

数仓设计之星型模型和雪花模型
们用一种非常易于理解的方式来介绍星型模型和雪花模型。
想象一下,你要分析一家超市的销售情况。
核心思想:两种不同的组织方式
这两种模型都是数据仓库中常见的维度建模方法,目的是为了更高效地查询和分析数据,而不是处理日常交易(那是OLTP数据库的活儿)。
它们都围绕一个核心:“事实”和“维度”。
-
事实 (Fact):发生了什么事?是可度量的、数值型的、连续的数据。通常是动词。
-
例子:卖了1瓶可乐,收入3.5元。这里的“销售”就是事实。
-
-
维度 (Dimension):谁?什么时间?什么地点?是谁?是描述性的、文本型的、离散的数据。通常是名词。
-
*例子:时间(2023-10-27)、门店(XX超市XX店)、产品(可乐)、顾客(张三)。*
-
一、星型模型 (Star Schema):简单直接
比喻:一个明星(事实表)被一群粉丝(维度表)直接围着。
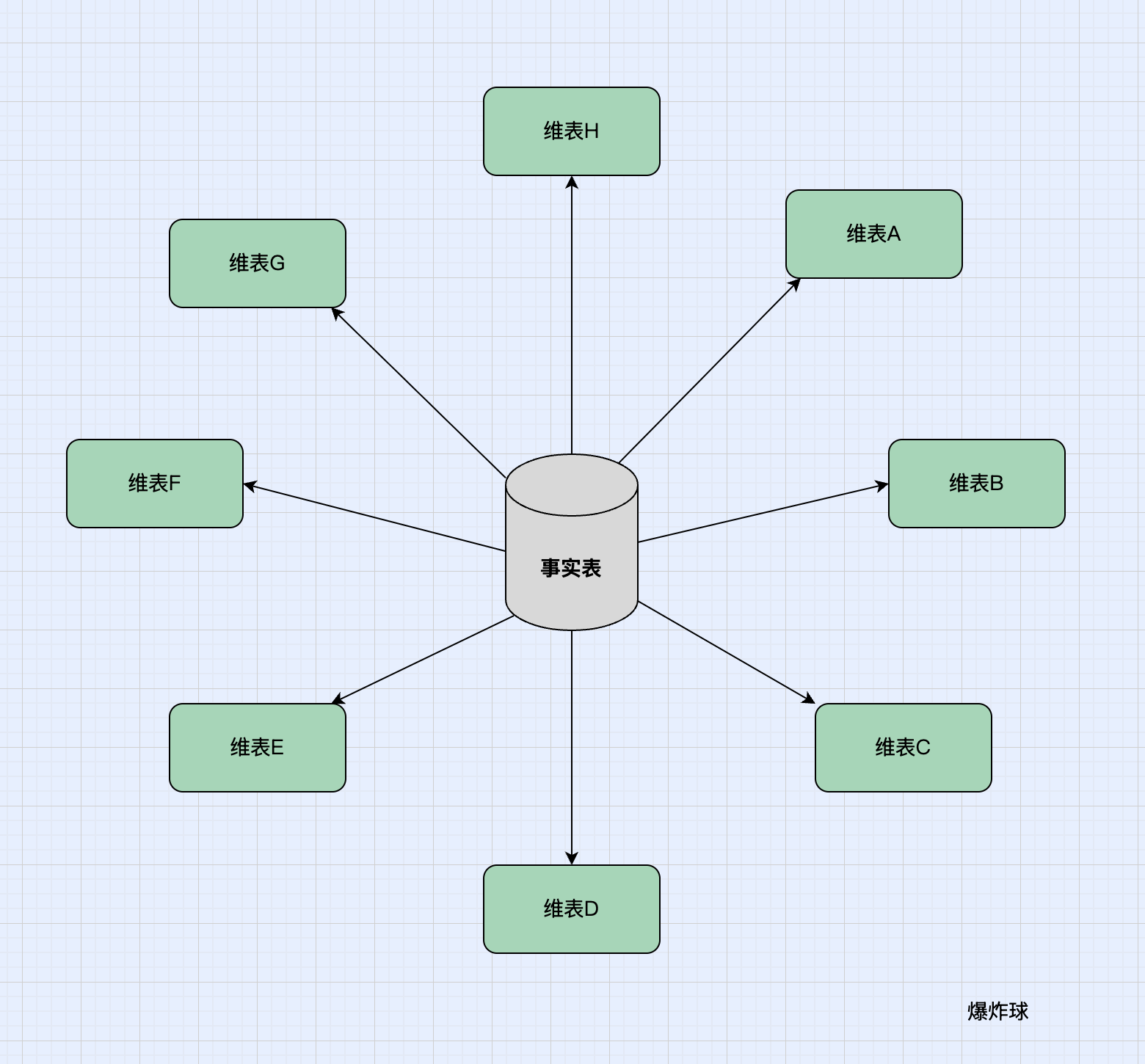
-
一个中心表:叫做事实表(Fact Table)。它记录了核心业务事件。
-
例子:
销售事实表。它的每一行代表一笔销售记录。 -
它包含两类列:
-
外键列:连接各个维度表的外键,如
时间键、产品键、门店键、顾客键。 -
度量值列:可计算的数据,如
销售金额、销售数量、成本、利润。
-
-
-
多个周边表:叫做维度表(Dimension Table)。它描述了事实的上下文。
-
例子:
时间维度表、产品维度表、门店维度表、顾客维度表。
-
-
所有维度表都直接连接到事实表,维度表之间没有任何连接。从图形上看,像一颗星星,所以叫星型模型。
优点:
-
查询非常简单快速:因为大部分查询只需要一次大表(事实表) 和 小表(维度表) 的连接(JOIN),甚至数据库优化器可以直接跳过某些维度表。
-
易于理解:结构非常清晰,业务人员一看就懂。
-
对BI工具非常友好:Tableau、FineBI等工具可以自动识别这种模型,轻松拖拽生成报表。
缺点:
-
数据冗余较多:为了避免连接,维度表会存储所有层级的信息。例如,
产品维度表里,每条产品记录都会重复存储它所属的品类、部门名称。如果品类名称改了,所有相关产品记录都要更新。
二、雪花模型 (Snowflake Schema):规范化
比喻:这个明星的粉丝(维度表)还有自己的粉丝(子维度表)。

结构特点:
-
它仍然有一个事实表作为中心。
-
