式。以散列类型为例,散列类型是通过散列表实现的,这样就可以实现o(1)时间复杂度的查找、赋值操作,然而当键中元素很少的时候,o(1)的操作并不会比o(n)有明显的性能提高,所以这种情况下redis会采用一种更为紧凑但性能稍差的内部编码方式。当键中元素变多时,redis会自动将该键的内部编码方式转换成散列表。
redis的每一个键值都是使用一个redisObject结构保存的,redisObject的定义如下:
typedef struct redisObject
{
unsigned type:4; //当前值对象的数据类型
unsigned encoding:4; //当前值对象底层编码类型
unsigned lru:REDIS_LRU_BITS; //存储最后一次使用此对象的时间等信息
/* lru time (relative to server.lruclock) */
int refcount; // 记录对象引用次数
void *ptr; //指向真正底层数据结构的指针
} robj;
其中type字段表示的是键值的数据类型,取值可以是如下内容
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
encoding字段表示的就是Redis键值的内部编码方式,取值可以是:
#define REDIS_ENCODING_RAW 0
#define REDIS_ENCODING_INT 1
#define REDIS_ENCODING_HT 2
#define REDIS_ENCODING_ZIPMAP 3
#define REDIS_ENCODING_LINKEDLIST 4
#define REDIS_ENCODING_ZIPLIST 5
#define REDIS_ENCODING_INTSET 6
#define REDIS_ENCODING_SKIPLIST 7
| 数据类型 | 可使用的编码方式(元素多/元素少) |
|---|---|
| 字符串string | raw,int |
| 散列类型hash | hashtable,zipist |
| 列表类型list | linkedlist,ziplist |
| 集合类型set | hashtable,intset |
| 有序集合类型zset | skiplist,ziplist |
字符串类型
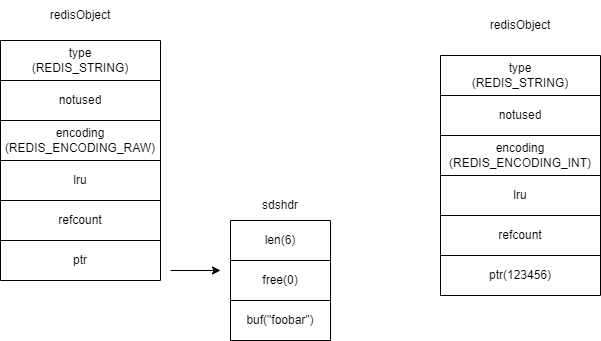
redis使用一个sdshdr类型的变量来存储字符串,而redisObject的ptr字段指向的是该变量的地址。
reids中key的类型为字符串类型
sdshdr的定义如下:
struct sdshdr {
int len;
int free;
char buf[];
}
其中len字段表示的是字符串的长度,free字段表示buf中的剩余空间,而buf字段存储的才是字符串的内容。
所以当之心SET key foobar时,存储简直需要占用的空间是sizeof(redisObject)+sizeof(sdshdr)+strlen("foor") = 30字节
而当键值内容可以用一个64位有符号整数表示时,redis会将键值转换成long类型来存储。如SET key 123456,实际占用的空间是sizeof(redisObject) = 16字节,比存储"foobar"节省一半的存储空间
redisObject中的refcount字段存储的是该键值被引用数量,即一个键值可以被多个键引用。redis启动后会预先建立10000个分别存储从0到9999这些数字的redisObject类型变量作为共享对象,如果要设置的字符串键值在这10000个数字内(如SET key1 123)则可以直接引用共享对象而不用再建立一个redisObject了,也就是说存储键值占用的空间是0字节
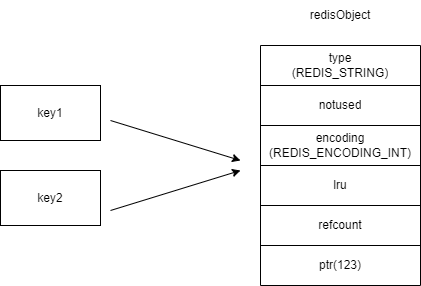
当执行了SET key1 123和SET key2 123后,key1和key2两个键都直接应用了一个已经建立好的共享对象,节省了存储空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号