但它的维度表是规范化的。这意味着一些维度表不会直接连接事实表,而是通过其他维度表间接连接。
-
例如,在星型模型中,
产品维度表直接包含了品类ID和品类名称。 -
在雪花模型中,
产品维度表只包含品类ID,而品类ID又连接到另一个独立的品类维度表(里面存品类名称、部门ID),部门ID可能又连接到部门维度表。 -
从图形上看,维度表像雪花一样分叉开来,所以叫雪花模型。
-
优点:
-
减少数据冗余:信息只存储在一个地方。例如,
品类名称只存在品类表里,而不是在每个产品记录里重复存储。节省了存储空间。 -
易于维护:更新数据更方便。比如更改品类名称,只需要在
品类表里修改一条记录即可。
缺点:
-
查询性能相对较低:因为需要连接更多的表(例如:事实表 -> 产品表 -> 品类表 -> 部门表)才能得到想要的信息,复杂的JOIN会影响查询速度。
-
结构更复杂:对业务用户和BI工具不如星型模型友好,理解和使用起来更费劲。
对比总结与如何选择
| 特性 | 星型模型 (Star Schema) | 雪花模型 (Snowflake Schema) |
|---|---|---|
| 结构 | 简单,扁平 | 复杂,分层 |
| 数据冗余 | 多 | 少(更规范化) |
| 查询性能 | 高(连接少) | 低(连接多) |
| 易用性 | 高(易于理解) | 低(更复杂) |
| 存储效率 | 低 | 高 |
| 维护 | 相对困难(更新冗余数据) | 相对容易 |
如何选择?
-
绝大多数情况下,选择【星型模型】。
-
理由:数据仓库的核心目标是快速查询和分析。存储成本通常远低于计算成本和时间成本。用一点点存储空间换取巨大的性能提升,是非常划算的。 这也是为什么星型模型是数据仓库领域最主流、最受欢迎的设计。
-
-
仅在特定情况下,考虑【雪花模型】:
-
维度表本身非常巨大:例如,一个
客户维度表有上亿行,并且其属性(如地址、行业)有复杂的多层结构。这时规范化它可以节省可观的存储空间。 -
工具要求:某些ETL工具或BI工具在处理某些特定逻辑时,雪花模型可能更合适。
-
业务逻辑本身是高度分层的:并且业务用户习惯按这种层级去查询。
-
一句话记住它们:
想要速度快、简单粗暴,就用【星型模型】。
想省点硬盘空间、不怕查询慢点,就用【雪花模型】。(但通常不建议)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号